
基于多神经网络协同训练的命名实体识别
2020-04-29 10:55李业刚
智能计算机与应用 2020年2期
王 栋, 李业刚, 张 晓
(山东理工大学 计算机科学与技术学院, 山东 淄博 255049)
0 引 言
命名实体识别(Named Entity Recongition,NER)是自然语言处理领域(Natural Language Processing,NLP)中经常用到的实用性技术,在事件抽取[1]、信息检索[2]、情感分析[3]等许多任务中发挥着重要作用,旨在从文本数据中提取指定的实体信息。传统的NER多采用机器学习中的监督学习模型,该类模型需要依赖大量的特征工程和语言学规则。随着信息时代的到来,存在于互联网中的文本数据越来越多,此时采用传统方法的NER技术处理如此巨大数据量的文本信息将会十分困难。近年来,深度学习技术(Deep Learning,DL)受到了研究者的广泛关注,基于深度学习的NER技术取得了丰硕的成果,深度学习中的神经网络模型可以有效地自动捕获序列文本中的词级和字符级特征,避免了对特征工程的依赖和人工添加语言学规则,显著地提高了NER的实用性。然而,基于深度学习的命名实体识别方法与统计机器学习方法一样,模型的训练需要大量的有标记数据,以确保识别精度的准确性。但是有标记数据需要人工进行标注,此过程必然会耗费大量的相关成本。如果有标记数据规模小,则难以获得较高的识别精度。
针对有标记语料数据的匮乏,充分利用海量无标记语料数据,本文提出了一种多神经网络协同训练模型(Tri-training for Multiple Neural Network, TMNN)。首先采用3种不同的神经网络(LSTM网络,BLSTM网络,GRU网络)初始化为3种不同的NER识别模型,然后基于Tri-training算法,利用少量有标记序列文本数据和大量无标记序列文本数据对3种NER模型进行协同训练,最后融合3种NER模型对文本数据进行标注。实验表明该模型在简历命名实体识别上取得了良好的效果。
1 相关工作
1.1 命名实体识别
命名实体识别任务于1996年在MUC-6会议上首次提出,旨在识别出序列文本数据中的实体类信息。早期的研究者采用统计机器学习方法对序列文本中的实体类数据进行识别,此类方法需要研究者人工制定相应的语言规则模板。目前,NER任务的研究赢得了众多学者的青睐与重视。究其原因,一方面NER是自然语言处理的关键技术,是信息提取和信息检索的基础。另一方面,随着深度学习的不断发展,将深度学习技术应用在NER任务上,也已成为时下学界的研究重点。
深度学习中的循环神经网络(Recurrent Neural Network,RNN)能够捕捉句子的上下文信息,尤其适用于序列任务。随后具有改进结构的长短期记忆网络(Long Short-Term Memory,LSTM)逐渐成为解决序列问题的主流方法,常见的基于深度学习的NER模型结构如图1所示。文献[4]使用LSTM网络和CNN网络组成了一种混合结构模型,该模型可以分别获取字符和词级别的特征信息,避免了对特征工程的需求。文献[5]的LSTM模型对输入模型的序列处理了两次,第一次以提取文本信息,第二次用来消除歧义。文献[6]将LSTM网络和条件随机场(Conditional Random Field,CRF)进行了联合,模型获得了良好的性能。
综合以上学者的研究在分析后可知,将深度学习技术与传统的机器学习方法进行融合所产生的混合模型具有良好的性能。一方面,深度学习技术可以自动获取文本序列的特征信息,减少人工干预。另一方面,用机器学习算法对深度学习识别模型进行优化和校正可以获得更优秀的识别效果。
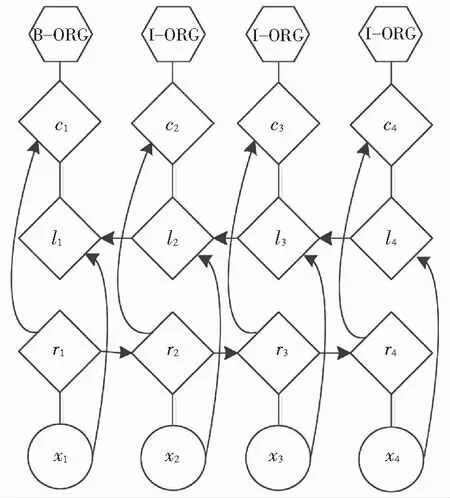
图1 基于深度学习的命名实体识别图
1.2 LSTM网络与BLSTM网络
长短期记忆网络(Long Short-Term Memory,LSTM)是一种能够捕获序列文本特征信息的RNN改进模型,在语音识别[7]、机器翻译[8]、语言建模[9]等多种任务中均有着良好表现。相较于传统的RNN模型,LSTM模型解决了早期RNN模型存在的长期依赖问题,同时避免了梯度爆炸和消失的问题。尽管文本序列和语音序列的任务不同,但LSTM网络的结构十分适合于处理序列化的数据,LSTM网络记忆单元结构如图2所示。LSTM网络具有3种门结构,分别是:输入门、遗忘门、输出门。其中,输入门控制当前输入的信息,遗忘门决定保留上层传来的信息量,输出门控制网络输出的信息。通过3种门结构,LSTM可以有效地控制记忆信息。LSTM网络的公式描述如下所示:
ft=σ(Wf·[ht-1,st]+bf),
(1)
it=σ(Wi·[ht-1,st]+bi),
(2)
(3)
(4)
ot=σ(Wo·[ht-1,st]+bo),
(5)
ht=ot⊙tanhCt.
(6)

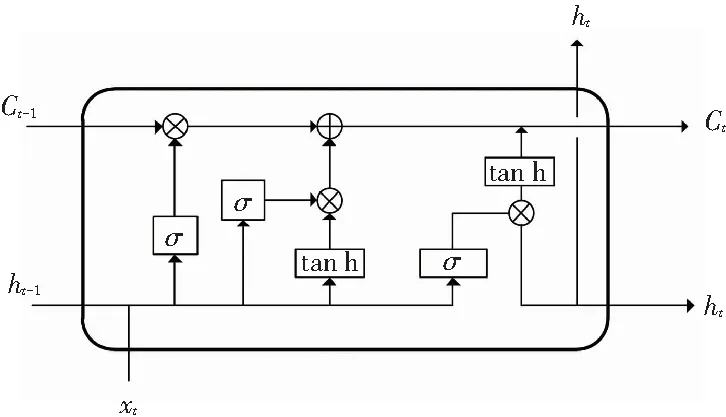
图2 LSTM记忆单元图
双向长短期记忆网络(Bidirectional Long Short-Term Memory,BLSTM)的设计原理是将一个前向的LSTM网络和一个后向的LSTM网络连接到同一输出,以此来获取前向和后向的信息[10]。相较于单向的LSTM网络,该网络结构可以更充分地利用序列化文本的上下文信息,双向网络的输出为前向和后向网络的输出拼接,该种输出的公式描述如下所示:
(7)
1.3 GRU
门控循环单元(Gated Recurrent Unit,GRU)也属于RNN网络的一种变体网络模型[11]。该网络具有更简洁的门结构,相较于LSTM网络依靠3种门结构来实现信息的更新与保留,GRU网络则依靠更新门与复位门来控制记忆信息,更新门负责控制t-1时刻时记忆单元存储的信息量,复位门负责结合当前输入的信息与历史记忆信息,2种门结构共同决定了GRU网络的输出表示。GRU网络记忆单元结构图如图3所示。GRU网络具有结构更简单,参数更少,计算速度更快的优势。GRU网络的公式描述如下所示:
rt=σ(Wr·[ht-1,st]),
(8)
zt=σ(Wz·[ht-1,st]),
(9)
(10)
(11)
其中,Wr、Wz、Wh为权重矩阵;zt为更新门;rt为复位门;σ为激活函数;⊙表示向量之间的点乘运算;ht为t时刻GRU的输出表示。

图3 GRU记忆单元图
1.4 协同训练
协同训练算法是一类典型的半监督学习算法,可以将无标记的数据自动训练为有标记的数据,使得海量无标记的数据得以利用,减少了对有标记数据的依赖,训练的过程中仅仅使用了少量的有标记数据。文献[12]提出的Co-training算法通过在2个视图上利用有标记的数据分别初始化分类器,并使用2个分类器对无标记的数据进行标注,同时将每个分类器标注后的数据作为另一个分类器的输入,从而达到更新训练集的目的。随后,文献[13]提出了Tri-training算法,增加了第三个分类器。该算法通过对有标记数据集重复取样生成训练集,由此训练得到3个分类器。在随后的训练过程中,3个分类器中用到的训练数据皆由其他两个分类器合作提供。在对数据进行标注时,Tri-training算法不同于Co-training算法仅仅使用一个分类器进行标注,而是采用投票法将3个分类器联合起来对数据进行标注。上述过程不再需要分类器的差异性,因此使得Tri-training算法具有了更强的实用性。
综合上述研究,本文融合神经网络模型和Tri-training算法,提出了多神经网络协同训练模型。首先选取3种不同的神经网络模型,作为Tri-training算法的3个初始模型,为使初始识别模型具有一定的差异性,本文实验中分别选取了LSTM网络、BLSTM网络及GRU网络。TMNN模型在训练的过程中使用了少量的有标记数据和大量无标记数据,克服了缺乏有标记语料的困难。
2 多神经网络协同训练模型
基于上述的相关工作,本文提出一种多神经网络协同训练模型TMNN,首先选取了3种不同的神经网络模型,彼此都具有一定的差异性。模型训练时使用少量有标记的数据L以及大量未标记的数据U对3种初始模型进行协同训练。首先对L进行重复采样,得到3个不同的训练集L1,2,3。然后利用训练集分别训练3种初始识别模型H1,2,3。
在协同训练的过程中,各神经网络识别模型所更新的有标记数据由其余两个识别模型协同提供。假设一个无标记的数据x,如果H2和H3对x的识别相同,则认为该识别结果准确。如果H1对x的识别与H2和H3不相同,则该识别结果不准确。每一轮训练,待标记的数据从U中获得,直至U为空。训练结束后,获得的模型H1,2,3基于投票法对数据进行重新标注,其计算公式如下所示:
(12)
其中,L为少量的有标记数据集;P为初始模型的识别精度;θ为用于判断标注结果的函数。
TMNN的算法步骤详见如下。
算法:多神经网络协同训练模型TMNN
输入:有标记数据集L;无标记数据集U;初始模型H1、H2、H3
输出:最后的NER结果
Step1L→L1、L2、L3、T
[H1,L1]→C1,[H2,L2]→C2,[H3,L3]→C3
Step2Repeat
从U中选取待标记数据至Ui
利用Ci1,Ci2,Ci3进行标记,并且得到更新数据集V1、V2、V3
Li1∪V1→Li+11、Li2∪V2→Li+12、Li3∪V3→Li+13。其中,Li+11,2,3为新的训练集
[H1,Li+11]→Ci+11
[H2,Li+12]→Ci+12
[H3,Li+13]→Ci+13
Li+11∪Li+12∪Li+13→T
H1,2,3依据投票法对T中数据重新标注
untilU为空
3 实验
3.1 实验设置
本文在新浪财经随机选取1 024份上市公司的高管简历中文文本数据作为实验的语料,该语料包括了姓名、学历、籍贯、毕业院校等8种实体信息,8种实体描述见表1。数据集的规模为16 565条,实验过程中对语料随机选取20%作为测试集,20%作为有标记的训练集L,60%的数据集作为未标注集U。为了避免神经网络模型输入差异性对实验效果的影响,实验的过程中统一使用[-0.25,0.25]区间内随机初始化的方式得到的字向量作为3种初始化模型的输入。

表1 简历实体类别表
3.2 评价指标与标注策略
本文采用BIO的标注策略,该标注策略中B表示实体的起始部,I表示的是实体的非起始部,O表示其他。并且采用准确率(Precision)、召回率(Recall)、F1值作为模型识别性能评价指标。本文评价指标的计算公式如下所示:
(13)
(14)
(15)
3.3 实验结果与分析
为了分析TMNN模型的性能,本文对比分析了TMNN模型与传统协同训练方法和3种单一神经网络NER模型(LSTM-CRF模型、GRU-CRF模型、BLSTM-CRF模型)在相同数据集上的识别效果。其中,传统协同训练选用条件随机场CRF作为初始分类器,实验结果见表2。从表2中可以看出,多神经网络协同训练模型的识别质量远高于传统协同训练算法。究其原因,传统协同训练对特征工程和语言学规则具有较高的依赖性,模型泛化性能较差,识别质量低,而本文提出的TMNN的初始识别模型分别选用了3种不同的神经网络模型,这三种神经网络可以自动提取文本数据的内部特征,避免了人工添加过多的特征工程和语言学规则,从而显著地提高了NER的精度。相较于3种单一的神经网络模型,多神经网络协同训练模型TMNN通过使用不同的神经网络提取到具有差异化的特征,并且通过协同训练模型,达到持续优化模型的目的,对比3种单一的神经网络模型的F1值分别有了3.35%、2.58%、1.25%的提高,系统性能显著提升。
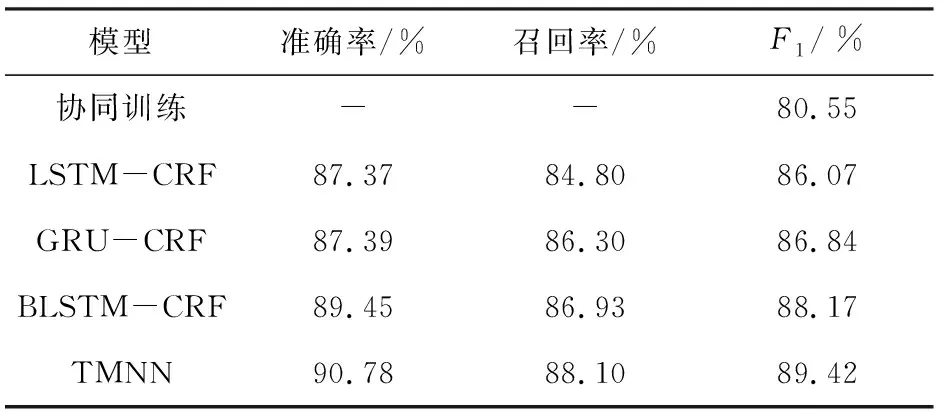
表2 实验结果对比表
图4给出本文提出的TMNN模型和模型所使用的LSTM网络、BLSTM网络、GRU网络在训练过程中识别精度的变化趋势。从图4中可以看出,当iteration大于5时,4种模型的F1值趋于稳定。并且在训练过程中,多神经网络协同训练模型的性能都要优于其他三种神经网络模型。综合上述实验结果可以看出,多神经网络协同训练模型具有良好的稳定性和系统性能,并且模型的实用性也有了显著的提高。
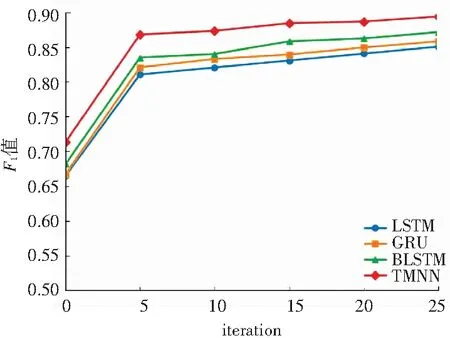
图4 TMNN和3种神经网络识别效果对比图
Fig. 4 Comparison of recognition effects between TMNN and three neural network
4 结束语
本文提出的多神经网络协同训练模型,将神经网络和协同训练算法各自的优势相结合,使用神经网络模型自动提取序列文本的内部特征,有效利用了协同训练算法对无标记数据进行训练,达到了利用大量无标记数据进行命名实体识别的目的,TMNN模型降低了对人工标记数据的需要,模型的系统实用性得到了提高。实验表明,本文模型具有良好的系统性能,在实际应用中优于已有的其它模型。
随着专业领域语料越来越多,识别专业领域命名实体的需求越来越大。下一步将探索专业领域的命名实体识别方法,以提高命名实体识别的跨领域适应性,进一步增强模型对于专业领域文本数据的学习能力,从而达到更好的专业领域识别效果,提高命名实体识别的应用范围。
猜你喜欢
社会科学战线(2022年9期)2022-10-25
现代电子技术(2022年15期)2022-07-28
舰船科学技术(2022年11期)2022-07-15
新班主任(2022年4期)2022-04-27
电子产品世界(2022年4期)2022-04-21
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
计算机系统应用(2021年2期)2021-02-23
民生周刊(2017年19期)2017-10-25
软件(2017年6期)2017-09-23
