
基于改进AdaBoost算法的选股模型
2020-04-29 11:00贺超,吴飞,何洋,朱海
智能计算机与应用 2020年2期
贺 超, 吴 飞, 何 洋, 朱 海
(上海工程技术大学 电子电气工程学院, 上海 201620)
0 引 言
随着改革开放的不断深入,股票市场呈现出强劲崛起态势,并且在高速发展的当代中国社会扮演着重要角色。股票投资的主要目的就是在控制一定风险的前提下取得投资的最高收益。
传统的交易模式通常基于人为经验的对MACD、BOLL和RSI等技术指标进行判断,从而做出投资决策。由于大数据、云计算以及人工智能等科学技术的进步,传统的金融交易也深受影响,并且在实际量化投资领域运用中取得了良好效果。一直以来,股票市场吸引了各界的广泛关注与探讨研究,究其原因就在于其具有各种复杂多变的指标和观测角度,使得投资机遇与风险并存。支持向量机(Support Vector Machine, SVM)是基于统计学习理论推演生成的数据挖掘技术[1],但是由于SVM对于大数量级的数据样本的训练有一定的难度,而实际面临的股市信息数据巨大,所以传统的SVM方法不足以支撑大规模训练强度。
针对股票信息受到影响波动拐点较多等特点[2],单独的分类或预测算法无法做到较为灵活处理的问题,经过研究可知,AdaBoost算法通过权重结合若干个弱分类器进行串行的学习[3],并且通过联合权重投票机制求得最终结果。同时考虑到股票因子繁杂,受到较多因素影响,如此一来就会在样本数据集层面上引入较多的不确定性噪声,而AdaBoost算法对于异常值较为敏感,对于最终结果也会造成较大的影响[4],所以在训练阶段选用了判决式的特征因子选择方法,能够在一定程度上剔除相关影响,与传统决策机制相比[5],除了分类器自身的精度信息外,还充分利用了特征因子权重信息来辅助决策,使得整体效果得到了显著提升。利用上述分析来研究上市公司的财务指标与个股价格浮动率之间的关系,从而建立选股分类模型[6]。这里对此课题拟展开研究论述如下。
1 AdaBoost算法
自适应增强算法(Adaptive Boosting Algorithm)[7],即AdaBoost算法,其主要思想是对于股票样本训练集合D={(x1,y1),(x2,y2),...,(xN,yN)},其中xi表示股票样本的因子属性特征,yi表示个股的输赢率作为标签变量,N表示样本个数,以股票一年为时间节点的后复权股价涨跌幅大于HS300指数的涨跌幅取“1”,小于则取“0”,所以有Y∈{+1,-1}。在选定好弱分类器后,初始状态下,所有样本权重相等,根据AdaBoost思想,不断串行迭代训练,并且在训练过程中后一个弱分类器将会着重训练被前一个弱分类器错分的样本,最终得到加权后的最终结果[8]。此处,给出主要流程具体如下。
输入:(x1,y1),(x2,y2),...,(xN,yN),其中xi∈X,且yi∈Y
初始化:W<1>=(w<1>1,w<1>2,...,w<1>N)T,w<1>i=1/N,其中i=1,2,...,N,表示第i个分类器样本的权重分布。
训练过程:
formin range(M):
Step1利用具有权重向量w
hm(X):x->{-1,1},
(1)
Step2通过hm(X)在训练集上的效果,计算分类误差率,可表示为公式(2):
(2)
并且,若分类误差率em≥1/2,则算法提前停止,整体构建失败。
Step3为基分类器分配相应的构建权重系数,可表示为公式(3):
(3)
Step4更新训练权重向量W
(4)
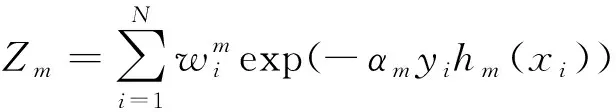

(5)
2 改进AdaBoost算法
2.1 判决式因子选取
根据随机子空间(Random Subspace Method, RSM)树结构采样方法[3],主要是从整个数据集中随机采样得到每个子树空间的子样本集,每次在建立子分类器的过程中,并不是采用整个数据集作为输入,当数据样本数量足够大时,通过实验表明,此种策略最终得到的分类结果精度要高于传统的AdaBoost算法。但是,上述随机采样在多次采样过程中,会出现某些样本被多次重复提取,而某些样本仅有少量的机会、甚至在建模阶段未被采用的情况,这就会导致基分类器的多样性受到制约。

ar=1+log2T,
(6)
研究中,并不是选择整个数据集的所有特征进行计算,选择基尼系数小的特征属性作为分割点,可表示为:
G[g(aj(d))]=gini(d)-gini(aj(d)) ,j∈[1,T],
(7)
其中,gini(d)表示该节点分割前的基尼系数,对应的gini(aj(d))表示在节点d中以最佳特征属性aj分割后的基尼系数。
由于采取特征属性随机采样的机制,就使得在构建基分类器的过程中会出现某些特征属性被多次采取的情况,而在样本个数相同的前提条件下,从特征属性采样的角度来分析,就势必造成了数据的不均衡,因此当所在基分类器建成后,对于被多次选择的特征属性aj,可进行如下处理:
(8)
其中,ns(aj)表示选择特征属性aj的次数,μ(G[g(aj(d))]) 表示其均值,在子决策树中选择所有G[g(aj(d))]和其对应的m个特征属性(m≤T),可推导计算出整体对应的均值μ(G(g))和标准差σ(G(g)),并且如果μ(G(g))和σ(G(g))之间的差值是正数,则提高特征属性aj的权重,反之减少其对应的权重。
2.2 改进决策机制
由2.1节内容可知,为了保证子树之间的多样性,改进AdaBoost算法对于样本特征属性进行随机采样,并不是完整使用样本的所有数据,对子分类器进行训练,从而提高了各子分类器之间的多样性,更贴近真实数据多变的情况。
改进AdaBoost算法采用包外估计的方法,选用2/3的训练数据用于构建子树,即基分类器,此外1/3的数据用于模型建成后的验证及相关学习权重的验证。利用训练数据集Dk去构建子树基分类器Ck,将测试数据作为输入时,由前述切割原理可知,通过计算特征属性的基尼系数得到最佳切割属性aj,再将测试数据通过基分类器得到分类结果的平均精度作为子树基分类器Ck的属性aj的决策权重wk,j。而在真正的在线使用阶段,对于任何一个未知的样本属性,改进后的算法将综合考虑属性分割点aj的决策权重wk, j和子分类器的自身精度去计算最终的联合投票权重,最终分类预测结果可表示为:

y∈Y.
(9)
其中,I-AdaBoost(x)表示改进算法的预测结果;y表示真实的分类标签;Ci(x)表示子树基分类器的预测结果;acci为子树Ci的精确度;wij即为切割属性aj的决策权重。
通过新的决策集成机制,充分保留了对特征属性随机采样而形成的子树之间的多样性,并且结合传统的投票决策方式,在提高预测结果精确度的同时,更好地切合了真实数据不确定性和多变性,从而有效提升了模型的鲁棒性。
3 实验设计与分析
3.1 实验设计
本文基于同花顺平台提供的iFinD数据库接口,以HS300为股票池,提取了2008~2018年的年度每只股票财务指标数据。文中例举了贵州茅台的财务指标实验数据见图1。

图1 贵州茅台的财务指标实验数据
Fig. 1 Experimental data of financial indicators of Moutai, Guizhou
实验选取2008~2018年HS300为股票池中的股票数据作^为实验数据,实验数据为每只个股的财务指标数据,包含营业总收入、营业总成本、营业利润、利润总额、净利润、每股收益、其他综合收益、综合收益总额等信息。目标函数是通过计算每只个股复权股价涨跌幅是否大于HS300指数涨跌幅计算求得。如果个股指数涨跌幅大于HS300指数的涨跌幅则取“1”,小于则取“0”,实验以2008~2017年数据为训练数据集,以2018年数据作为测试数据集。
3.1.1 评价标准
对于改进AdaBoost模型,在实际运用中,以分类准确率为其性能好坏的评价标准,其数学定义可写为:
(10)
3.1.2 设计流程
股票投资中,股票收益率的涨跌幅是一个非常重要的指标。根据模型规则,如果预测下一年的收益率为正,则做出买入的决策,并且投资状态设置为1;如果预测下一年的收益率为负,则做出卖出的决策,并且投资状态设置为0。决策流程如图2所示。
3.2 实验分析
在量化交易发展初期,SVM算法由于其原理的简单易用性,在实际运用中取得了很好的效果,但是随着数据量级的增加,SVM在大数量级的交易数据和研报数据的处理中暴露出不足之处,这也是其算法本身存在的问题。由于AdaBoost算法框架思想的提出,使得可以集中各弱分类器,并在每一步中不断地进行迭代优化,因为其对异常值较为敏感的因素,在实际生产数据的应用上会产生较大的影响,因此对于传统的AdaBoost算法,加入新的特征属性选择机制,如此即使得最终的决策机制同时结合了子分类器自身的精度和特征属性权重信息,使得最终的分类精准度得到了极大的提升。本次研究中各选用算法的结果对比曲线如图3所示。

图2 决策流程图

图3 分类准确率
由图3分析指出,由于改进后的AdaBoost算法融合了属性自身精度和基分类器的精度,更加贴合实际决策方式,提高了系统的鲁棒性,而相比于传统的AdaBoost算法,SVM性能上要稍有逊色。改进后的AdaBoost算法的实测效果最佳,分类准确度可达到99.3%。
上述对比主要是基于业务层面的分析,下一步则需讨论模型本身的性能分析,而为了更好地分析3种算法模型的性能,选取2014~2018年间的数据作为样本,分析对比结果如图4所示。

图4 AUC评分
由图4分析可知,从每个时期上看,因为改进后的AdaBoost算法运用新的判决式因子选择机制,保证了基分类器间的多样性,提高了算法整体的鲁棒性,所以每个时期的AUC评分非常稳定,并且评分较高,最高评分可达0.71,这就表明改进后的AdaBoost算法自身性能上较为稳定且有好的实际效果。其中,SVM算法与传统的AdaBoost算法相比,性能上仍有欠缺。
4 结束语
随着中国一带一路等政策的发展,逐渐走向国际市场,股票市场将不断完善。金融科技的布局,也将给股票市场带来新的活力。本文从股票的投资价值角度分析,利用改进AdaBoost算法,通过新的判决式属性选择机制保持了基分类器的多样性,更客观地贴合实际股票数据的情况,增强了整体的鲁棒性,与此同时,在最终的投票机制中融合了特征因子自身的精确度和基分类器的精确度评分,很大程度上提高了最终的决策性能,在实际应用中有着良好的适用性。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
心理学报(2022年5期)2022-05-16
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
当代陕西(2020年17期)2020-10-28
领导决策信息(2018年16期)2018-09-27
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
人大建设(2017年10期)2018-01-23
软件导刊(2017年4期)2017-06-20
