
基于深度学习的风格迁移算法的研究与实现
2020-04-29 10:55曾国辉
智能计算机与应用 2020年2期
王 鹿, 曾国辉, 黄 勃
(上海工程技术大学 电子电气工程学院, 上海 201620)
0 引 言
近年来,随着人工智能、计算机视觉技术的迅猛发展,越来越多的机器学习应用场景在不断涌现。与此同时,目前有着较好表现的监督学习需要大量的标注数据,但标注数据是一项枯燥无味且花费巨大的任务,所以无监督的image-to-image式风格迁移学习即吸引了学界的更多关注,并已成为深度学习技术的重要应用之一。对于传统监督式机器学习而言,迁移学习都是基于同分布假设[1],同时需要大量标注数据,然而实际使用不同数据集的过程中可能出现一些问题,比如数据分布差异,训练数据过期,也就是已然做过标定的数据要被丢弃,有些应用中数据分布也会随着时间的推移产生变化。因此,如何充分利用已经标注好的数据,同时又保证在新任务上的模型精度已经成为一个亟需解决的难题。基于此,本文拟对基于深度学习的迁移学习进行研究[2-3]。
目前,研究发现对一幅图像而言,风格和内容在卷积神经网络中的表达是可以分开的。也就是说,研究中可以独立地操纵2种表达来产生新的、可以感受的有意义的图片。在本文中,将使用VGG-16、VGG-19和 Cycle GAN[4],来实现风格迁移,对比这3种网络的结果,分析后发现,Cycle GAN的效果最好,VGG-16和VGG-19虽然也有一定的效果,但是合成图像的整体风格并不突出,不能满足本文研究的需求。
1 图像风格迁移算法
图像风格迁移技术主要有2种。一种是由Gatys等人[5]率先提出的NAAS,该方法以VGG网络为基础进行损失网络的设计;另一种是Johnson等人[6]提出的快速图像风格迁移技术(FNST),该方法基于Gatys等人的研究成果,在损失网络的前端添加了一个Image Transform Net,该网络基于残差网络进行设计。两者之间的关系如图1所示。
Gatys所提出的NAAS是在VGG网络的基础上,利用梯度下降,经过若干次的迭代从而获得转换风格后的图像。该方法的整体流程如图2所示。

图1 快速图像风格迁移方法
Fig. 1 Fast image style migration method

图2 NASS工作流程图
1.1 VGG网络
VGG (Visual Geometry Group)隶属于牛津大学, VGG自2014年先后发布了网络模型VGG11~VGG19, 该小组研究证明了增加神经网络的深度能够在一定程度上影响神经网络的性能。VGG网络结构简单,其卷积层和池化层可以划分为不同的块(Block),从前到后依次编号为Block1~Block5。每一个块内包含若干卷积层和一个池化层。使用同样大小的卷积核尺寸 (3×3) 和最大池化尺寸 (2×2)。此外,VGG网络还有5个最大池化层,分别分布在不同的卷积层之下[7-8]。
(1) VGG16。VGG16共有13个卷积层(Convolutional Layer),分别用conv3-XXX表示,3个全连接层(Fully connected Layer)分别用FC-XXXX表示,5个池化层(Pool layer)分别用MaxPool表示。卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是VGG16中16的来源。考虑到池化层不涉及权重,因此不属于权重层,不被计数。VGG16神经网络模型结构如图3所示。
(2) VGG19。VGG19共有16个卷积层和3个全连接层。如图4所示。
以图4为例,在VGG19的Block2中包含2个卷积层,卷积核为3×3×3,通道数都是128,而Block4包含4个卷积层,1个最大池化层,通道数是512。
1.2 Cycle GAN
传统的GAN的G是将随机噪声转换为图片,但风格迁移中需要将图片转为图片,所以这个时候就要将图片作为G的输入,而G则是学习一种映射了。但是用单独一个GAN的训练并不稳定,可能导致所有照片全部映射到同一张图片的mode collapse[9]。为此,就提出了Cycle GAN用来解决这个问题,Cycle GAN是将2个GAN组合起来,其目的是实现非成对image的转换,尤其适用于图像风格迁移中。为了使得GAN更加稳定,引入了此双向映射的机制,即A→B的GAN和B→A的GAN,同时加入了一个cycle_loss,cycle_loss是采用L1损失设计而成[10-11]。所以研究得到Cycle GAN的损失函数,可将其写为:

图3 VGG16网络结构图
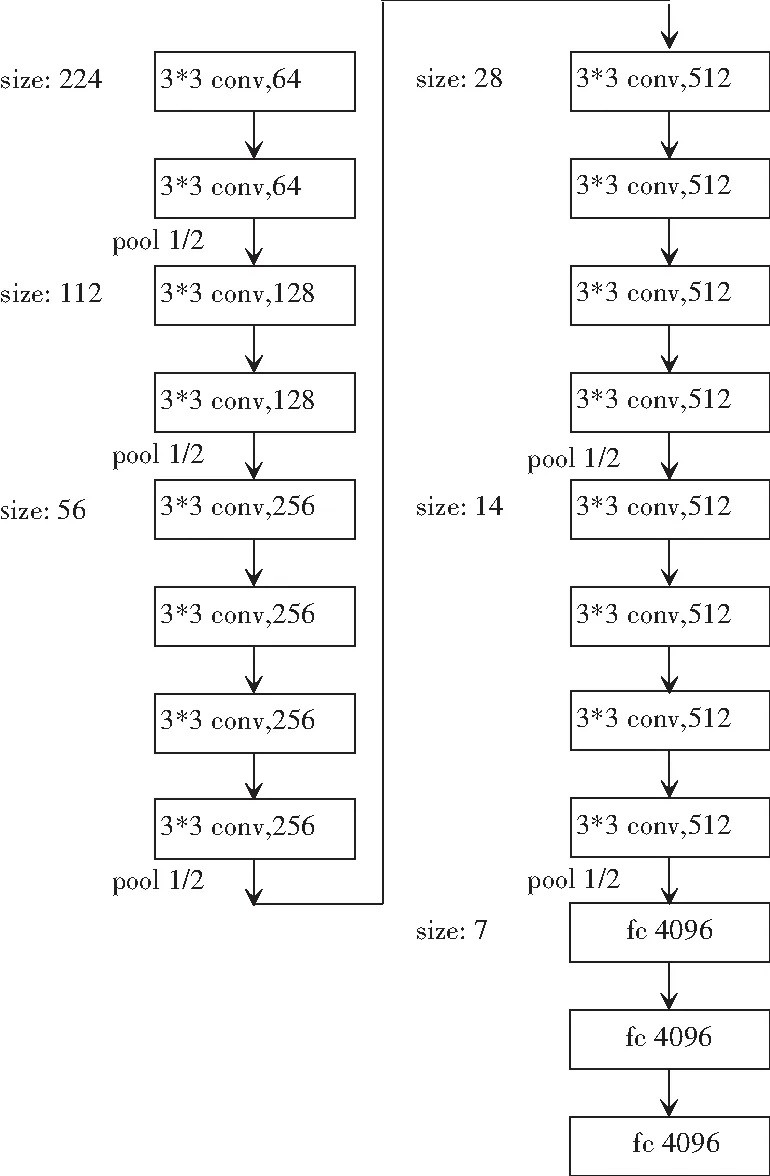
图4 VGG19网络结构图
LGAN(F,DX,Y,X)=Ex~Pdata(x)[logDX(x)],
(1)
LGAN(G,DY,X,Y)=Ey~Pdata(y)[logDY(y)],
(2)
接下来,研究得到了循环一致性损失可表示为:
Lcyc(G,F)=Ex~Pdata(x)[‖F(G(x))-x‖1],
(3)
进而,推得总损失的数学公式如下:
L(G,F,DX,DY)=LGAN(G,DY,X,Y)+
LGAN(F,DX,Y,X)+λLcyc(G,F).
(4)
1.3 损失函数

(5)
(6)
(7)
综上可知,总的损失函数可由下式来计算:
(8)
其中,α和β分别是内容和风格在图像重构中的权重因子,且满足:
α+β=1.
(9)
2 实验
2.1 迁移效果的衡量指标
(1)峰值信噪比(Peak Signal to Noise Ratio,PSNR)[12]:这是一种全参考的图像质量评价指标。运算中需用到如下数学公式:
(10)
(11)
其中,MSE(Mean Square Error)表示当前图像X和参考图像Y的均方误差;H、W分别表示图像的高度和宽度;n为每像素的比特数,一般取8,即像素灰阶数为256。PSNR,单位是dB,取值范围为(0,∞),数值越大表示失真越小。
(2)结构相似性(structural similarity,SSIM)[13]: 这也是一种全参考的图像质量评价指标,可分别从亮度、对比度、结构三方面度量图像相似性。运算中涉及的数学公式可表示为:
(12)
(13)
(14)
其中,uX,uY分别表示图像X和Y的均值;σX,σY分别表示图像X和Y的方差;σXY表示图像X和Y的协方差,即:
(15)
(16)
(17)
其中,C1、C2、C3为常数,为了避免分母为0的情况,SSIM取值范围[0,1],值越大,表示图像失真越小。
2.2 实验环境
本实验选择Python语言和Tensorflow, Pytorch框架进行图像风格迁移的仿真测试。实验环境为 Intel(R) Core(TM) i5-8300H 2.1GHz CPU, GPU 为 NVIDIA。
2.3 训练部分
(1) VGG16和VGG19训练。由于VGG网络深,网络架构权重数量非常大,导致训练非常缓慢,故研究用到的模型就是在ImageNet数据集上预训练的模型。
研究将从预训练的模型中,获取卷积层部分的参数,用于构建仿真中使用的模型,这些参数均是作为常量使用,即不再被训练,在反向传播的过程中也不会改变,此外VGG中的全连接层舍弃掉。参数设置见表1。
(2) Cycle GAN。使用vangogh2photo数据集,Generator采用的是文献[6]中的网络结构;一个residual block组成的网络,降采样部分采用stride 卷积,增采样部分采用反卷积;Discriminator采用的仍是pix2pix中的Patch GANs结构,大小为70×70,Lr=0.000 2。对于前100个周期,保持相同的学习速率0.000 2,然后在接下来的100个周期内线性衰减到0。

表1 VGG16与19相关训练参数设定
2.4 实验分析
实例中的风格图片选为梵高先生的名画《星夜》,如图5所示。

图5 模板艺术图《星夜》
分别使用Cycle GAN、VGG16、VGG19进行实验, 通过生成的图片观察不同目标函数的效果,实例中的风格图片均为梵高先生的名画《星夜》,实验运行效果见图6,图6的对应数据指标见表2。
通过对图6以及表2 的对比发现,VGG16,VGG19得到的结果相近,相较之下艺术风格并不浓烈,而Cycle GAN给人的直观感受就好得多,色度适宜,艺术化表现也恰到好处。

图6 实验效果
表2 实验指标
Tab. 2 Experimental index
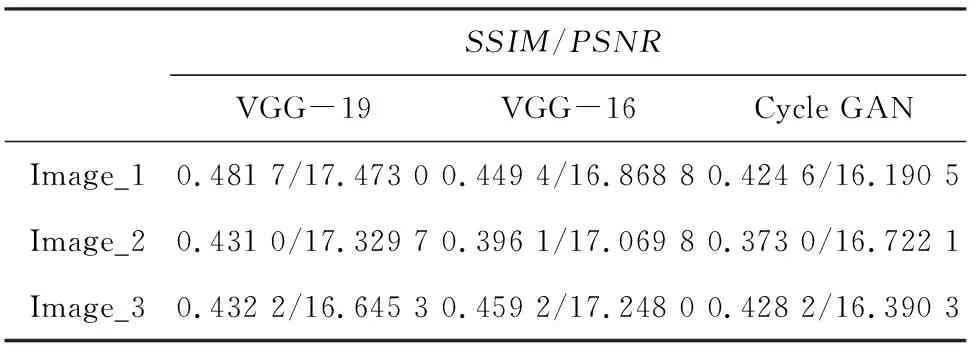
SSIM/PSNRVGG-19VGG-16Cycle GANImage_10.481 7/17.473 00.449 4/16.868 80.424 6/16.190 5Image_20.431 0/17.329 70.396 1/17.069 80.373 0/16.722 1Image_30.432 2/16.645 30.459 2/17.248 00.428 2/16.390 3
2.5 实验结果分析
VGG-16与VGG-19本质上并无太大区别,两者均继承了Alex Net的深度思想,以其较深的网络结构、较小的卷积核和池化采样域,使其能够在获得更多图像特征的同时控制参数的个数,避免过多的计算量以及过于复杂的结构,如此一来VGG就能更好地找出内在特性,从而提取图像的style features。
对比之下,由2个镜像对称的GAN组成的Cycle GAN不仅不需要成对的数据样本,在损失函数方面也进一步考虑了防止生成器G与F生成的样本相互矛盾,保证生成的样本与真实的样本同分布,这样也就保证了生成图像的连续性。
总体来说,GAN网络在这种image-to-image 领域内还是存在很大的优势。
3 结束语
本文选用卷积神经网络模型VGG16、VGG19和Cycle GAN作为训练模型,详细论述三者的网络结构,在pytorch框架下实现图像的风格迁移。对比分析了3种模型的优缺点。最后,以梵高的著作《星夜》为风格模板,以峰值信噪比(PSNR)和结构相似度(SSIM)作为评价指标,选取3幅真实的照片做主观和客观评价,结果表明Cycle GAN效果最佳。但是在实际中,由于卷积神经网络的不可控性,以及噪声处理等原因,可能会使得网络的结果变得不可接受,这也是后续有待深入研究加以改进的问题。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
软件(2017年6期)2017-09-23
