
基于Word2Vec模型和K-Means算法的信息技术文档聚类研究?
2020-04-27 08:53毛郁欣邱智学
中国信息技术教育 2020年8期
毛郁欣 邱智学


摘要:互联网上与信息技术相关的文档和学习资料较为分散,而且会随着信息技术的发展而动态更新。作者提出了一种基于Word2Vec模型和K-Means算法的聚类方法,能够实现对与信息技术相关的网络文档的聚类,并对不同来源和主题的技术文档自动分类,此方法对构建信息技术知识库和在线学习平台具有较强的支撑作用。
关键词:文本聚类;Word2Vec;K-Means算法;领域本体
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2020)08-0099-03
引言
随着互联网的发展,各个技术领域在网上都产生了大量的专业文档和技术资料,且较为分散,再加上信息技术本身发展和迭代非常迅速,相应的文档也会随之不断地动态更新,对应的文档主题和内容呈现出较为明显的动态性。例如,CSDN(信息技术社区)上的技术文章,基本上是按照网站设定好的固定类别(如游戏开发、人工智能、Python等)进行分类,同时允许作者添加一系列个性化标签。但是随着文章数量的增多,有限的固定类别显然无法满足精细化的文章分类需求,只能进行粗略、大概的归类,而作者添加的标签又带有很强的主观性和随意性,不能完全作为分类的依据。因此,运用更加有效和准确的方法对互联网上不同来源、不同主题的信息技术文档进行研究和分析,具有十分现实的意义。互联网上与信息技术相关的文档属于无结构文本,因此运用文本挖掘技术进行量化处理和分析是比较可行的方法。
总体来看,虽然目前关于Web文档聚类或分类的研究已经比较多[1-2],但是直接针对信息技术文档的研究还不多,而结合深度学习模型进行文本挖掘的研究也比较缺乏。为此,本文研究并提出一种基于Word2Vec模型[3]和K-Means算法的聚类方法,能够实现对与信息技术相关的网络文档的聚类。该方法实现了对不同来源和主题的信息技术文档的自动分类,对于构建信息技术知识库和在线学习平台具有较强的支撑作用。
信息技术文档的特征处理
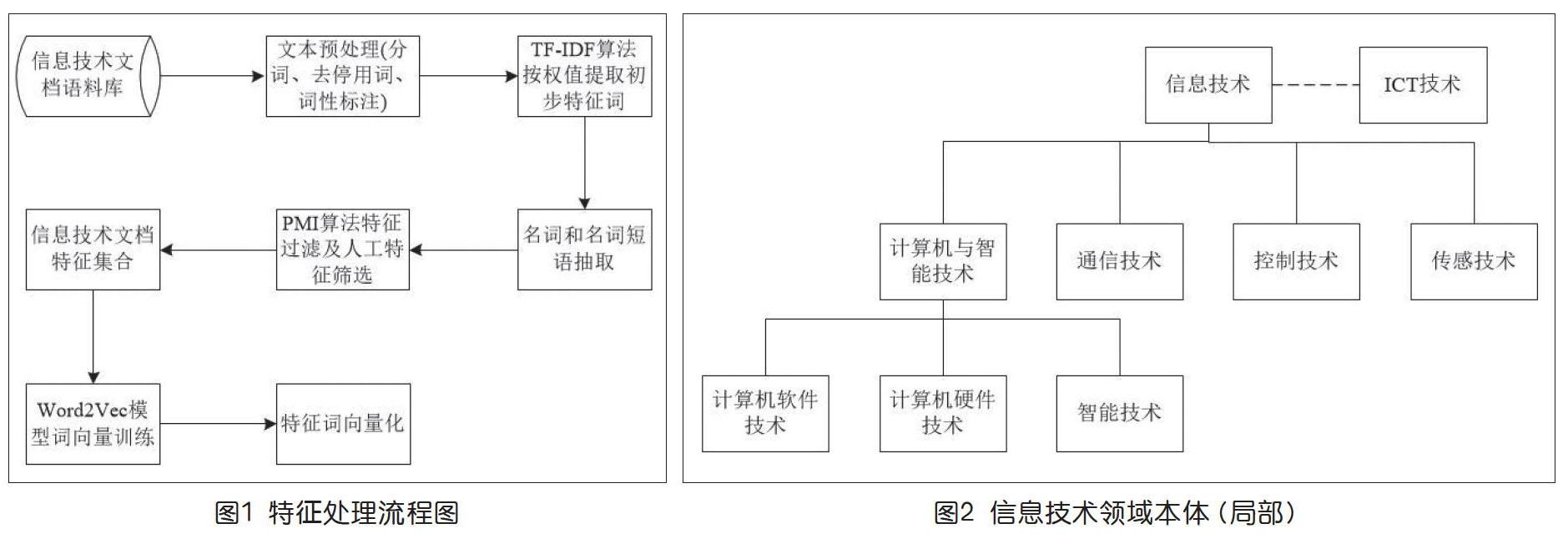
要实现对互联网上多来源、多主题的信息技术文档的自动分类或聚类,首先必须对文档进行特征处理,本研究提出的特征处理流程如下页图1所示。
对于采集到的信息类网络文档,利用开源分词工具进行分词,完成文本预处理。文本预处理之后会产生很多的特征词,如果直接使用预处理后的特征词进行挖掘,不但会造成特征表示上的维度灾难,而且也得不到高质量的聚类结果。[4]因此,需要进一步开展特征提取,从而为后续的挖掘以及最终的聚类带来更好的效果。
本研究使用词频-逆文档频率TF-IDF[5]来计算信息类文档中特征词的权值,按权值大小排序,并选择TF-IDF值超过特定阈值的特征词作为初始特征。此外,由于同一个特征词在不同的技术文档中会重复出现且权值不同,故同一个特征词取最大的TF-IDF值作为权值,并进行去重处理形成初始特征集。
点互信息PMI是从信息论里的互信息概念衍生而来的[6],这个指标常常用来衡量两个事物之间的相关性,如两个词。本研究使用PMI算法将信息类文档预处理语料作为输入,先通过频率计算词语的共现概率,然后再计算词语共现的标准化互信息值NMI,最后返回符合NMI阈值的特征词列表及PMI特征词共现列表。最终通过人工筛选初始特征词和PMI算法过滤得到的特征词,形成信息技术文本的特征集,完成特征提取工作。
Word2Vec是能把词语转化为多维词向量的模型,根据词语的上下文预测词向量。词向量由多维实数表示,虽然不能说明每一维度的实际含义,但它却蕴含了豐富的信息。由于训练时会根据前后就近位置预测词语,考虑了词语间的共现,所以它保持了同义词之间强的相关性。运用Word2Vec词向量模型训练信息类文档的文本语料,可以将其中的信息领域特征词转化为多维实数向量。与传统的空间向量模型相比,它考虑了词与词之间的共现,同义词所对应的词向量在多维空间中会更加接近,为后续更准确的挖掘工作做好了铺垫。
Word2Vec中有两个重要的算法模型:Skip-gram模型和CBOW模型。这两个模型都包含了三层,即输入层、投影层和输出层。CBOW模型是通过输入特征词上下文来预测特征词的空间向量;而Skip-gram模型则是通过输入特征词来预测特征词上下文的空间向量。[7]Skip-gram模型训练时间比CBOW模型要长,但在Skip-gram模型中,每个词都要受到周围词的影响,每个词在作为中心词的时候,都要进行次的预测、调整,这种多次的调整会使得词向量相对更加准确。因此,在对信息技术文档进行文本挖掘的过程中,选择Skip-gram模型进行词的向量化训练。
Skip-gram模型是将一个词语作为输入,来预测它周围的上下文。假设有一个句子结构为,Skip-gram模型就是通过输入来预测 的词向量。
基于K-Means和本体映射的信息技术文档聚类
K-Means是经典的划分聚类算法,算法的优点是时间复杂度低,聚类效果较好。因此,利用K-Means算法对经过向量化的特征词进行聚类,步骤如下:
①随机选择个簇类中心点;
②遍历所有数据点,把数据点划分到距离最近的一个簇类中;
③划分之后就有个簇,计算每个簇类中点的平均值作为新的簇类中心点;
④重复步骤②和③,直到聚类中心不再发生变化,或是迭代次数达到设定的值。
对K-Means聚类中的值的选择,可以依据基于误差平方和SSE的手肘法,计算公式如下:
其中,是第个簇,是中的样本点,是的质心即中所有样本的均值,SSE是所有样本的聚类误差,代表了聚类效果的好坏。在确定的取值后,使用K-Means聚类算法对从信息技术文档中提取出的特征进行聚类。
同时,通过整理和分析信息技术领域的基本概念及其相互关系,初步构建一个面向信息技术领域的本体。其中,本体的部分概念结构如上页图2所示。
利用聚类算法对特征聚类,得到一系列的特征簇类,进一步对簇类进行整理和分析,将簇类及其特征词映射到事先构建好的信息技术领域本体上(如图3)。
结束语
针对互联网上存在的大量与信息技术相关的专业文档,本研究提出一种基于Word2Vec模型和K-Means算法的聚类方法,能够实现对信息技术相关的网络文档的聚类。对经过预处理的文本,利用相对成熟的特征提取算法提取和过滤特征集合,然后利用Word2Vec模型进行特征词向量化处理,在此基础之上利用K-Means算法进行聚类。该方法实现了对互联网上不同来源和主题的技术文档的自动分类,对构建信息技术知识库和在线学习平台具有较强的支撑作用。
参考文献:
[1]乔少杰,韩楠,金澈清,等.基于Multi-Agent的分布式文本聚类模型[J].计算机学报,2018(08):19-31.
[2]宋凯,李秀霞,赵思喆.基于CTM模型与K-means算法融合的文本聚类研究[J].情报理论与实践,2017(11):135-138.
[3]周练.Word2vec的工作原理及应用探究[J].图书情报导刊,2015(02):145-148.
[4]Chandrashekar G,Sahin F. A survey on feature selection methods[J].Computers & Electrical Engineering,2014(01):16-28.
[5]Salton G. The SMART retrieval system-experiments in automatic document processing[M].Prentice-hall,Inc Upper Saddle River,1971.
[6]Vergara J R,Estevez P A. A review of feature selection methods based on mutual information[J].Neural computing and applications,2014,24(01):175-186.
[7]Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word rep-resentations in vector space[J].Computer Science,2013.
基金項目:浙江省高校“十三五”优势专业建设项目(120801,电子商务),浙江工商大学2019年度校高等教育研究课题(xgy19024)资助。
