
基于CART决策树和BP神经网络的landsat 8影像粳稻提取方法
2020-04-27 11:00许童羽胡开越周云成于丰华
沈阳农业大学学报 2020年2期
许童羽,胡开越,周云成,于丰华,冯 帅
(沈阳农业大学 信息与电气工程学院/辽宁省农业信息化工程技术研究中心,沈阳110161)
水稻是中国最主要的粮食作物,居三大粮食作物之首,及时准确地掌握其空间分布状况和种植面积信息,对预测水稻产量、指导农业生产等农业活动起着重要作用[1]。遥感技术因其快速、宏观、综合等特点,已被广泛应用于作物识别、估产等农业领域[2]。根据不同作物生长发育期的差异,采用不同时间序列遥感影像,结合作物物候信息,可以有效识别作物类型及提高其分类精度[3]。朱彤等[4]利用2014~2015年MODIS-NDVI时序数据构建决策树分类模型,根据决策树分类结果与混合像元分解结果精确提取作物种植面积,精度达到92.3%。魏鹏飞等[5]利用多时相影像,通过分析作物的典型植被指数时序变化特征,构建了决策树分层分类模型,成功提取出研究区域水稻等作物空间分布情况,总体精度达到90.9%,Kappa系数为0.895。以上研究是基于作物完整物候期遥感影像,但部分地区易受云、阴雨等天气影响,造成缺乏完整的作物生长发育期影像数据,而基于单时相影像的作物提取易产生“同物异谱”现象,因此本研究综合粳稻3个关键生长期遥感影像特征数据进行分类识别研究。随着深度学习在大规模图像数据集分类上的发展,越来越多学者尝试将深度学习引入遥感图像分类任务上。刘大伟等[6]利用深度学习的常用模型—DBN(深度信念网络)对高分辨率遥感影像进行了基于光谱-纹理特征的分类。赵漫丹等[7]通过构建五层CNN(卷积神经网络)结构,逐像素对光谱信息开展分析,实现对影像光谱特征的提取与分类。但由于遥感领域的小样本性质,使得基于深度学习模型的分类研究易导致过拟合现象,因此本研究选择传统机器学习,在CART决策树初步提取的研究区粳稻分布范围基础上,利用BP神经网络对其进一步细分,探讨采用CART决策树和BP神经网络结合的分类法对我国北方粳稻分类的适用性和精度效果,为基于传统机器学习模型的关键物候期遥感数据作物分类研究提供一条新思路。
1 材料与方法
1.1 研究区概况
以沈阳市为研究区域,其地处东经 118°53~125°46′,北纬 38°43′~43°26′,多为平原,属温带半湿润大陆性气候,全年气温在-35~36℃,平均气温 8.3℃,全年降水量 500mm,无霜期 183d[8]。沈阳市区总面积约 1.3×104km2,2017年沈阳市统计年鉴显示,沈阳市耕地面积约为6.83×103km2,主要粮食作物为粳稻,一年一熟制。
1.2 数据源及预处理
本研究在综合考虑研究区域覆盖范围、影像空间和时间分辨率等条件下选择了中高分辨率Landsat 8 OLI影像数据源,该影像能够提供16d重返周期和最高15m空间分辨率多光谱影像,覆盖9个波段[9]。选取的卫星影像获取时间分别为2017年5月23日、8月7日、9月24日,对应粳稻的移栽期、抽穗期和成熟期。因研究区跨度较大,每个物候期需2景共6景影像(条带号:119-30,119-31),选取影像时,为确保影像质量应将云量控制在10%以内。2017年5月,在研究区开展了野外实地调查。根据研究区土地利用背景数据等先验知识,利用手持GPS采集了研究区粳稻和其他地物类型的控制点信息,并将样本控制点数据通过ARCGIS软件绘制出矢量图层(图1),以便后续分类研究使用以及分类精度检验;在ENVI软件中对原始影像进行辐射定标、大气校正、镶嵌和裁剪[10],得到研究区遥感影像(图2)。
1.3 研究方法
1.3.1 分类指标选择 不同光谱组合而成的植被指数在一定条件下能够反映不同植被类型的物候差异和光谱特征,因此在农业遥感领域被广泛应用[11]。在粳稻大多数生长期中,遥感获取的稻田反射光谱信息是粳稻秧苗、陆地表面水体及其他植被的混合光谱信息,因此,本研究选取对植被、植被水分及土壤湿度敏感的3种植被指数作为分类指标,分别为归一化差值植被指数(normalized difference vegetation index,NDVI)(式 1)[12]、增强型植被指数(enhanced vegetation index,EVI)(式 2)[13]和陆表水分指数(land surface water index,LSWI)(式3)[14]。经过长期实践证明,NDVI植被指数在不同地物中的分类应用效果较好,能够较好的区分植被与非植被,可应用于本研究的粳稻与非植被覆盖区的区分;相比NDVI、EVI指数对土壤和气溶胶的影响更不敏感,在植被覆盖度高的地区也更不易饱和,因此EVI适合监测生长期叶面积指数较高的粳稻;由于稻田的多数时期都灌溉水,土壤湿度较高,因此需构建对土壤湿度较为敏感的植被指数,LSWI指数包含对植被的水分含量和土壤湿度都较为敏感的短波红外波段的反射率,可用于区分粳稻与其他作物种植区。

式中:ρBLUE、ρRED、ρNIR、ρSWIR分别为蓝波段、红波段、近红外波段、中短波红外反射率,分别对应 Landsat 8 OLI数据的第2,4,5,6通道;L为土壤调节系数,本研究取1。

图1 研究区主要地物样本点分布Figure 1 Location of main feature sample points in the study area

图2 研究区5月原始影像Figure 2 Landsat 8 image of the study area in May
纹理特征体现了像素及其周围空间领域的灰度分布,常被用来辅助遥感影像的地物分类,提高分类精度[15],本研究所用纹理特征是基于统计方法的灰度共生矩阵(grey-level co-occurrence matrix,GLCM)[16]。粳稻的生长期纹理特征较明显且不同时期特征值表现不同,而非植被区不同时期的纹理特征变化不明显,因此通过构建不同时期的纹理特征有助于粳稻分类。对研究区8月和10月影像进行正向主成分分析(principal component analysis,PCA)提取主成分波段,发现8月第一主成分信息量为99.06%,10月第一主成分信息量为98.49%,第一主成分基本涵盖了影像的全部信息量,因此本研究利用GLCM对8月和10月第一主成分进行纹理提取,获取其对比度(Contrast)、信息熵(Entropy)和自相关(Correlation)3个纹理特征,计算公式为:

式中:p(i,j)为影像的灰度值为i和j的两个像素点出现的次数。
由于不同地物在不同时相辐射的波段值存在差异性,因此不同时相影像的波段差值特征有助于地物的分类研究,对研究区粳稻抽穗期和成熟期影像的原始光谱波段进行差值处理,分别求出两个时相对应7个波段的差值特征,并利用ISODATA非监督分类算法[17]多次迭代得到波段差值合成影像的分类结果,并将该结果作为分类指标。因此,通过构建不同时期植被指数、纹理特征、非监督分类数据及原始波谱特征的多特征数据集进行粳稻分类研究,保证了粳稻分类信息量的充分,也提高与其他作物的可区分度。
1.3.2 主要分类方法及精度验证 决策树(decision tree)[18-19]是基于遥感影像及其他空间数据,采用自顶向下的递归方式,在其内部节点进行属性值的比较,根据不同属性值判断从该节点向下的分支,最终在其叶节点得到结论。从决策树根节点到叶节点的一条路径就对应着一条规则,其是影响分类精度的重要因素,分类和回归树算法(classification and regression trees,CART)[20-21]可以通过选取的地类样本自动获取规则,且可结合专家知识,很大程度提高规则建立的效率和精确度。BP神经网络[22-24]是一种多层前馈及误差反向传播的学习算法,通过周而复始的信息正向传播和误差反向传播得到最优的网络权值、阈值及可接受的输出误差。BP神经网络的设计包括输入层、隐含层和输出层节点数的确定,隐含层层数的确定。本研究中输入层节点数是根据各组多特征数据集中参与分类的特征参数个数而定;隐含层神经元个数需通过多次试验确定;输出层节点数根据分类地物的类型数目确定,本研究通过实地调查,将研究区的分类系统确定为粳稻、其他作物、水体、建筑和裸地5大类,因此输出层神经元个数为5个;有研究表明,一个3层BP网络可以映射出任意的非线性关系,所以本研究取3层BP神经网络。本研究基于实地控制点数据选取验证样本集,通过混淆矩阵计算总体分类精度和Kappa系数[25],综合验证基于CART算法构建的决策树和BP神经网络结合的分类法的可行性。
1.3.3 训练样本选取 通过实地调查,将研究区地物确定为粳稻、其他作物、水体、建筑和裸地5大类。在遥感影像分类中,训练样本的好坏对分类结果影响较大,因此,本研究参考Google earth和实地采集的控制点信息提高训练样本的精确性、代表性,最后利用变换分散度(Transformed divergence)和J-M距离(Jeffries-Matusita)[26]来计算每类训练样本的可分离性,若两类地物之间的可分离性大于1.9,则训练样本达到分类要求;若小于1.8,应重新获取训练样本;若小于1,考虑进行样本的合并,反复提取直至可分离性达到标准[27]。研究区粳稻与其他地物的分离性如表1。

表 1 研究区粳稻与其他地物可分离性Table 1 Separability table of japonica in the study area
根据选取的合格样本集提取植被指数特征,用于CART算法训练地物分割阈值。由于MATLAB的输入数据需保证是矩形,因此本研究利用ENVI平台的矩形ROI工具选取了5类地物的感兴趣区,并裁剪出每类地物的ROI区域作为BP神经网络分类的训练样本。
2 结果与分析
2.1 光谱特征分析及CART决策树分类结果
通过波段运算提取出5月研究区NDVI、EVI和LSWI光谱特征影像,并统计出每类地物的植被指数变化范围(表2)。由表2可知,粳稻的 NDVI值基本稳定在0.4,EVI值大于0.8,小于0.9,LSWI值介于0.1至0.6之间,由于移栽期稻田含水量高,引起光谱反射率变换导致LSWI值较高于NDVI值,3种植被指数的分布范围与其他作物的指数值均可区分;水体的NDVI和EVI值均在0以下,LSWI值大于0,易于区分;建筑与裸地的NDVI和EVI均小于0.1,与其他3类地物区分明显。

表 2 地物植被指数变化范围Table 2 Characteristics of NDVI、EVI and LSWI for major objects
由于本研究区域较大,因此选取沈阳农业大学道南、辽中和沈北新区粳稻种植区作为代表区域获取CART算法训练样本,训练分类规则并将其应用于整个图像,从而初步提取出各地物大致分布区域。基于CART算法获取的规则树如图3,训练共构建11条知识规则,其中区分粳稻与其他地物的规则有两条,分别为:(1)LSWI大于 0.2,NDVI大于 0.08,LSWI大于 0.33;(2)LSWI小于 0.2,NDVI小于 0.52 大于 0.05,EVI大于0.85。训练得到的分割阈值与表2的研究区粳稻植被指数分布范围基本相同,因此基于CART算法获取的粳稻种植代表区域分类规则具有实际意义,可用于整个研究区粳稻的分类识别。

图3 决策树分类规则Figure 3 Decision tree classification rule
初步提取的粳稻种植区局部数据如图4,可看出部分粳稻和水体被误分,连续的粳稻种植区中出现较明显“椒盐”现象。5月份是粳稻生长的移栽期,禾苗较小,稻田含水量较高,此时遥感获取的稻田反射光谱信息包含陆表水体信息、粳稻秧苗信息和其他地物信息[28],因此移栽期获取的3种植被指数信息是混合光谱信息,导致粳稻和水体的错分率升高,“椒盐”现象问题明显,且水生植被区易被错分为稻田种植区域,所以单时相影像提取的稻田信息误差较大,需结合作物其他生长期光谱、纹理等特征进一步提取。

图4 基于CART算法的决策树初步分类结果局部数据Figure 4 Local classification data of decision tree based on CART algorithm
2.2 基于CART决策树和BP神经网络的分类结果与精度评价
为进一步去除决策树初步提取的粳稻种植区中永久水体、其他地物和水生植被区域,以及减少粳稻与其他地物被错分的情况,本研究结合粳稻抽穗期和成熟期的特征对其初步种植区进一步细分。具体做法是对初步分类结果进行聚类处理得到更加连续的稻田区,通过波段运算提取出稻田位图和其他地物图,将稻田位图分别与8月和10月影像的7个波段进行波段运算,重新生成14个波段,每个波段都去除了非稻田信息,最后将两个不同物候期的14个波段进行波段合成,得到下一步待分类影像,提取其分类特征,并设计5组不同特征组合分类数据集,分别为原始光谱特征、光谱+植被指数特征、光谱+纹理特征、光谱+ISODATA分类数据、光谱+植被指数+纹理特征,采用BP神经网络算法分别对5组特征数据集进行分类,得到稻田进一步细分结果,并分别结合决策树提取的其他地物图得到最终分类结果。各组试验最终分类结果的部分地区分类影像数据如图5,可看出原始光谱引入不同时相特征后分类结果中的“椒盐”现象均有所改善。
采用实地调查样本数据点进行粳稻分类精度验证,各组试验提取的粳稻面积和分类精度对比数据如表3。由表3可知,基于单时相数据源,采用CART决策树初步分类效果较多时相分类效果差,单时相影像中存在许多“同物异谱”现象,而多时相遥感影像可显著提高分类精度,总体精度从76.6%提高到89.1%,Kappa系数从0.748提高到0.881;原始光谱特征单独引入不同时相的植被指数特征、纹理特征、非监督分类数据,分类效果均得到不同程度的改善,说明多特征综合比单一特征的分类效果更好,其中植被指数特征对粳稻分类的贡献作用最显著,而非监督分类数据的贡献效果一般。考虑研究区域范围较大,本研究采用30m中等分辨率的遥感数据源,其纹理特征不如高分辨率影像明显,且纹理特征易受光照等外界环境因素的影响,一定程度上使加入纹理特征的分类效果没有植被指数效果显著;而光谱特征中引入植被指数、纹理特征的分类精度低于单独引入光谱特征的分类精度,表明特征参数过多,参数间相关性较强,导致分类精度的降低。结果表明,基于多时相原始光谱和植被指数的多特征数据集的分类效果较好。

图5 各方案部分地区分类影像数据Figure 5 Local classification data of each experiment
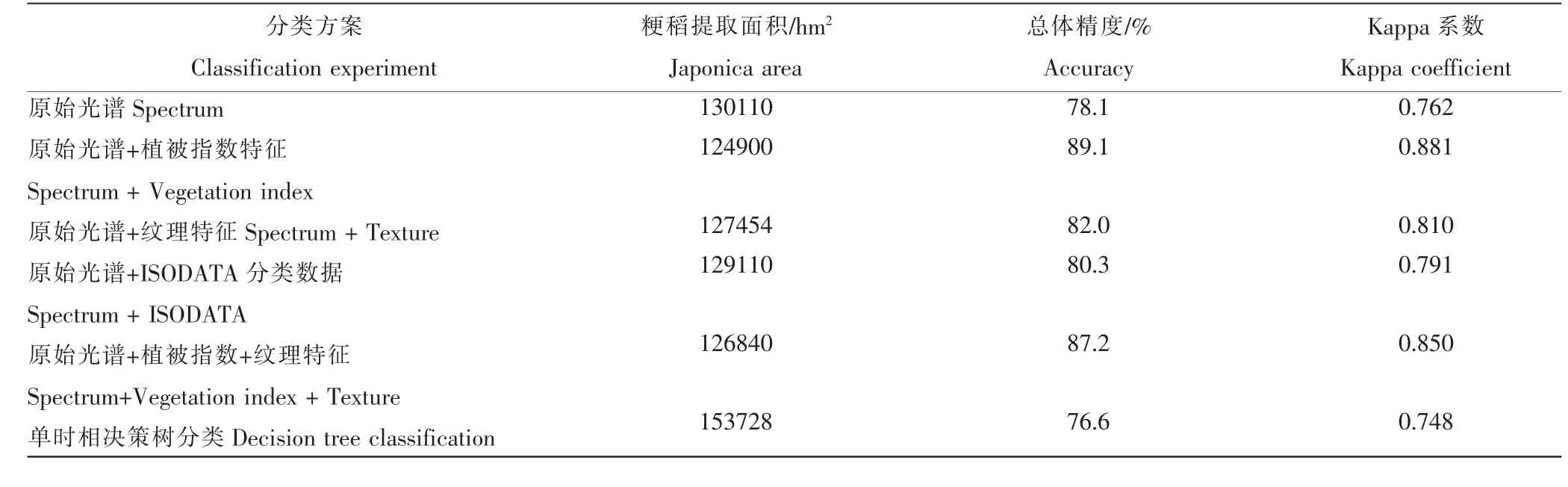
表 3 各分类方案提取的粳稻种植面积及分类精度对比Table 3 Japonica planting area and classification accuracy of each experiment
应用BP神经网络和最大似然分类法分别对多时相原始光谱和植被指数综合数据进行分类提取,得到研究区粳稻面积及分类精度对比数据如表4。由表4可知,采用CART决策树和BP神经网络结合的分类法可以获得较高分类精度,总体精度为89.1%,Kappa系数达到0.881,证明该分类法对Landsat 8 OLI影像的粳稻分类识别具有一定的区域应用价值。
由图6知,沈阳市的粳稻种植主要分布在辽中、新民,沈北、于洪及苏家屯区,少量分布在康平和法库地区,空间分布与沈阳市粳稻种植实际情况相符。

表4 3种分类法提取的粳稻面积及分类精度对比Table 4 Japonica planting area and classification accuracy of three experiments

图6 研究区粳稻种植空间分布Figure 6 Spatial distribution of japonica planting in the study area
3 讨论与结论
由于粳稻生长期多云雨,部分地区受天气影响,造成缺乏完整的作物生长发育期影像数据,使得吴静等[29]这种基于完整时序数据提取作物物候特征的分类研究具有局限性;由于遥感领域小样本特性,使得张佳滨[30]这种基于深度学习模型的分类研究易产生过拟合现象。因此,本研究在小样本条件下,基于传统的机器学习方案提出一种新的分类思想,利用传统CART决策树和BP神经网络,对其复合模型进行研究区粳稻分类研究和精度评价,该方法一定程度克服数据源缺失的问题,也为小样本遥感数据分类提供新思路。
本研究以多景粳稻关键物候期Landsat 8 OLI影像为数据源,综合多时相植被指数、纹理特征、非监督分类数据及原始波谱特征,结合CART算法构建的决策树初步分类结果,利用BP神经网络算法实现了研究区粳稻的分类识别,总体精度和Kappa系数分别为89.1%和0.881。最终结果表明,根据粳稻不同物候期的差异性选取不同分类指标和分类方法,既保证了充足的粳稻分类信息量,也提高与其他作物的可区分度;基于CART算法构建的决策树和BP神经网络相结合的复合模型,能够综合利用两种分类法的优点,提高分类精度;采用多时相粳稻物候期NDVI、EVI、LSWI和原始波谱特征的多特征数据集,改善了“椒盐”现象,一定程度解决了“同物异谱”问题,也有效提高研究区粳稻的分类精度。本研究思路一定程度上克服了粳稻遥感识别中单时相的“同物异谱”问题,同时也很大程度解决了识别特征单一的不足,说明了多时相多特征综合在Landsat 8 OLI遥感影像的粳稻分类识别中的重要性,证明了CART决策树和BP神经网络结合的分类法在粳稻分类研究中的可行性,为基于传统机器学习模型的作物关键物候期中等分辨率遥感影像分类识别提供一条新思路。但本研究方法目前对大片种植的沈阳粳稻识别效果较好,而对于南方的破碎斑块状稻田的识别效果还需进一步验证。
猜你喜欢
今日农业(2021年15期)2021-10-14
农民致富之友(2020年32期)2020-12-03
成都信息工程大学学报(2019年3期)2019-09-25
农业机械学报(2019年6期)2019-06-27
水土保持研究(2018年5期)2018-10-12
电子制作(2018年16期)2018-09-26
中国农业信息(2018年2期)2018-07-28
河南农业(2017年7期)2017-07-25
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
浙江农业科学(2016年11期)2016-05-04
