
利用大数据编制CPI代表性项目抽样方法研究
2020-04-27 05:21:56李绍泰刘建平
统计与信息论坛 2020年3期
李绍泰,刘建平
(1.中共临海市委党校 科研室,浙江 临海 317000;2.怀化学院 商学院,湖南 怀化 418000)
一、引 言
大数据为CPI(消费者价格指数)编制带来了新机遇,如何利用价格大数据改进CPI编制的理论和方法成为经济统计领域的研究热点。价格大数据中的超市扫描数据、电商数据、通信账单数据等电子数据是新的统计数据来源,是目前少数几个具备操作性和实用性的大数据类型,在改进CPI编制上拥有巨大应用前景。
1993年Diewert第一次提出了可以利用扫描数据编制CPI[1]。1995年Silver使用彩电扫描数据编制了基本分类指数,证明了扫描数据能够适用于传统的编制公式[2]。从1995年开始研究扫描数据编制CPI的学者逐渐增多,研究内容更加详细具体。在大数据中针对权数确定和代表性商品抽样的研究文献不多。权数反映了商品或服务的相对重要性,Haan等利用荷兰的咖啡扫描数据开始尝试在编制公式中使用权数,结果发现使用未加权的月度价格公式会导致价格指数被低估[3]。各国在实践中都有一套自己的编制方法,荷兰采用排除抽样选择代表性项目编制指数,瑞典采用与规模成比例概率序列抽样[4-5]。抽样得到的代表性商品可能会出现价格缺失,需要进行质量调整,Silver等使用时间虚拟变量特征法、最优的精确特征指数、匹配法三种方法测量质量调整的价格变化,认为特征法是最好的选择[6-7]。Haan探讨了特征指数的调整方法,指出对于不加权的特征指数,时间虚拟法和特征虚拟法都能使匹配项目不受影响[8]。之后,国外学者的研究重点逐渐转向解决链指数产生的偏离、缺失项目的替代上,Haan提出使用Lloyd-Moulton优指数,该指数能降低链偏离,但不能消除[9]。直到Ivancic等提出滚动年GEKS方法(RYGEKS),该方法保留了GEKS多边指数的优点,在公式中运用Fisher理想指数,能够免受链偏离的影响,且省去了要不断修正前期数据的麻烦[10]。因此,这个指数产生后,被作为一个基准指数,荷兰、挪威等国家的统计部门将本国扫描数据编制的指数与它进行比较,并尝试改进本国的编制方法,都取得了很好的效果[4,11]。为提高编制结果的准确度,很多学者提出了新的指数公式,如Imputation Törnqvist RYGEK[12-13]、CCDI index[14]、imputation CCDI index[15],但未被统计机构正式采用。目前已有荷兰、挪威、瑞士、瑞典、比利时、丹麦和新西兰等国家正式利用大数据编制CPI[16-17]。在中国,这方面的研究较少。陈相成等介绍了国外研究扫描数据的成果和应用经验[18]。李绍泰等利用Jevons和Törnqvist公式编制奶酪和啤酒基本分类指数,将编制结果与RYGEKS基准指数进行了比较,认为Törnqvist链指数是更优的选择[19]。
本文从利用价格大数据的角度,提出改进CPI编制中代表性项目的抽样方法,针对“有价格大数据”和“无价格大数据”的基本分类,分别设计代表性项目的抽样方案和指数的编制方案,研究抽样和纳入所有项目编制的指数结果差异,证明在大数据中进行代表性项目抽样是可行的,分析不同抽样方法、不同指数公式对价格指数编制结果的影响,为利用大数据编制价格指数提供参考。
二、现行CPI编制存在的问题
(一)调查网点抽样框覆盖不全面,更新维护不及时
中国调查网点的抽取是以销售额或经营规模为标志,将抽样框中的企业从高到低进行排队,再使用等距抽样抽取规定的数量[20]。抽样框根据本地区的零售企业和农贸市场经营网点基本情况台账建立,不包括网上商户[21]。而这些网上商户,如天猫超市、京东超市、淘宝店等电商的销售额很大且所占比重逐年提高,不纳入调查必将影响价格的准确性。抽样框的更新维护只有少数地区做到按月进行,大部分地区一年进行一次,而抽样框的涵盖误差影响估计精度。
(二)代表规格品的选择靠人判断,容易出现偏差
国家统计局规定代表规格品要选择同类商品中“消费量大、质量好、货源稳”的商品。在实际操作中,确定调查商品的代表规格品往往依靠主管业务人员和价格工作人员的判断,极易出现选择偏差。代表规格品确定后,原则上一年不会更改[22]。而现如今,商品更新换代速度加快,特别是电子商品,采价员很难及时准确地掌握新商品的进入和旧商品的退出,导致规格品的代表性降低。
(三)采价模式僵化,不易捕捉价格变化
中国的采价制度采用定时、定人、定点的形式,由固定的采价员在每月固定的日期和时点到固定的调查网点采集商品或服务的价格[20]。“三定”原则是为保持价格的连续性和可比性,但也带来不少问题。采价员采集的价格是固定日期中某几个时点的价格,不包括销量信息,未能捕捉价格变化对销量的影响,特别是固定的采价时间不一定在商品促销期内,而在促销期内商品销量往往较大,这会严重影响商品价格的准确性。手持设备采集的商品价格,由于可能存在的折扣优惠,也不一定是商品的真实价格。
(四)权数调整频率低,不能及时调整权数偏差
中国价格指数编制的权数主要依据住户调查中消费支出资料确定,权数确定后,5年才有一次大的调整,而长时间保持固定,会导致权数偏差,使权数的可靠性和代表性降低。
三、利用大数据编制CPI与现行编制方法的区别
大数据拓展了CPI的数据来源渠道,为改革CPI的编制方法带来了机遇。利用大数据编制CPI方法主要体现在价格采集方式、代表性项目选择、权数构建、价格缺失的处理、质量变化的调整、价格指数计算等方面,与现行的CPI编制方法存在较大区别。大数据包含商户详细的商品销售额、价格和销量等资料,能从数据中选择销售额占比大的代表性项目,可从数据中构建各个层级的权数,能根据所有同类项目的价格变化对缺失的项目进行价格虚拟,并使利用优指数公式编制CPI成为可能。利用大数据编制CPI与现行编制方法的区别主要为以下四方面:
第一,编制顺序不同。现行的CPI编制方法中,价格指数的编制要事先确定代表性项目、权数,再确定调查网点,最后去采集价格。在大数据中,编制顺序发生了重大改变,首先要确定调查网点,再从调查网点中采集价格数据,最后从价格大数据中构建权数、确定代表性项目。
第二,代表性项目的抽样方法不同。目前大部分国家包括中国都采用代表性项目法。代表性项目法基于人的主观判断来选择代表性项目,会降低样本的代表性。在大数据中,不依靠主观判断来选择代表性项目,而是采用与大数据编制方法相匹配的排除抽样、与规模成比例概率序列抽样,这两种方法优势明显,都是基于项目的支出份额计算一个包含概率,项目的支出份额越大,入样的概率越高。
第三,权数来源不同。现行的编制方法中,商品基本分类的项目、基本分类及以上层级的权数构建主要来源于城乡居民家庭收支调查的消费资料。在大数据中,主要通过计算商品项目的支出份额来构建各个层级的权数。
第四,指数公式的选择不同。现行编制方法中,受人力、物力因素限制,每月采价次数有限,代表性项目通常只有几个价格数据,且不包括销量信息,因此在编制CPI时只能选择不加权的指数公式。大数据中,由商户每月将商品基本分类详细的项目价格、销量等电子数据发送至统计部门,统计部门能使用加权的指数公式甚至优指数来编制CPI。
四、代表性项目的抽样方法与指数合成
在实际操作中,并不是将所有的价格大数据都纳入到CPI编制中,而是采用抽样的方法从商品的基本分类中抽取一定的商品项目,主要基于以下三方面的考虑:
第一,商品基本分类中的项目存在大量销售期非常短或销量少的项目(非季节性商品),容易出现价格缺失,如果全部纳入,则需要花费大量时间来虚拟价格缺失值,反而会影响指数的准确性。
第二,商品基本分类项目支出的分布通常是高度偏斜的,相对少量的项目所占支出比重较大[23],将项目全部纳入指数编制不仅没有必要,还会增加时间成本,加重工作负担和降低效率。
第三,采用抽样方式编制的指数结果与包含所有项目编制的指数结果比较差异较小,且标准偏差在可控范围内,已经能够反映价格指数的变化趋势。本文的研究结果也证明采用抽样是可行的。
随着互联网、电脑设备的普及,基本上都能从电商平台或实体商户采集到各种类型的电子数据,即能够获得商户所经营商品的价格大数据,但是由于某些条件的限制,可能还存在一些无价格大数据的商品。因此,本文按是否拥有价格大数据,分别针对“有价格大数据”和“无价格大数据”的基本分类设计了代表性项目的抽样方案和指数的编制方案。
(一)“有价格大数据”基本分类的代表性项目选择
在现行CPI编制方法中,因先确定代表性项目及其权数,再确定调查网点,采价人员去确定的调查网点直接将采集的代表性项目价格传输给统计部门,商户及其经营商品基本分类项目的构成在编制过程中作用非常有限。在大数据中,由于编制顺序的改变,在采集价格和确定代表性项目前要先确定调查网点,商户的重要性显现,商户是价格数据的拥有者和提供者,商户提供的商品基本分类所有项目(包括代表性项目和非代表性项目)数据都在编制过程中发挥作用。商品或服务的价格由各个商户每月传输给统计部门,商品基本分类项目的抽样框根据商户发送的电子价格数据建立,权数的构建直接来源于商户提供的价格数据,代表性项目的选择是基于该项目在同类项目中所占的支出份额大小确定,因此非代表性项目价格数据对代表性项目的选择和权数的构建也有重要影响。
代表性项目是从项目所属的基本分类里抽取的,一个商户可能经营多个基本分类项目,一个基本分类项目的价格数据可能来源于多个商户。这与现行的编制方法有所不同,现行编制方法中一个基本分类中确定的代表性项目通常很少,且采集代表性项目价格的调查网点数量也只有几个。在大数据中不再根据代表性项目去选择调查网点,编制顺序的改变要求编制方法也要相应改变,应通过商户这个商品价格数据的载体来选择代表性项目。但是,各种类型的商户成千上万,且商户销售额的分布(与基本分类项目相似)也是高度偏斜的,没有必要全部调查,应抽取具有代表性的商户进行调查。针对有价格大数据的调查网点,先按商户主营业务所属的商品大类或中类将商户进行归类,同类商户按销售额从高到低排序,计算同类商户中各个商户所占的销售份额。同类商户中,可以设定合适的商户销售份额值,抽取销售份额最大的几个商户,使这些商户的累计销售份额超过设定的销售份额值。调查网点越多,价格的准确性越高,且有价格大数据的商户不需要进行人工采价,因此可以适当地提高商户销售份额的设定值,以抽取更多的同类型商户。商户抽样是实施项目抽样的前提,抽取的商户越多,所得到的商品基本分类项目越齐全,越能反映项目的价格变化。
1.抽样框的构建和维护。被抽中的商户每月定期将所有商品基本分类项目的价格、销量等资料发送给统计部门,统计部门将各个类型商户的所有价格数据按基本分类进行汇总,在此基础上建立有价格大数据项目的总体抽样框。若项目出现永久性价格缺失,则寻找相似的项目进行替代;若项目出现暂时性的价格缺失,根据所有同类项目的价格变化对缺失的项目进行价格虚拟。
2.代表性项目的抽样方法。代表性项目的抽样方法有概率抽样和非概率抽样。概率抽样常用的方法是与规模成比例的概率抽样,瑞典与美国使用较多;非概率抽样中常用方法包括排除抽样、定额抽样和代表性项目法[24]。荷兰使用排除抽样,大部分国家包括中国采用代表性项目法。代表性项目法基于人的主观判断,不易及时发现新商品的进入和旧商品的退出,会降低样本的代表性。定额抽样也是基于个人判断来选择代表性项目,且无法确定估算值的标准误差。
在大数据中,采用与规模成比例概率序列抽样和排除抽样优势比较明显,但哪种方法更适合,则需要进一步验证。因此,本文利用奶酪和啤酒两个基本分类项目的扫描数据进行实证分析。
(1)排除抽样
排除抽样指事先设定一个阈值,选择超过这个阈值的na个最大的抽样单位,并排除剩余的抽样单位。商品基本分类项目的支出是高度偏斜的,使用排除抽样必定会纳入支出份额大的重要项目,而支出份额小的项目通常会被排除。具体的计算方法如下:


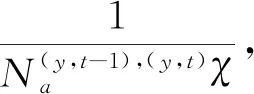
(2)与规模成比例概率序列抽样法
与规模成比例概率序列抽样也是选择支出份额大的重要项目,但选择方法与排除抽样不同。与规模成比例概率序列抽样要先根据层的支出份额大小确定各层拟分配的样本量,层内的项目都要计算一个包含概率,包含概率公式为:
(1)

序列变量计算公式如下:
(2)
其中,Rhi为每个项目设定的永久随机数,服从(0,1)均匀分布。项目按层h和序列变量Qhi进行升序排序。在价格采集时,每一层前nh种项目被选入样本[5]。
(二)“无价格大数据”基本分类的代表性项目选择
“无价格大数据”的基本分类表示该基本分类中所有项目或大多数项目无价格大数据。现行的CPI编制方法中,即无价格大数据时,采用代表性项目法,选择同类项目中“消费量大、质量好、货源稳”的具体项目,价格指数的编制要事先确定代表性项目,再确定调查网点,最后去采集价格。此时分成两种情况处理:
第一,采集价格时发现事先确定的代表性项目无价格大数据,但该基本分类中少量项目有价格大数据,且这些项目具有替代性,则选择有价格大数据的相似项目采集价格,不再调查原先确定的无价格大数据的代表性项目。
第二,如果同类项目中不存在拥有价格大数据的可替代项目,则人工采集事先确定的代表性项目的价格,同一规格品至少要从两个调查网点采集价格。
(三)权数的确定
1.无价格大数据时,基本分类及以上层级的权数构建主要来源于城乡居民家庭收支调查的消费资料。
2.在大数据中,基本分类项目的权数根据该项目的消费支出在同类项目总支出中所占的比重来获得;基本分类层级的权数根据该基本分类在所属细类总支出中所占的比重来构建;基本分类层级以上的权数,即大类、中类、小类和细类的权数等于其对应分项的权数总和,如大类的权数等于其对应的各个中类的权数加总。
3.若一个基本分类中部分项目有价格大数据,部分项目无价格大数据,则略去无价格大数据的项目,只计算有价格大数据项目的权数,按大数据中的方法进行确定;若一个细类中,部分基本分类无价格大数据,部分基本分类有价格大数据,则基本分类层级的权数需要根据价格大数据、城乡居民家庭收支调查资料综合衡量后确定;基本分类以上层级若出现同样情况,也要综合考虑。
4.基本分类层级及以上的指数加总采用的权数是基于基本分类所有项目的年度支出,无论这个项目是否被选中为代表性项目,权数在每年12月重新构建。
(四)指数的合成
对于“有价格大数据”的基本分类,基本分类指数按照代表性项目的价格进行计算。对于“无价格大数据”的基本分类,基本分类指数的计算分两种情况处理:
第一,如果基本分类抽中的代表性项目无价格大数据,但该基本分类中存在少量能采集到价格大数据的可替代项目,则选择同类项目进行替代,基本分类指数按照价格大数据的方法选择指数公式计算,更高层级的指数按照层级逐次向上加权汇总。
第二,抽中的代表性项目无价格大数据,且基本分类中也不存在有价格大数据的可替代项目,则该基本分类指数使用人工采集的代表性项目的价格进行计算。“有价格大数据”的基本分类和“无价格大数据”需人工采价的基本分类向更高层级的指数进行合成时,基本分类、细类、小类、中类的权数已于前一年的12月确定,因此采集的项目价格只需按公式向上逐级加权。
五、实证分析
分别使用排除抽样、与规模成比例概率序列抽样两种方法对奶酪和啤酒基本分类的扫描数据观察值进行抽样,研究抽样和纳入所有项目编制的指数结果差异、在大数据中进行代表性项目抽样是否可行,探讨抽样方法的不同对指数编制结果的影响,以选择在大数据中更优的抽样方式。奶酪和啤酒的价格数据来源于美国多米尼克数据库,奶酪共有 917.5万条观察值,啤酒有38.5万条观察值。在计算时将4个星期作为1个月处理,奶酪和啤酒扫描数据各自包含36个月的数据。根据项目的规格(按重量或容量划分)进行分层。先使用排除抽样法确定样本总量,χ值越大,则阈值越小,入选的项目数越多。但是,项目的支出是高度偏斜的,当入选项目达到一定的数量后,通过增加入选项目来使支出份额增长的作用不再明显,且还会增加成本、加重工作负担。荷兰统计局经过反复试验发现设定χ=1.25最好,本文使用χ=1.25是因为该设定值经过验证,且在奶酪和啤酒基本分类中抽样效果较好,奶酪和啤酒入样项目数量适中,数量占比分别为44.1%和33.9%,但入样项目的平均支出份额超过了80%。出于方法比较的目的,与规模成比例概率序列抽样的样本总量为排除抽样确定的样本总量,按照各层的支出份额分配样本量。
(一)抽样结果的比较
奶酪扫描数据共有28种规格、331个项目。应用排除抽样共抽取146个项目,这些入选项目归属于18种规格,即有18种规格至少存在1个项目入选;应用与规模成比例概率序列抽样共抽取146个项目,归属于19种规格。啤酒扫描数据共有23种规格、310个项目。应用排除抽样共抽取105个项目,归属于6种规格;应用与规模成比例概率序列抽样共抽取105个项目,归属于11种规格。奶酪和啤酒排除抽样设定的阈值分别为0.258%和0.242%,如果某个项目的平均支出份额超过对应的阈值,则选入样本。与规模成比例概率序列抽样先计算包含概率,如果某个项目的包含概率大于1,则直接选入样本,如果小于1,则根据序列变量大小进行升序排序,选择序列变量值最小的nh个项目入样。
通过入选项目的比较,可以发现两种抽样方法的不同。第一,与规模成比例概率序列抽样入选样本的层数(规格数)要比排除抽样多。排除抽样是基于层内某个项目的平均支出份额是否超过阈值,超过则入选,不受层支出份额的影响;与规模成比例概率序列抽样是先根据层的支出份额计算该层应分配的样本量,只要层的支出份额足够大,分配到的样本量大于等于1,则该层就会有项目入选,入选的项目数等于分配的样本量,无论这些项目是否超过阈值,这与排除抽样不同,因此与规模成比例概率序列抽样入样的层数覆盖更多。
第二,与规模成比例概率序列抽样的某些层出现了需要超过100%抽样的情况。有些层的支出份额大,按支出份额计算拟分配给这些层的样本量大于层包含的项目数,此时这些层需要超过100%的抽样。实际操作中,对这些层进行100%抽样,再将剩余的待分配的样本量在其他层内进行分配;而排除抽样则不会出现上述情况。
(二)指数编制结果的比较
传统的基本分类指数公式的选择上,因为缺少代表性项目的权数信息,一般使用Jevons指数。当前几个正式使用大数据编制价格指数的国家都选择月度链指数,月度链指数指通过将环比指数连乘,链接到特定时期得到的指数。循环性检验指两个时期之间的链指数等于这两个时期的定基指数,如:通过环比指数逐期相乘得到的链指数P0,3=P0,1×P1,2×P2,3与第3期对0期的定基指数相等,则满足循环性检验;如果不满足,则产生了链偏离。荷兰、瑞典和瑞士使用Jevons链指数。Jevons链指数不加权,能有效避免链偏离,但在价格大数据能给出项目层级权数的情况下,不进行加权是对数据的一种浪费。挪威则使用了优指数——Törnqvist链指数。国际CPI手册指出,当有详细的价格和数量信息可用时,优指数是最佳的选择[25]。但是,当时期间存在大的价格和数量波动时,使用链式优指数可能会导致链偏离。RYGEKS指数具有良好的指数特性,能通过循环性检验,在匹配项目中能防止链偏离,但这种方法也有缺陷,它忽略了不匹配项目,忽略了新项目与旧项目间价格变化的影响,因此这个指数只是被各个国家当作基准指数进行比较,并未在实际中采用该指数公式编制CPI[12]。在基本分类层级,这三个指数公式使用最普遍,有优点,也存在缺陷。本文选择了这三个指数公式进行抽样方法的比较,根据两种不同的抽样方式分别编制了Jevons指数、Törnqvist指数和RYGEKS指数,进行两个维度的比较:一是采用入样项目编制的指数与包含所有项目编制的指数进行比较,探讨不同的抽样方式但采用相同的指数公式对指数结果的影响;二是相同的抽样方式但采用不同的指数公式,探讨哪个指数公式编制的指数结果更加准确。
1.Jevons链指数的比较。Jevons指数的公式如下:
(3)

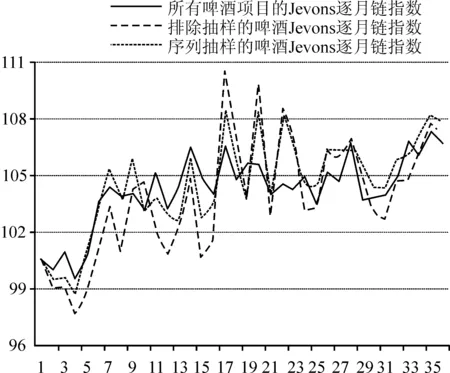
图1 不同抽样方式编制的Jevons逐月链指数
与包含所有奶酪和啤酒项目编制的指数相比,使用排除抽样、与规模成比例概率序列抽样两种抽样方式抽取的代表性项目编制的Jevons逐月链指数结果差异较大。排除抽样编制的啤酒Jevons逐月链指数与所有啤酒项目编制的Jevons逐月链指数每个月差值的平均值为0.37个百分点,每个月差值的标准差为1.08,都比与规模成比例概率序列抽样小;排除抽样编制的奶酪Jevons逐月链指数与所有奶酪项目编制的Jevons逐月链指数每个月差值的平均值为-0.44个百分点,标准差为2.30,与规模成比例概率序列抽样相比,都相对更大。
从总体上看,使用相同的指数公式,即Jevons指数公式,采用排除抽样、与规模成比例概率序列抽样两种抽样方式抽取的项目编制的价格指数与包含所有项目编制的指数比较走向不规则且差异较大,无法判断哪种抽样方式编制的效果更好。偏差大的原因主要在于Jevons指数公式。在采用抽样的方法选择代表性项目时,已将不符合入选标准的项目淘汰,在指数计算中,那些被淘汰的项目价格不会在指数中反映,但在编制纳入所有项目的指数中,原本在抽样过程中被淘汰的项目的价格被编制到指数中,增加了价格的波动性。且采用的Jevons指数公式未加权,支出份额小的项目和原本该被淘汰的项目价格变化的作用在指数编制中被放大,导致结果偏差增大,偏离比较明显。
2.Törnqvist链指数的比较。Törnqvist指数是优指数,挪威在基本分类层级选择了Törnqvist指数公式。Törnqvist指数公式与Jevons指数公式的差异主要在于指数是否加权。Törnqvist指数的公式如下:
(4)

Törnqvist逐月链指数的编制结果如图2所示。与包含所有项目编制的价格指数相比,使用排除抽样、与规模成比例概率序列抽样两种抽样方法编制的结果都存在较小的偏差,且趋势方向基本相同。
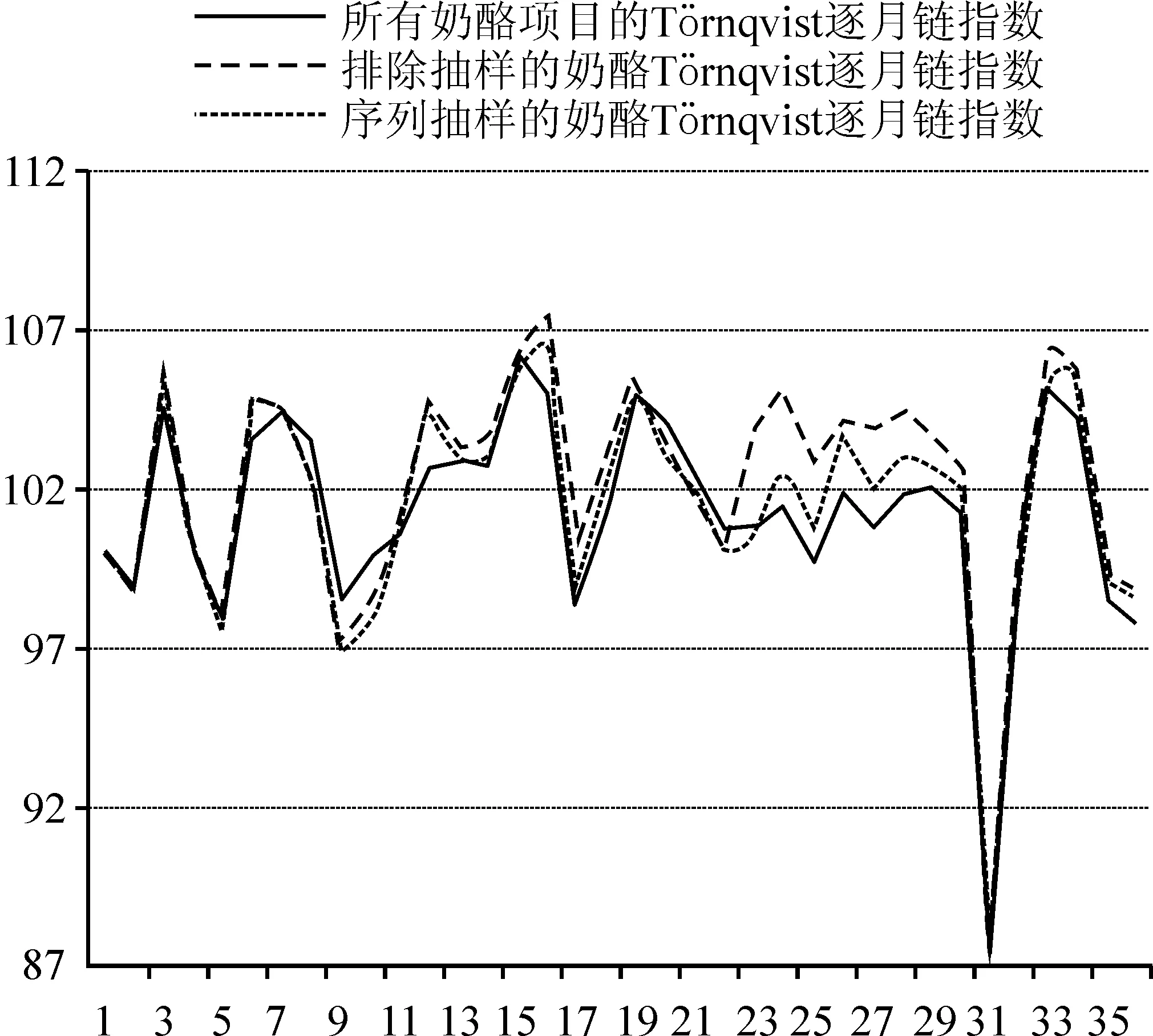

图2 不同抽样方式编制的Törnqvist逐月链指数
无论是啤酒基本分类还是奶酪基本分类,采用排除抽样编制的Törnqvist逐月链指数与包含基本分类所有项目编制的Törnqvist逐月链指数,每个月差值的平均值都比与规模成比例概率序列抽样的结果大,表明与规模成比例概率序列抽样编制的指数相对更好。
采用相同的Törnqvist指数公式,与规模成比例概率序列抽样编制的指数结果要比排除抽样更加准确,偏差更小。Törnqvist指数公式是加权的指数,与项目所在层的权数有关。与规模成比例概率序列抽样是先根据层的支出份额大小计算该层应分配的样本量,层中入选项目的加权平均价格更具有代表性;而排除抽样中项目是否入选与项目的支出份额有关,样本量的大小与层的支出份额关系不大。此外,与规模成比例序列抽样入选的规格数相对更多,因此更能反映价格的变化情况,指数的精确性相对更高。
3.滚动年GEKS指数(RYGEKS)的比较。GEKS多边指数是所有双边Fisher指数比率的几何平均值,GEKS指数的缺点是当有新时期的数据时,所有的前期数据必须要重新计算。RYGEKS指数克服了这个缺陷,不用修正前期数据,且保留了GEKS多边指数良好的循环性和传递性等指数特性[19]。RYGEKS指数能通过多期恒等性检验、时间逆检验和循环性检验,能够避免链偏离的影响[10],因此各国将RYGEKS指数作为基准指数,将各自编制的消费者价格指数与RYGEKS基准指数进行比较。
RYGEKS的一般表达式如下:
(5)
其中,Pt,τ表示时期t和τ间的一个价格指数。Ivancic等使用的是Fisher价格指数[10],不过在之后的研究中,Haan和Grient基于Törnqvist价格指数,荷兰统计局也是使用Törnqvist价格指数[11]。Törnqvist是优指数,具有良好的指数特性,所以本文也编制基于Törnqvist优指数的RYGEKS基准指数。
从图3可知,与纳入所有项目编制的指数结果比较,两种抽样方式编制的RYGEKS基准指数都存在上行或下行的偏差,但基本趋势相同,编制结果与Törnqvist逐月链指数相似。与规模成比例概率序列抽样编制的奶酪和啤酒两个基本分类指数分别与包含奶酪和啤酒基本分类所有项目的指数比较时,每个月差值的平均值和标准差都比排除抽样小,表明使用RYGEKS指数公式时,采用与规模成比例概率序列抽样方法更好。


图3 不同抽样方式编制的RYGEKS指数
通过与纳入所有项目编制的指数结果比较,发现使用与规模成比例概率序列抽样编制的Törnqvist指数和RYGEKS指数都相对更好。采用Jevons指数、Törnqvist指数和RYGEKS指数公式编制的两个基本分类指数结果中,无论采用哪种指数公式,使用两种抽样方式编制的奶酪基本分类指数间的差距都较大,而啤酒基本分类指数间差距都较小,这主要是受基本分类支出权数的集中度影响。集中度高的基本分类入选的规格数相对更少,支出权数集中在少数几个规格,这几个规格入选的项目相对较多,两种抽样方式抽取的项目重合率较高,因此两种抽样方式编制的基本分类指数间的差异较小。奶酪有28种规格,权数最大的4个规格所占的比重只有72.6%,相对比较分散。啤酒有23种规格,其中3种规格的权数已占所有项目的90%,集中度非常高。针对支出权数集中度低的基本分类,使用排除抽样产生的偏离较大,不是较好的选择。支出权数集中度高的基本分类使用排除抽样、与规模成比例概率序列抽样产生的偏离相差不大,但从总体上看,与规模成比例概率序列抽样偏离相对更小。
4.采用与规模成比例概率序列抽样的不同指数公式编制比较。采用相同的指数公式、不同的抽样方式比较时,发现与规模成比例概率序列抽样编制的指数偏差相对更小,因此在比较不同指数公式对编制结果影响时,采用了与规模成比例概率序列抽样。图4是各个指数的编制结果。从趋势图可知,Jevons逐月链指数与基准指数RYGEKS比较时,趋势走向不一致,存在较大的偏差。Törnqvist逐月链指数与基准指数RYGEKS比较偏差较小,且大部分月份的数据出现重合,只有最后3个月出现了偏离。这主要与基准指数公式中Pt,τ采用了Törnqvist指数有关。RYGEKS忽略了不匹配项目,忽略了新项目与旧项目间价格变化的影响,因此RYGEKS指数并不适合在实际编制中使用,Törnqvist指数公式是更优的选择。
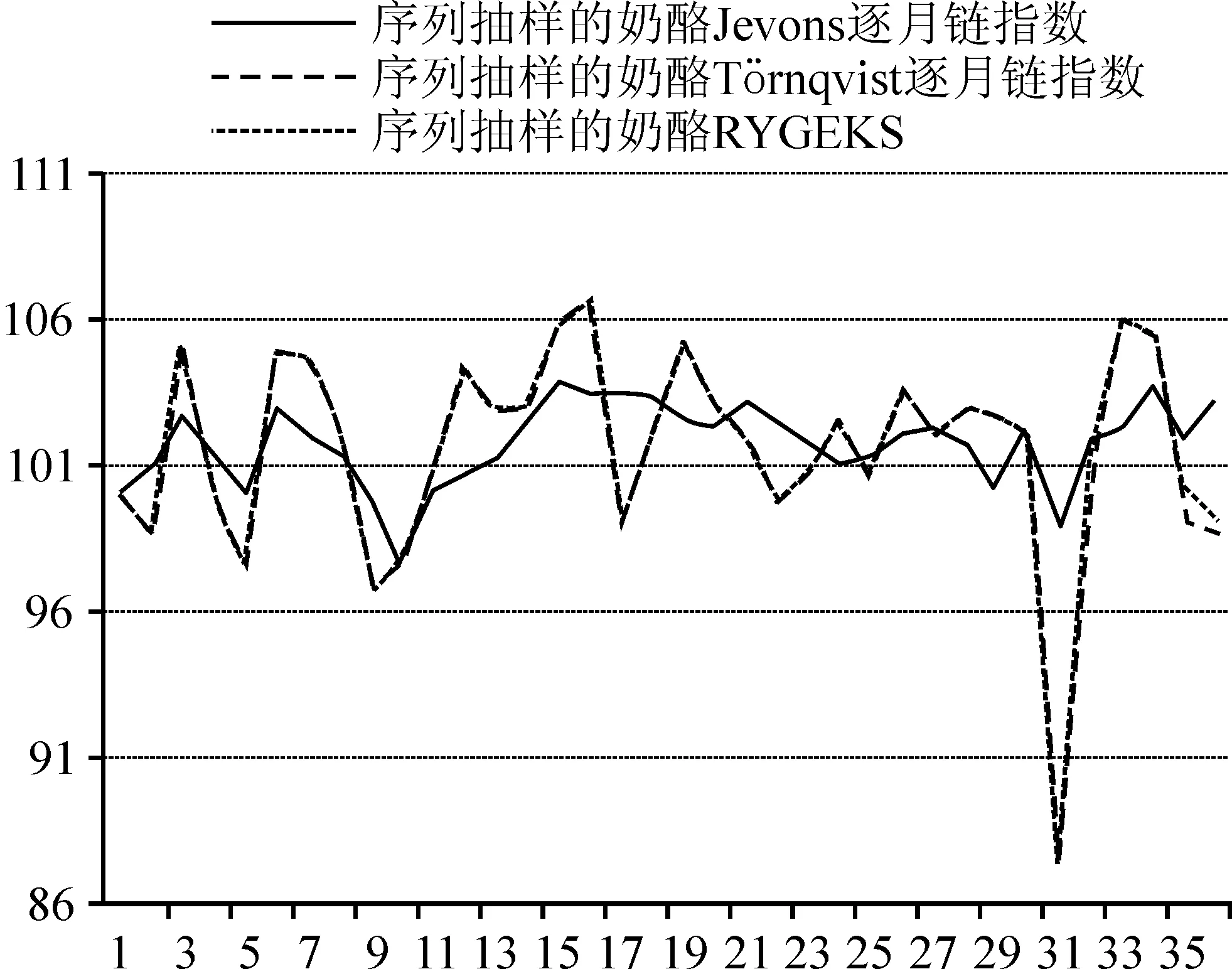

图4 同种抽样方式不同指数公式编制的指数
六、结 论
本文讨论了大数据中的不同抽样方式、不同指数公式对指数编制结果的影响。采用排除抽样、与规模成比例概率序列抽样方法编制了Jevons逐月链指数、Törnqvist逐月链指数和RYGEKS指数,并将抽选的代表性项目编制的指数与包含所有项目的指数进行比较,证明了在大数据中进行代表性项目抽样是可行的,结论如下:
1.代表性项目的选择。同与规模成比例概率序列抽样方式比较,排除抽样的代表性项目选择更加简单,操作更加方便。设定一个阈值,只要基本分类层级中项目的平均支出份额高于这个阈值,即被纳入样本,它的入选标准是统一的。而与规模成比例概率序列抽样则要先根据层的支出份额大小确定各层的样本量,层内要计算目标包含概率,若目标包含概率低于1,还要计算序列变量,操作相对复杂。各层间的包含概率是独立计算的,因此层间各个项目入选的标准是不统一的,但与规模成比例概率序列抽样能够控制每个规格(每层)的代表性项目入选的样本量,样本控制更加灵活;而排除抽样通过设定参数χ的大小,只能控制总样本量。在大数据中,如果由电脑系统设定程序自动完成,样本量的分配、包含概率和序列变量的计算都不需要人工操作,操作的复杂性不应该考虑,入选项目的代表性应该是主要因素,从指数的编制结果来看,与规模成比例概率序列抽样抽取的项目代表性更高。
2.支出权数。基本分类指数是编制价格指数中最基础也是最关键的环节。基本分类的支出权数对抽样方式的选择有一定的影响。支出权数集中度低的基本分类应该使用与规模成比例概率序列抽样,排除抽样编制的指数产生的偏离较大,不是一个较好的选择。支出权数集中度高的基本分类使用排除抽样、与规模成比例概率序列抽样产生的偏离相差不大,但从总体上看,与规模成比例概率序列抽样产生的偏离相对更小,是更优的选择。
3.指数公式的选择。其一,在采用相同的指数公式、不同的抽样方式比较编制指数结果的维度上,与纳入奶酪和啤酒两个基本分类所有项目编制的指数比较,使用排除抽样的Törnqvist逐月链指数和RYGEKS指数比与规模成比例概率序列抽样编制的指数偏差更大,因此对于加权的指数,采用与规模成比例概率序列抽样更好。其二,在采用不同的指数公式、相同的抽样方式比较编制指数结果的维度上,使用与规模成比例概率序列抽样编制的Jevons逐月链指数、Törnqvist逐月链指数与RYGEKS基准指数比较时发现,Jevons公式编制的逐月链指数与基准指数偏差较大且趋势不一致;Törnqvist逐月链指数偏差较小且趋势走向基本一致,很多时期还出现了重合,因此Törnqvist逐月链指数是更优的选择。
猜你喜欢
河北科技大学学报(社会科学版)(2022年4期)2023-01-06 12:39:34
中学生数理化·中考版(2022年6期)2022-06-05 06:49:10
中学生数理化·中考版(2021年6期)2021-11-22 07:52:30
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
闽南风(2020年6期)2020-06-23 09:29:01
统计与信息论坛(2020年5期)2020-06-03 06:57:04
中国现代中药(2020年2期)2020-04-29 08:01:04
证券市场周刊(2019年25期)2019-08-16 01:27:48
证券市场周刊(2019年26期)2019-07-20 10:00:48
