
基于迁移学习与RetinaNet的口罩佩戴检测的方法
2020-04-23 01:23:04邓黄潇
电子技术与软件工程 2020年5期
邓黄潇
(中国矿业大学计算机科学与技术学院 江苏省徐州市 221000)
人脸识别作为计算机视觉领域的最基本和最具挑战性的问题,近些年来取得了很大的成就,Viola 和Jones 提出了基于AdaBoost[1]的人脸检测算法。Chen[2]等人提出了RPN 网络和RCNN 网络。Le[3]等人提出了多尺度检测的Faster-RCNN 的方法。2017年,文献[4]提出了RetinaNet 网络,该网络利用了Focal Loss 函数成功控制了正负样本、难分易分样本产生的损失值,这使得one stage 目标检测模型在COCO 数据集上首次超过了当时最先进的two stage 目标检测模型的结果。
由此,本文希望通过利用RetinaNet 网络,来对复杂环境下佩戴口罩的人脸和未佩戴口罩的人脸进行识别检测。
本文选择ResNet101 作为迁移学习的BackBone,数据集来自WIDER Face 和MAFA 共计7959 张图片,将人脸目标分为两类,包括佩戴口罩人脸(face_mark)、未佩戴口罩人脸(face)。
1 RetinaNet网络
1.1 RetinaNet简介
RetinaNet 为何凯明和Girshick R 等人在2017年提出的通用目标检测网络,对于多尺度目标检测问题,该算法采用特征FPN(特征金字塔网络)来预测不同尺度的目标。对于检测样本图片中正负样本不均衡的问题,该算法采用Focal Loss 来代替交叉熵损失函数来提高检测精度。如图1 所示[4]。
Retinanet 由Backbone、FPN、预测结构构成,Backbone 主要作用是提取图像特征,FPN 主要用主网络提取的特征提高对多尺度检测精度的提高,预测结构用于生成包含目标的边界框。
1.2 Backbone
常用目标检测网络的Backbone 有VGGNet[5]、GoogleNet[6]、ResNet[7]等。VGGNet 通过叠加3x3 的卷积核来达到提取图像特征的目的,常用的是包含13 层卷积层与3 层全连接层的VGG-16。GoogleNet 基于Inception 模块构建基础结构,深度达到22 层,提取到的特征更为多样。
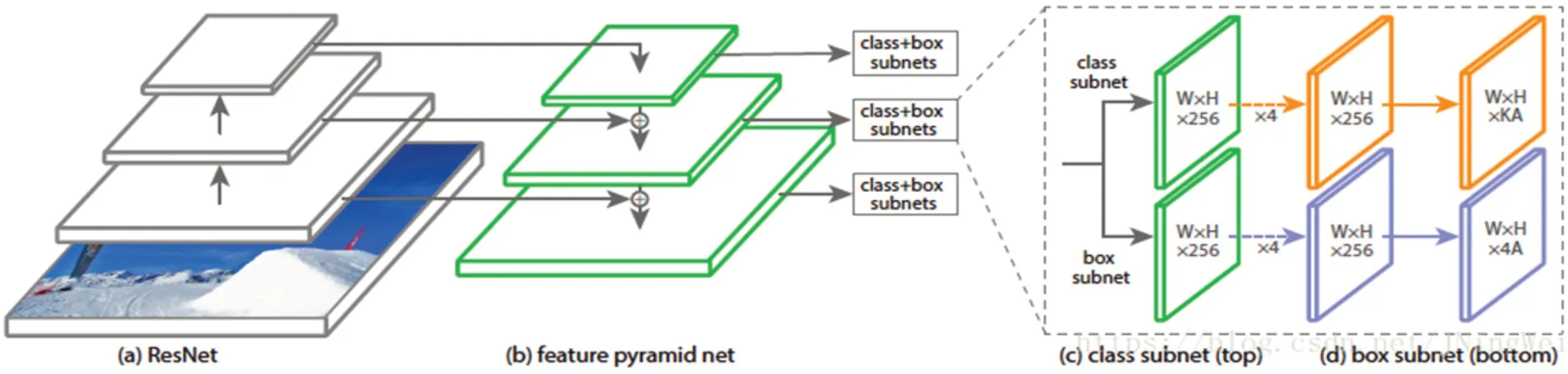
图1:Retinanet 结构
ResNet 基于ResNet 模块构建,因其具有跨层连接的特性,极大的减轻了梯度消失在深度神经网络中训练的问题[8],常用的ResNet 为ResNet50 与ResNet101。本 文 选 择ResNet101 作 为Backbone。
1.3 Focal Loss损失函数
一般分类问题采用交叉熵函数作为损失函数,表达式为式(1),该损失函数在图像分类中效果显著,但对于需要预选框的目标检测却效果一般。而Focal Loss 损失函数[表达式见式(2)]中的权重系数α 针对正负样本不均衡的情况,由于实际图片中包含目标的预选框非常少,大多数预选框并不包含待检测目标,而通过调整权重系数α,能有效解决正负样本损失值的比例问题。

1.4 FPN
针对图像底层特征语义信息少、高层语义信息多、目标位置粗糙的特点,FPN 通过自底向上、自顶向上、横向连接三个部分将不同层的特征图进行融合,使得小目标被易于检测。
自底向上是CNN 的前向传播过程。自顶向下过程采用上采样进行。横向连接将上采样的结果和自底向上的结果进行相加操作。这对单张图片能有效构建多尺度特征图,使FPN 的每一层均可以用于不同尺寸的目标检测。
2 试验研究
2.1 数据获取与标注
为了满足在复杂环境下对人脸是否佩戴口罩进行检测,本文采用WIDER Face 和MAFA 两个数据集7959 张图片。其中6067 张作为训练集,300 张作为验证集,1592 张作为测试集。数据集含有两类标签,分别是佩戴口罩的人脸(face_mark)与未佩戴口罩的人脸(face),并将其制作为PASCAL VOC2007 数据集格式。
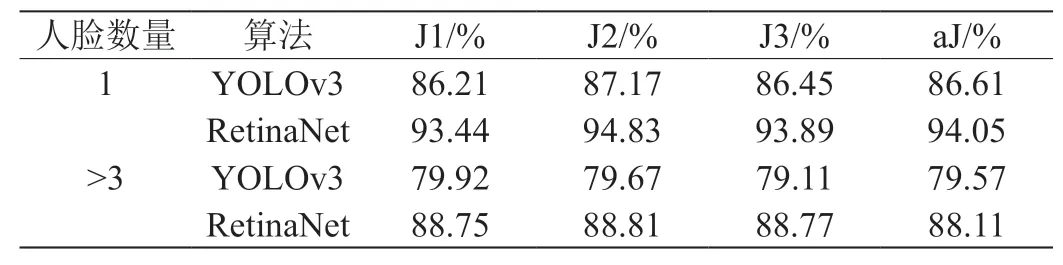
表1

表2

表3
2.2 试验平台
本文的试验平台的配置为Ubuntu18.04、CUDA10.0、cuDNN7.6.5、NVIDIA RTX2080Ti(11GB)。在此基础上使用keras 深度学习框架,并用Python 语言编程实现网络的训练和测试。
2.3 模型训练
对VOC2007 数据集进行训练之前,需要先将所有标签转化为CSV 文件,然后使用预训练好的模型初始化网络参数。初始化学习率设置为0.00001,训练300 轮。训练后在在验证集上的mAP 值为86.45%,平均检测一张图像的速度为233ms。
3 试验结果与分析
为了验证训练模型对于佩戴口罩的有效性,试验将与基于DackNet 的YOLOv3 的检测效果进行对比,比较两种种算法在复杂情况下的检测表现,并得出试验结论。
3.1 试验评价指标
由于需要直观的对识别结果做出评价,因此评价指标要同时考虑到准确率和召回率,设定 J 作为口罩佩戴识别结果的评价指标,J 为召回率与准确率的函数,定义如下式(3)。

式中:P——准确率;
R——召回率。
3.2 不同数目人脸检测的对比试验
在实际的检测中,由于一对一的检测将会耗费大量的时间,因此多数情况下将会有多人脸在一帧图像中同时进行检测,此时就会出现一些人脸轮廓不完整、人脸较小以及人脸之间存在遮挡的情况。由此设计了在不同人脸数目下检测结果的对比。未佩戴口罩人脸测试集下的检测效果图与原图如图3 所示[9],佩戴口罩的人脸测试集检测效果图与原图如图4 所示[9]。
从图3 可以看到,当检测单张人脸时两种算法的效果都很好,检测密集的多张人脸时虽然检测出的数量相差无几,但在检测精度上RetinaNet 明显领先YOLOv3,且数量也更为准确。从测试集中选取两种数目不同的含有人脸图像各20 张,分别用上述两种算法计算评价指标J 的值,并重复三次,求取J 值的平均值,可以发现RetinaNet 在检测密集的多张人脸上效果显著,J 值明显高于YOLOv3。结果如表1 所示。

图2:ResNet 模块

图3
从图4 可以看到,如同图3 的情况,在检测单一佩戴口罩的人脸时两种算法精度均很高,但在密集多人脸的情况下YOLOv3 表现明显不如RetinaNet。从测试集中选取两种数目不同的含有佩戴口罩的人脸图像各20 张,分别用上述两种算法计算评价指标J 的值,并重复三次,求取J 值的平均值,可以发现RetinaNet 在检测密集多张佩戴口罩的人脸同样更加出色,但在检测佩戴口罩的人脸的任务上两种网络都比检测未佩戴的口罩更加出色。结果如表2。
3.3 两种目标同时存在时的对比试验
在实际情况中戴口罩与不带口罩的人会同时出现在图像帧中,因此有必要测试当两类待检测目标同时出现时两种网络的检测效果,效果图与原图如图5 所示[9]。

图4

图5
可以看到,YOLOv3 不仅在精度上低于RetinaNet,同时对于像素值很小的人脸也不能将其识别出来,且在像素值很小时,还会错将佩戴口罩的人脸误识别成未佩戴口罩的人脸。从测试集中选取同时含有佩戴口罩和未佩戴口罩的人脸图像20 张,分别用上述两种算法计算评价指标J 的值,并重复三次,求取J 值的平均值,也能证明RetinaNet 比YOLOv3 出色,计算结果如表3。
4 结论
本文提出一种基于RetinaNet 的人脸口罩佩戴检测的方法,通过实验表明在复杂环境下该模型具有较高的精度与鲁棒性。通过迁移学习利用预训练的ResNet 模型来帮助新模型训练,经过GPU 加速训练后在验证集上的AP 值为86.45%,检测一张图片的时间为233ms。通过与目前流行的YOLOv3 模型进行对比,RetinaNet 也展示出了更好的检测效果。受限于数据集大小,以后将对现有数据集进行扩充,进行更深入的研究并与硬件设备相结合,为社会治安发挥应有的贡献。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
作文小学中年级(2020年6期)2020-07-24 08:33:10
意林(2020年9期)2020-06-01 07:26:22
海峡姐妹(2020年4期)2020-05-30 13:00:08
作文大王·笑话大王(2019年3期)2019-04-22 23:58:02
动漫星空(2018年9期)2018-10-26 01:17:14
作文评点报·低幼版(2017年8期)2017-03-11 20:44:08
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
