
网上数字档案大数据分析中的知识挖掘技术
2020-04-23 01:22刘禹辰程奕心许志伟宋姿颖
电子技术与软件工程 2020年5期
刘禹辰 程奕心 许志伟 宋姿颖
(山东科技大学 山东省青岛市 266590)
1 大数据时代网上数字档案资源挖掘需求
伴随着计算机、互联网等科学技术的发展,各领域信息资源数量不断增加,促使网上数字档案资源日渐丰富。而在信息资源利用方面,档案资源具有特殊性,属于高价值信息产品,包含地方文化、经济、社会等各方面发展记录的同时,也能使社会活动现状得到有效反映,为各领域工作开展提供有价值的参考信息。而在大数据时代,网上数字档案资源体量增速较快,给档案资料管理带来了一定困难。现阶段,网上数字档案涉及政治、科学、体育等多个领域,存在一定信息差异,促使档案数据结构复杂,带有大数据的多元化特征[1]。面对这一局面,想要实现档案资源充分利用,促使档案价值得到有效体现,还要结合档案使用者需求完成档案信息深层次挖掘,确保有价值的内容得到整合,从而使档案数据效用得到增强。
2 基于大数据分析的网上数字档案知识挖掘目标
2.1 挖掘资源价值
网上数字档案对个人、机构和社会组织在社会活动中的各种信息进行了记录,带有一定知识属性。而不同于其他形式的记录,档案属于历史记录,内容具有真实性。在知识经济时代,则具有一定知识价值,对各种社会实践活动的经验教训进行了积累。通过对档案资源价值进行挖掘,能够为个人、社会和国家开展社会活动提供知识服务。在挖掘档案知识的过程中,想要体现资源价值,还要从无序、分散的原始符号记录中挖掘能够规范排列的信息,构成相应知识体系,为知识运用创造便利条件。对于不同用户来讲,在资源挖掘需求方面存在一定差异。想要为用户提供有价值的信息,还要通过数据挖掘确定用户需求,然后根据需求实现知识挖掘,完成信息专题的设置。将抽取的专题知识存入到用户信息资源库中,才能做到准确为用户提供需要的档案资源。因此运用知识挖掘技术,需要做到高效完成有价值的资源挖掘,通过加强与用户的信息交互提高资源搜索效率,进而使用户个性化需求得到满足。
2.2 推动知识创新
人类开展知识活动,目的是通过运用知识实现知识创新,以推动社会的发展与进步。网上数字资源中融合了各种文献资源,由显性信息和隐性信息构成,带有不同的知识价值。相较于显性信息,隐性信息不仅仅为社会活动中形成的神秘经验,更是人类追究的知识根源,能够为知识创新提供依据。在现代社会管理网上数字资源,显然更侧重挖掘其中隐性知识,如工作经验、学习技巧等,能够体现人类在知识挖掘方面的主动性。因此运用知识挖掘技术,还要侧重利用聚类分析、关联分析等各种智能分析算法完成网上数字档案中的隐性知识挖掘,通过寻求档案数据间的联系确定潜在的知识信息。在实现旧知识逻辑化处理的过程中,能够借助档案资源完成更大知识体系构建。实现资源挖掘的不断深入,能够完成隐形信息汇聚,发掘其中的潜藏价值。通过实现资源结构更新完成档案资源深入挖掘,可以发掘新的知识领域,推动知识创新活动的开展,继而使档案知识挖掘过程成为知识创新过程。
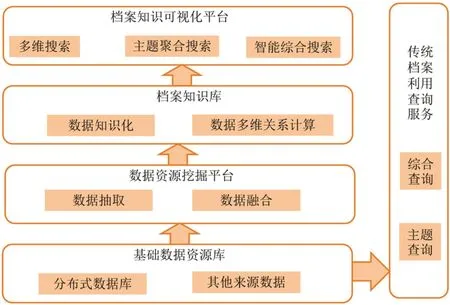
图1:网上数字档案知识挖掘体系架构
3 基于大数据分析的网上数字档案知识挖掘技术
3.1 知识挖掘体系架构
在网络数字档案数据海量增长的过程中,想要从中挖掘知识和完成大数据分析,还要采用必要的技术手段,利用计算机代替人工完成档案信息挖掘操作,确保知识能够得到快速提取,继而使知识服务得到顺利供给。结合这一需求,采用大数据分析方法实现档案知识挖掘,还要建立相应的体系架构提供知识检索服务,满足不同档案使用者的知识获取需求。如图1 所示,架构由基础数据资源库、数据资源挖掘平台、档案知识库和档案知识可视化平台构成,能够提供档案主题查询和综合查询服务。在基础资源库中,需要利用分布式数据库完成不同领域网上数字档案数据存储,同时也可以通过互联网等途径获取其他来源数据。数据资源挖掘平台能够从资源库中获取档案数据信息,通过知识抽取完成数据知识化分析。根据各类实体语义、关联等信息,利用大数据技术能够实现数据融合,满足档案知识库的知识获取需求。知识库通过对数据的多维关系展开计算,能够为主题聚合搜索、多维搜索、智能综合搜索等平台功能实现提供支撑,促使档案知识得到可视化显示,继而使用户的知识获取需求得到满足。
在知识挖掘体系架构运行期间,资源库和知识库能够协同开展作业,共同作为知识挖掘数据资源平台,在提供档案数据的同时,为档案数据关联挖掘提供支持。实现档案知识化,则是实现档案知识提炼,能够根据知识概念和逻辑关系组建结构完整的知识链网,使档案得到准确定位的同时,根据知识特点和结构实现档案合理存储,继而为用户搜索知识提供便利[2]。采取该种设计,能够加强档案数据资源中各种实体及其属性的关联,为信息抽取和融合提供支持。在知识表达上,能够利用语义完成知识本体结构挖掘,构建知识模型,利用知识组织规则实现各类实体解析,继而使各类隐性因子得到挖掘。在知识关系得到可视化显示的同时,能够实现知识聚合,使档案知识结构得到清楚展示。而采用计算机视觉技术将知识语义概念、模型等以图形、图像等形式展现出来,能够确保知识得到精确和高效传递,为人员通过手机、计算机等终端查看提供便利。
3.2 知识挖掘过程分析
从大数据分析角度来看,网上数字档案知识挖掘其实就是数据清洗、集成、处理和分析的过程。尽管拥有广泛的数据来源,使得档案数据类型较多,同时应用需求也存在差异,但是却拥有相同的数据处理流程。
首先,针对异构的原始数据,需要完成清洗、抽取和集成,促使数据按照统一标准存储,为后续数据处理与分析奠定基础。针对格式、性质存在差异的数据,需要从物理或逻辑上实现数据集成,对存在一定关联的实体进行提取,聚合得到统一数据标准。在数据清洗方面,还应加强质与量的权衡,避免粒度过细造成有价值信息被滤除,同时避免粒度过粗造成冗余信息过多。在档案数据组织方面,可以采用EAD 元数据实现数据聚合分析,完成知识合理组织。
其次,需要对数据属性特征进行提取,然后通过转换处理得到易于分析的形式,并在分布式处理模型和数据仓库中存储。在数据分析方面,可以通过数据训练完成分类器的构建,并通过实现多个分类器聚集取得较好数据分类效果。在数据训练中,保证每次选择相同概率权重,可以使误分类数据的选取概率权重得到增加。对训练数据进行重新抽取,并完成迭代分析,能够得到多个分类器。将分类器加权投票当成是输出结果,能够完成数据分类转换。在数据存储方面,需要采用分布式方式,建立开源计算平台,利用分布式文件系统完成非结构化数据存储。通过对档案数据进行分割,能够得到多个数据块,再由数据节点构成的分布式集群中存储。
最后,需要通过数据挖掘完成有益知识提取,然后实现结果可视化,为用户提供需要的知识服务。数据挖掘实际就是数据深层分析过程,需要采用人工智能等技术完成语义处理。从百度、搜狗等网站中,可以获得海量语义知识。根据其中蕴含的语义信息和规则,能够实现档案数据中各种语义关联的抽取,得到档案主题分类表、词表等各种表格,为语义处理提供支持[3]。而挖掘得到的知识关联较为复杂,为满足用户知识获取需求,还要完成数据交互式分析,采用趋势图等各种图形、图像实现分析结果的可视化展示,确保用户能够理解挖掘结果。根据用户需求对档案知识单元进行提取后,通过在数据描述框架下完成信息背景封装,然后加强相关知识链接,能够构成由多个知识单元构成的网络,确保用户知识获取需求能够得到满足。
3.3 知识挖掘关键技术
在对网上数字档案中的知识进行挖掘时,还要加强文件排序、元数据著录等关键技术的运用,以便使知识得到充分挖掘的同时,能够得到高效利用。
首先,针对各种电子档案文件进行处理,已经无法实现物理排列,因此还要通过挖掘历史关联实现虚拟排列。作为档案资源开发者,需要根据网上数字档案文件内容完成文件夹建立,筛选相关文件,根据背景信息确定文件关联。在全宗建立时,需要从时间、事由和来源三个角度构建年代、主体和客体全宗,以虚拟形态保证文件之间拥有完整关联。对档案文件各种关系进行挖掘,能够利用多关系数据结构建立聚分类模型,实现各种关系中关联知识提取,使分散在不同档案资料中的信息与知识关联得到解释,从而满足知识迁移需求。
其次,在文件描述方面需要加强元数据著录技术运用,利用结构型、知识描述型等不同类型元数据对文件结果、内容等进行转化,在保证档案数据完整性和真实性的同时,为资源利用奠定基础。从元数据类型上来看,包含主题、时间、来源、格式、语言等,签发人、份数等则作为属性信息保留。利用元数据完成各种档案要素描述,能够为隐性知识挖掘提供便利。实际采用EAD 标记语言,能够创建通用的档案数据标准。在常用的档案检索工具中,基本都采用该种语言,可以确保档案数据调用突破平台限制,能够实现数据兼容,继而为档案知识得到灵活挖掘和利用。
最后,在档案知识检索中,需要采用“全宗-案卷-文件”的信息组织方式,加强文件主题、形成时间等特征利用[4]。根据特征完成知识组织后,可以根据来源机构关联形成引文链,确保知识得到顺利链接。采用聚类分析等技术,能够完成档案知识连续挖掘,为知识重组提供支持。实际检索知识,需要采用概念检索技术完成关键词汇转换,实现词义拓展,做到高效和精准查询。知识挖掘和检索需要满足用户需求,因此还要加强用户访问习惯挖掘,确定其与资源内在关联。结合组织特性加强档案内容比较,能够在全宗范围内对相关文件资源和知识进行挖掘,并根据主题关联进行知识关系的可视化展示,引导用户通过点击链接快速完成知识检索。
4 结论
综上所述,在大数据技术的支撑下,可以实现网上数字档案资源的充分利用,在促使数字资源价值得到凸显的同时,为知识创新提供动力。实际想要实现档案知识挖掘,还要完成相应资源库、知识库和挖掘平台的构建,以便形成能够为档案利用提供服务的知识挖掘体系架构。通过完成档案资源大数据分析和处理,实现知识充分挖掘,能够使用户需要的知识得到可视化显示,最终满足档案数据价值管理需求。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
云南化工(2021年8期)2021-12-21
新世纪智能(数学备考)(2021年9期)2021-11-24
海洋信息技术与应用(2020年1期)2020-06-11
当代陕西(2019年15期)2019-09-02
传媒评论(2019年4期)2019-07-13
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
数学大王·低年级(2009年10期)2009-12-21
