
如何使用NLP高效解析语言文字
2020-04-23 01:22徐铮浩
电子技术与软件工程 2020年5期
徐铮浩
(上海大学 上海市 200437)
自然语言是人类发展过程中形成的一种信息交流的方式,包括口语及书面语,反映了人类的思维。现在世界上所有的语种语言都属于自然语言, 包括汉语、英语、法语等。 在人工只能领域,对自然语言的处理(NLP)在近年得到了较快的发展。
目前NLP 主要研究以下几个领域,文本检索、机器翻译、文本分类/情感分析、信息抽取、序列标注、文本摘要、问答系统、对话系统、知识图谱、文本聚类,所涉及的基本技术有分词系统、词性标注、句法分析、词干提取、文本生成等。NLP 的核心思想,是要提取基本的文本表征转化为数字形式并加以计算,而模拟的数字运算都是连续的,例如(X,Y)∈[0.1],即x 和y 的值可以在这个区间内被找到,但自然语言的分布却是离散,对于,是无法,到定义在任意两个词之间的某个情绪词,同理,自然语言处理也不能像普通的图像处理那样,可以通过调节分辨率等数值来对图像的显示做调整。自然语言的处理,主要通过对转化后的数字做概率和统计进行运算,来预测或解析使用的词句。
随着NLP 的研究发展,目前已经有很多算法来支持文本表征的抽取以及预测,比如one-hot 将各个词编码为一个向量,假设喜欢(001)、不喜欢(010)、很喜欢(011)等,使用这些向量来作为预测和训练的语料,运算结束后再解码为具体的词句,缺点由于中文词库十分庞大,特征的维度会非常高。tf-idf 是基于词频来统计文本表征的算法,可表示为词频(TF)表示词条(关键字)在文本中出现的频率。特点是字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。但该算法往往会升高一些生僻词的权值,对一些出现次数较少的人名、地名提取效果不佳。word2Vec,doc2vec,glove 和facebook 的fastext 通过给与一些任务构建它的损失函数,训练一个深度模型,模型的中间产物来得到文本表征,词向量,文本向量和句向量。但这些并不符合现在标准的深度模型,属于比较浅层的网络模型。因为词向量使用的分布式假设认为相同的上下文语境的词具有相似的含义,那对于“美国总统特朗普决定在墨西哥边境修建隔离墙”和“听说美国的那个川普总统要在墨西哥边上修个墙”2 句话,由于存在很多相同的关键字很容易被判断为相同语境,则特朗普和川普会被认为是同一个人,但这么做的弊端在于,词向量的每个词只有一个固定表征,对于“同学你的川普挺带感啊(四川普通话)”这类在上下文中含义不同时的处理会出现问题。
本文采取了和word2Vec 等算法不同的途径,核心思想是通过不同的上下文对词的共现度不同,可以得到不一样的文本表征,作为可以结合上下文的动态表征,这么做的话,前后上下文的信息越充足,预测的词句就越精确,越符合自然语言沟通的特性。
1 相关技术
1.1 语言模型
语言模型本质上是一个概率模型,在给定前后上下文的基础上,从概率上预测接下来的内容,模型的目标就是学会语言的“套路”,即文法,句式和词法,所以上下文越详细,预测的目标越明确。比如“人们彼此的交往离不开_”,空缺文字可以是“语言”,“文字”,或者“信息”,但不可能是“动物”,如果加上“语言是人与人之间的一种交流方式”的前提,那答案只能是“语言”。
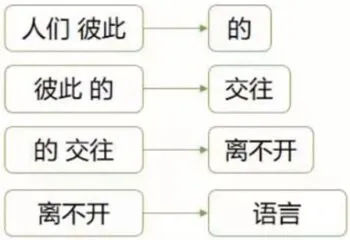
图1
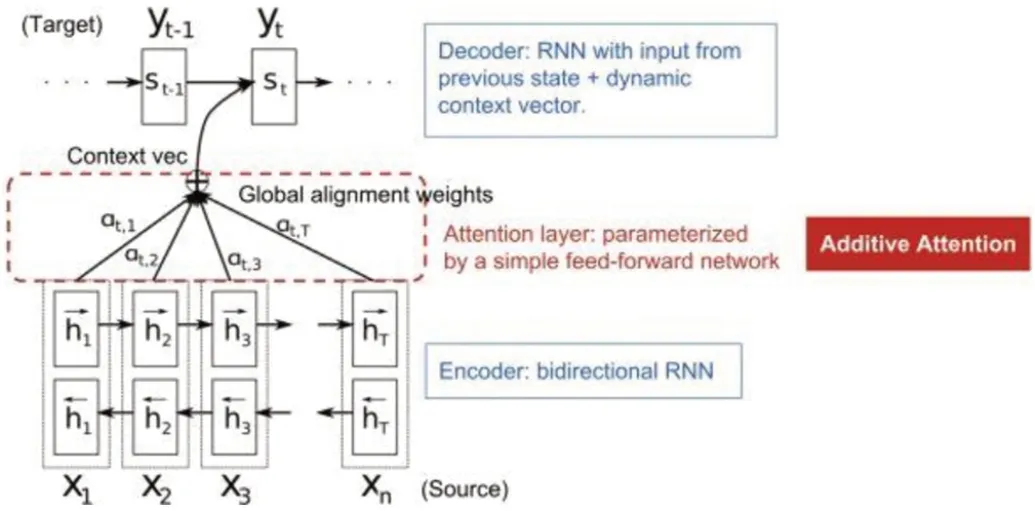
图2
1.2 传统语言模型的问题
传统语言模型使用N 元语言模型,把训练的语料中连续的文本切成语言的碎片,用前面N 个词预测第N+1 个词,比如二元语言模型(参考图1),但弊端是过于短程的依赖无法满足语言的多样性,而多元语言模型虽然可以支持长词句依赖,却也造成了统计结果变得稀疏,算力的依赖也大幅增加。
1.3 神经网络语言模型
使用循环神经网络语言模型可以解决长程依赖的问题,在Bengio Yoshua 提出前向神经网络(Feed-forward Neural Network, FNN)语言模型之后,神经网络语言模型引起广泛关注,而循环神经网络(Recurrent Neural Network, RNN)引入语言建模,使得语言模型的性能得到较大的提升。接着循环神经网络的改进版本,长短期记忆(Long Short Term Memory, LSTM)和注意力机制(Attention),相继地被用于进一步改善语言建模的性能。
单向RNN 共享一个权重矩阵 A ,理论可以编码无限长度,只往一个方向,弊端是根据有限的前置上下文预测后词,难度大,准确率低,而双向RNN 能根据前后文预测之间的词,准确率更高,网络深度更深,算力要求更高。
注意力机制的核心思想是拉平所有的词,将每个词与任意一个词巧妙的建立了联系,这在解释翻译时,通过每个词的语义向量的加权和,识别出每个词在整句中的重要性分布,和人类翻译时的注意力习惯是保持一致的。如图2 所示。
1.4 BERT
Bert 的全称是Bidirectional Encoder Representation from Transformers,是Google 开源的一套模型,采用了双向注意力机制,Bert 运用了更复杂的结构,更多的语料,mask lm 方式的编码,以及给模型更多的上下文内容来训练模型。
1.4.1 Bert 的结构
Bert 运用了三种向量,词向量(Token EmBeddings)并没有进行预训练,但会在训练过程中变化、学习。表征向量(Segment EmBeddings)表明输入序列是前句还是后句,EA 和EB 分别代表左句子和右句子。位置向量(Position EmBeddings)和注意力机制不同,注意力机制中所有的词一起输入,没有序列,位置向量则会有序列编码,位置向量是可训练的,只跟位置有关,和具体的词无关。在模型的输入中,会包含“cls”,“sep”二种特殊符号,cls 用于预测下一句话,当为true 表示前后两句话是连续有关系的,false 则相反。Sep 是前后文本的分隔符。
1.4.2 Masked LM
mask language mode,类似完形填空,虽然仍旧看得到所有位置信息,但需要预测的词已被特殊符号代替,不影响双向encoding。模型训练时随机遮盖语料中15%的token,然后将masked token 位置输出的最终隐层向量送入softmax,来预测masked token。这样输入一个句子,每次只预测句子中大概15%的词,模型训练速度会比较慢,但网络模型非常深。本文按一定的比例在需要预测的词位置上输入原词或者输入某个随机的词。80%的概率用“[mask]”标记来替换、10%的概率用随机采样的一个单词来替换、10%的概率不做替换。
1.4.3 Transformer
Transformer 模型是2018年5月提出的,可以替代传统RNN和CNN 的一种新的架构,用来实现机器翻译。 无论是RNN 还是CNN,在处理NLP 任务时都有缺陷。CNN 是其先天的卷积操作不很适合序列化的文本,RNN 是其没有并行化,很容易超出内存限制。Transformer 结构主要由编码器,解码器以及attention 组成,每个attention 都具有multi-head 的特征,将一个词向量切分成h 个维度,求attention 相似度时每个h 维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。而每个词位的词都可以无视方向和距离,有机会直接和句子中的每个词encoding,这是self-attention 的特征,最后,通过position encoding加入没考虑过的位置信息。
2 实验
2.1 实验数据
实验数据采用百度百科以及中文维基中1 亿token 级向量作为训练语料,训练参数分别为batch_size=32,length=512。
2.2 实验任务
本文选用了2 种任务,文本对分类任务判断前后文是否有关联,QA 任务向系统提问并获得答案。
2.3 实验过程
由于预训练的成本比较高,预训练阶段的模型,本文采用Google 提供的现成模型,由于本文只处理中文,所以我们选用一个参数较小的BERT 预训练模型Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters。 用Fine-Tuning 方法来运行,在预训练的语言模型基础上,加入少量的任务参数。直接运行tensorflow 开源代码中run_classsifier。py 就可以进行模型的训练,--task_name 可以配置我们的任务key,--output_dir可以配置模型的输出路径。
3 实验结果分析
本文采用了迭代率、准确率作为模型的测评指标。其中准确率是指在各项任务中最后的输出结果是否符合预期,而迭代率则关注得到结果所付出的系统代价。

表1:实验结果
由表1 可知,对于不同的迭代次数,基于BERT 的微调分类模型与另外2 个模型相比,其准确率要高几个百分点,说明基于BERT 的微调分类模型效果最优。虽然基于 BERT 的微调分类模型与 Transformer 分类模型的网络结构有相似的结构,但基于 BERT 的微调分类模型在预训练阶段通过无监督的方法学习具有上下文语义的词嵌入特征,能更好的表达语义,在微调阶段再用监督的方法训练 BERT 模型和全连接层的参数。结果说明,基于 BERT 的模型具有结构简单,训练参数较少,训练速度快等特点,同时能够高效分析和处理。
4 总结
本文针对自然语言处理的问题,构建了基于BERT 文本对分类任务以及问答系统的模型,证实了两阶段模型(预训练和微调)较强的表征学习能力对自然语言处理的影响,结果显示基于BERT 的模型在QA 任务上效果明显,但在短文本分类上效果不如预期,在不按完整句子构建span 时,预测是否连续的任务收敛很快,短句很多时ppl 收敛很慢。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
海外华文教育(2016年1期)2017-01-20
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
新高考·高二数学(2015年11期)2015-12-23
当代教育理论与实践(2015年9期)2015-12-16
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
