
档案信息资源平台数据的改进措施和效果分析
2020-04-22 20:37葛春丽
兰台世界 2020年4期
葛春丽

摘要 信息时代档案信息资源具有类型多样、体量庞大、形成速度快等特征,要对这些海量的档案信息资源数据实施高效的管理,使档案信息资源平台及时响应用户的个性化需求,以达到有效利用的目的。探讨信息时代背景下档案信息资源平台数据的改进措施,并模拟验证其功能效果,发现改进后平台对于数据的处理效率大大增强。
关键词 信息时代 档案信息资源平台 数据 改进 成果
近年来,信息技术不断深入发展,各类信息充斥着网络,人类社会进入到了一个信息大爆炸的时代,档案信息资源也呈现出类型多样、体量庞大、产生速度快等诸多特点。用户在面对纷繁复杂的档案信息资源时,更多地希望能快速、精准、方便、个性化地獲取所需要的信息资源,因而建设有效的档案信息资源平台势在必行[1]。当前,我国的档案信息资源平台建设普遍较为落后,这与档案管理工作的固有思想观念有着很大的关系,领导层对档案工作的不理解、不重视,单纯地认为这项工作仅是对信息的记录和资料的保管;而员工层面也表现为思想意识淡薄,观念落后,缺乏开拓创新精神,这些都是导致信息时代背景下档案信息资源平台建设落后的一个重要因素。档案信息是人类社会活动最原始性、真实性的信息记录,是社会最有价值的反映,能够真实地体现当前社会行为者所做决策的背后原因及各自的目标、使命、志愿、思想、信念、心理作用,体现出典型社会生活的不同法律、管制、义务和机制的结构,对档案信息进行有效开发与利用,不但是社会技术进步的要求,更是影响到档案信息创新成果是否高效应用于社会生产、生活的各类活动中去的重要要素[2]。因此,当务之急是要实现对海量档案信息资源数据的高效管理,使档案信息资源平台及时响应用户的个性化需求,达到有效利用的目的。
一、大数据环境下档案信息资源共享平台性能需求
信息时代背景下网络分为有线网络和无线网络。在移动设备未出现前,有线网络下的档案信息是通过网站进行信息发布,用户群体也只局限在有线的计算机中,该方式的档案信息具有资源利用不高、服务形式单一、资源较为匮乏等瓶颈[3]。随着移动互联网技术的发展,移动设备的大量普及,用户除了使用计算机进行档案信息的检索使用,还可以利用移动设备导入档案信息资源共享平台,对信息进行检索和利用。不但增强了信息的检索频率,提升了信息的曝光率,同时也强化了对档案信息资源共享平台的性能需求。尤其是在大数据时代下,网络已经发展到当前的3G、4G,甚至是即将到来的5G网络,移动设备日益更新,技术不断进步,与网络的匹配上也是与时俱进,档案信息资源共享平台数据处理的性能需求必须要满足高性能、高可靠和高稳定的特点[4]。一是高性能要求。大数据档案信息资源共享平台会面向终端用户,平台上用户量就会变得越来越多,大数据量请求随之也会增长为了避免出现死锁现象,档案信息资源共享平台的优化就很重要,通常要求数据处理性能指标应增长到每秒上万次的请求吞吐量,以增强用户的体验。二是高可靠要求。随着平台用户数量的增加,出现平台并发,众多用户使用同一个功能的现象就会较常见,在面对众多用户的请求实时,平台的前期并发性能指标要满足上千以上的并发数据处理请求[5]。三是高稳定要求。用户体验是档案信息资源共享平台得以持续使用的关键,不但要求数据量请求高性能,还需要出错率低。不管面对的用户群体增长的数量是上万还是上亿,出错率通常要求在万分之一左右,才能确保该平台的可信赖性。
二、信息时代档案信息资源平台数据的改进措施
信息时代所有的信息基本上都集中在网络里面了,档案信息资源平台自然成为用户获取有用信息的主要途径。但是用户在信息获取时普遍反映很难快速准确获得,一方面是数据量大,数据杂乱无章,另一方面是档案信息资源平台缺乏数据的管理工作,因此对于数据处理优化越来越重要[6]。一是面向用户的前端页面的优化,用户通过平台获取有用信息,每个信息都要从前端页面来获取,前端页面及时快捷响应是保证,这样才能增强用户的体验度。二是存储档案信息的数据优化,信息时代最显著的特点就是信息量巨大,而且呈现不断增长的大趋势[7],要使得用户不但获得有用信息,而且获得更全的信息,需要加强对缓存技术的研究。
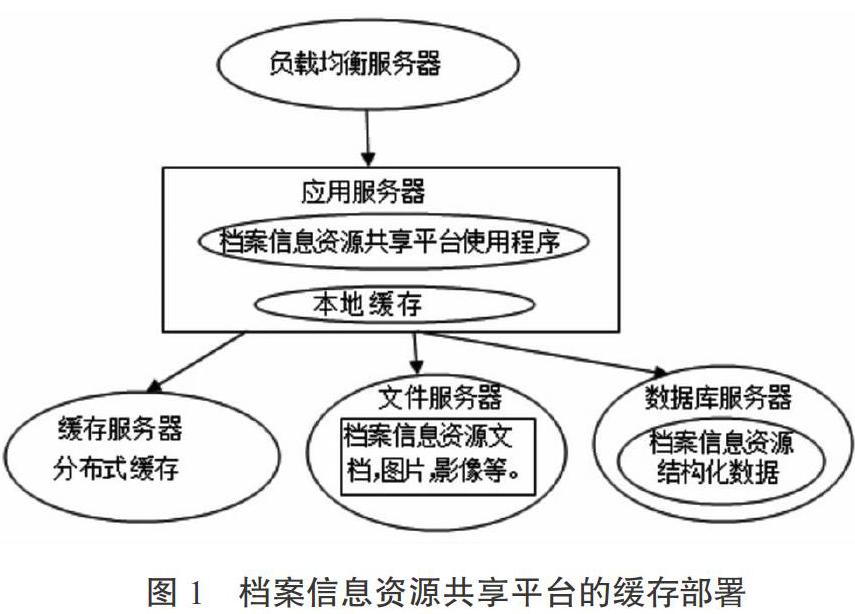
1.信息时代档案信息资源共享平台的缓存部署。档案信息资源共享平台建立之初是将应用服务器,数据库服务器与文件服务器等全部资源都集中在一个服务器中、那时是因为用户面窄,信息化程度较低,服务器的负荷不大,设计是以达到满足够用为目的。随着科技的发展,不单是传统PC网站,还有移动互联网均呈现高速增长趋势,同时用户放开,不但涉及内部用户,还包括外部用户。档案信息资源共享平台若是仍旧沿用原有的构建结构,势必因用户的增加、信息量的增多,凸显出吞吐量不够的弊端,使得系统变得越来越慢,用户在使用该平台过程中,体验度就会变得越来越差。基于此,当前平台的解决办法是将应用与数据进行分离,让应用服务器、数据库服务器和文件服务器进度单独部署。平台的数据处理问题,可以借助缓存技术。缓存作为分布式系统里面的重要组件,能够处理高并发,实现大数据环境下热点数据访问的性能效果。从部署方式上,前期可以把缓存部署到应用服务器上,访问速度会大大提高,但是同时也会暴露出一个问题,就是会和应用程序争内存。后期应利用远程分布式技术来解决平台数据处理问题(如图1)。
2.档案信息资源共享平台的缓存系统拣选。当前,分布式缓存系统主要有两大类型,Memcached和Redis两种,两种系统应用在档案信息资源共享平台有着各自的优缺点,均属于内存的数据存储系统。其中Memcached属于高性能的分布式内存对象缓存系统,Redis属于开源的key-value存储系统,都支持字符串、哈希表、链表、集合、有序集合等数据类型。但是在应用过程中,Memcached用到动态Web上可以减小数据的负载,可是在缓存占用内存分配上使用的是预分配内存池方法,会造成内存的浪费,难以对过于复杂的数据类型及对持久性要求较高的数据类型进行有效的支持。随着各种技术的出现,档案信息资源共享平台需要缓存的档案信息类型变得多样化,而Redis支持更丰富的Key-Value数据库(支持列表、集合、哈希等大量数据结构),而且提供多样语言API,这使得Redis具有应用于档案信息资源共享平台方面的突出优势。数据存储方面,档案信息需要做到持久保存,而Memcached保存不够持久,因为该系统中的信息都保存在内存上面,只要服务器重新启动,所有缓存的信息都会丢失。Redis不一样,它是把部分数据保存在硬盘里面,可以做到长久保存,也不会因为用户对平台的操作造成信息的丢失。档案信息的形式方面,当前档案信息日益多样化,除了过去的文字信息外,还有图片、视频、录音、文件等多媒体信息,对缓存自然就会有一定的要求,将会越来越大。Memcached的Value存储最大只有1MB,Redis的Value存储将会达到1GB。通过上述分析,选择Redis作为档案信息资源共享平台的缓存系统更为合适。
三、信息时代背景下档案信息资源平台数据的改进实现办法
信息时代背景下,人们从档案信息资源平台获取有用信息的诉求越来越高,平台用户数量的大量增加,信息存储量的增多,档案信息资源平台数据问题也日益凸显,因而在现有基础上对档案信息资源平台数据予以改进是当务之急。改进实现的办法需要从档案信息资源共享平台的缓存部署、技术的选择确定出发,具体从以下几个方面予以实施。
1.前端数据改进措施实现。前端与后端是相对平台使用的用户而言,平台的前端改进主要是让用户最大限度地使用浏览器缓存。檔案信息资源平台中最大的特点是更新静态资源文件的频率非常低,尤其是CSS、JS和图标这些文件。平台用户的前端主要集中在档案信息检索页面、档案信息管理维护页面、用户管理页面这三种,其中使用频率最高的是用户直接面对的检索页面,因此改进的措施就主要集中在检索页面。对该功能的改进主要利用CSS、JavaSeript技术,实现让压缩存储和功能页面里的图片达到合并,因此用户一次请求就能够实现CSS、JavaSeript和页面形样图片的获得。将静态资源文件放到浏览器缓存里面,用户在下一次相同页面的资源请求时,就能够从浏览器缓存里面直接读得,访问的效率就会明显提高。当在平台的前端使用了符合传统PC和移动设备的JS、CSS软件技术后,对应的资源文件访问则可以使用CDN软件技术,其作用就是当浏览器请求大文件资源时,就会从CDN软件里面直接送回给用户设备,资源访问的线路变得最小了,就会使得访问的速度增快,并且还会减小平台中服务器的负载。
2.后端数据库数据改进措施实现。后端数据库数据改进方面是根据前端的影响而决定的。前端使用最频繁的是档案检索功能,因此后端数据库数据的改进主要就集中在后端数据库检索模块的改进。因为前端的档案检索功能变得频繁了,必然增加了后端数据库的检索工作,这就需要采取措施减小后端的工作压力。具体可从几个方面着手:第一是减小档案检索功能里面数据反复访问的次数和数据量,可以把档案检索的前置条件设定得更详细并且能一次递交进后台中,给予数据的检索,当数据库检索成功以后,就会把用户需求的结果送回给它们。采用这种方法能够增强系统检索功能,能够最大限度减小数据的访问数量,并且送回的数据变得更加准确,互联网的压力也会相应减小。第二是在档案检索过程中,存在非常繁琐的数据提取动作,就需要采用存储过程方法。把过程数据处理逻辑融入存储过程中,达到避开利用互联网反复开展数据的交换,同时档案信息利用存储过程处理后一起回复用户请求信息,存储过程中利用参数的方法输送检索请求信息,在增强检索能力的时候,也避开了资源共享平台SQL的依附造成系统缺陷。第三是利用索引技术增强检索性能。索引的创建主要是在档案信息最常应用的检索点上利用有关列上进行创建。增加索引不但能提升检索性能,而且有效的检索实施后,可以减小平台档案信息的删修再新增等工作。对后端数据库数据而言,可以把档案信息检索所需的主要信息放入历史表里面,以提升由于信息的变化造成的其他功能的性能问题。
3.Redis缓存数据处理改进实施完成结果。Redis缓存能将部分数据保存在硬盘里面,并实现长久保存。随着档案信息资源共享平台用户的增加,用户量级到达一定程度,若是信息都从数据库里面读取,平台的性能就会受到极大影响,为了减轻数据库的压力,可以把频繁访问的用户请求档案信息放进Redis缓存里面。当档案信息检索请求产生后,开始要分析Redis缓存里面有没有用户请求的档案信息,假设里面有,就直接从Redis缓存里面获得档案信息,检索也会变得更加的直接,其性能就会大幅度提高。假设Redis缓存里面没有用户请求的档案信息,那么就需要从数据库里面获得档案信息的有关数据,并且要把获得的档案信息写进Redis缓存里面,这样的好处就是当用户下次发起同样的请求时,系统会直接从Redis缓存获得,而并不需要在访问数据库进行获得。档案信息资源共享平台Redis缓存完成流程图如图2所示(见下页)。
从Redis缓存请求完成流程可以看出,在档案信息资源共享平台中,要实现Redis缓存在客户端应用,需要在Redis缓存里面加入DLL。DLL(Dynamic Link Library)文件是动态链接库文件,又叫做“应用程序拓展”。把DLL文件加入到引用后,应把配置Redis操作参数导进配置文件里面,其中Redis的端口信息是Redis服务里面出现的端口,默认端口号是6739。当这些有关信息构建好后,还应写一个普遍应用的Redis缓存管理器,主要功能是获得Redis客户端实例,增加档案信息实体融合到缓存里面,增加文字符类档案信息以获得文字符类型的档案信息。接下来就是档案信息列表,全部档案信息以及认定文件类型档案信息列表,只需要按照键名就能获得,同时还具有删除、清空认定键缓存信息的功能。在实际的应用过程中,如需用到缓存功能,可以直接调用Redis缓存管理器予以实现。
对档案信息资源平台数据的改进完成后,需要进一步验证其功能效果。采用模拟现实环境中超大数量的档案信息数据,包括文字符号类型、时间类型和GUID类型等数据,数据量是2000万条档案信息。平台操作请求和请求的数据条数都使用的是10的N次方递增加压方式,测试计算机用的操作系统是Win10,处理系统用的是Intel Core i5-7200U。结果发现,当档案信息大量请求数量出现时,平台每秒钟能支撑的请求数也会大量增加,并且Redis缓存软件对并发连接的支持也非常高,可以说利用该技术,平台对于数据的处理效率大大增强。需要注意的是,利用Redis缓存软件有一个最大的问题就是数据的命中率,这将是以后档案信息访问中研究的一个重要方向。
猜你喜欢
史志学刊(2022年2期)2022-05-25
南北桥(2021年16期)2021-05-25
领导文萃(2017年20期)2017-11-03
价值工程(2016年30期)2016-11-24
电脑知识与技术(2016年24期)2016-11-14
商(2016年27期)2016-10-17
商(2016年27期)2016-10-17
科学与财富(2016年28期)2016-10-14
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
