
面向废线路板拆解的高值电子器件自动识别方法研究
2020-04-18 13:54:48陈从平徐道猛李游邓扬何枝蔚张屹戴国洪
三峡大学学报(自然科学版) 2020年2期
陈从平徐道猛李 游邓 扬何枝蔚张 屹戴国洪
(1.三峡大学 机械与动力学院,湖北 宜昌443002;2.常州大学 机械工程学院,江苏 常州213164)
目前,我国电子产品年报废达5亿台/540万t,并正以33%的速率增长,造成环境污染和极大资源浪费,迫切需要开发高效的处置利用技术与方法,以实现对线路板金属材料进行回收利用[1].线路板上的主要金属如铜等主要富集在引脚密集的接口上(如PCI等);稀贵金属如金、银等主要富集在CPU、IC 芯片、晶振及主要总线型接口上.如果对上述含铜及稀贵金属富集的高值电子器件单独拆解,后集中提纯处理,相比于对整块线路板及其上所有电子器件同时处理而言,将会显著提高处置效益,同时也会减少后续提纯过程中化学试剂的用量而减少环境污染[2-4].然而,由于废线路板种类繁多,不同废线路板上所含高值电子器件数量、大小、形状、相对位置等都各异,若采用人工识别并进行拆解,会严重降低效率并增加成本,亟待开发自动化的识别方法.
现有对线路板上电子器件自动识别的方法均采用人工定义特征并结合机器视觉进行识别.其中影响识别准确性最为关键的人工定义特征主要分为两大类,一是轮廓特征,二是颜色特征.例如柯一剑提出的采用机器视觉算法识别电子器件[5],即使是在较简单的背景下对4类元器件的识别准确率也只有81.3%,当改变检测背景和元器件颜色或形状时,准确率基本降为零,可见机器视觉算法的环境适应性和可移植性极差.然而,同类高值器件在同一块线路板或不同类型线路板上的形状、大小、颜色都存在差异,且易受其他非高值元器件形状、颜色、印刷电路轮廓、线路板底色等背景的干扰,故上述方法虽然对单一类型电子器件或固定类型线路板上多类电子器件识别有较好效果,但不适于生产线上多类型板卡、多类型电子器件的通用性识别,方法的可移植性和鲁棒性差.
本文提出了一种基于深度学习的废线路板高值电子器件自动识别方法,搭建YOLOv3网络模型并对模型进行了改进,后通过网络训练获得多类高值电子器件特征模型对目标器件进行识别.与现有的基于深度学习识别方法相比,经本文改进后的方法不仅能实现多类高值电子器件的高精度识别,还具有很强的可移植性,可为废线路板高值电子器件智能拆解提供关键技术支撑.
1 电子器件的识别方法
目前较为典型的深度学习网络模型主要有SINet、SSD-Resnet、SSD[6]、Fast-RCNN、Faster RCNN[7]、R-FCN、YOLOv3[8]等,其中YOLOv3网络模型相比于其他几种网络模型在检测精度高的同时实时性也非常好,且其网络内部采用了金字塔网络结构和多尺度检测思想,针对不同的问题优化空间大.因此本文以YOLOv3模型为基础并对其优化作为高值电子器件自动识别的网络训练模型.
1.1 YOLOv3算法原理
YOLOv3由Joseph Redmon在2018年提出,它是在Deaknet和YOLO[9]的基础上发展而来的,主要采用了Darknet的残差结构来构建网络深度和运用不同的降采样倍数来提取不同尺寸特征图,从而实现多尺度预测[10-11].其中残差网络结构除了用于构建网络深度以外,在训练过程中还有利于信息的流动,使网络训练起来比较容易.残差结构通常为每个残差块按一定的顺序堆叠,各卷积层之间有直接连接,也有跳跃性连接,通过这样的连接方式实现不同残差块、不同卷积层之间的信息传递与共享.若以xi和xi+1来表示第i个残差块的输入与输出向量,Fi(xi)表示转换函数,有:
对于多尺度目标检测,YOLOv3使用了类似FPN 网络金字塔的结构,将原图像按照特征图尺度大小将其划分为K×K个等大的单元格,每个单元格再借助3个先验框(anchors box)来预测3个边界框,而神经网络则为每个边界框预测坐标(x0,y0)、目标宽w1和高h14个值.若设目标中心相对图像左上角偏移量为(Δx,Δy),先验框高宽分别为w0,h0,则边界框修正后为:
由于不同尺度特征图的感受视野不一样大[8],因此适合检测不同尺寸的高值电子器件目标.
1.2数据集制作、网络搭建优化及训练
1.2.1 数据集的制作
总共采集了1000张含各类高值电子器件的废线路板图像,并按9∶1分配为训练集样本和验证集样本.这些图像来自多种电子电器设备如洗衣机、电视机、空调、电脑等的废线路板,并按VOC2012数据集的格式将其统一缩放成一个规格,即将图片高和宽其中一个值固定为500 pixel,另一个值在450~500 pixel范围内,然后对数据集的图像进行标注,为了减小标注工作量,对小于25×25 pixel的电子器件未做标注也不列入回收范围.采集的部分样本如图2所示,图中主要对6个类别的目标进行了标注,分别是CPU,IC芯片,晶振(X),插槽(PCI、DDIM),锂电池(CR).
1.2.2 网络搭建与优化
以YOLOv3网络模型为基础,将原来的网络主体Darknet-53调整为Deaknet-62,并增加一个检测尺度,构建新的网络模型YOLOv3-Darknet62.从模型的结构上看整个网络没有像Faster RCNN 等网络那样含池化层和全连接层,而是在前向传播过程中,通过改变卷积核的步长来变换张量尺寸[8].所搭建的网络模型深度为130 层(BN、leak_Re LU、add、con、zero Padding共178层未计算在内),其中0~87 层为Deaknet-62部分,含有61 个卷积层,并引入Resnet特征金字塔网络和运用残差结构的跳跃式连接来增加网络深度;88~130 层为YOLO网络的特征交互层,分为4个尺度,每个尺度内,通过卷积核的方式实现特征图局部特征交互,根据数据标准化处理以及维度聚类、细粒度特征操作,直接预测出目标的中心坐标;通过惩罚机制来提高模型的泛化能力,更好地匹配定位目标,在此基础上添加多标签、多分类的逻辑回归层,对每个类别做二分类,从而可实现分类识别.
由于各类高值电子器件尺寸差异较大,例如通常IC芯片与PCI插槽的长度尺寸差别可达到数倍.为提高YOLOv3网络模型对不同尺寸的高值器件检出能力,本文对传统YOLOv3 网络模型进行改进,在YOLOv3网络模型后增加一个卷积块(res4)与原网络组成4尺度检测模型,并将图像输入尺寸调整为512×512,构成64×64,32×32,16×16,8×8共4个尺度的特征金字塔,即将网络模型的最小提取特征层尺寸降为8×8,最大提取特征层尺寸提升到64×64,使得在检测较大尺寸的插槽和较小的IC芯片时均有较高的检出能力.并对形成的特征金字塔仍执行2倍以上采样操作,与前面的深度残差网络拼接形成深度为130层的高值电子器件识别网络模型.图3为所搭建网络模型的结构简图,其中的6 个卷积块共含有54个卷积层和27个残差层.图中Yi(i=1,2,3,4)表示不同的输出尺度,DBL 是YOLOv3 的基本组件,代表conv+BN+Leaky_ReLU;Res-n 为YOLOv3的大组件,n代表数字,有res1,res2,…,res8 等,表示该res-block里含有多少个res-unit;con为张量拼接,即将darknet中间层和后面某一层的上采样进行拼接,用来扩充张量的维度(本文类别为6类输出张量维度为33),add表示残差层的相加.
其中特征金字塔与残差网络的拼接方式为:经上采样的第98层与第74层残差层拼接,经上采样的第110层与第61层残差层拼接,经上采样的第122层与第36层残差层拼接,并且所有卷积层使用1×1或3×3的卷积核进行卷积,细节如图4所示.
进一步,通过数据集运行了10次K-means聚类运算程序,对每次生成的12个achours结合本文检测目标的尺寸和高宽比进行分析比较,最终选择20×172,22×19,26×40,35×27,38×331,47×53,72×86,90×42,129×118,209×203,233×20,365×39作为先验框.
1.2.3 网络的训练
模型训练时,采用Adam作为优化器,使用随机梯度下降进行优化,初始学习率设为lr=0.001,衰减因子dec=0.1,每训练10个批次衰减一次.同时还采用对数据集图像随机裁剪、水平翻转、旋转角度、调整色调、曝光度和饱和度来生成更多的训练数据,以提高模型的检测能力和泛化能力,其中表1为数据增强策略对检测产生的不同效果.
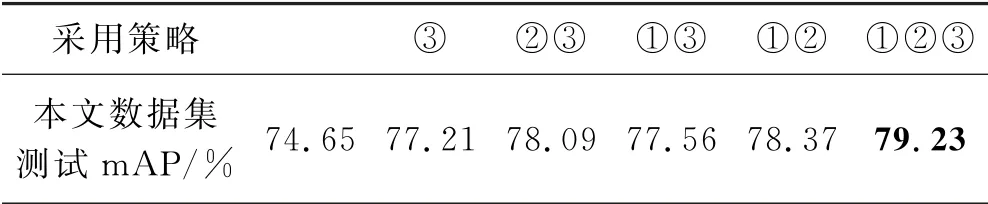
表1数据增强策略产生的不同效果
在网络收敛后,利用已标注好的100张验证集样本对模型进行验证,结果如图5所示,其中图5(a)为未经改进的YOLOv3 原模型在验证集上的验证结果,在图5(a)的第2张图中出现了PCI插槽被重检及晶振X 被漏检的现象;图5(b)为经本文改进后的模型在验证集上的验证结果,从中可以看出对于CPU 的检测精度从87%上升到了92%;对其他高值电子器件的平均检测精度提升了约2.5%,同时PCI插槽的重检和晶振的漏检问题也被解决.故优化后的YOLOv3-Darknet62模型不仅解决了重检漏检问题,在检测精度上也有所提高.
2 实验与分析
2.1 实验条件与训练结果
实验软硬件配置见表2.

表2软硬件配置
图6 为本文制作的数据集在YOLOv3-Darknet62网络模型训练过程中的损失值收敛曲线,横坐标表示迭代次数,最大迭代为55 000次.当网络迭代超过3万次时,各参数变化基本稳定,最后损失值趋近于0,网络训练结果较理想.
2.2 网络模型性能评估与分析
依据VOC2007的评价标准通过绘制P-R曲线(如图7所示),其中P代表Precision(准确率),R代表Recall(召回率),并比较曲线下方与坐标轴所围成的面积(AUC)和比较检测精度m AP 来对网络模型性能进行评估.其中AUC和m AP的值越大,则表示模型的性能越好.下面给出了P-R曲线的绘制方法和m AP的计算方法.
图7(a)展示了在部分KITTI数据集(小目标数较少)上5种不同深度学习网络(Faster-R-CNN、YOLOv2、SSD-512、YOLOv3、YOLOv3-Darknet62)的P-R曲线.其中纵坐标为6种目标类别(pedestrian,car,van,truck,tram,cyclist)的平均值,横坐标为平均召回率.图7(b)为在本文制作的数据集(含有大量小目标)上5种不同方法6个类别的P-R曲线,从图7可看出两种不同数据集对YOLOv3类网络模型性能的相对影响不大,而对其他3种网络模型性能的相对影响却很大.同时YOLOv3-Darknet62 在两种数据集上绘制出的P-R曲线与坐标轴所围成的面积(AUC)都最大,分别为0.843和0.791,由此可知YOLOv3-Darknet62的性能最优.
用Tp代表真例,Fp代表假例,FN为假负例,AP代表每个类别的平均精度,为召回率满足时的精度最大值,R代表获得精度最大值时的召回率,N代表类别数,则有:
表3为5种不同网络模型在本文测试集上的识别结果.通过比较AP 和m AP 两个评估指标可以发现,在对含有大量小目标的高值电子器件进行识别时,采用残差网络结构和4尺度预测算法的YOLOv3-Darknet62网络模型在对高值电子器件识别上其检测精度m AP 值最高且达到了79.23%,比
SSD、YOLOv2高出8.1%以上,同时可发现检测尺寸偏小的目标(如晶振X)时所得到的AP(每个类别对应的列)虽然偏低,但是YOLOv3-Darknet62模型的AP值仍然高于其他类型网络的识别结果.

表3不同网络模型在本文测试集上的识别结果
3 结论
本文提出了一种面向废线路板智能拆解的高值电子器件识别方法,通过调整YOLOv3网络结构和增加检测尺度提升了原YOLOv3网络模型的目标检测识别性能.实验表明经改进后,本文所提供的方法对废线路板高值电子器件识别精度显著提高,且能对多类高值电子器件同时识别.
猜你喜欢
传感技术学报(2022年6期)2022-08-18 14:35:00
现代农村科技(2022年9期)2022-08-16 02:25:34
传感技术学报(2022年12期)2022-02-05 06:01:24
云南化工(2021年7期)2021-12-21 07:27:24
中国麻业科学(2021年5期)2021-12-02 02:08:52
传感技术学报(2021年7期)2021-09-29 10:11:46
传感技术学报(2021年2期)2021-05-15 06:59:58
微特电机(2020年5期)2020-12-31 23:46:21
电子制作(2018年14期)2018-08-21 01:38:30
深圳职业技术学院学报(2018年3期)2018-07-23 06:42:26
