
一种基于深度学习的两阶段图像去雾网络
2020-04-18 13:15吴嘉炜余兆钗李佐勇刘维娜张祖昌
计算机应用与软件 2020年4期
吴嘉炜 余兆钗* 李佐勇* 刘维娜 张祖昌
1(闽江学院计算机与控制工程学院 福建 福州 350121)2(福建省信息处理与智能控制重点实验室(闽江学院) 福建 福州 350121)3(福建信息职业技术学院计算机工程系 福建 福州 350003)
0 引 言
大气中存在浑浊的介质(如雾霾、灰尘等颗粒),这些浑浊介质会导致拍摄的图像出现明显的质量下降,如对比度和饱和度损失等,造成图像偏灰白,从而难以辨别图像中的物体。许多计算机视觉任务(如交通监控知[1]、自动驾驶[2]等),最初设计时假定捕获环境是干净的,如果将这些退化的图像作为输入,很容易出现性能急剧下降的问题。图像去雾技术可以作为上述视觉系统的预处理步骤,具有重要的实际意义。
目前,图像去雾方法可以大致被分为两类:第一种是基于先验知识的传统图像去雾方法;另一种是基于深度学习的现代图像去雾方法。近年来,这两种方法均取得了较大的进展。大气散射模型由McCartney首次提出,并由Narasimhan和McCartney进行了详细的推导与描述[3-4]。最终,大气散射模型可以被描述为:
I(x)=J(x)t(x)+A(1-t(x))
(1)
t(x)=eθD(x)
(2)
式中:I(x)代表采集有雾图像;J(x)代表求得的无雾图像;t(x)代表透射率;A是大气光值;θ代表大气散射系数;D(x)表示景物深度。
由式(1)可以看出,估算出透射率t(x)和大气光值A之后,可以从有雾图像反推出无雾图像。因此大多数传统的图像去雾算法致力于准确地估算透射率t(x)和大气光值A。其中最具有代表性的是He等[5]提出的暗通道先验去雾算法(DCP)和Zhu等[7]提出的颜色衰减先验去雾算法(CAP)。He等[5]通过暗通道先验的方法估计出透射率图和大气光值,然后根据大气散射模型反演出无雾图像,但是由于其暗通道先验方法自身的问题,导致去雾后的图像整体亮度变暗[6]。Zhu等[7]提出了一个可训练的颜色衰减先验模型,用来对有雾图像的场景深度进行建模,然后在监督学习的模式下对模型中的参数进行训练,得到景深图,最后用大气模型进行无雾图像的恢复。虽然上述基于手工特征的方法取得了很大的进步,但仍然受到各种先验或依赖的约束,通用性不能得到保证。
最近几年,深度学习理论在计算机视觉领域的研究取得了重大进展,一些学者结合深度学习理论和先验知识提出了图像去雾的新方法,获得了较好的效果。如Cai等[8]将传统的图像去雾算法和深度学习的方法建立了联系,通过深度学习的方法估算出有雾图像的透射率t,一定程度上解决了传统图像去雾方法中普适性差的这一问题。Ren等[9]提出多尺度深度去雾网络(MSCNN)直接学习并估计透射率与有雾图像的关系,解决了人工特征的缺陷,进一步改进了基于物理模型的去雾方法,但是求解物理模型的过程导致是次优解方案,不能直接最小化图像重建误差,模型参数的单独估计会导致误差累计甚至放大。这两种方法虽然在一定程度上弥补了传统的图像去雾方法的缺陷,但本质上还是基于大气散射模型的图像去雾算法。因此,基于大气散射模型的图像去雾算法存在的缺陷也存在于这两种方法中。
最近,Li等[10]对大气散射模型进行优化,将大气散射模型参数统一为一个公式,直接最小化图像重建误差,提出一种端到端的非线性去雾模型(AOD-Net)回归有雾图像和无雾图像之间的关系,这种方法协同估计去雾模型参数,直接获得有雾图像和无雾图像的非线性关系,避免了单独估计参数导致误差累计甚至放大。但是由于有雾图像和无雾图像间非线性关系比较复杂,模型受到速度和空间的约束,所以去雾效果受到一定限制。近期,Liu等[11]摆脱了先验约束,提出一种端到端的全卷积神经网络模型(GMAN),利用编码器-解码器结构直接将有雾图像恢复成无雾图像,去雾效果较好,但由于模型中未考虑图像细节恢复处理,恢复出的无雾图像细节不够完整。Zhu等[12]创新性地探究图像去雾、生成式对抗网络和可微设计的联系,提出了DehazeGAN,获得了很好的去雾效果,也为图像去雾领域提供了另一种思路。
在上述网络的优缺点启发下,基于深度学习理论,提出一种端到端的两阶段去雾网络。第一阶段用编码器-解码器结构学习低分辨率雾霾残留图,第二阶段通过超分辨率重建恢复原始分辨率雾霾残留图,最后预测出无雾图像。提出的网络通过学习低分辨率雾霾残留图能降低网络学习非线性关系难度,且通过超分辨率重建有助于恢复原始分辨率雾霾残留图像细节。本文提出的两阶段去雾网络没有先验条件的约束,创新性地将超分辨率重建任务融合进图像去雾任务,能够端到端地预测具有完整细节的雾霾残留图像从而恢复具有完整细节的无雾图像,且速度较快,有良好的去雾效果。
1 算法设计
图像去雾属于图像处理领域中重要的任务,对图像原始信息的保留要求很高,为了更好地保留原始信息恢复清晰图像细节,提出了端到端的二阶段去雾网络。首先对训练数据进行预处理,用镜像操作保留图像更多边界原始信息,再将预处理后的数据送进提出的去雾网络预测出雾霾残留图像从而恢复出无雾图像。端到端两阶段去雾网络的学习目标为有雾图像的雾霾残留图,第一阶段用编码器-解码器结构学习低分辨率雾霾残留图,第二阶段将任务迁移至超分辨率重建任务,用亚像素卷积和残差结构恢复原始分辨率雾霾残留图,最后直接输出无雾图像。
1.1 数据预处理
图像去雾作为视觉领域中低等级的任务,对图像高层语义信息的依赖程度较小,但是对图像原始信息完整性要求很高,更完整的图像原始信息有助于卷积神经网络更好地恢复出无雾图像的细节。因此,我们采用镜像操作对称复制图像上下边缘对训练数据进行增强。如图1所示,增强后为方形图像数据,有助于保持卷积过程中特征图横向和纵向尺寸计算的一致性,不会造成图像四周信息丢失。

(a) 原图 (b) 镜像结果图1 图像的镜像操作
1.2 网络模型结构
本文提出的两阶段去雾网络结构如图2所示。第一阶段用编码器-解码器结构预测出尺寸为原图一半的低分辨率雾霾残留图,从而恢复出低分辨率无雾图像;第二阶段将去雾任务迁移到超分辨率重建任务上,将低分辨率雾霾残留图像作为输入,采用亚像素卷积[13]和残差结构[14]预测出原始分辨率雾霾残留图,最后恢复出和原图大小一致的无雾图像。
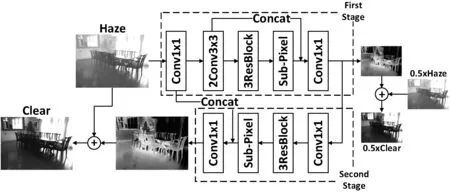
图2 本文去雾网络结构图
本文采用GN[15]作为归一化层、PReLU[16]作为激活函数,作用于每一层卷积层后。GN[15]是将通道分为组,并在每组内计算归一化的均值和方差,从而解决BN[17]训练阶段和测试阶段数据分布不一致问题。PReLU[16]激活函数让神经网络对ReLU[18]激活函数负信号区域进行自适应偏移,从而避免神经元坏死,且让神经网络达到最优状态。
整个网络的学习目标为有雾图像的雾霾残留图,相比直接学习无雾图像,降低了网络的学习难度,并且将超分辨率重建任务融合进去雾任务中,恢复出来的无雾图像细节信息更加完整,并且是端到端的无先验约束的网络结构。
1.2.1残差结构
残差网络[14]由He等提出,他们证明在浅层网络上叠加恒等映射层可以让网络随深度增加而不退化,但是直接学习一个映射函数难以训练,因此提出了残差结构。残差结构的简单描述如下:
H(x)=F(x)+x
(3)
式中:H(x)为残差结构输出;F(x)为学习的目标残差;x为上层输入。图3为本文残差结构图,图中的捷径连接将期望学习目标从复杂潜在映射转换为对恒等映射的扰动,没有引入额外的参数和计算复杂度。因为学习找到对恒等映射的扰动会比重新学习映射函数容易,同时残差对网络的输出变化更加敏感,所以残差结构效果更好。
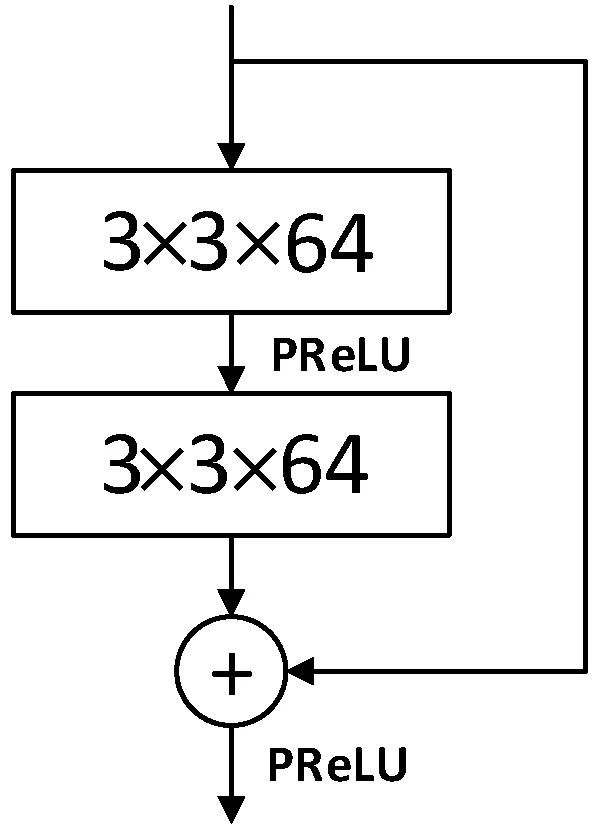
图3 残差结构图
1.2.2亚像素卷积
由于相机成像能力限制,成像面上每个像素仅代表附近颜色,虽然宏观上两个像素是连在一起的,但是在微观上它们之间还有无数微小的东西存在,代表更多细节,这些微小的东西称为亚像素。如图4所示,其中大点为实际像素点,小点为亚像素点。

图4 亚像素表示图
为了恢复图像更多细节,并且考虑到在转置卷积中可能存在大量补0的区域对结果有害,因此通过亚像素卷积[13]的方式,实现从低分辨图到高分辨图的重构。亚像素卷积过程描述如下:
IHR=fL(ILR)=PS(WL×fL-1(ILR)+bL)
(4)
式中:IHR为高分辨率图;ILR为低分辨率图;f为卷积操作;WL为卷积核权重;bL为偏置项;PS为像素重组操作。
亚像素卷积实际上是在普通卷积的基础上再进行周期性像素重组,最终将H×W×C×r2的特征图转换为rH×rW×C的特征图,r为缩放倍数。像素重组过程如图5所示(channels为高分辨率特征图通道数)。一个周期具体过程为从多通道特征图的每个通道各取一个元素,组合成新的特征图上的一个方形单位,原特征图上的像素就相当于新的特征图上的亚像素。
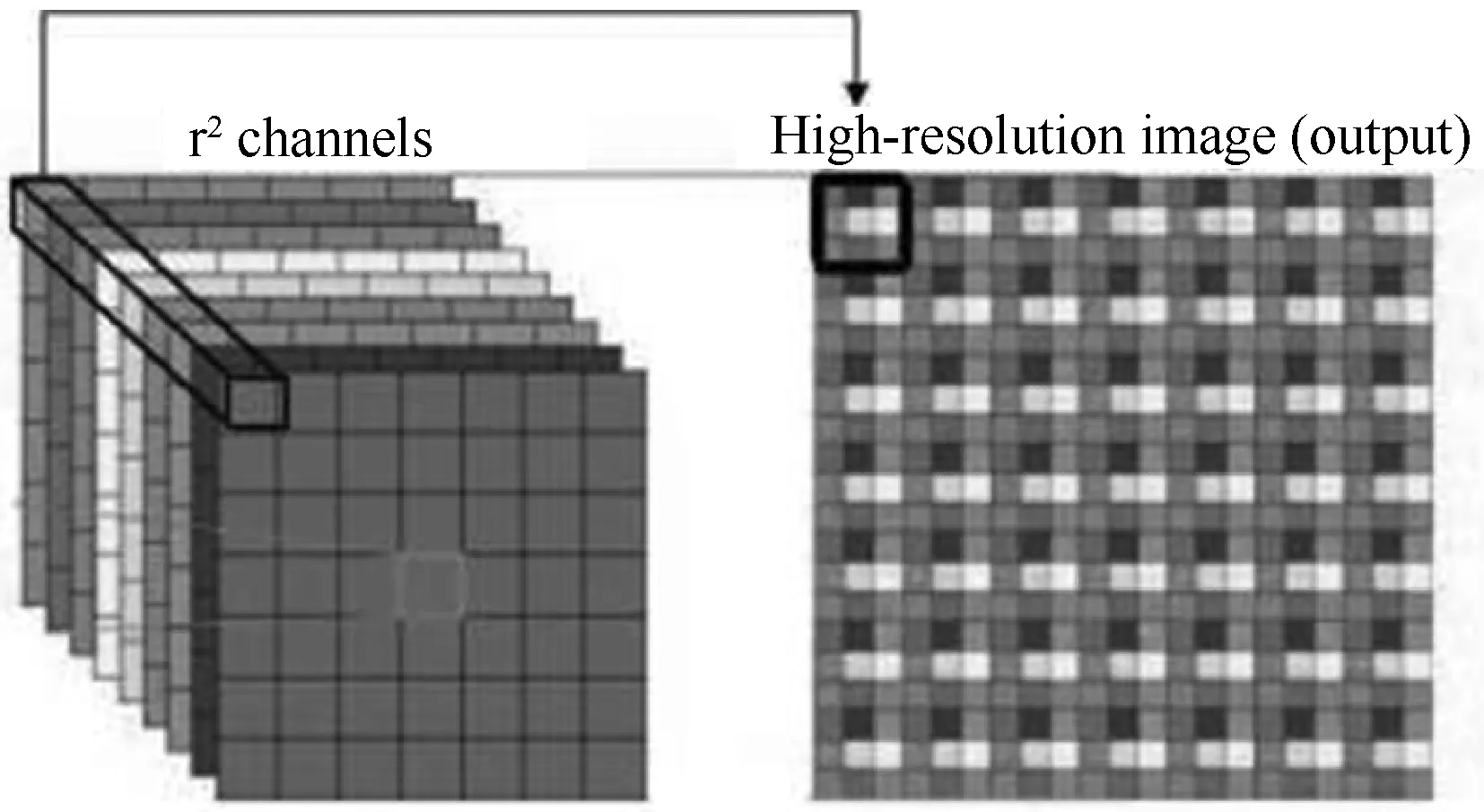
图5 亚像素卷积像素重组示例图[13]
亚像素卷积可以恢复更多高分辨率图像细节,在超分辨率重建任务上已经证明了它的有效性[13],并且在速度上也能够达到视频实时处理的要求,很适合将低分辨率雾霾残留图恢复成原始分辨率雾霾残留图。
1.2.3编码器-解码器结构
U-Net[19]网络提出编码器-解码器的网络结构,在高层隐空间中对高维特征图进行变换,再逐层结合对应编码层解码至低层空间,有效降低网络学习难度和增加网络性能。
受到U-Net[19]网络启发,第一阶段我们采用解码器-编码器结构实现低分辨率雾霾残留图的预测,如图2上半部分网络结构所示,整个编码器-解码器的目的在于学习雾霾残留图,因为雾霾残留图的稀疏性能够有效降低网络学习难度。为了保留图像原始信息,我们先用尺寸为1的卷积核将有雾图像映射到高维空间;用2层尺寸为3的卷积核在高维空间提取特征图高层特征进行编码;用3层残差块[14]对高层特征图进行非线性变换,目的在于从高层隐空间有雾特征图预测出高层隐空间雾霾残留图;最后用亚像素卷积[13]对层隐空间雾霾残留图上采样和降维进行解码。同时因为编码部分包含较多图像原始信息,比如边缘信息和空间信息,所以对解码部分具有指导意义,因此,将解码后的特征图和编码部分第一层特征图进行叠加,再用尺寸为1的卷积核将特征图映射回低维空间,最后得到低分辨率雾霾残留图。我们将雾霾残留图和双线性插值下采样后的有雾图像进行相加,得到了效果良好的低分辨率无雾图像。
1.2.4雾霾残留图超分辨率重建
传统算法中,从低分辨率图像变换到高分辨率图像采用插值算法,效果并不理想,插值后的高分辨率图像容易失真模糊。最近,基于深度学习的超分辨率图像重建方法[13]取得了很大的进步,恢复出的高分辨率图像具有良好的细节信息。
我们将网络的第二阶段设计为超分辨率重建任务,如图2下半部分网络结构所示,将低分辨率雾霾残留图用尺寸为1的卷积核扩充维度信息,再用3层残差块进行非线性变换,目的是获得上采样所需隐空间特征信息。之后用亚像素卷积进行上采样,恢复出原始分辨率雾霾残留图特征,最后再用尺寸为1的卷积核映射为原维度空间得到原始分辨率雾霾残留图。由于雾霾残留图可视化过程有雾图像比无雾图像大多数像素点灰度值较高,预测出来的雾霾残留图负数比重大,因此按式(5)对雾霾残留图变换进行可视化,变换后的雾霾残留图中灰度值越大,去除的雾量也越大。
IV=min{0,(-2.0×IR)}
(5)
式中:IV为可视化结果;IR为预测雾霾残留图。图6为雾霾残留图超分辨率重建可视化结果,可以看出,可视化雾霾残留图中灰度值越高,去除的雾气量越大。

(a) 有雾图像(b) 可视化雾霾残留图(c) 去雾结果图6 雾霾残留图可视化结果
1.3 损失函数
为了训练本文提出的网络,定义了一个双分量损失函数,第一项用均方误差度量预测图像和真实图像相似性,第二项用感知损失[20]帮助构建更符合视觉的图像,两者以某种平衡协同作用于网络中低分辨率部分和原始分辨率部分。
1) 均方误差损失(MSE):使用PSNR来衡量预测图像与真实图像之间的差值,是一种最常用的显示算法有效性的方法。因此,选择MSE作为损失函数的第一个分量,即LMSE。通过在像素级最小化MSE,可以得到PSNR的最优值,只衡量残差之间的MSE以降低网络学习难度,表示为:
(6)
式中:r′为预测雾霾残留图输出;r为真实雾霾残留图。
2) 感知损失(Perceptual Loss):在许多经典的图像恢复问题中,输出图像的质量完全是由MSE损失所决定。然而,MSE损失属于L2型损失函数,具有不确定性,不一定是好的视觉效果指标。Johnson等[20]证明,从预先训练好的神经网络的特定层中提取高等级特征,有利于内容重建,高阶特征得到的感知损失比像素级损失更能鲁棒地描述两幅图像之间的差异。我们选用VGG19[21]作为损失网络,前3层作为感知损失衡量层,定义如下:
(7)
式中:fi为VGG19网络第i层的输出;r′为预测雾霾残留图输出;r为真实雾霾残留图像,真实雾霾残留图像为真实无雾图像减去有雾图像所得。
3) 总损失:总损失综合MSE和感知缺失两种成分,我们对低分辨率雾霾残留图像和原始分辨率雾霾残留图像同时约束,产生以下表达式:
(8)

2 实验及分析
我们使用大型公开数据集RESIDE[22]中的ITS数据集作为训练数据。ITS是室内真实图像进行人工加雾的合成数据集,包括13 990幅训练数据,在GPU上进行训练,Batch Size为2,学习率设为0.000 1,一共迭代100个epoch。实验运行在1 080 Ti GPU、8 GB RAM、Windows 7操作系统的软硬件环境下,使用Tensorflow框架构建模型,测试时仅使用一个线程。
因为RESIDE中的SOTS室外合成数据集中一些真实图像仍然为有雾图,去雾结果评价不具有准确性,所以,我们用RESIDE中的SOTS室内合成有雾数据集进行定量评价,用真实有雾数据进行定性评价。对比算法包括目前效果较好的传统去雾算法DCP、CAP和基于深度学习的AOD-Net和DehazeNet去雾算法。
2.1 合成数据集定量评价及分析
虽然文献[22]中提出了各种指标来衡量去雾效果,但是我们只采用PSNR和SSIM作为衡量指标,这是之前去雾算法中使用最广泛的指标。如表1所示,在SOTS室内合成图像测试集上,本文算法优于目前较好的方法,PSNR和SSIM相对经典去雾算法DCP有较大的提升,表明了本文算法的有效性。
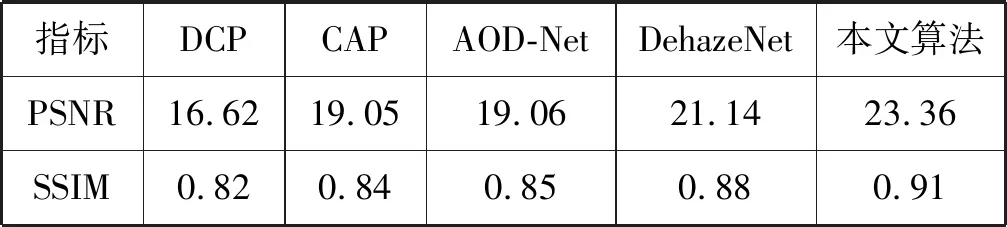
表1 不同算法SOTS测试集去雾结果指标
图7为SOTS合成图像室内数据集部分去雾结果对比图,PSNR作为衡量指标,在前两幅室内合成图像中,DCP和CAP在为去雾模型建模时错估了模型参数,造成光线较暗。而AODNet因为其本身的模型结构不能很好地拟合有雾图像和无雾图像的映射关系,所以去雾效果受到限制。DehazeNet同样依赖于手工特征,每个像素透射率的准确估计较为困难,造成一些像素去雾不干净。本文算法通过两阶段组合任务,去雾彻底,并且恢复了更多的细节,指标优于其他对比算法,证明了算法的有效性。在后两幅室外合成图像中,本文算法与其他对比算法相比依然具有很强的竞争力,证明提出的算法具有良好的泛化能力。

图7 SOTS去雾PSNR值对比结果
对SOTS合成数据集的定量评价分析可以得出,所提出的去雾网络具有有效性并且具有良好的泛化能力,但是在户外去雾任务中,本文算法仍然有较大的改进空间。户外去雾能力的不足和训练数据具有正相关关系,室内图像训练集数据分布和室外图像数据分布存在差异,所以造成泛化能力受到限制。
2.2 真实有雾数据定性评价及分析
将RESIDE[22]中真实有雾数据集HSTS和真实交通数据集中真实有雾的数据作为测试集进行实验,将本文算法和对比算法上在同一条件进行定性评估。
在真实有雾图像上对比结果如图8所示,DCP从5幅图像结果可以看出,在浓雾去除上相比其他算法更有效,但是在5幅图上都出现不同程度的变色或者光晕,这是大气模型参数估计不够准确所导致的;由于浓雾区域颜色信息较少,CAP去除浓雾效果差,且在部分测试数据中丢失了图像原本的颜色;AOD-Net虽然比较稳定,但是受到模型的限制,去雾效果不够理想;DehazeNet在第一幅图将树林恢复成了黑色,丢失了树林原始信息,在第三幅图也将路面恢复成了黑色;本文算法未出现变色或者光晕现象,并且大多数区域去雾效果良好,恢复出原始信息,在去雾稳定性上优于其他两种对比算法。实验表明,本文算法去雾效果良好且稳定性高。

(a) Hazy (b) DCP (c) CAP (d) AOD-Net (e) DehazeNet (f) 本文图8 真实有雾图像去雾对比结果
3 结 语
本文提出的基于深度学习的两阶段端到端去雾网络,将图像去雾任务和图像超分辨率重建任务相结合,通过学习雾霾残留图降低网络学习任务难度。在对比实验的定量和定性分析中表明,本文算法恢复出的无雾图像细节更好,并且网络性能更加稳定,不易出现图像变色和光晕的现象。但是实验发现,本文算法去除浓雾效果不够理想,是因为浓雾区域保留原始信息较少,预测恢复原始信息难度大。考虑到合成浓雾图训练集和真实浓雾图片数据分布较近,可能可以改善去除浓雾效果,拓展训练数据集从而优化去除浓雾效果是以后需要继续研究的方向,同时考虑将所提出的去雾网络拓展于视频去雾领域。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
成都信息工程大学学报(2022年2期)2022-06-14
心理学报(2022年4期)2022-04-12
北京大学学报(自然科学版)(2022年1期)2022-02-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
河南科技(2021年35期)2021-04-25
计算机系统应用(2020年1期)2020-01-15
CHIP新电脑(2016年3期)2016-03-10
