
基于多点地质统计与集合平滑数据同化方法识别非高斯渗透系数场
2020-04-15 07:36宗成元康学远施小清吴吉春
水文地质工程地质 2020年2期
宗成元,康学远,施小清,吴吉春
(南京大学地球科学与工程学院/表生地球化学教育部重点实验室,江苏 南京 210023)
地下水模型有助于地下水资源的开发利用和污染修复,在地下水资源管理以及地下水环境风险性评估、预测等方面具有重要意义。模型模拟、预测效果的好坏取决于模型参数(如渗透系数、储水系数等)精度的高低。然而,复杂的水文地质环境与观测资料的有限性造成无法预先精确刻画模型参数[1]。
地下水模型包括地下水流模型、溶质运移模型等,目前模型参数估计主要使用非线性回归法和贝叶斯方法,例如,Bachmaf等[2]利用非线性参数估计软件PEST[3]推估水文地球化学反应的相关参数;Carniato等[4]利用贝叶斯方法对反应运移模型进行参数估计,并对残差相关性及模型误差进行讨论。模型参数个数多、观测数据类型多样的特点,给传统估计方法带来了困难与挑战。鉴于传统方法计算效率低和估计效果差,地下水模型参数估计中引入了数据同化方法。数据同化方法广泛用于水文地质、石油工程等领域,通过融合多源观测数据,模拟值与观测值之间的差尽可能小,进而估计模型参数值。例如,通过同化地下水水位和示踪剂浓度观测数据推估渗透系数场[5-6]。参数推估方法很多,其中包括Kalman filter方法[7](KF,Kalman),ES方法[8](Ensemble Smoother,VanLeeuwen and Evensen),集合卡尔曼滤波法[9](Ensemble Kalman Filter,EnKF,Evensen),iES方法[10](iterative Ensemble Smoother,Chen)。相比于其他方法,Emerick和Reynolds在2013年提出来的Ensemble Smoother with Multiple Data Assimilation(ESMDA)方法可以获得更好的数据拟合、参数估计效果,且计算成本更低,但其仅可处理服从高斯分布的渗透系数场[11-14]。
在冲积含水层中,由于岩相的非均质分布,渗透系数一般呈现出明显的非高斯特性,非高斯特性给参数推估带来了困难与挑战[15]。例如,当渗透系数的分布受到具有高渗优势流动管道的古河道的影响;或含有连续的高渗透带的冲积含水层的影响[16]。多点地质统计方法(Multiple-point geo-statistics,MPS)广泛用于模拟非高斯场,保持参数场的非高斯特性,通过训练图像描述实际含水层的结构。MPS中的Direct Sampling(DS)方法结合逐点模拟和模式模拟方法的优点,利用顺序模拟的策略,不需要预扫描训练图像和存储地质模式,计算效率较高[17],但动态观测数据(如水头和浓度等)无法融入DS方法的模拟过程。耦合数据同化方法与DS方法既可保持参数场的非高斯特性,又通过融合多源动态观测数据提高非高斯场的推估精度。Cao等[18]构建了iES-DS数据同化框架,融合单一类型观测数据(地下水位),较好地刻画了非高斯参数场。
本文基于DS与ESMDA,构建一种新的数据同化框架(ESMDA-DS)。ESMDA-DS方法结合了ESMDA与DS的各自优势,通过融合多源动态观测数据推估非高斯参数场。构建3个理想算例,包括仅融合水位,同时融合水位与浓度,同时融合水位、浓度以及对数渗透系数,分析融合不同类型观测数据对推估精度的影响,并对比基于不同类型观测数据推估场的水位及浓度预测效果。
1 研究方法
1.1 水流和溶质运移模型
多孔介质饱和承压含水层中地下水非稳定流运动的控制方程为[19]:

(1)
式中:K——渗透系数;
h——水位;
Ss——贮水率;
W*——源汇项;
t——时间。
本文采用MODFLOW[20]求解上述水流问题。
饱和承压含水层中溶质运移的对流—弥散方程为[19]:

(2)
式中:c——溶液中某种组分的浓度;
t——时间;
D——水动力弥散系数;
u——实际平均流速矢量。
本文基于MT3DMS[21]求解上述溶质运移问题。
1.2 ESMDA-DS方法
ESMDA[12]方法是Emerick和Reynolds在2013年提出的一种参数推估方法;DS方法作为多点地质统计方法的一种,具有重构诸如非高斯参数场等复杂地质模式方面的优势。本文提出一种新的参数推估方法,通过构建ESMDA与DS的数据同化框架,融合多源动态观测数据解决非高斯场的参数推估问题。在推估过程中,随机产生一定数量的向导点,ESMDA方法基于水位、浓度更新向导点处的参数值,DS方法基于向导点处更新的参数值与对数渗透系数观测值更新全场参数值,保持对数渗透系数场的非高斯特性。
ESMDA-DS方法更新参数场的主要步骤见图1。
步骤1:基于DS方法生成参照场与样本场。
步骤2:确定观测井与向导点数量及位置。
步骤3:构建状态向量X:
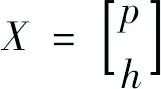
(3)
式中:p——向导点与观测点处对数渗透系数的集合;
h——运行MODFLOW后的模拟水位或浓度。
步骤4:确定样本数量Ne,迭代次数Na,系数αi,每次数据同化满足以下限制条件:

(4)
ESMDA中每个数据同化的系数取α1=9.333,α2=7.0,α3=4.0,α4=2.0[12]。
步骤5:每次迭代时,利用更新的参数从零时刻开始运行耦合模型:
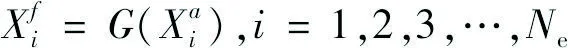
(5)
式中:i——样本编号;
f——预测;
a——分析。
通过式(5),根据模型参数获得不同时刻的状态变量,同时该变量可在步骤5中用于更新。
步骤6:更新样本:

(6)
式中:CYD——状态向量与模拟值之间的互协方差矩阵;
CDD——模拟值的自协方差矩阵;
l——ESMDA的迭代次数,l=1,2,…,Na;
CD——观测误差的协方差矩阵;
dobs——具有协方差αlCD噪声的扰动观测值;
d——预测数据。
步骤7:DS方法基于向导点处的参数更新值与对数渗透系数观测值更新全场对数渗透系数场分布。
ESMDA-DS中,向导点发挥重要作用,通过向导点概念耦合ESMDA与DS。若不设置向导点,ESMDA-DS方法中仅利用DS方法,此时仅能保持参数场的非高斯特性,动态水位或浓度数据无法融合到多点地质统计学模拟中。如果模型所有网格均为向导点,ESMDA-DS方法中仅利用ESMDA方法,仅能融合多源观测数据,不会保持对数渗透系数场的非高斯特性。通过耦合ESMDA方法和DS方法,既可保持参数场的非高斯特性,又通过融合多源观测数据更好地推估非高斯含水层,刻画模型中高渗优势通道。

图1 ESMDA-DS方法的主要步骤流程图Fig.1 Flow chart of the proposed ESMDA-DS method
2 算例
构建理想算例验证ESMDA-DS方法推估非高斯参数场的效果。理想算例为二维平面矩形承压含水层非稳定流模型。模型面积为0.04 km2,x与y方向长度均为200 m,z方向的含水层厚度为5 m,含水层底板高程为0 m。网格均匀剖分,边长为5 m×5 m,网格数为40×40。模型初始水位为30 m,南北边界为隔水边界,东侧边界是水位为30 m的给定水头边界。为提供同化价值高的观测数据,流场水位波动较大,将西侧边界设定为分段赋值的给定流量边界。模型模拟时长为40 d,前30 d用于数据拟合,为进一步评价参数估计效果,后10 d用于预测,模型预测精度越高,说明模型参数估计效果越好。模型具体参数设置,见图 2与表 1。如图 2所示,在研究区域内均匀布设9口观测井,提供水位、浓度观测数据,其中1~6号井还提供渗透系数观测值。

图2 模型设置Fig.2 Model settings
本文共设置3个理想算例(表2),Case 1仅同化水位数据,Case 2同时同化水位与浓度数据,Case 3同时同化水位、浓度数据以及渗透系数观测值(lnK)。在模型东侧位置设置线状持续泄露的污染源泄露点,设定单个网格点的源强浓度为1 mg/L。基于参照场运行模型,计算得到水位与浓度模拟值,分别加上噪声作为水位观测值(h)与浓度观测值(c)。假设水位、浓度、对数渗透系数的观测误差均服从高斯分布,均值均为0,标准差分别为模型最大降深的5%、模拟值的10%、0.1%[22-23]。在研究区内随机布设160个向导点,DS方法将基于向导点处参数值更新全场参数分布。

表2 算例情景设置Table 2 Case settings
DS方法是一种基于模式识别的方法,直接根据训练图像获取其结构特征。与传统的两点地质统计学方法相比,多点法能够更好地描述含水层的非高斯结构。本文利用DS方法生成含水层中砂和黏土两相分布情况,基于表 3中的随机函数产生一系列的连续性变量。
图3(a)为描述含水层特征的训练图像,图3(b)所示的参照场在训练图像的基础上利用DS方法产生,每一相都以连续性变量填充。
在推估参数场过程中,首先,基于DS方法随机生成200个对数渗透系数场作为初始样本。与产生参照场的方法类似,利用DS方法和图 3(a)所示的训练图像,基于与产生参照场相同的随机函数参数随机生成200个参数场集合,从而构成lnK场的初始参数集合。其次,ESMDA融合动态观测数据更新向导点处的参数值。最后,DS根据向导点与渗透系数观测点处的参数值对参数场进行插值,从而计算对数渗透系数的全场分布。

表3 生成砂、黏土两相的参数设置Table 3 Parameter settings for sand and clay
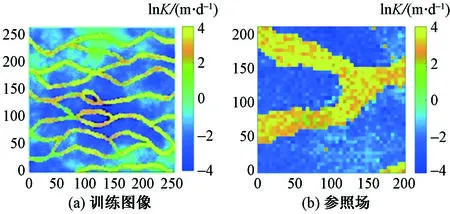
图3 理想算例的训练图像与参照场Fig.3 Training image and reference field of the ideal case
3 结果与讨论
3.1 非高斯对数渗透系数场的推估
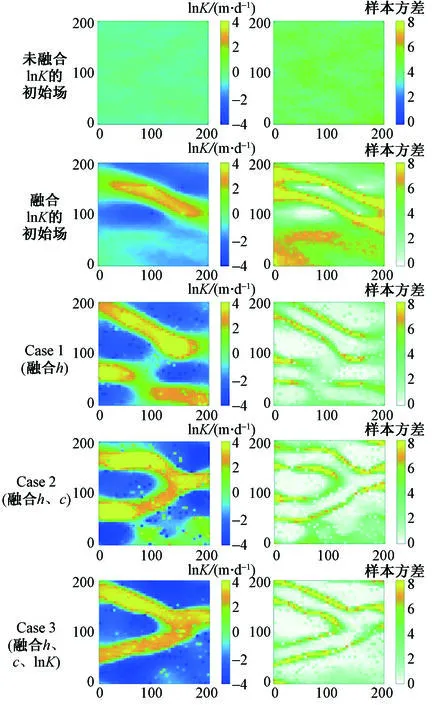
图4 lnK场的集合均值及集合方差分布Fig.4 Mean and variance distribution of lnK field注:Case 1融合h,Case 2融合h与c,Case 3融合h、c与lnK。
未融合lnK数据的初始场、融合lnK数据的初始场以及融合不同类型观测数据lnK场推估结果的集合均值及集合方差分布见图4。未融入lnK时,缺乏渗透系数观测值,随机产生的初始样本场集合均值分布图为类均质特征,基于此初始场构建Case 1与Case 2。Case 1仅推估出上侧的一条高渗优势通道,无法准确推估出两条高渗优势通道。可能是由于水位误差较大,观测数据量不足,同时存在异参同效现象导致推估精度不高。Cao等[18]基于耦合的iES-DS方法融合误差较小的水位数据较好地刻画了非高斯参数场。观测误差大小代表观测水平的高低,其直接影响观测数据的可用性,随着观测误差增大,推估精度越低。当观测数据量较少时,同样无法得到准确的推估结果,导致推估场与真实场相差较大[24]。Case 2可大致推估出两条高渗优势通道,表明同时融合多源数据可提高参数场的推估精度[25-26]。融入lnK时,在推估过程中观测点处对数渗透系数值保持不变,初始样本场集合均值分布图可刻画出上侧的高渗优势通道。与未融入lnK相比,其更接近参照场。同时集合方差分布图下侧显示较大的不确定性,表明融合对数渗透系数观测值可生成较为精确的初始场。基于此初始场构建Case 3,与Case 1、Case 2推估结果相比,Case 3的推估效果更好,表明融合对数渗透系数观测值较好的约束非高斯场的推估精度。
为定量分析渗透系数场的推估精度,可通过计算均方根误差(Root Mean Square error,RMSE)和集散离合度(Ensemble Spread,ES)评价数据同化效果,RMSE越小说明参数估计结果与参照场越接近,ES值下降越快说明同化过程收敛越快:

(7)

(8)
式中:N——模型中网格数量;
Ne——迭代次数;

Yi——每个格点的参照值;
var(xi)——每个格点处不同样本的方差。
图5为不同算例lnK场推估结果直方图,图6为不同算例lnK场的RMSE与ES基于同化步数的变化曲线。基于lnK场推估结果直方图,验证了基于ESMDA-DS方法可以保持参数场的非高斯特性。此外,对比融合单一类型数据与多源观测数据的lnK场推估结果直方图,RMSE与ES变化曲线图,表明同时同化水位、浓度及对数渗透系数时推估精度更高,同时收敛速度更快。

图5 lnK场直方图Fig.5 Histogram of the lnK field注:Case 1融合h,Case 2融合h与c,Case 3融合h、c与lnK。
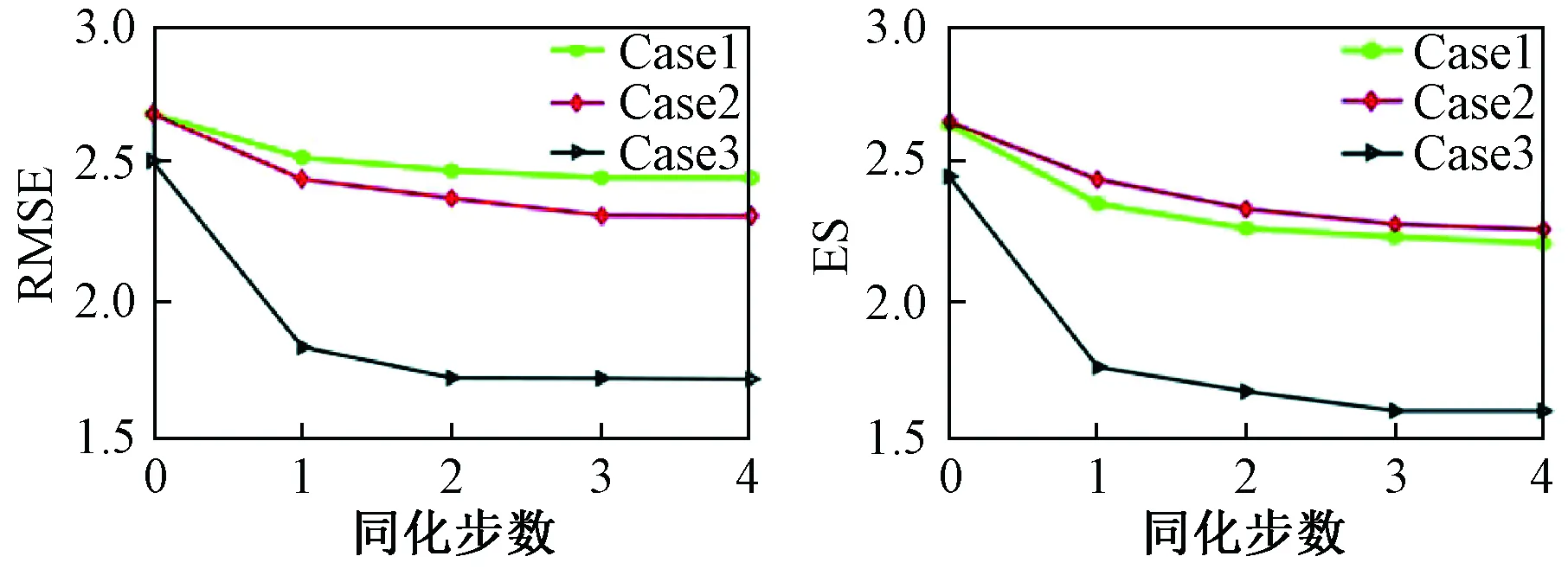
图6 lnK场的RMSE与ES随同化步数变化曲线Fig.6 RMSE and ES of the lnK field注:Case 1融合h,Case 2融合h与c,Case 3融合h、c与lnK。
3.2 观测数据的拟合与模型预测
利用水位与浓度的拟合、预测精度进一步评价推估效果。
图7为1、2号井的水位与浓度拟合、预测图。前300个时间步长(即前30天)为拟合期,后100个时间步长(即后10天)为预测期。在水位预测结果中,Case 1中1、2号井的水位预测值与真实值相差较大,预测效果较差。Case 2与Case 3相比,两口井的水位预测精度大致相当,但同时融合3种观测数据可降低推估结果的不确定性。在浓度预测结果中,与Case 1、Case 2相比,Case 3联合多源数据可更准确地刻画非高斯参数场,获得更高的预测精度[27-28]。
Case 2中,融合水位、浓度数据后参数场推估效果与预测精度不理想的原因是:(1)溶质运移范围与时间相关,在模拟期内,高渗优势通道外观测井内溶质浓度变化很小或者无变化,数据价值不高,反而由于引入额外误差使同化效果变差。9口井中,1、2、6、7号井位于高渗优势通道内,其仅在模拟后期提供浓度信息,有价值的数据量较少。(2)在模拟期内水位变化幅度较浓度变化幅度大,与浓度数据价值相比,水位变化对数据同化效果影响更大。由于水位存在较大的观测误差,因此即使融合了浓度数据,参数推估效果与预测精度仍未得到较大改善。
4 结论与展望
本文构建了ESMDA-DS耦合框架,基于理想算例,验证了其对非高斯参数场的推估效果,进一步探讨了不同类型观测数据对推估效果、水位与浓度预测精度的影响。研究表明:
(1)ESMDA-DS方法吸收了DS方法保持对数渗透系数场非高斯特性以及ESMDA方法在同化多种数据方面的优势,既保留了参数推估场的非高斯特性,又准确推估出高渗优势通道。
(2)单独融合水位数据时,由于水位误差较大、数据量较少,导致仅能推估出参照场的局部特征,水位、浓度预测精度较低。同时融合水位与浓度数据可改善参数场的推估效果、提高水位与浓度的预测精度,但存在较大水位误差导致浓度数据对参数场的推估效果提高有限。而同时融合水位、浓度与渗透系数时可有效提高参数场的推估精度、水位与浓度的预测精度,同时降低推估结果的不确定性。
水文地质模型包含许多参数,如渗透系数、孔隙度、弥散度等,本文为验证ESMDA-DS方法的有效性,算例仅推估渗透系数。后续可进一步融合多源观测数据(如温度[29]),联合同时推估多个水文地质参数,从而有效提高模型反演精度。
猜你喜欢
有色金属科学与工程(2022年3期)2022-07-07
中国海洋大学学报(自然科学版)(2021年2期)2021-12-22
水利技术监督(2019年6期)2020-01-01
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
浙江工业大学学报(2017年5期)2018-01-22
电影故事(2015年16期)2015-07-14
中学生数理化·七年级数学人教版(2008年10期)2008-01-21
