
多层次降维的头颈癌图像特征选择方法*
2020-04-15 09:45:42程天艺王亚刚潘晓英
计算机与生活 2020年4期
程天艺,王亚刚,龙 旭,潘晓英
1.西安邮电大学 计算机学院,西安 710121
2.陕西省网络数据分析与智能处理重点实验室,西安 710121
1 引言
癌症作为世界常见病种之一具有极高的致死率,其中头颈癌(head and neck cancer,HNC)因其原发部位和病理类型之多,居全身肿瘤之首。同时,由于头颈部包括人体的多数重要器官组织,解剖关系复杂,对于此类癌症的治疗也就尤为困难。因此,对患者进行精准的生存期预测是当前癌症问题的关键[1]。
目前常见的生存期预测多从基因组学数据入手[1-4]。然而,除此之外,病理图像、临床信息等其他癌症数据也与头颈癌的生存期预测关系密切。大量的研究表明,病理图像中包含丰富的癌症生存期预测相关信息,可以直接反映癌症的类型、区别肿瘤的良恶性以及肿瘤的组织病理分级等,这些信息均与头颈癌预后,尤其是生存期的状态有着直接联系[5],在癌症的生存期预测中扮演着十分重要的角色[6-7]。目前己有一些基于病理图像的癌症生存期预测工作成功提出。Wang 等人提取出166 个病理图像形态学特征并用于非小细胞肺癌的分类和生存期预测[6]。其后,Yu 等人进一步采用CenProfiler[8]工具从2 186张肺癌患病理图像中提取出包含更全面图像信息的9 879 维特征[7]。然而,采用现有工具提取出的图像特征,存在数据维度较高而样本数相对于特征而言较少的鲜明特点。这些数据中常包含不相关或冗余特征[9],对现存机器学习算法处理小样本高维数据的效果造成影响,通过特征选择来降低数据维数是解决该问题的一种有效途径。
特征选择作为一种常用的降维方法可分为两类[10]:基于相关性的过滤式特征选择和基于搜索的启发式特征选择。基于相关性的过滤式特征选择通过样本的统计属性来评价特征子集对于分类目标所起的作用,由此选择出最优特征子集。它不将任何分类器纳入到评估标准,相对于后续分类算法具有极强独立性,可避免高维数据所造成的较高的分类算法运行成本。但同时,这种统计方法不能保留特征间关联性对分类结果的影响。此类型下常见的特征选择算法包括Relief[11]、MRMR(minimum-redundancy maximum-relevancy)[12]、Mitra 基于特征相似性进行的特征选择[13]、CFS(completely fair schedule)[14]和FCBF(fast correlation-based filter)[15]等。
另一类是基于搜索的特征选择,这类算法中常采用启发式搜索方式来寻找最优特征子集[16],这种方式选出的特征子集保障了特征对分类目标的共同影响。然而基于搜索的特征选择受搜索空间的影响,在高维问题上表现较差。近年来,由于进化算法优秀的全局搜索能力及通用性,众多研究者将目标放在了通过改进各类进化算法来进行特征空间的搜索上。Zhang 等人[17]将骨干粒子群算法结合最近邻算法应用于特征选择。Vieira 等人[18]用决策树来进行特征选择,采用遗传算法来寻找使得决策树分类错误率最小的一组特征子集。Xue 等人[19]在粒子群算法中引入了三种新的初始化机制、个体和全局最优更新机制,在特征数量和分类性能上均有提高。
针对头颈癌病理图像特征提取后产生的高维度小样本问题,本文提出一种基于ReliefF-HEPSO 的多层次特征选择算法。
(1)ReliefF-HEPSO 算法将过滤式特征选择算法与启发式搜索算法相结合,构建多层次框架。在高维环境下,由于启发式搜索算法存在筛选精度低,效率低下的问题,引入过滤式特征选择算法,从而缩小搜索空间,提升搜索精度,降低算法运行时间。
(2)混合二进制进化粒子群算法(hybrid binary evolutionary particle swarm optimization,HEPSO)使用进化神经策略(evolutionary neural strategies,ENS)来改进传统的二进制粒子群算法(binary particle swarm optimization,BPSO),并将其应用在头颈癌图像特征上。该算法通过ENS 使得粒子突变产生新的粒子种群,丰富了粒子种群多样性,从而使得算法能够跳出局部最优解,提升搜索效率。
(3)HEPSO 采用决策树(decision tree,DT)分类器的分类准确率作为算法的目标函数(即评价准则),验证了ReliefF-HEPSO 算法在头颈癌病理图像特征数据上的有效性。ReliefF-HEPSO 算法以较快速度寻找到使得分类性能较高且特征个数较少的病理图像特征子集。
2 ReliefF-HEPSO 多层次病理图像特征选择
本文提出融合ReliefF 和HEPSO 的多层次的病理图像特征选择算法——ReliefF-HEPSO。如图1 所示,对于头颈癌数据特征集,首先使用对应特征的平均值以补全整个样本集,并将经过数据预处理后的数据集输入到ReliefF-HEPSO 中;其次通过ReliefF提取数据的低维特征并将其作为HEPSO 的输入,不断迭代得到最优特征子集;最后将经过特征选择的数据集划分为测试集和训练集,其中训练集用来训练决策树分类器的相关参数,测试集则被送入固定参数的决策树分类模型中,从而得到头颈癌数据的分类结果。
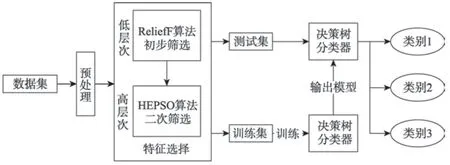
Fig.1 Multi-level pathological image feature selection algorithm flow图1 多层次病理图像特征选择算法流程
2.1 ReliefF 算法
ReliefF 算法是一种基于随机选择特征权重搜索的特征选择方法[11],它根据单个特征与数据类别的相关性,给予特征不同的权重,将高于指定阈值或满足某种判定条件的特征作为候选子集,其余特征被移除。特征的权重根据式(1)来更新。

其中,Ri是每次从训练样本集U中任意选择的一个样本,H、M(C)分别是在Ri的同类样本集和不同类(设为C类)样本集中分别找出的p个近邻样本,近邻样本个数p的选取由数据集的实际情况决定,p>0且小于类别样本中的最小值,本文p∈[0,14],P(C)为C类样本数占样本总数的概率,M为抽样次数。
患者的病例图像特征同时存在连续值和离散值两种类型,当第k个特征的属性是连续值时,根据式(2)计算样本Ra和样本Rb在第k个特征上的绝对差值。
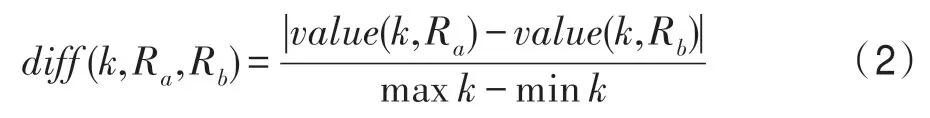
当第k个特征的属性是离散值时,根据式(3)进行计算。
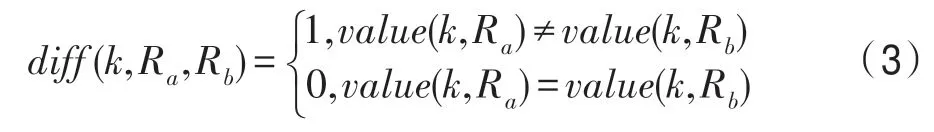
如果Xi和Hj在某个特征上的距离小于Xi和Mj(C)的距离,diff(k,Ri,Hj)<diff(k,Ri,Mj(C)),表明该特征对区分同类和不同类样本是有益的,应当增加该特征的权重;反之,则降低该特征的权重。迭代m次,得到各特征的最佳权重。
w(k)越大,表示该特征的分类能力越强,对特征权重进行筛选,若w(k)>∂,∂为特征阈值,保留第k个特征作为候选特征,否则删除该特征。重复该过程直至i个特征全部遍历完成。
2.2 二进制粒子群算法(BPSO)
为解决离散问题的需求,Eberhart 等人[20-21]提出基于二进制编码的离散粒子群优化算法(BPSO)。该算法通过模仿生物种群(鸟类)的觅食行为,将待优化问题的解空间对应于鸟类的飞行空间,将每只鸟抽象为一个粒子,用以表示候选解。
每个粒子被视为搜索空间中的一个搜索个体,仅具有两个属性:速度和位置。粒子的当前位置表示为待优化问题的一个候选解,粒子的飞行过程则是该个体的搜索过程。粒子的飞行速度根据粒子历史最优位置和种群历史最优位置进行动态调整。BPSO 算法不断迭代,更新粒子的速度和位置,最终得到满足终止条件的最优解。
针对高维度特征选择问题,BPSO 存在两个主要不足:第一,BPSO 中每次迭代产生的粒子,即使确定为非最优粒子也无法被剔除,仍然参与算法的迭代过程,这一行为大大增加了计算资源的浪费;第二,在BPSO 中更优的粒子在每一次迭代结束时会丢弃所有有价值的信息,并在下一次迭代开始时再次被随机初始化,这样的行为模式与算法在整个演变过程中始终追踪局部最佳和全局最佳的目标相矛盾,极易使得BPSO 陷入局部极小值。
因此,本文采用进化神经策略(ENS),通过粒子突变产生新的粒子种群,丰富种群多样性,同时丢弃失败粒子,降低算法时间复杂度。
2.3 混合二进制进化粒子群算法(HEPSO)
2.3.1 进化神经策略(ENS)
进化神经策略(ENS)是Chellapilla 等人在数学游戏中学习的一种适当策略[22]。该策略由m个神经网络pi(i=1,2,…,m)组成,每个网络中均存在一个自适应参数向量σi(j),σi(j)的每个分量对应一个权重或偏置值,它们负责管理搜索神经网络的新突变参数的步长。权重或偏置值通过在[-2,2]上的均匀分布抽样产生。
对于每个父辈pi来说,后代可以通过式(4)、式(5)来创建。
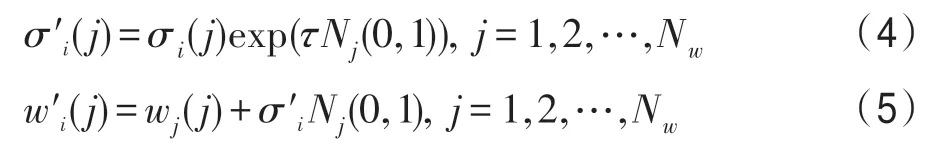
其中,Nj(0,1)是每一个j重新采样的标准正态分布,Nw表示权重和偏差的最大数量,并且。
2.3.2 BPSO 的改进算法HEPSO
m个粒子的种群中每个粒子i在K维空间的位置和速度都可表示为一个矢量。
位置向量Xi={Xi1,Xi2,…,Xik} 表示候选特征子集,Xik表示第i个粒子的第k个特征;
速度向量Vi={Vi1,Vi2,…,Vik}表示选择该特征子集的概率,即粒子位置Xi分配为1 的概率。
HEPSO 算法中首先对粒子的位置向量和速度向量随机初始化,根据式(6)、式(7)更新粒子的速度向量,根据式(8)更新位置向量。
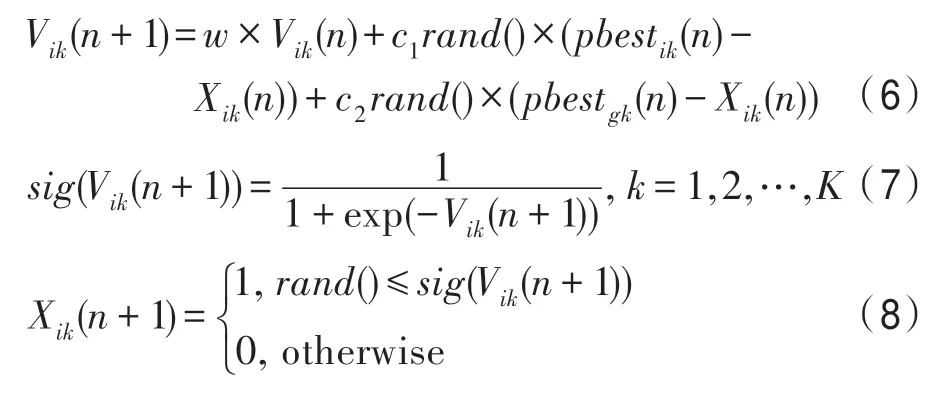
其中,n为迭代次数;rand() 为0~1 之间的随机数;pbestik为粒子i的个体最优值;pbestgk为粒子的种群最优值;w为惯性系数,w∈[2.1,8.0]决定了粒子先前速度对当前速度的影响程度,调节w的大小可以起到平衡粒子群算法全局搜索能力和局部搜索能力的作用[23]。
适应度函数是HEPSO 算法中评价特征子集优劣的重要指标,如式(9)所示,自定义适应度函数f(pi)为分类器的准确率。适应度函数的输入表示具有所选特征子集的粒子(即Xi向量中标记为1 的特征),然后基于所选特征子集构建DT 分类器。适应度函数的输出设置为分类器的分类准确率。

其中,TP(true positives)是样本被分类器正确地划分为正例的个数,TN(true negatives)是被正确地划分为负例的个数,F为样本总数。
本文将特征选择思想引入最优化搜索算法中,利用混合二进制进化粒子群算法(HEPSO),结合BPSO 与ENS,在迭代过程中通过父辈与子代之间的突变丰富粒子种群的多样性,同时种群个体之间的协作和信息共享也使得能够更好地寻找最优特征集合。

Fig.2 HEPSO particle mutation network图2 HEPSO 算法粒子突变网络
如图2 所示,每次迭代时,对适应度函数值进行排序,保留前一半更优适应值对应的获胜粒子,优化的个体(或解)直接遗传到下一代通过BPSO 继承其全部信息,视为精英粒子。而剩下的具有最低适应度函数值的失败粒子将被丢弃。在获胜粒子的基础上,根据式(4)、式(5)进行突变产生新的粒子,并与原有父辈pi中的精英粒子组合,形成下一次迭代的新种群。
粒子i在HEPSO 算法中的演化过程如图3 所示。
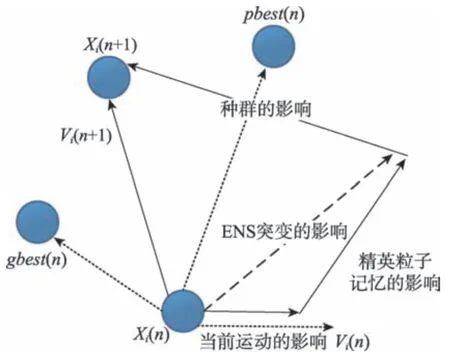
Fig.3 Particle evolution process in HEPSO图3 粒子在HEPSO 算法中的演化过程
ENS 中的突变特性是通过使粒子“飞入”新的搜索空间来帮助粒子群体多样化从而达到丰富种群多样性的目的,解决了BPSO 在迭代过程中产生的局部最优解问题。同时,来自BPSO 父辈突变后产生相同数量的粒子将被用来填补被丢弃后粒子的空白。这些新粒子继承了父辈的认知特征,这将反过来增强ENS 的竞争力和多样性。
第k+1 次粒子状态更新结束后,对粒子个体最优值和种群最优值进行更新,局部最优pbest和全局最优gbest的更新方式如式(10)、式(11)、式(12)所示。

HEPSO 算法的步骤如下所示:
步骤1 随机初始化HEPSO 算法的参数PID,包括粒子数m,迭代次数n,邻域大小[-a,a],常参数c1、c2等。
步骤2 随机选择一组粒子并初始化粒子位置random(Xik,Vik),即随机选择特征向量。
步骤3 根据式(9)计算所有粒子的适应度函数f(pi)。
步骤7 根据式(6)~式(8)更新精英粒子的位置与速度,合并父辈精英粒子与突变粒子为下次迭代的子代粒子群。
步骤8 若当前迭代次数j≥n,结束迭代循环,转步骤9;否则转步骤3。
步骤9 输出种群最优gbest作为问题最优解,求得最优特征集合。
2.4 ReliefF-HEPSO 多层次特征选择算法
算法流程如图4 所示,首先对数据集进行预处理,将处理后的数据送入ReliefF 算法中,计算每个特征权重并以此进行排序,选择特征权重较大的特征作为候选特征子集。其次初始化HEPSO 参数,以决策树分类器的分类准确率为适应度函数,对其降序排列。其中排序前一半的粒子作为精英粒子保留,更新当前迭代的个体极值位置和全局极值位置,而剩下粒子在精英粒子的基础上进行突变,产生新的子代粒子群,从而参与更新全局最优。重复这个过程,直到满足迭代终止条件,生成最优特征子集。
设ReliefF-HEPSO 的迭代次数为n,粒子数为m,其中ReliefF 算法的特征总个数为N,抽样次数为M,选取近邻样本数为p,则执行ReliefF 算法的时间复杂度为O(M×max(N×p,N2))。设执行ReliefF 算法后保留特征个数为K1,HEPSO 算法的时间复杂度为。传统BPSO 算法无需进行适应度函数的排序以及新粒子的突变,设其特征个数为K2,则时间复杂度为O(n×m×K2)。由于HEPSO算法中的K1经过ReliefF 算法做低维特征选择,远低于BPSO 中使用全部特征的K2,且m通常小于K1、K2,因此HEPSO 的时间复杂度小于BPSO。此时,ReliefF-HEPSO 的时间复杂度为:
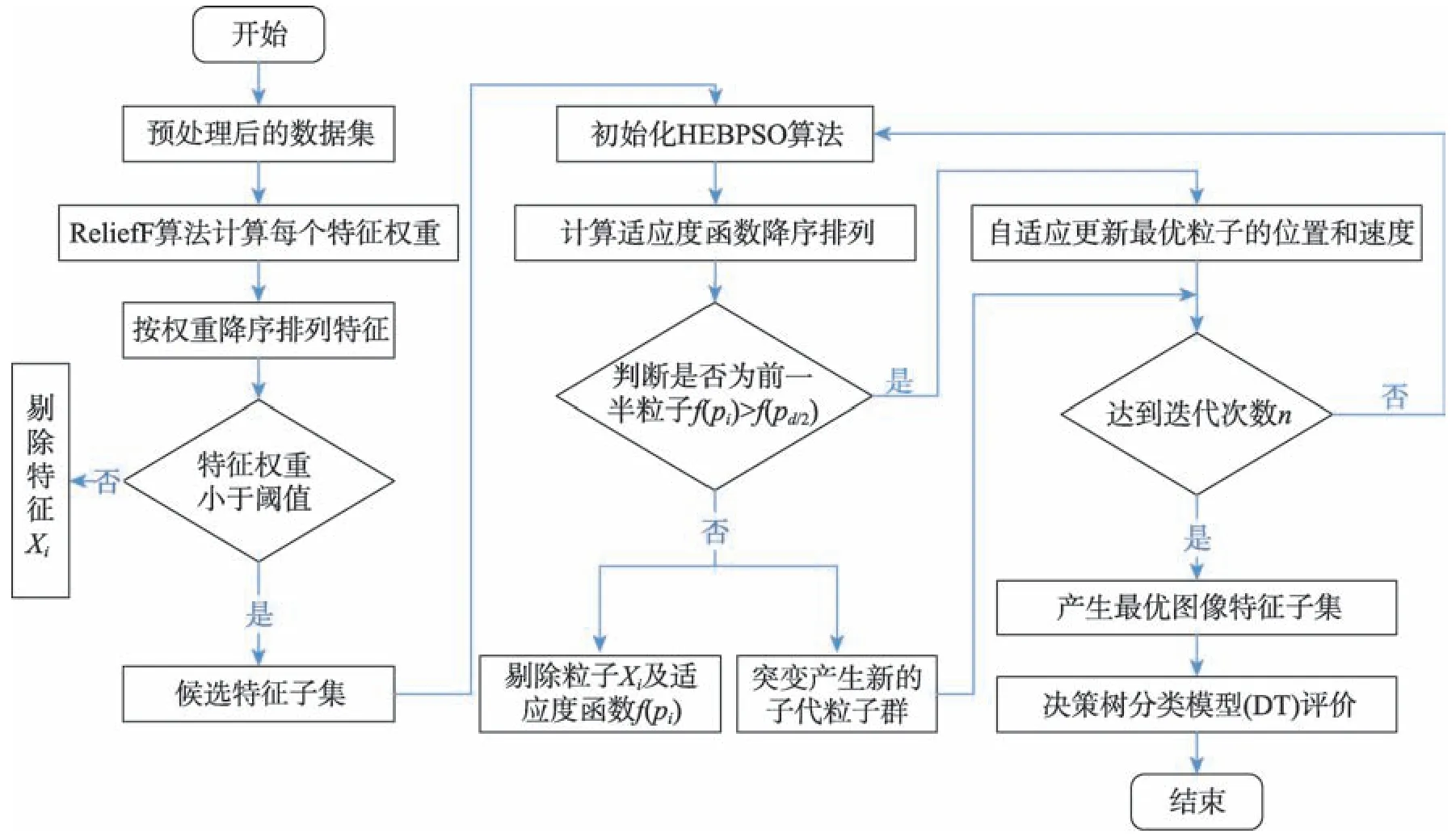
Fig.4 ReliefF-HEPSO multi-level pathological image feature selection algorithm图4 ReliefF-HEPSO 多层次病理图像特征选择算法
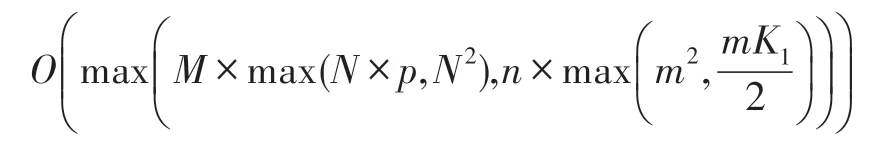
在空间复杂度方面,本文ReliefF-HEPSO 算法的HEPSO 比标准BPSO 算法在每次迭代中增加了常数量级的中间变量,如式(4)、式(5)中的σi(j)、等,以及与之相关的临时变量的存储,空间复杂度有所升高,但由于在迭代前使用ReliefF 算法大幅减少HEPSO 算法中作为输入的粒子向量长度,缩小存储空间,因此空间复杂度相比标准BPSO 算法仍有所降低。
在现代化技术支持下,建立智慧园区的总体构想,综合考量地块信息化差异。其一,应用系统层,主要包括园区控制云、园区管理云和园区服务云;第二,应用支撑平台层;其三,网络通信层;其四,智能感知层;其五,基础设施层。
3 实验结果
3.1 实验数据
实验数据采用由美国加州医院提供的真实患者数据集,其中关于患者个人敏感信息已被剔除,使用之前对数据集进行预处理。原始数据为患者的RT 病理图像,图像格式为dicom 的CT 图像,如图5 所示。
通过Ibex 软件[24]从患者的CT 图像中提取出数据形状为[59,1 387]的csv 格式文本数据。其中59 指共59 名患者作为样本参与预测,1 387 指提取出的图像特征共1 387 维。
每条患者数据包含形状、图像直方图强度、灰度共生矩阵、邻域强度差矩阵、灰度级游程长度矩阵和强度直方图高斯拟合共6 种特征类别。每类中通过不同的图像特征提取方法提取出图像特征,例如,形状中根据二元掩模中的相邻体素的3D 连通性来计算ROI 凸包的体积。每种方法对应1 个属性,共产生1 387个特征属性。全部特征的具体描述见文献[24]。
由于数据集为真实病例数据,其中存在部分信息缺失问题,使用整列特征的平均值来进行补全。对于部分特征属性,为避免某些数值较小的属性被隐藏掩盖,提高精度,对数据进行标准化处理。
医院原始数据给出的59 名患者的生存期(按月计算)分布如图6 所示。根据相关医学文献及医生经验分析,将59 名患者的生存期划分为3 类,分别用0、1、2 表示。其中,0~18 个月为第一类,用0 表示,共24 人;18~36 个月为第二类,用1 表示,共15 人;36~150 个月为第三类,用2 表示,共20 人。每类标签占总数的比例分别为41%、25%、34%。
3.2 实验设计
本文实验环境为Windows10 64 位操作系统,处理器为Intel i5-8250U,2.6 GHz,安装内存RAM 4.00 GB。软件环境pycharm 编译器,python3.5。
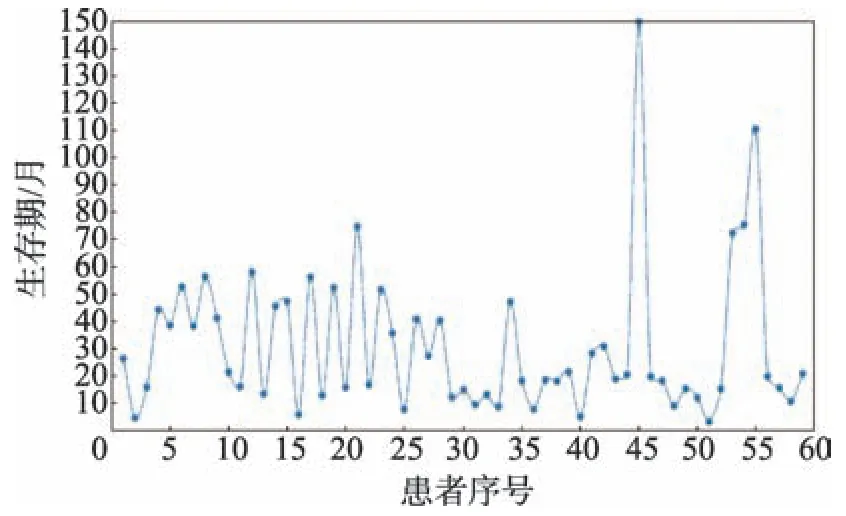
Fig.6 Label distribution of survival time图6 生存期标签分布
为了验证ReliefF-HEPSO 算法在头颈癌病理图像特征选择上的有效性和优越性,本文分别与未降维、特征降维方法——PCA、ReliefF 算法、混合鲸鱼优化算法(whale optimization algorithm-simulate anneal,WOA-SA)[25]、二进制粒子群算法(BPSO)、混合二进制进化粒子群算法(HEPSO)、ReliefF-BPSO 进行对比实验。
其中,WOA-SA、BPSO、HEPSO、ReliefF-BPSO和ReliefF-HEPSO 这5 种模型的最大迭代次数n取100。WOA-SA 模型其他参数根据文献[24]设置。BPSO、HEPSO 模型参数设置:种群规模m=50,学习因子c1=c2=0.5,惯性系数w=2.5,粒子最大速度Vmax=4,最小速度Vmin=-4。ReliefF-BPSO、ReliefF-HEPSO参数设置:抽样次数M=5,阈值∂=30 293.46,近邻样本数p=10,其他参数与BPSO、HEPSO 模型相同。ReliefF 参数:抽样次数M=5,阈值∂=50 588.91,近邻样本数p=10。
3.3 结果分析
针对Ibex 软件提取后的头颈癌病理图像特征数据集,实验使用原始数据(即未降维数据)、PCA、ReliefF、WOA-SA、BPSO、HEPSO、ReliefF-BPSO 和ReliefF-HEPSO 共8 种模型,分别得到真实数据集下的最优特征集合,并使用决策树分类模型作为分类器。
测试采用5 折交叉验证,计算正确率(accuracy)、精度(precision)、召回率(recall)、F1 分数(F1-score)和运行时间(单位:s),并通过比较8 种模型的多项分类性能指标及其特征子集规模,说明算法在特征选择和分类预测方面的能力。
决策树分类模型有以下分类性能评价指标:
(1)正确率
正确率是最常见的评价指标,accuracy=(TP+TN)/(P+N)。通常来说,正确率越高,分类器越好。其中,TP指被正确地划分为正例(P)的个数,即实际为正例且被分类器划分为正例的实例数(样本数);TN是被正确地划分为负例(N)的个数,即实际为负例且被分类器划分为负例的实例数。
(2)精度
精度是精确性的度量,表示被分为正例的示例中实际为正例的比例,precision=TP/(TP+FP) 。其中,FP(false positives)指被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数。
(3)召回率
召回率是覆盖面的度量,度量有多少个正例被划分为正例,即所有正例中被分对的比例,recall=TP/(TP+FN)=TP/P。其中,FN(false negatives)指被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数。
(4)F1 分数
F1 分数,也称为综合分类率,它被定义为精确率和召回率的调和平均数,F1=2×precision×recall/(precision+recall)。本文实验为3 分类,因此为了综合多个类别的分类情况,评测系统整体性能,采用宏平均F1(macro-averaging)。宏平均F1 先对每个类别单独计算F1 值,再取这些F1 值的算术平均值作为全局指标。由于宏平均F1 平等对待每一个类别,因此它的值易受到稀有类别的影响。
由表1 可得,PCA、ReliefF、WOA-SA、BPSO、HEPSO、ReliefF-BPSO、ReliefF-HEPSO 算法选取的特征子集规模较未降维前,分别减少93%、93%、57%、48%、51%、97%和98%。且在降维比例最低98%时,ReliefF-HEPSO 算法达到最佳的分类效果83%。
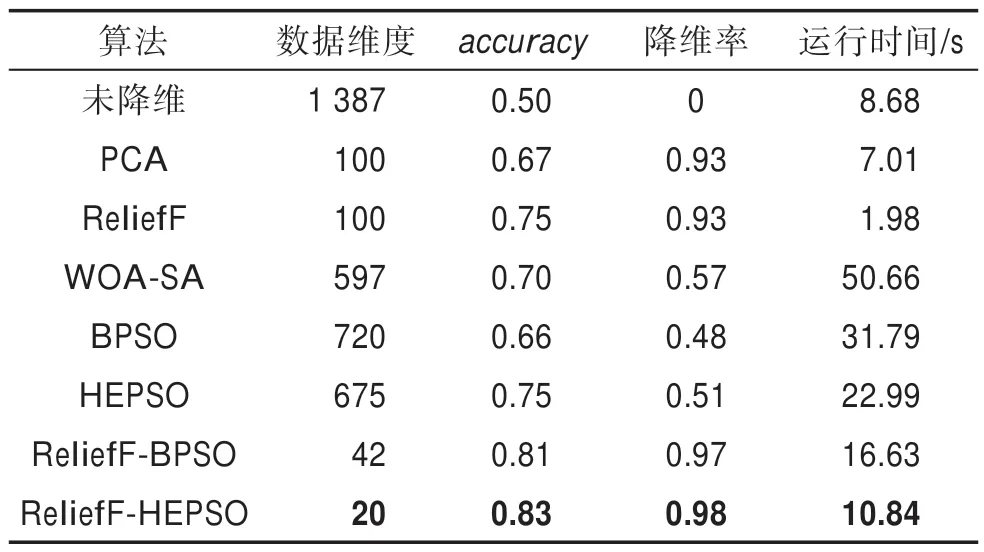
Table 1 Number of features under different algorithms表1 不同算法下的特征个数
PCA 和ReliefF 算法在降维率均为93%时在数据集上分类准确率分别为67%、75%,且均比未降维前数据分类效果好。因此,在本文数据集上,使用特征选择算法获得的分类性能效果较好。
在相同迭代条件下,HEPSO 的分类准确率为75%,比BPSO 高出9 个百分点,同时特征的降维率也提高了3 个百分点,特征个数相比BPSO 的720 个减少至675 个。ReliefF-BPSO 在降维率为97%时取得81%的准确率,ReliefF-HEPSO 的降维率为98%时,准确率为83%,特征个数相比ReliefF-BPSO 的42 个减少了52.4%。因此,HEPSO 比传统BPSO 在本文数据集上表现更好,以较高降维率取得较好分类性能。无论是BPSO、ReliefF-BPSO 还是HEPSO 与ReliefFHEPSO 相比,使用ReliefF 算法先进行低维特征选择的算法均能取得更好降维率并提升分类准确率。
WOA-SA 算法是Mafarja 在2017 年提出用于特征选择的启发式算法,并在UCI经典数据集中有较好表现效果。相同迭代条件下,由表1 可知,WOA-SA在降维率和准确率上分别为57%、70%,虽比传统BPSO算法的表现较好,但仍逊色于本文提出的ReliefFHEPSO 算法。
BPSO、HEPSO、ReliefF-BPSO、ReliefF-HEPSO的降维率分别为48%、51%、97%和98%时,分类准确率为66%、75%、81%、83%。随着降维率的提高,分类准确率也随之升高。但WOA-SA 中,降维率为57%时,分类准确率却仅有70%。因此,降维率与分类准确率成正比的关系,仅在一定区间范围内成立。随着降维率的升高,分类准确率在一定时刻达到最高,其后存在降低的可能性。
从运行时间角度分析,在相同迭代次数下,BPSO、HEPSO、ReliefF-BPSO、ReliefF-HEPSO 的运行时间分别为31.79 s、22.99 s、16.63 s、10.84 s,ReliefF-BPSO 和ReliefF-HEPSO 的运行时间分别比BPSO 和HEPSO 提高15.16 s、12.15 s 且没有降低分类性能。HEPSO、ReliefF-HEPSO 相比BPSO、ReliefFBPSO 运行时间也有所提升。由此可知,使用ReliefF算法先做低维特征选择能大幅减少运算时间,且保持较好分类准确率。
综上所述,ReliefF-HEPSO 算法在本文数据集上的特征选择能力优秀,能得到更小比例的特征子集;并且在原本千维级别特征的基础上,算法仅使用2%左右比例的特征即可达到最佳分类性能,运行时间也最短。因此,ReliefF-HEPSO 算法在较短时间内,既使得取得的特征子集规模更小,又能够保证获得最高分类性能,该算法很好地减小了数据规模,获得更高分类准确率,减少算法运行时间。
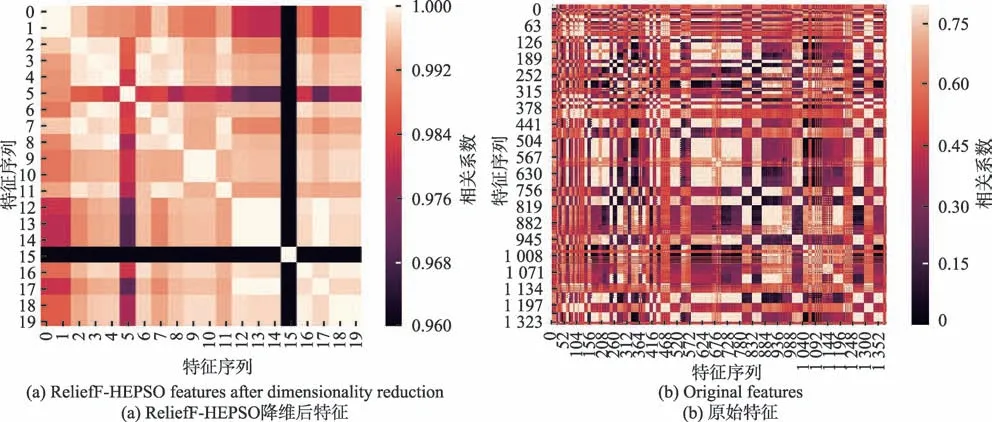
Fig.7 Characteristic heatmap图7 特征热力图
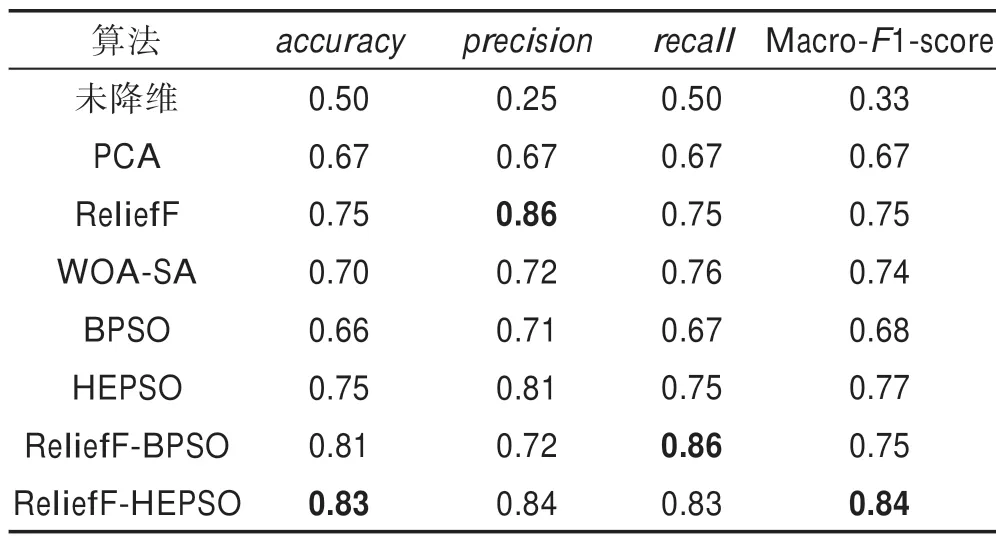
Table 2 Comparison of classification performance of different feature selection and dimensionality reduction algorithms表2 不同特征选择和降维算法的分类性能对比
8 种算法在决策树的多标签分类器下的分类性能如表2 所示。ReliefF-HEPSO 算法在各项度量参数上较之未降维、PCA、WOA-SA、BPSO、HEPSO、ReliefFBPSO 算法均有大幅提高。ReliefF-HEPSO 在分类准确率、召回率、F1 参数上较之ReliefF 算法有所提升,只有分类精度与ReliefF 算法基本持平。ReliefFHEPSO 在分类准确率、分类精度、F1 参数上较之ReliefF-BPSO 算法均有提升,在召回率上保持近似。ReliefF-HEPSO 算法较之未进行降维前的预测准确率提高33 个百分点。由上述结果可知,经过ReliefFHEPSO 算法进行头颈癌病理图像特征选择后的数据多项分类性能均得到了优化,整体表现优于其他算法。
图7 所示为最终选取的20 维特征的heatmap图像。
综上所述,ReliefF-HEPSO 算法能够有效地去除特征冗余,获得规模更小的特征子集,并且在整体性能上优于同类算法,经其输出的特征子集更加精简和有效。因此,本文提出ReliefF-HEPSO 多层次特征选择算法,并将其运用到头颈癌病理图像特征的选择中是可行的。经过特征选择后的病理图像特征可用于设计个体化放射治疗以潜在改善临床结果。
4 结束语
本文将特征选择方法运用于头颈癌患者的病理图像特征的研究中,提出了一种基于ReliefF-HEPSO的多层次特征选择方法。该算法首先利用ReliefF算法对病理图像的形态学特征进行快速降维,然后用特征权重较大的特征候选子集初始化粒子群,决策树分类器(DT)的分类准确率作为特征子集的评价函数,将离散二进制粒子群算法(BPSO)与进化神经策略(ENS)相结合,通过多次迭代得到最优特征子集。实验表明,与PCA、ReliefF、WOA-SA、BPSO、HEPSO、ReliefF-BPSO 这6 种模型比较,ReliefFHEPSO 算法更能有效剔除冗余特征,筛选出高相关性的病理图像形态学特征,在保证83.3%的分类准确率情况下,达到98%的降维率,同时保持较快的运算速度。ReliefF-HEPSO 算法构造了过滤型与搜索型算法相结合的多层次混合模型,不仅能够快速降低数据维度,而且能够自动确定最优特征子集,该算法为解决小样本高维问题提供了一种行之有效的方法。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
电子测试(2018年1期)2018-04-18 11:52:35
电子制作(2017年23期)2017-02-02 07:17:06
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
西北工业大学学报(2015年4期)2016-01-19 03:31:47
都市丽人(2015年4期)2015-03-20 13:33:22
电测与仪表(2014年15期)2014-04-04 12:05:20
