
一种基于高阶混合投影估计的网络嵌入方法
2020-04-15 02:58潘嘉琪邹俊韬
计算机技术与发展 2020年2期
潘嘉琪,邹俊韬
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
0 引 言
网络嵌入[1]因成功应用于节点分类[2]、链路预测[3]、节点聚类[4]和可视化[5]等实际网络分析任务之中,而在机器学习和数据挖掘领域得到了广泛的关注。它解决了传统以启发式方法构建网络特征而引发的高计算成本和不可追溯性的问题。
早期,网络嵌入被视为一种特殊的数据降维技术,其流程主要被分解为网络特征提取和数据降维两个独立的阶段。网络特征提取主要负责扩展和利用网络的局部或全局拓扑属性来构建网络相关的表示矩阵,而数据降维的本质就是使用如SVD[6]、IsoMap[7]和神经网络[8]等降维技术将输入数据线性或非线性地投影到低维空间以达到嵌入的目的。由于这类方法在潜在空间中缺乏对原始网络属性的建模表述以及不能够定义一个可解释的目标函数来迭代优化,所以在大部分网络相关的预测任务中表现出的性能差强人意。为了增强嵌入特征向量对原网络结构属性的表征能力和解释嵌入特征向量在潜在空间中的意义,近几年提出的方法试图在潜在空间中对节点之间的关系进行建模,从而在一定程度上耦合网络特征提取和数据降维两个先前独立的过程。通过定义一个迭代优化目标来捕获网络在原始结构空间中的性质,学习到的嵌入特征向量在某些特定的机器学习任务中具有更优良的性能。例如,基于网络局部结构信息,用概率的方式对目标节点及其邻近的上下文节点进行建模,可以让节点在潜在空间中的分布近似于在原始结构空间的分布。此外,网络中的节点通常趋向于某几个中心以形成社区结构,在同一社区内部的连接较为紧密,而在不同社区之间的连接较为稀疏,网络的社区性被证明可以保存全局的拓扑结构属性[9]。
为了嵌入网络社区结构与节点局部相似性,文中提出了一种基于高阶混合投影估计的网络嵌入方法,简称为HPNE。该方法使用混合概率生成模型对节点的社区性进行建模,并且融入了节点一阶相似性以防止过拟合现象,最后采用随机梯度下降的优化策略,迭代最大化极大似然函数以求得最佳嵌入结果。
1 问题定义
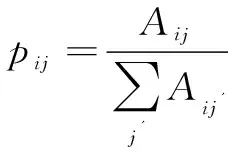
定义2(网络嵌入):给定一个网络G=(V,E),网络嵌入的目标就是学习一个映射函数f:VRd,将网络中的每个节点投影到一个d维的潜在空间,与此同时保留节点在原始结构空间中的性质。用ui表示节点vi对应的潜在特征向量。
定义3(节点相似性和相似性矩阵):节点相似性反映了成对节点在原始结构空间或潜在空间中的相似程度,通常由图核函数将其转化成特定的实值。由节点相似性构成的矩阵称为相似性矩阵。
2 基于高阶混合投影估计的网络嵌入方法
2.1 基于skip-gram和负采样的网络嵌入方法
skip-gram模型是用极大似然估计去刻画目标节点w及其上下文节点c共同出现的概率,它利用一个长度为T的滑动窗口从随机游走序列中构建目标-上下文语料集D={(w,c)|w∈V,c∈{wi-T,…,wi-1,wi+1,…,wi+T}}。文献[10]通过公式推导证明基于负采样下的skip-gram模型等价于对式做因式分解,即
(1)
其中#(w,c)、#(w)、#(c)分别表示目标-上下文对(w,c)、目标节点w和上下文节点c在D中出现的次数,b是负采样的数目。
文献[11]将现有的基于skip-gram和负采样的网络嵌入模型转化成了谱分解的形式,即
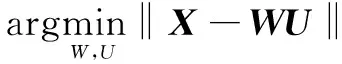
(2)
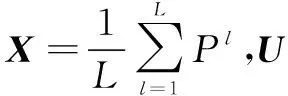
2.2 模型优化目标构建
基于谱分解的网络嵌入是将输入矩阵X∈RN×N直接线性地投影至低维潜在空间,从而生成网络的嵌入特征矩阵U∈Rd×N。从数据降维的角度看,谱分解只是减小原始数据和重构数据之间的误差,而并非是在潜在空间中对网络的特性进行建模。为了使得嵌入结果更好地保存网络的性质,文中引入一个可学习的线性正交算子W∈Rd×N来实现原始结构空间到潜在空间的映射,并在潜在空间中直接构建可解释的迭代优化目标函数来生成节点的潜在特征向量,其投影过程可以表述为:
u=Wx
(3)
其中,x∈RN表示节点在原始结构空间中的特征向量,u∈Rd表示相应的潜在特征向量。
然而,网络的稀疏性和搜索策略上的局限性会导致x及其真实值xtrue之间存在误差xnoise。为不失一般性,假设传播误差的分布服从各向同性高斯分布p(xnoise)~N(0,σ2I),其中σ2是模型的超参数[12]。
x=xtrue+xnoise
(4)
xnoise=x-WTu=(I-WTW)x
(5)
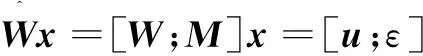
(6)
其中,M∈R(N-d)×N也是线性正交算子,有MMT=I。假设ε服从各项同性高斯分布p(ε)~N(0,σ2I),它具有和xnoise相同的噪声方差。由于u和ε相互独立,则输入数据x的极大似然概率为:
(7)
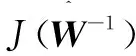
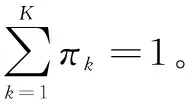
(8)
事实上,节点之间的关联可能会随着W的迭代优化而被破坏,即出现过拟合现象。这一方面是由于W的正交约束在每次迭代中不能总是被满足或只能近似满足,另一方面是由于网络的社区性会过分地弱化属于不同社区的两个节点之间的关联或过分地增强同一社区内的两个节点之间的关联。因此,为了防止上述过拟合现象,需要在每次迭代过程中重构节点的相似性来维持网络的局部结构。文中通过最小化先验概率和似然概率之间的KL距离来重构节点的一阶相似性,即
(9)
其中,σ(x)=1/(1+exp(-x))是激活函数。
综上所述,在联合嵌入社区结构和节点局部相似性后,最终的目标函数变成了最大化式(10),即
L=L1-αL2-βLreg
(10)
其中,Lreg是正则项,用于对投影算子W施加正交约束,α,β>0是权衡系数,Lreg是一个可微分的函数[13],定义如下:
(11)
其中,wi表示投影算子W的第i个行向量,且有‖wi‖=1,i=1,2,…,d。
2.3 模型迭代优化
文中采用随机梯度下降方法来优化式(10)中的目标函数。在每次迭代过程中,关键步骤就是计算正交投影算子W、混合高斯分类参数{θk,πk}和噪声方差σ2的偏导数。详细的优化流程如算法1所示。
算法1:基于随机梯度下降的优化流程算法。
输入:网络G=(V,E),嵌入维度d,混合高斯组件个数K,最大训练迭代次数T,学习速率η,权衡系数α,β
输出:网络嵌入特征矩阵U
2.随机初始化模型参数W,σ2,μk,Σk,πk(k=1,2,…,K)
3.fori=1 toTdo
4.计算嵌入特征矩阵U=WX
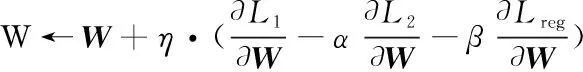
7.fork=1 toKdo //更新每个高斯混合组件的参数
8.根据式(16)~式(18)计算μk,Σk,πk的梯度,并做更新,即
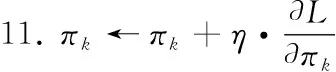
12.end for
14.end for
(1)L关于正交投影算子W的偏导数为:
(12)
其中,L1,L2,Lreg关于W的偏导数分别为:
(13)
(14)
(15)
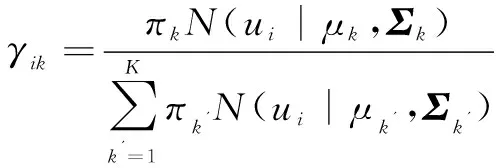
(2)L关于混合高斯分量参数{θk,πk}的偏导数为:
(16)
(17)
(18)
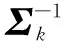
(3)对于噪声方差σ2,存在闭合解,即
(19)
3 实验仿真与结果分析
3.1 实验设置
3.1.1 数据集
为验证提出算法的有效性,采用4个真实的网络数据集,其相关的统计信息如表1所示。
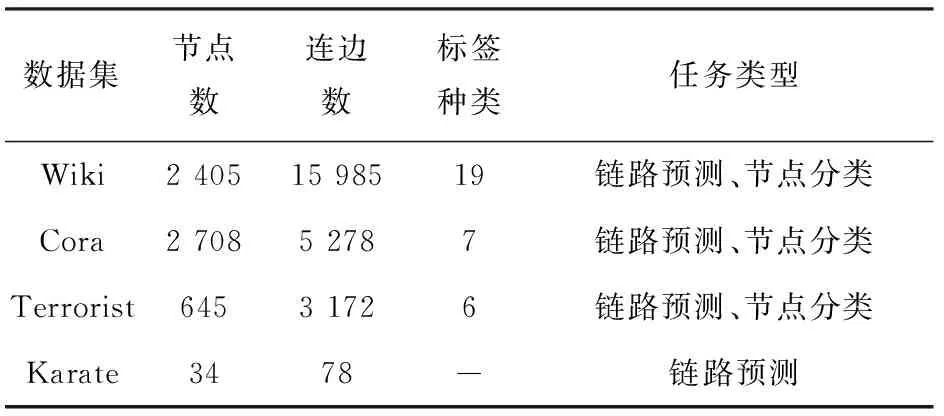
表1 实验网络数据的统计信息
Wiki包含2 405个页面,15 985个页面之间的超链接,一共有19种标签。
Cora是一个学术引用网络,其中每个节点代表一篇论文,连边代表论文之间的引用关系,每篇论文只含有1个标签。Cora总共含有2 708个节点,5 278条连边(移除了自连接的引用关联,原先有5 429个引用关联)。
Terrorist是一个恐怖袭击网络,其中每个节点表示一个恐怖袭击个体,且分配一个标签用于显示攻击类型。该网络一共含有645个节点(移除了孤立点,原先有1 293个节点),3 172条连边,6种标签。
Karate是一个小型网络,包含34个节点和78条边。
3.1.2 基准算法
DeepWalk[14]是典型的基于随机游走的网络嵌入方法,它在网络上执行均匀随机游走来构建语料集,并通过skip-gram模型训练得到网络的潜在特征。
Node2vec[15]在DeepWalk的基础上引入了两个参数p和q来控制二阶随机游走过程,以此来平衡深度搜索和广度搜索。
LINE[16]定义了节点的一阶、二阶相似度,并使用负采样的优化策略来最小化相似度先验概率和后验概率的KL距离。
GraRep[17]使用截断SVD方法来分解不同步长的高阶PPMI矩阵,并将各步长分解后的特征级联在一起形成网络的潜在特征矩阵。
3.1.3 实验参数设置
在和现有模型的对比实验中,除非特殊说明,否则对所有的网络而言,嵌入维度都默认设置为d=128。对于DeepWalk和Node2vec方法,窗口大小设置为10,采样步长为80,随机游走算子数为10。此外,Node2vec方法执行网格搜索p,q∈{0.25,0.5,0.75,1,4}来寻找性能最佳的控制参数。对于LINE方法,文中采用一阶相似度和二阶相似度相组合的形式,在基于随机梯度下降优化过程中,负采样数为3,学习率为0.01。对于GraRep方法,最高移动步长设置为6。对于HPNE方法,高斯混合组件数K的大小设置为标签的类别种数;在Karate网络中,权衡系数α=1,β=5,在Cora和Wiki网络中,α=0.01,β=0.02;在Terrorist网络中α=0.01,β=0.004;学习速率设置为0.01,最大迭代次数为100。
3.2 实验结果分析
3.2.1 链路预测任务
链路预测作为一项监督式学习任务,它根据节点之间的结构信息来推断其中存在连边的可能性。如果节点vi和节点vj之间存在连边,则连边eij的标签为1,否则为0。为了构建训练集Etrain,文中随机从边集E中抽取80%的边作为训练集中的正例样本,记为Etrain+,并且从不存在的边集Enon=V×V-E中随机抽取同等数量的边作为训练集中的负例样本,记为Etrain-,以此解决类不平衡问题。E中剩余20%的边将作为测试集中的正例样本,记为Etest+,而测试集中的负例样本则是从Enon中随机抽取和Etest+同等数量的边构成,记为Etest-。实验先在网络G=(V,Etrain)上执行网络嵌入算法来获得节点的潜在特征向量,然后借鉴文献[15]中定义的二元操作算子g(u,v)生成每条边的特征,最后使用scikit-learn库中的线性分类器SVM来训练和预测。
二元操作算子g(u,v)定义如下
Average:
(20)
Hadamard:
gi(u,v)=f(u)i·f(v)i
(21)
Weighted-L1:
gi(u,v)=|f(u)i-f(v)i|
(22)
Weighted-L2:
gi(u,v)=|f(u)i-f(v)i|2
(23)
其中,f(u)和f(v)分别表示节点u和节点v的潜在特征向量,f(u)i表示f(u)中的第i个元素。
文中使用AUC(area under the roc curve)指标评估链路预测的性能。实验结果如图1所示,对于Karate网络,HPNE在Average、Hadamard、Weighted-L2算子上将最佳基准线分别提高了17.64%、15.0%、8.7%,并在Weightd-L2算子上获得了最高AUC得分;对于Cora网络,HPNE在Weighted-L1、Weighted-L2算子上将最佳基准线分别提高了7.6%、10.5%,并在Weightd-L2算子上获得了最高AUC得分;对Wiki网络,HPNE在Hadamard算子上将最佳基准线提高了5.1%并且获得了最高的AUC得分;对于Terrorist网络,HPNE在Hadamard、Weighted-L1算子上分别将最佳基准线提高了0.4%、3.4%。总体而言,提出的模型在链路预测任务中和现有的网络嵌入算法相比,具有一定的优越性。
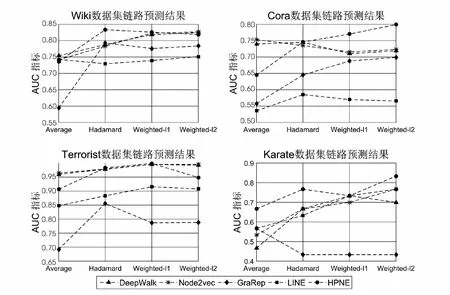
图1 链路预测结果
3.2.2 节点分类任务
在节点分类任务中,每个节点都分配有一个或多个标签。文中将节点的潜在特征向量随其标签一同作为输入,使用scikit-learn库中带有L2正则项的一对多Logistic Regression分类器进行分类。随机抽取10%到90%的样本作为训练集,其余作为测试集。在该任务中使用Micro-F1和Macro-F1指标对模型的性能进行评估,并且每个网络重复实验10次取平均结果,以避免偶然性。
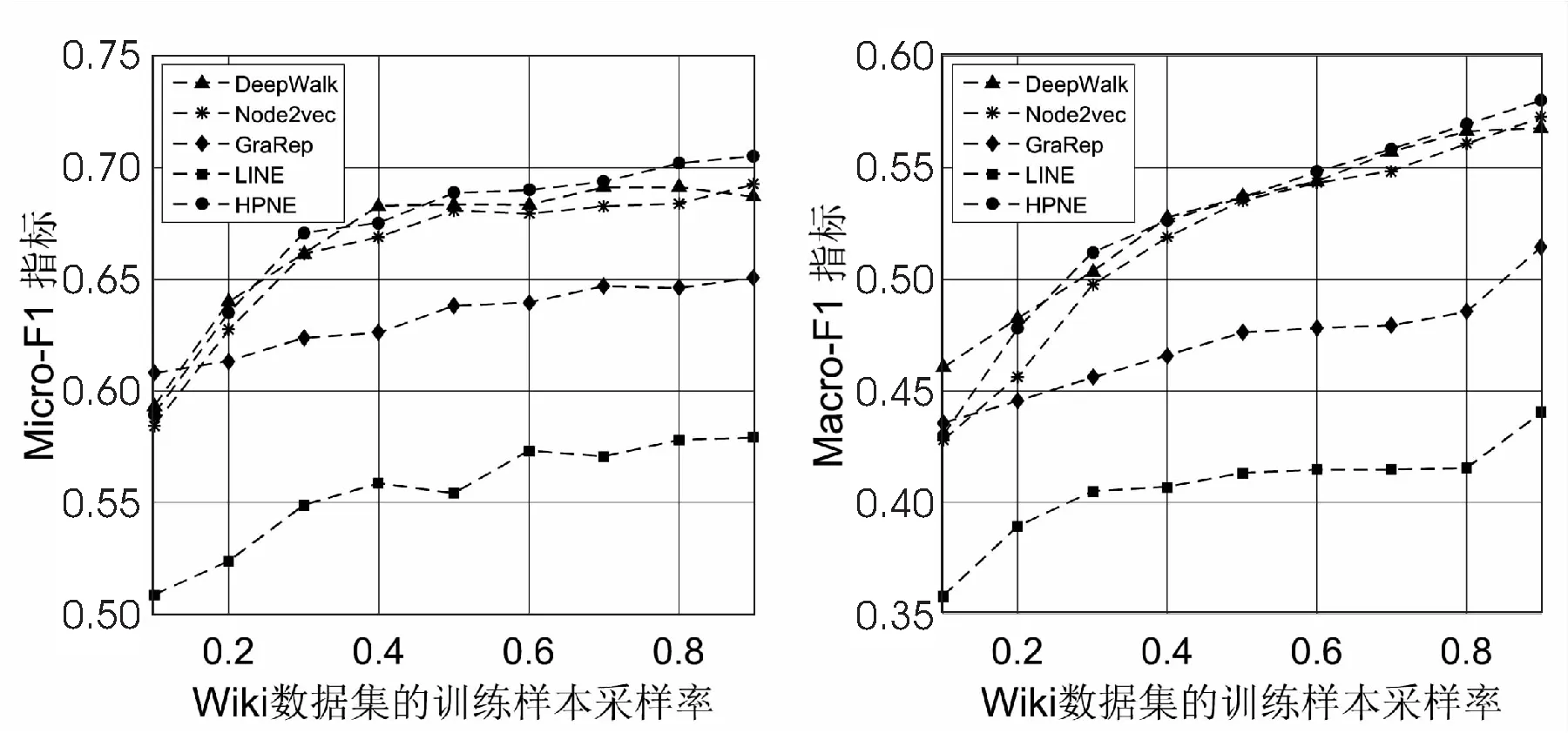
图2 Wiki数据集的Micro-F1和Macro-F1指标得分
如图2~图4所示,文中提出的HPNE算法在Micro-F1和Macro-F1指标下较其他算法都有一定的性能提升。对于Wiki网络,HPNE将Micro-F1和Macro-F1的最佳基准线分别提高了2.7%和2.2%,在训练样本的抽取比率小于20%时,DeepWalk和GraRep的性能优于HPNE,这是由于训练样本的规模太小而无法在网络中凸显社区结构导致;随着训练样本抽取率的提升,社区结构越来越凸显,HPNE的性能也逐渐提升。对于Cora网络,HPNE在Micro-F1和Macro-F1指标上比DeepWalk分别提高了1.3%-2.9%和0.74%-3.0%,比Node2vec分别提高了1.9%-2.2%和0.2%-2.0%,比GraRep分别提高了5.2%-11.0%和4.0%-9.2%,比LINE分别提高了21.6%-43.%和22.9%-40.0%。对于Terrorist网络,在训练样本抽取率为90%的时候,HPNE在Micro-F1和Macro-F1上拥有最大的性能提升,分别为6.95%和2.54%。综上所述,HPNE可以将网络的社区结构和局部节点之间的关联嵌入至潜在特征向量中,从而提高节点分类任务的预测性能。
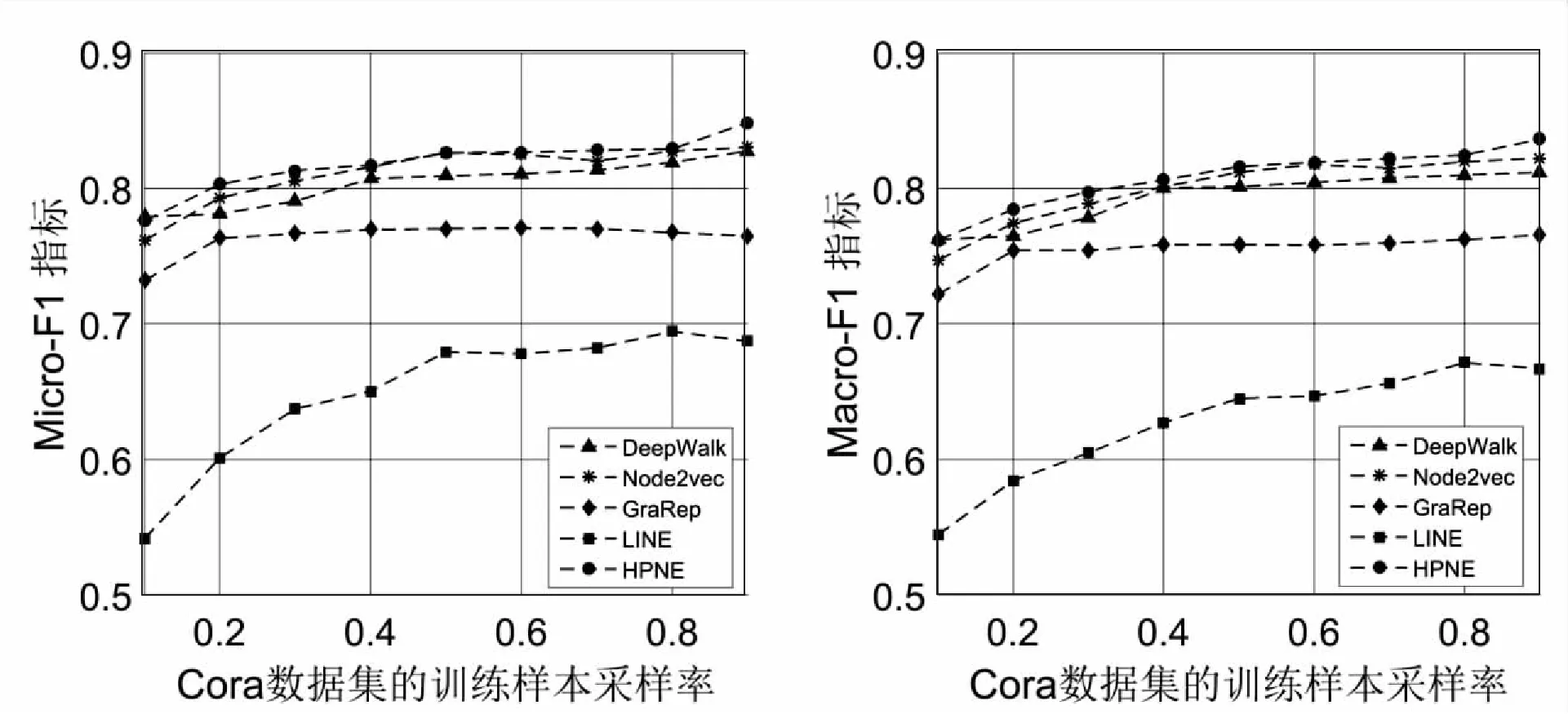
图3 Cora数据集的Micro-F1和Macro-F1指标得分
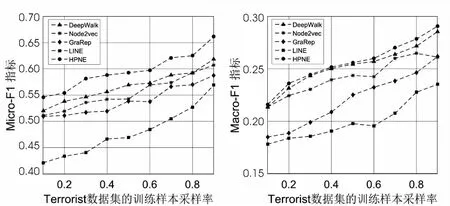
图4 Terrorist数据集的Micro-F1和Macro-F1指标得分
4 结束语
提出了一种基于高阶混合投影估计的网络嵌入方法,该方法借鉴谱分解的思想,利用线性算子将网络从高维结构空间投影至低维潜在特征空间,然后利用混合概率模型对节点的分布进行建模以刻画网络的社区性质。此外,在每次迭代的过程中还融入了节点的一阶相似性来防止过拟合现象。在实际的优化过程中,该模型的时间复杂度与网络的规模呈正相关,且采用随机梯度下降优化高斯混合模型参数时,需要对协方差做近似取舍。因此,如何有效地加速迭代优化过程和使用更合适的混合概率模型来对节点的分布建模是后期主要研究的问题。
猜你喜欢
保定学院学报(2022年2期)2022-04-07
云南大学学报(自然科学版)(2022年1期)2022-02-21
中学生理科应试(2021年11期)2021-12-09
现代英语(2021年18期)2021-11-22
校园英语·上旬(2020年1期)2020-05-09
数学学习与研究(2018年15期)2018-11-12
卷宗(2017年16期)2017-08-30
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
数理化学习·高一二版(2009年2期)2009-03-30
