
基于LSTM的藏语语音识别
2020-04-14 04:54郭龙银扎西多吉尚慧杰旦增
电脑知识与技术 2020年4期
郭龙银 扎西多吉 尚慧杰 旦增

摘要:针对藏语语音识别处理的步骤,首先将藏语语料的国际音标转换,其次根据人耳对语音的处理方式,使用MFCC进行语音特征提取,再构建CNN_BiLSTM_CTC声学模型,最后利用2-gram语言模型进行音标与文字的转换。该文最终实现语音转文本,并在音标识别上有较好的准确率。
关键词:藏语;语音识别;MFCC;CNN_BiLSTM_CTC;2-gram .
中图分类号:TP183
文献标识码:A
文章编号:1009-3044(2020)04-0154-02
藏语作为藏族的母语,同时也是中国重要的少数民族语言之一,其语音识别在信息化时代的如今,在解决语言沟通障碍,实时交流上的作用越来越受人重视。藏语主要分布于中国西藏自治区、青海、四川、甘肃、云南等省以及印度、尼泊尔、不丹锡金等国家地区,是国内外藏族同胞使用的主体语言[1]。目前实用型成果还未出现,本文是在深度学习方法上对其进行的研究。
1 MFCC特征提取
梅尔频率倒谱系数MFCC)是基于人听觉的屏蔽效应而来的,模拟人耳对于语音处理,其重点在于频域内波于波之间的i距离关系显得尤为清楚[2]。利用相关对数公式,在MEL频域内,将语音频率划分为MEL滤波器组,每个滤波器的中心频率由于屏蔽效应的非线性因素,使得其分布密度由频率而定,但前一个和后一个滤波器与当前滤波器有重合部分,以表征屏蔽效应。我们利用MEL滤波器组得到MEL频谱,在对MEL频谱:进行傅里叶逆变换得到的倒谱系数就是MEL频率倒谱系数(MFCC)。
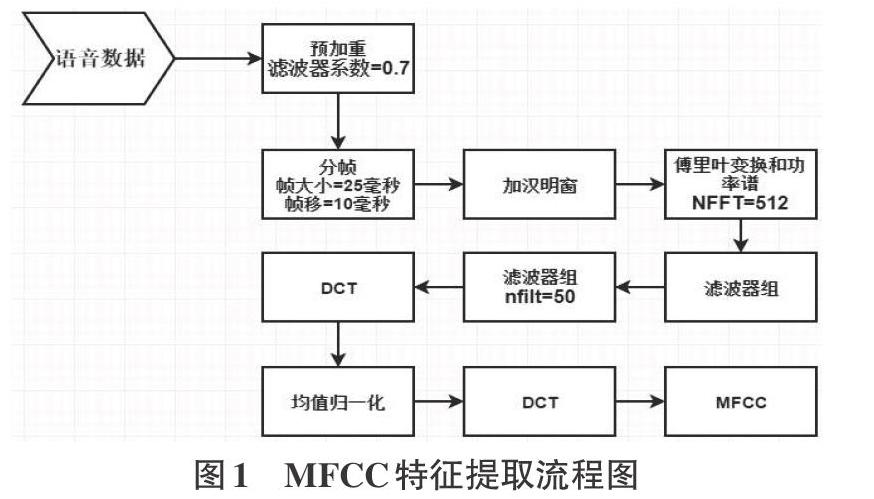
本项目的语音数据的采样率为16KHz,比特率256kbps,时长在6-10秒左右,大小在300kb左右,是句子级语音数据,文件质量高。对MFCC特征提取流程图如图1所示。
首先将语音数据转换成数字矩阵,这是我们利用数字矩阵画出的样例声音波形,如图2所示。
其次我们经过对MFCC特征提取后,再将所得的部分MEL频率倒谱系数画出相应的热力图,如图3所示。
2 声学模型
LSTM模型是目前流行的用来处理语音识别的模型之一,它是在RNN模型的基础上变形而成,用来解决当传播时间比,较长而弓|起的网络权重更新慢和梯度爆炸和消失问题[3]。这些问题会使RNN失去长期信息带来的长距离依赖,这使得他能够处理像语音处理这类与时间序列高度相关的问题。
LSTM相比RNN的多了输入门、遗忘门、输出门以及一个隐藏状态,这种隐藏状态包含将信息储存较久且选择性记忆网络误差回传参数的存储单元[3]。我们本文使用的前向传播计算公式如下:
wij表示从神经元i到j的连接权重,输入a用表示输出用b、d表示,主要激活函数为sigmoid和tanh两种,下标i、w、φ分别表示输入门、输出门、遗忘门,sct为细胞隐藏状态,I为输入层神经元的个数,H为隐层cell的个数,C为隐藏状态的个数。
LSTM的反向传播算法也是使用梯度下降法迭代更新所有参数,而计算方式则是基于损失函数的偏导数,在此便不予以展开。而本文使用的BiLSTM就是将LSTM的前向传播和反向传播算法相结合,类似BP算法包含前向和反向传播。
本文的总体模型是CNN_BiLSTM_CTC网络模型,模型先由CNN卷积提取特征、池化层缩减模型大小一般该维度的值缩小一半,并提高特征鲁棒性,而由于我们的模型层数较多且较为复杂,在每一次卷积层和池化层以及随后的BiLSTM层都要有dropout操作,这可以忽略部分的特征检测器,从而丢弃部分输出以防止过拟合现象。在网络最后生成的输出序列中会产生与原先的输入label序列不能一一對其,CTC(Connectionist Temporal Classification)则能有效解决此问题,它使得模型的输出能够消除由于音素特征训练产生的重复结果,最终使得输出序列与输入序列一一对应,完整模型总体较为复杂,在此仅显.示部分涉及BiLSTM的结构图,如图4所示。
3 语言模型
我们在训练的语料库分为(卫藏拉萨方言)语音数据、对应的藏语文本、对应的国际音标文本。在声学模型中输入输出的是国际音标序列,通过2-gram语言模型,,使用隐马尔科夫链寻找音标序列对应的文字概率序列。
2-gram语言模型,就是两个字为一组,将所有语句从第一个字开始与第二个字为宜组,然后第二个字开始与第三个字为一组,再第三个……逐字进行化组,然后建立相关2-gram词典,然后每次化组都会更新词典生成新组或增加某一组频率值。
对于藏语的国际音标我们采用龙从军等人的藏语国际音标转换方案。从藏文文本到国际音标的转换总体上需要经过三个大的阶段,首先是分词,其次是音标转换,最后是变音变调[6]。
4 实验结果
本文语料数据一共40200个语音语料,以9:1切分语料为训练语料和测试预料。训练出的声学模型的训练PER值为28.34%,测试PER值为35.51%。而由于语言模型较差,在转文字的正确率上只有训练数据的单字能有70%以上。
5 结束语
本文最终实现了从语音到文本的识别,虽然语料能够满足,但由于存在国际音标转换复杂性,实践上有部分的错误,音标转换不够准确,且音素转文本的语言模型很简单,未能将语言模型进行深度学习的训练,使得在转文字上错误了大幅上升。
对于藏语语音识别而言,有一套快速而又成熟的国际音标转换方案显得迫在眉睫,这可以使得更多的人能够参与藏语语音的识别且能让研究者将精力从语料准备上抽离出来,更好的编写声学模型和语言模型。
参考文献:
[1]姚徐,李永宏,单广“荣,等.藏语孤立词语音识别系统研究[J].西北民族大学学报:自然科学版,2009,30(1):29-36+50.
[2]BARUA P,AHMAD K,KHAN A A S,et al.Neural networkbased recognition of speech using MFCC features[C].International Conference on Informatics,Electronics & Vision.IEEE,2014:1-6.
[3]赵淑芳,董小雨.基于改进的LSTM深度神经网络语音识别研究[J].郑州大学学报:工学版,2018,39(05):63-67.
[4]余凯,贾磊,陈雨强,徐伟.深度学习的昨天、今天和明天[J].计算机研究发展,2013,50(9):1799-1804.
[5]史笑兴,顾明亮,王太君,等.一种时间规整算法在神经网络语音识别中的应用[J].东南大学学报,1999,29(5):47-51.
[6]龙从军,刘汇丹,吴健.藏文国际音标(拉萨音)自动转换研究[J].中文信息学报 2016,30(5):203-208+214.
[通联编辑:代影]
猜你喜欢
客联(2022年2期)2022-04-29
中国音乐学(2020年2期)2020-12-14
新教育时代·教师版(2019年16期)2019-06-17
西藏研究(2017年3期)2017-09-05
现代交际(2016年24期)2017-04-14
传播与版权(2017年11期)2017-03-28
唐山文学(2016年2期)2017-01-15
新课程(2016年3期)2016-12-01
西藏研究(2016年5期)2016-06-15
文理导航(2015年33期)2015-11-19
