
基于去噪自编码器和长短时记忆网络的语音测谎算法
2020-04-09 14:49傅洪亮雷沛之
计算机应用 2020年2期
傅洪亮,雷沛之
(河南工业大学信息科学与工程学院,郑州450001)
0 引言
测谎的重要性不言而喻,自20 世纪末,谎言检测逐渐在刑侦、国安、民事仲裁等方面得到了广泛的应用。人们在说谎时往往会伴有心理变化,这种变化会导致部分声音特性的改变,这就使利用语音进行测谎具有了可行性[1]。而且与以往的测谎方法相比,语音测谎有操作简单、成本低、结果更客观等优点,因此,研究语音测谎具有重要的现实意义和使用价值。但是语音测谎是一项具有挑战性的任务,因为目前还不清楚运用语音中的哪些特征可以高效地分辨谎言和真话。以往的研究中,部分研究者仿照语音情感识别中传统的特征提取方法,使用基于先验知识的人工设计的特征LLD(Low-Level Descriptor)和它的统计函数HLSF(High-Level Statistic Function)进行谎言检测。LLD 可以描述短时语音的语音特性,包括韵律、音质等特征,具体来说,常见的LLD 包含基频、能量、过零率、线性预测倒谱系数、抖动等;与此同时,HLSF作为LLD 的统计量主要描述了语音的全局动态变化,包括最大值、最小值、方差、偏度等[2]。例如,Ekman 等[3]通过收集受试者对于某些电视片段的观后感来进行语料采集,分析后发现谎言和真话的基频部分有明显差异;Hansen 等[4]利用梅尔频率倒谱系数以及它的一阶差分、自相关函数和互相关函数等构造出一组特征进行谎言检测。然而这些人工设计的特征是较低级的,提供的信息不能全面地体现出说话人在语音中表达的主观状态,这些特征中的冗余信息也会干扰识别,更糟糕的是,仅凭先验知识很难选择出真正有效的特征,该过程还会花费研究者大量的时间。
近几年,深度神经网络在语音识别、图像处理等领域取得了优异的性能,利用深度学习提取出语音特征并进行测谎也引起了研究者的关注。深度学习可以从语音中学习到更高级的 深 度 特 征,如Zhou 等[5]用 深 度 置 信 网 络(Deep Belief Network,DBN)将语音的稀疏表示作为输入进行测谎;Srivastava 等[6]提取语音中的基本特征后,利用多层神经网络和支持向量机(Support Vector Machine,SVM)进行谎言检测。然而这类测谎方法也有其缺点,它没有考虑到语音中基于先验知识的人工特征信息,相当于丢弃了语音中的这部分信息,进而影响了识别结果。有研究表明,人工统计特征和深度学习技术提取出的特征存在着各自的特征空间,可以从不同的角度来描述语音的主观情感状态并具有互补性,然而目前还没有将其融合在一起进行语音测谎的研究。
针对这些问题,本文提出了基于去噪自编码器(Denosing Autoencoder,DAE)和长短时记忆(Long Short Term Memory,LSTM)网络的多特征融合语音测谎算法,在特征和模型方面都做了改进,旨在从语音中获取更丰富的有助于识别谎言的信息。在特征方面,本文算法根据2009 年情感识别挑战赛制定的特征集,从语音中提取出共384 维的特征及其统计函数值;此外,还提取出每条语音的Mel谱。对于提取出的人工统计特征,先使用优化后的DAE 进行处理,去除其中的冗余信息并提炼出更鲁棒的特征,对于Mel谱特征,将其输入到在语音识别领域表现卓越的LSTM 模型中,逐帧学习语音的深度特征以保留语音中的所有情感细节信息。在模型方面,所提算法将传统DAE 中的每一层都加入批归一化(Batch Normalization,BN)以提高模型收敛速度,且在批归一化层之后还加入了dropout 以防止过拟合,并放弃了传统的ReLU(Rectified Linear Unit)、tanh(tanhyperbolic)等激活函数,选择ELU(Exponential Linear Unit)作为激活函数。之后,将优化后的DAE 和LSTM 并行连接在一起,将两类特征同时输入模型进行处理,并将融合特征输入softmax 分类器中进行分类。最后在2个谎言语料库上对所提算法的有效性进行了验证。
1 算法介绍
1.1 语音特征提取
1.1.1 人工统计特征
基于人类先验知识的人工特征和统计函数种类丰富,仅凭主观随机挑选部分特征会丢失许多信息,因此,本文算法使用2009年情感识别挑战赛规定的特征集[7]。该特征集是语音处理领域权威的人工统计特征集,制定者选择了在语音的韵律、音质等方面应用最为广泛的特征和函数,包括16 个LLD及其一阶差分和12 个HLSF,如过零率、谐波噪声比、基频和最大最小值、均方误差等,具体信息如表1 所示。为了保证实验的可复现性,本文使用opensmile[8]开源软件从语音中提取这些特征,最终每条语音都得到16×2×12=384维特征。

表1 2009年国际语音情感识别挑战赛特征集Tab.1 Feature set of 2009 International speech emotion recognition challenge
1.1.2 Mel谱
与人工特征不同,Mel 谱从另一个角度描述了语音中的细节信息。Mel 谱将语音建模成图像,它不仅包含了丰富的时频特性,而且语音中的主观情感在不同时间频率下的变化也可以从谱图中得到。本文算法首先对语音信号进行预处理,这一步的目的是为了消除说话人口唇辐射的影响,增加语音的高频分辨率,之后使用1 024 长度的汉明窗及512 长度的帧移对每条语音进行加窗分帧,在本文中,采用64个Mel滤波器来过滤语音信息以保证每帧的信息细节程度相同。最终得到的Mel谱维度如式(1)所示:

其中:F 是Mel 滤波器组的大小,为64;T 为帧数,因为每条语音长度不同,因此T也不一样。
谎言和真话的Mel 谱图样例如图1 所示,Mel 谱图中横坐标表示帧序号,纵坐标表示频率,图中颜色的深浅代表着特定频带能量的大小。
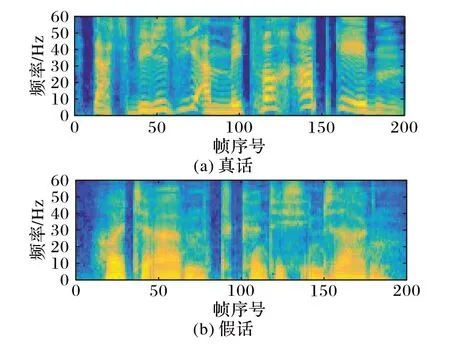
图1 真话和谎话的Mel谱图Fig.1 Mel spectrum of truth and deception
1.2 基于去噪自编码器和LSTM的特征融合
1.2.1 基础模型
1)自编码器由编码层、隐含层和输出层组成,数据经编码层映射到隐含层,之后再通过解码层尽量恢复出原始数据,它经常被用来提取数据中的高级特征[9]。去噪自编码器(DAE)是其经典的变种,如图2 所示,它向原始数据中加入部分干扰元素,DAE 需要克服这些杂质的干扰以重构出原始数据,因此可以提炼出更具鲁棒性的特征。它的编码过程和解码过程分别如式(2)、(3)所示:

其中:F 为非线性激活函数,一般为sigmoid 或ReLU 函数;W1、W2为编码网络和解码网络的权重矩阵;B1、B2为偏置向量;X为加入噪声后的数据;Y 为隐含层数据,即提取出的鲁棒特征;Z 为输出层数据。它在训练时利用反向传播算法来最小化重构误差,其误差函数可以表示为:

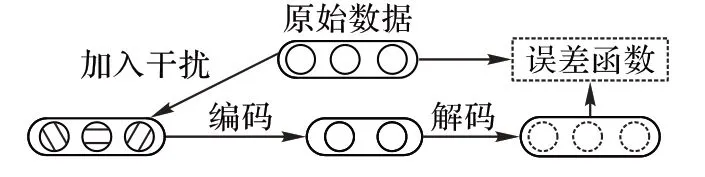
图2 去噪自编码器Fig.2 Denoising autoencoder
2)长短时记忆网络。语音中的信息是按序列进行编码的,而循环神经网络(Recurrent Neural Network,RNN)在处理序列问题时有明显的优势。LSTM 是为了解决RNN 长程依赖问题的特殊类型[10]。如图3 所示,它的内部单元结构比RNN更复杂,输入门、输出门、遗忘门这三个门控制着信息的流向,因此它可以有效地存储和更新上下文信息。LSTM 每次的输入包括当前时间点的输入值xt、前一时间的单元输出值ht-1和最后的单元状态Ct-1三部分,最终将当前时刻的输出值和当前状态值一并进行输出。
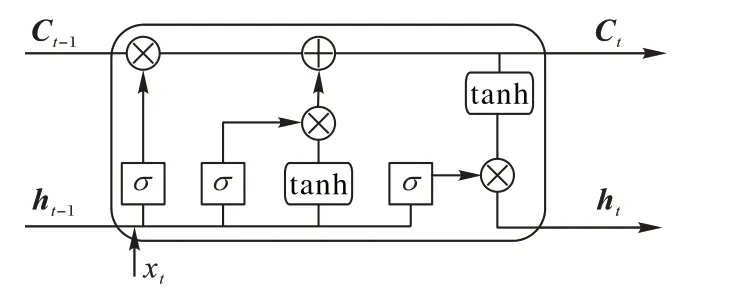
图3 LSTM结构Fig.3 Structure of LSTM
遗忘门确定以往信息的丢弃或保留,它通过读取当前输入和上一时刻的输出来确定最终的结果是0 还是1,0 代表完全丢弃,1代表完全保留。

然后输入门决定需要更新的信息并将单元状态由Ct-1更新为Ct:
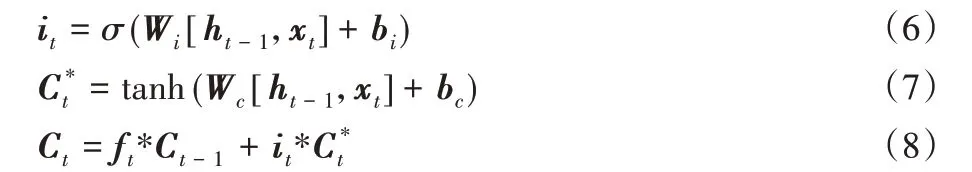
最后输出门决定当前的状态值有多少成为当前时刻的输出值。
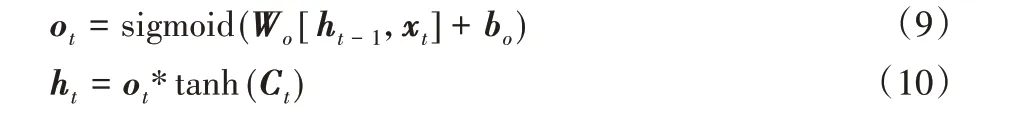
在上述公式中,σ 代表sigmoid 激活函数,这样每个门的输出都是0到1之间的值,Wf、Wi、Wc、Wo和bf、bi、bc、bo分别代表权重和偏置向量。
1.2.2 本文设计的模型及特征融合
DAE在去除冗余信息、提取鲁棒性特征等方面表现良好,LSTM在处理序列问题时能保证数据的前后依赖关系,因此本算法设计了如图4所示的用于特征融合的模型。对于DAE部分,算法采用两层神经网络来分别组成编码和解码部分,并在每一层之后都加入了批归一化(BN)来加快模型收敛和提高模型的稳定性;因为语音测谎是二分类问题,在数据量有限的情况下容易过拟合,因此在批归一化之后加入了一定比率的dropout,使部分神经元处于暂停工作状态,这样可以有效地避免过拟合的发生。同理,LSTM 也加入相同比率的dropout。之后将DAE 和LSTM 进行并联组合(Parallel connection of DAE and LSTM,PDL)以对不同的特征同时进行处理,模型的最后为全连接层(Fully Connected Layer,FC)和分类器。这是本文后续实验的基本框架。
如前所述,人工特征和深度特征具有不同的特征空间并有互补性,因此本文算法使两类特征协作以充分利用语音中的情感信息,进而获得更好的识别效果。本文算法使用特征融合而不是决策融合,这是因为特征融合设计成本低、计算方便,在许多系统中都得到了应用[11]。此外,算法所设计的模型是并行连接且同时工作的,在训练时需要同时将不同的特征输入到对应的模块中进行处理并融合。这也是该模型的先进性之一,同时处理特征能确保特征的一致性,在优化模型参数时也能保证不同的特征对融合特征的贡献度达到最优,而不是简单的特征堆叠。下面介绍特征融合的过程。
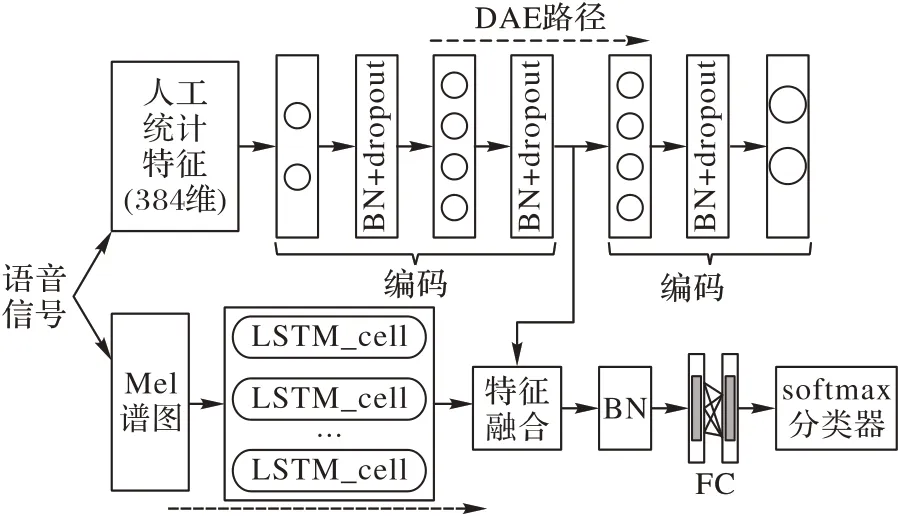
图4 本文算法的整体框架Fig.4 Overall framework of the proposed algorithm
对于人工统计特征,在模型工作时将其输入到优化后的DAE中,设输入为x1,提取到的鲁棒特征(即待融合的特征)为F1,输出的数据为x2,那么DAE 自身的重构误差L1计算如式(11)所示:

同时,用LSTM学习Mel谱中的帧级深度特征,流程如图5所示。LSTM 需要一样维度的输入,然而语音是不等长的,因此分帧后的长度也不相同。为了解决这个问题,本文采用补零的方式让每条语音Mel 谱的维度保持一致,补充的零不涉及单元内的参数更新,所以不会影响LSTM 对深度特征的提取。经补零后,CSC(Columbia-SRI-Colorado)库中提取出的Mel谱维度都是(1 190,64),Killer库中提取出的Mel谱维度都是(709,64)。由于Mel 谱是将语音分帧后提取的,因此LSTM的输入是组向量[m(1),m(2),…,m(T)],T 为语音的帧数,m(t)为对应帧的Mel 谱;经过LSTM 的学习后,可以得到语音的帧级深度特征[n(1),n(2),…,n(T)]。进一步地,为了使LSTM学习到更丰富的信息和提高模型的稳定性,本文将对帧级深度特征进行平均处理后(如式(12)所示)得到的F2作为待融合的特征。

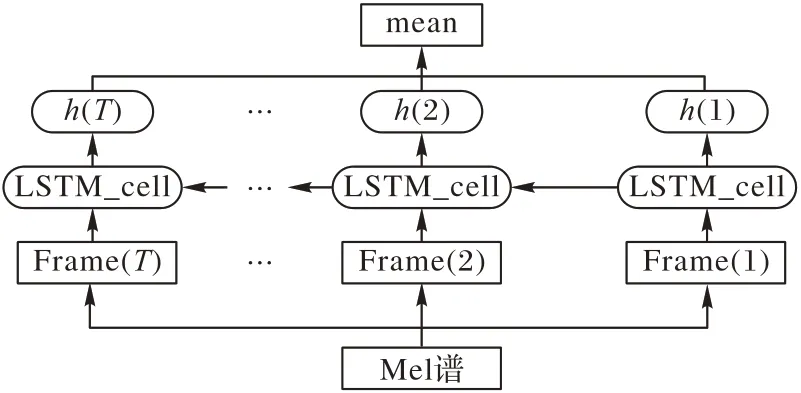
图5 LSTM提取帧级特征Fig.5 Extracting frame-level features with LSTM
得到两类待融合的特征后将它们先进行批归一化处理,这一步的目的是消除不同的最大最小值对融合效果的影响,之后再对两类特征进行串联,即得到了两类特征的组合F=[F1,F2]。然后将F 作为下一全连接层的输入,全连接层的作用是将它们投射到相同的特征空间中并减少特征维度。特征维度对识别效果有一定的影响,维度过大则冗余信息增多,过小则会丢失信息,本文参考了文献[12-13],经过多次实验后,将经DAE 处理后得到的特征的维度设为1 024,经LSTM 得到的深度特征维度也设为1 024,全连接层的维度设为1 024(模型参数的详细信息见实验部分),即最终得到了1 024 维的融合特征,最后使用softmax 分类器对融合特征进行分类,输出该语音是真话还是假话的概率。
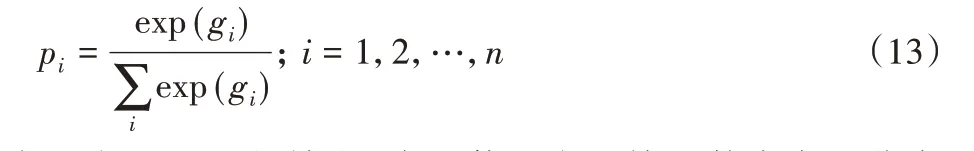
其中gi为softmax 的输出,本文使用交叉熵函数来定义分类误差:

其中yi为语音对应的真实标签。因为在模型工作时,DAE 从人工统计特征中提取出更鲁棒的特征和LSTM 从Mel 谱中学习帧级深度特征是同时进行的,所以最终的误差函数为:

模型训练时,本文采取小批次随机梯度下降法来最小化误差函数[14],这种方法不仅训练速度快,而且在每次更新参数时都使用了全部的训练样本,可以得到全局最优解。
2 实验与结果分析
2.1 数据集
为了验证本文所提算法的有效性,本文在CSC 库和自行构建的谎言语料库中进行了实验。CSC 语音库是美国哥伦比亚大学录制的用于语音测谎研究的专业数据库[15],参与录音者都是该校的师生,共32 人,男女各占一半。录制以访谈形式进行,受试者被告知参加一个“寻找美国顶级企业家”的活动,并努力使面试官相信自己符合所规定的条件,最终生成约7.5 h的语音数据,本文从中剪取了5 400条语音(谎言语音为2 209条),其中包含了4 860条训练数据,540条测试数据。
此外,参照瑞士Idiap 机构建立的Idiap Wolf 数据库的规则及流程[16],本文还自行构建了用于语音测谎研究的语料库。先是选择了网络上近50 h 的“狼人游戏”和“杀手游戏”视频,在游戏中,平民和警察需要找出场上的所有杀手,杀手则需要找出所有警察,玩家需要掩盖自己的身份并进行逻辑推理,因此参与者有了充分的说谎动机。每场“狼人游戏”参与者为12 人,每场“杀手游戏”参与者为16 人,剔除重复参与者后的详细人数见表2。之后用Cooledit 软件从中提取语音,并邀请多人进行听辨检验,去除低质量和难以听清的部分后,从中剪切出987 条语音(谎言语音为510 条),其中包含了890 条训练数据和97条测试数据。将该语料库命名为Killer语音库。

表2 游戏玩家人数Tab.2 Number of players in games
2.2 实验设置及评价指标
本文所做实验均基于谷歌的开源深度学习框架tensorflow,显卡为GTX 1080ti。所有实验均重复10 次并求其均值,以消除偶然误差影响。模型中各个部分的参数如表3所示。
将系数为0.3 的高斯噪声加入人工特征作为DAE 的输入,激活函数选择Elu,在模型训练时采用小批次随机梯度下降法,学习率设为0.000 01,dropout统一设置为0.6,训练最多迭代100次。
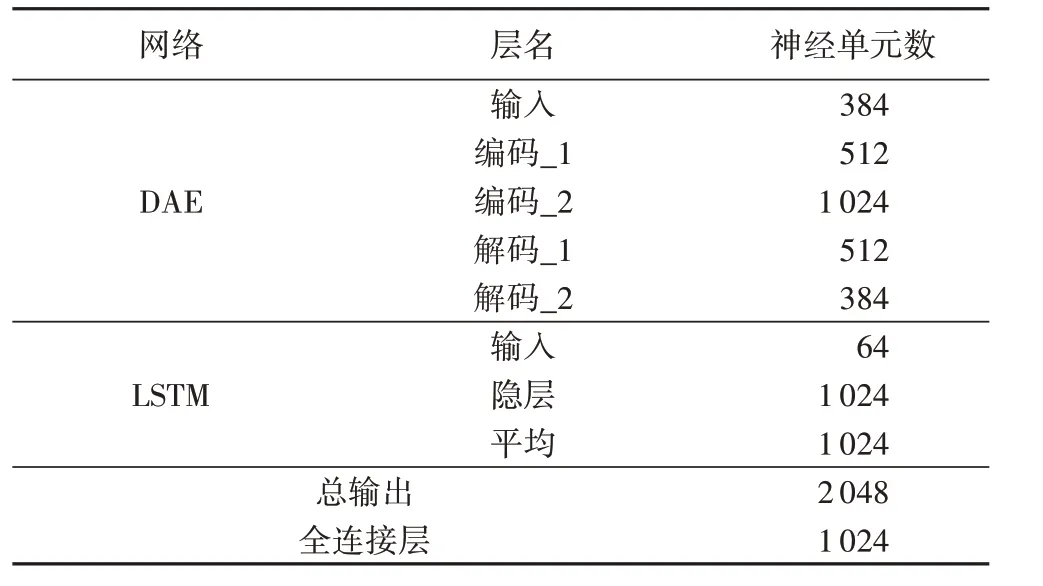
表3 模型参数Tab.3 Parameters of model
本文选取加权平均召回率(Weighted Average Recall,WA)和非加权平均召回率(Unweighted Average Recall,UA)作为识别性能的评价指标。WA 是正确识别的样本数和所有样本数的比值,UA是该类中正确识别的样本数和该类总数的比值,这是语音测谎领域常用的评价指标。
2.3 实验结果及分析
为了验证使用所提出的DAE-LSTM 并行融合特征相较于仅使用单一特征时对分类效果的影响,本文分别去掉模型的DAE 部分和LSTM 部分,只保留其一,在其他参数保持不变的情况下,观察它们各自的谎言识别情况。
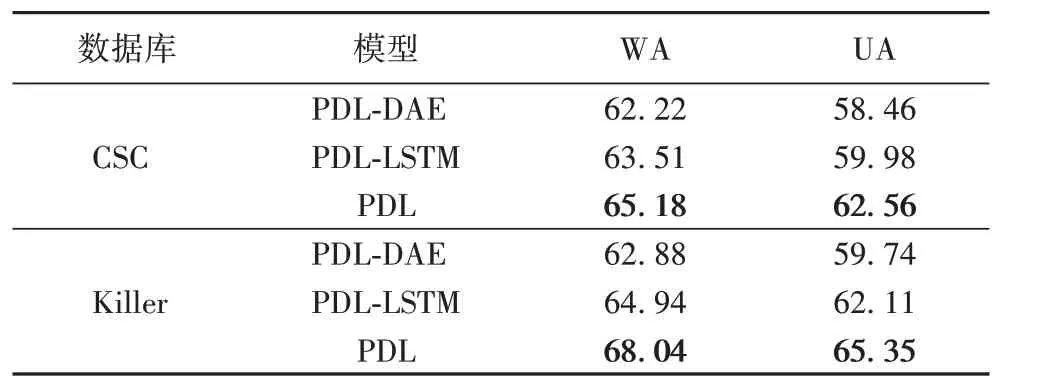
表4 不同模型的识别精度 单位:%Tab.4 Recognition accuracy of different models unit:%
从表4中可以看到:所提并行模型在CSC库上的WA达到了65.18%,UA 达到了62.56%;在Killer 库上的WA 达到了68.04%,UA 达到了65.35%。相较于仅使用单一特征,并行模型的识别性能有了较大提升。
结合收敛曲线图6 可以看出:并行模型的收敛曲线更平滑且能较快地达到收敛,说明所提模型的稳定性较高;Killer库上的收敛曲线较CSC库有更多的波动,原因在于Killer库的语音数量较少,且人数多于CSC库,因此相对来说较难收敛。
此外,本文还对测试结果进行了T 检验(显著性检验),目的是验证在不同数据集中,PDL模型对识别效果的改善情况。根据T 检验的理论,需要先计算出两组数据存在差异的概率(P 值),然后根据此值来判断它们是否存在显著性差异,一般来说当P 值小于0.05 时,两组数据存在显著性差异[17]。检验结果如表5 所示,可以看出,在不同的数据集上,PDL 模型与单独的DAE 和LSTM 模型相比,P 值都小于0.001,因此,所提模型对识别效果有明显的改善。
在本文算法中,将人工统计特征用DAE 进行处理这一步十分关键,如果不利用DAE 提取原始特征中更具鲁棒性的特征并去除掉包含在内的冗余信息,可能会影响分类效果,为了验证这一点,本文还将未经DAE 处理的人工统计特征直接和深度特征相结合进行测谎,得到的实验结果如表6所示。
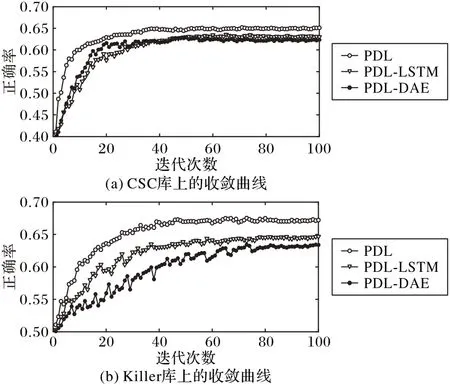
图6 不同语料库上的收敛曲线Fig.6 Convergence curves on different corpora
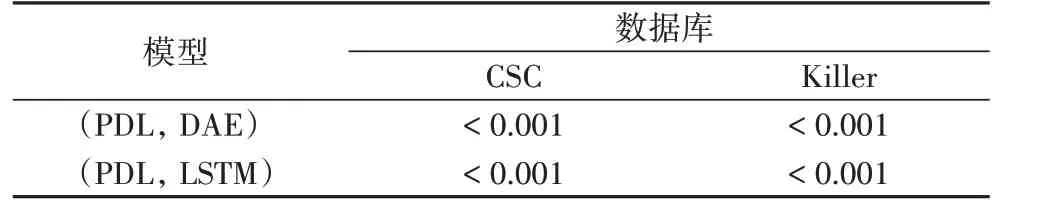
表5 测试结果的T检验Tab.5 T-test of test results
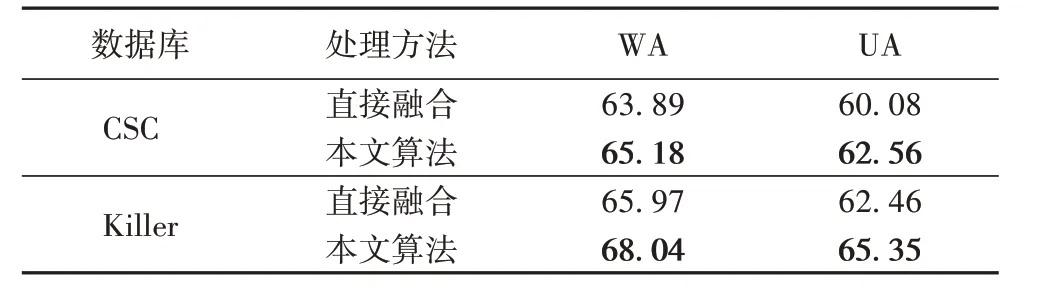
表6 是否利用DAE得到的不同识别精度 单位:%Tab.6 Different recognition accuracies whether to using DAE unit:%
可以看到,人工统计特征经DAE 处理后再与深度特征融合会达到更优的识别效果。与直接融合的方法相比:本文算法在CSC 库上的WA 提高了1.29 个百分点,UA 提高了2.48个百分点;在Killer库上的WA提高了2.07个百分点,UA提高了2.89 个百分点。说明利用DAE 对人工统计特征进行处理很有必要。
进一步地,本文还将所提算法与其他基于经典模型的语音测谎在识别效果上进行了比较。它们分别是:
1)多层神经网络(Deep Neural Network,DNN)。DNN 属于基础模型之一,许多文献将其设置为基本对比模型,在本文中,DNN的层数设置为3,隐层单元数为128。
2)SVM。SVM选择线性核函数,C值设置为10。
3)栈式自编码器(Stacked Autoencoder,SAE)网络[18]。根据文献[18],SAE的层数设置为2,隐层单元数为200。
4)深度信念网络-极限学习机(Deep Belief Network-Extreme Learning Machine,DBN-ELM)[19]。DBN 包含3 个隐层,每层单元数为100;ELM的隐层单元数为120。
以上对比模型使用的特征均为本文选择的2009 年情感识别挑战赛特征集。
5)卷 积 神 经 网 络(Convolutional Neural Network,CNN)[20]。文献[20]中的CNN 为经典的Lenet-5,包括3 个卷积层,卷积核都为5×5,步长为1,第一个卷积层的输出通道数为6,第二个为16,第三个为120,每个卷积层后都连接一个最大池化层,该模型使用本文提取的Mel 谱特征进行谎言检测。
从表7 中可以看出,本文算法的单条语音识别时间比其他方法相对来说要长一些,这主要是因为本文算法使用的融合特征具有更大的数据量,以及将Mel谱逐帧输入LSTM 时的计算量也更大,但增加的幅度也仅为几毫秒到几十毫秒之间,人体感官几乎难以察觉,与此同时,本文算法的识别准确率却提升明显。在CSC 库上:本文算法的WA 相较于其他算法最低提升了2.05个百分点,最高提升了5.56个百分点;UA相较于其他算法最低提升了2.53个百分点,最高提升了9.36个百分点。在Killer 库上:本文算法的WA 相较于其他算法最低提升了4.02个百分点,最高提升了7.22个百分点;UA相较于其他算法最低提升了3.79 个百分点,最高提升了9.67 个百分点,识别结果显著优于其他算法,进一步验证了本文所提算法的先进性。
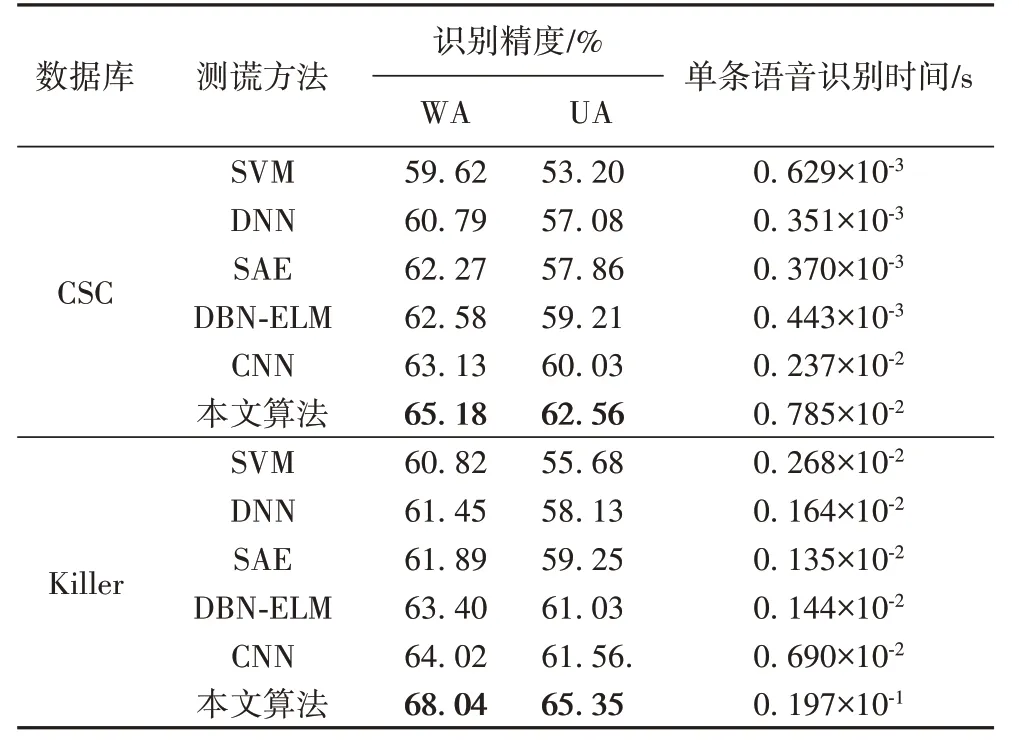
表7 不同测谎方法的识别精度与单条语音识别时间对比Tab.7 Comaprison of recognition accuracy and recognition time of single speech by different deception detection methods
3 结语
为了充分利用语音的不同特征所包含的信息,本文提出了一种基于去噪自编码器和LSTM 的特征融合语音测谎算法。该算法分别提取出了语音中的人工统计特征和Mel 谱图,在用去噪自编码器处理人工特征的同时,LSTM 也对Mel谱进行了帧级深度特征的学习,最后用softmax 分类器对融合特征进行了识别。融合特征综合利用了不同类特征中包含的不同信息,两个数据库上的实验结果显示,相较于以往的识别方法,本文所提算法可以达到更高的准确度。但是,利用融合特征进行语音测谎仍然有广阔的研究前景,如何选择其他特征进行融合以及使用其他先进的模型对特征进行处理,将是下一阶段的研究工作。
猜你喜欢
军事文摘(2022年8期)2022-11-03
哈哈画报(2021年11期)2021-02-28
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年9期)2019-05-30
故事作文·高年级(2019年2期)2019-02-24
电子制作(2019年24期)2019-02-23
小说界(2018年5期)2018-11-26
家教世界·创新阅读(2016年9期)2016-05-14
智慧与创想(2013年7期)2013-11-18
小猕猴智力画刊(2013年2期)2013-03-15
