
一种基于生成式对抗网络的图像数据扩充方法
2020-04-09 06:36王海文邱晓晖
计算机技术与发展 2020年3期
王海文,邱晓晖
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
近些年来,深度学习受到了各领域学者的广泛研究,其中卷积神经网络(CNN)是用于图像分类研究的最基本模型。目前常见的卷积网络有AlexNet、VGGNet、GoogleNet、ResNet等。最早提出卷积神经网络并将其运用于数字识别的是Yann LeCun[1]的LeNet-5模型,它包含了一个深度学习的必要模块和卷积层、池化层、全连接层的基本组合方式,采用基于梯度的反向传播算法BP[2]在图像数量为60 000张,分类标签数为10的手写体Mnist数据集上对网络进行有监督训练。直到AlexNet[3]的出现,提高了神经网络的训练速度和网络的分类能力,AlexNet采用训练集大小为1 400万张、涵盖2.2万个类别的ImageNet数据集进行训练。其主要优势在于,使用了一种非线性激活函数Relu[4]以及重叠的最大池化,提出局部响应归一化LRN(local response normalization),提取了图像丰富的深层特征,增强了模型的泛化能力,并使用GPU并行计算,极大地缩短了对图像计算的时间。此外,AlexNet还使用了数据增强和Dropout[5]组合防止过拟合,随机地从256*256像素的原始图像中截取224*224大小的区域,增加了2 048倍的数据量。该模型说明了数据集的扩充有效提升了网络训练的质量,由此也激发了研究人员对数据增强方法的研究和应用。后来一些深层卷积神经网络如VGG16、ResNet[6],即使使用了质量较高,且数量庞大的数据作为训练集,也都会对图像数据进行常见的预处理,如crop或小批量的数据增强。由此可见,数据集的大小和质量极大地影响了CNN网络的训练过程和最终的质量。
目前比较好的神经网络都具有一定的深度。然而随着神经网络的加深,需要学习的参数也会随之增加,这样就容易导致过度拟合。过度拟合是指神经网络可以高度拟合训练数据的分布情况,但对于测试数据准确率很低,缺乏泛化能力。造成训练网络过度拟合的原因有很多,数据集数量少和质量差是最直接的原因。早在2012年Alex赢得ImageNet竞赛后便提出PCA Jittering,对网络的输入数据进行规范化,并在整个训练集上计算了协方差矩阵,进行特征分解,用于PAC Jittering,从而有效地对输入数据进行预处理,规范数据质量。后来的Inception网络[7],VGG和ResNet也均使用Scale Jittering,即尺度和长宽比的增强变换方法来扩充数据,对图像进行预处理,实现数据增强。这些最先进的研究均表明了数据增强对一般深层网络最后的识别性能和泛化能力有着至关重要的作用。所以,为了避免出现过拟合(over-fitting)且数据量较小时,数据增强十分必要。
1 数据增强算法
一般来说,数据增强分为两类:离线增强,即在网络未获取数据之前,直接对数据集进行扩充处理,数据的数目会根据增强因子直接成倍增长,这种方法常用于数据集很小的时候。在线增强,这种方法主要用于,在获取一组Batch数据后,对该组数据中的每个对象实现数据增强,如:旋转、平移、翻折等变换。近些年研究人员发现,卷积神经网络对于放置在不同方向的对象也能进行稳健的分类,即具有旋转不变性。更具体地说,CNN对于平移、视角、尺度变化甚至光照的组合都可以是不变的。这一特性使得可以利用基本变换对数据集进行有效扩充。例如,空间变换类:翻转、裁剪(ROI)、旋转、缩放变形;频域变换类:旋转畸变变换[8]、极坐标变换[9]、RGB变换。
此外,还有一些特殊的数据增强方法。SMOTE(synthetic minority over-sampling technique)针对数据集中样布分类不平衡现象导致的特征提取不足,基于插值法为小样本类合成新的样本,其主要思路为:
(1)定义好特征空间,将每个样本对应到特征空间中的某一点,根据样本不平衡比例确定采样倍率N。
(2)对每一个小样本类样本(x,y),按欧氏距离找k个最近邻样本,从中随机选取一个样本点,假设选择的邻近点为(xn,yn)。在特征空间中样本点与最近邻样本点的连线段上随机选取一点作为新样本点,满足式(1):
(xnew,ynew)=(x,y)+rand(0,1)×((xn-x),(yn-y))
(1)
(3)重复选取取样,直到大、小样本数量平衡。
2018年1月,Google科学家Ekin Dogus Cubuk和Barret Zoph开发了一款自动寻找数据本身最佳增强策略的优化工具AutoAugment。AutoAugment能为计算机视觉数据集自动设计图像增强策略,它不仅包含了水平/垂直、旋转、改变颜色等常规方法增加图像数据量,还能预测每种增强方法使用的最优占比,从而寻找最优的图像增强策略。AutoAugment在数据集ImageNet的实验结果也表明,对于颜色和色调敏感度不同的数据集,如果仅仅运用裁剪或改变颜色去增强数据,用最后生成的图像训练模型可能会降低模型性能。寻找一种或组合使用多种数据增强算法,可以进一步提升网络模型做图像分类时的准确率。
生成式对抗网络(GAN)[10]自2014年被Goodfellow提出后,被誉为近十年来最富想象力的深度学习网络模型,并且被不断改进,形成了CGAN、DCGAN、WGAN、BEGAN、infoGAN[11]等用于图像、自然语言处理甚至语音处理等领域的新模型。由于传统方法在数据增强方面的效率较低,且生成的图像数据带有很多的冗余信息,给网络训练带来更多不确定性。为了得到更丰富的图像数据,降低网络训练难度,一定程度上缓解因数据集太小造成网络模型泛化能力不强的问题,文中受生成式对抗网络启发,将带深度卷积的GAN网络用于生成图片,从本质上分离传统图像增强时带来的生成样本相关性,实现数据增强。目前生成式对抗网络主要使用了一些常见的激活函数如Tanh、Relu[12]和Batch Normalization等方法简化网络模型参数,使训练变得快速高效,但这些方法实际使用中还是会由于参数调整不当而造成求解损失函数最小值时不收敛或震荡,生成图像质量较差等问题,为此引入一种新的激活函数Selu使训练更加稳定,改善训练生成式对抗网络不够稳定的缺点。
2 基于Selu的改进DCGAN网络
2.1 DCGAN网络原理及特点
DCGAN(deep convolutional GAN)是一种带深度卷积的GAN模型。GAN模型如图1所示,主要包括了一个生成模型G(generator)和一个判别模型D(discriminator)。G负责生成图像,它接受一个随机的噪声z,通过该噪声生成图像,将生成的图像记为G(z);D负责判别一张图像是否为真实的,它的输入是x,代表一张图像,输出D(x)表示x为真实图像的概率,实际上D是对数据的来源进行一个判别:究竟这个数据是来自真实的数据分布pdata,还是来自于一个生成模型G所产生的一个数据分布p(z)。所以在整个训练过程中,生成网络G的目标是生成可以以假乱真的图像G(z)让D无法区分,即D(G(z))=0.5,此时便得到了一个生成式模型G用来生成图像扩充数据集。模型训练的过程构成了G和D的一个动态博弈,可以构造式(2)所示的交叉熵损失函数:
V(D,G)=Ex~pdata(X)[lnD(x)]+Ez~pz(Z)[ln(1-
D(G(z)))]
(2)
其中,x为用于训练的真实图像数据,pdata(X)为图片数据的分布,z为输入G网络的噪声且已知噪声z的分布为pz(Z),而G(z)为网络生成的图片。在理想状态下,经过训练,G尽可能学习到真实的数据分布pdata(X),G将已知分布的z变量映射到了未知分布的x变量上。判别模型D的训练目的就是要尽量最大化自己的判别准确率。当这个数据被判别为来自于真实数据时,标注1,来自于生成数据时,标注0。而与这个目的和过程相反的是,生成模型G的训练目标是要最小化判别模型D的判别准确率。在训练过程中,GAN采用了一种交替优化方式,它分为两个阶段,第一个阶段是固定判别模型D,然后优化生成模型G,使得判别模型的准确率尽量降低。而另一个阶段是固定生成模型G,来提高判别模型的准确率。

图1 DCGAN网络判别结构示意图
DCGAN的特点是在G和D网络中使用了深度卷积网络。D网络与一般卷积神经网络类似,使用了带步长的二维卷积,提取深层特征的同时不断减小特征图的大小,实现下采样。而G网络则使用了一种转置卷积,从一维向量逐渐扩充成二维图像,实现上采样过程。其中卷积滤波器长宽L=3,卷积步长P=2的正向卷积完成特征图大小5×5到3×3下采样(见图2)和转置卷积完成特征图大小3×3到5×5上采样(见图3)。
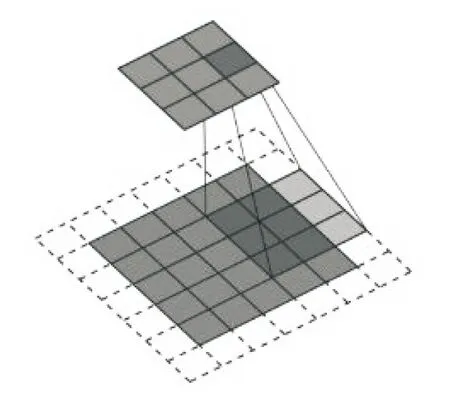
图2 正向卷积示意图
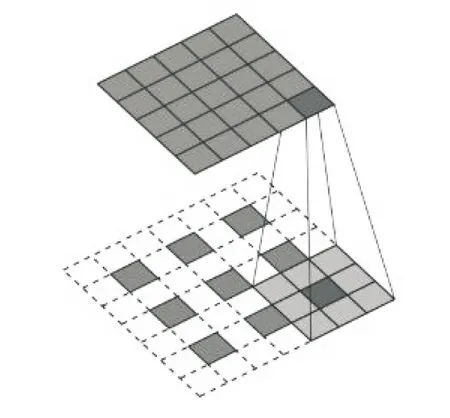
图3 转置卷积示意图
生成网络是否能生成判别网络无法区分真假图片的关键不仅依赖合理的卷积层,还需要选取合适的激活函数,如不用激活函数,下面每一层输出都是上一层输入的线性函数,如早期的感知机模型,即使使用生成式对抗网络也无法学习和生成有意义的图像。只有引入非线性函数作为激活函数,深层网络层才具有意义,生成需要的图像,并完成非线性映射和加速网络收敛的速度。相较于Tanh和Sigmoid函数,在GAN网络中运用Relu在使用随机梯度下降法(SGD)中能更快地收敛,且为神经网络提供了稀疏表达能力。研究中人们还会使用LeakyRelu、Relu等Dropout组合构建网络的激活层[5],这些激活函数不仅能将卷积层提取的图像特征非线性地映射到高维空间,还能在一定程度上简化计算网络参数的难度,加速网络的训练过程,如在利用反向传播(BP)训练参数时,Relu函数在求导后仅剩常数。Relu的公式如下:

(3)
2.2 结构简化的改进DCGAN网络
由于在DCGAN网络中,Relu层和归一化层(batch normal)分别完成了卷积层的非线性激活和去复杂归一化[13],文中算法使用了一种自归一化Selu(缩放指数线性单元)激活函数(如式(4)),目的是为了替代激活层和归一化层,简化网络结构,解决对抗网络训练不稳定的问题,提升生成图像质量。
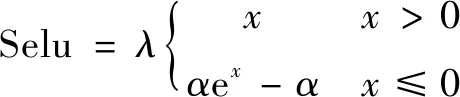
(4)
其中,λ≈1.05,α≈1.67。
Relu在之前表现较好的特性是因为它在输入是负值时,神经元就不会被激活,从而使得网络很稀疏,提升了计算效率,但在反向传播中,会出现一个趋于0的梯度空间,即输入值变换到负值后梯度会再也不更新,这些神经元将永远不会被激活且很可能会对整个生成网络甚至判别网络产生弊端。理论上,希望经过激活函数后使得样本分布归一化到均值为0,方差为1,这样在利用梯度下降法的训练过程中,不会产生梯度越来越大或者消失的情况[14]。而Selu函数正符合这样的特点:在负半轴坡度平缓,在激活后方差过大的时候可以让它减小,防止了梯度爆炸,正半轴设置了大于1的常数,在方差过小的时候可以让它增大,同时也防止了梯度消失。这样激活函数就有了一个不动点,在网络加深后每一层的输出都是均值为0且方差为1。所以,引入Selu激活函数加入DCGAN网络,从理论上简化了网络结构。DCGAN网络在训练时易发生因生成网络或判别网络结构过于复杂或学习率选取不当造成的不稳定现象,从而导致无法生成有意义的图片,仿真实验验证了文中方法网络训练的有效性和稳定性,同时也能生成更高质量的图片。
2.3 a_Dropout技术
通常可以采用更深的网络和更多的神经元来提高网络的分类表达能力,但是复杂的网络如果没有足够多的数据去训练,就会造成过度拟合现象。过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数较大,预测准确率较低。在2012年的AlexNet中就使用了一种Dropout方法,在前向传播的时候,让某个神经元的激活值以一定的概率q停止工作,即在训练阶段随机组成了无数的神经元网络,简化了每次训练网络时的参数,提升了训练网络所耗费的时间。另一方面,Dropout降低了神经元间的相互依赖,大大提升了网络泛化能力,起到一种正则化效果。
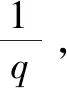
对于Selu激活函数,引用了一种带参数归一化的a_Dropout方法。使用该方法后的均值和方差满足式(5),其中β的值为Selu中的-λα。
E(xd+β(1-d))=qμ+(1-q)β
Var(xd+β(1-d))=q((1-q)(β-μ)2+υ)
(5)
在计算中还会利用a,b两个参数进行仿射变换保证均值和方差不变,如式(6),并且可以通过μ,v计算出最佳的a,b值。
E(α(xd+β(1-d))+b)=μ
Var(α(xd+β(1-d))+b)=υ
(6)
3 实验仿真
实验采用Intel Cpu8750H、Nvidia GTX1070、Win10操作系统,基于tensorflow1.8-GPU的网络构建及训练,数据集采用Mnist。
3.1 Selu激活函数的自归一化特性仿真
在一个层数为2的卷积网络上分别使用Selu(左)和Relu(右)激活后激活函数输出值分布激励图如图4所示。
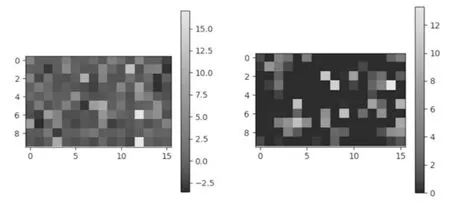
图4 Selu(左)与Relu(右)激活值分布激励图
由于Selu的自归一化特性,保证了网络训练的参数分布均值为0,方差为1。不同于Relu激活后无负数,且分布整齐,为DCGAN网络生成复杂的样本提供了可能。
3.2 DCGAN网络的图像数据集扩充仿真
文中分别按下面常用的5种判别网络结构和1种生成网络结构构建。判别网络与一般神经网络类似,采用卷积层-激活层的组合方式,不同的是由于训练参数较多,需要加入归一化层对神经元统一。在实验中保持了一种稳定的生成网络结构,即使用转置卷积和Relu直接连接的网络层。判别网络则是设计了五种结构仿真,其中D1采用了一种传统DCGAN结构方式,即在做激活前对所有参数归一化,加快训练速度,D2和D3则是比较了bn层位置变换对整体训练效果的影响,D4则是将Selu加入验证文中方法的有效性,最后D5选取了一种与Selu更适合的Dropout方法简化网络参数,加快训练过程。D1-D5、G0分别为判别网络和生成网络单层结构设计(conv1表示第一层卷积层,bn表示归一化层,conv2表示第二层卷积层):
D1:conv1->bn->Relu->conv2
D2:conv1->Relu->bn->conv2
D3:conv1->bn->Relu->bn->conv2
D4:conv1->bn->Selu->conv2
D5:conv1->Selu->A_Dropout->conv2
G0:deconv1->Relu->tanh
当G & D learning rate=0.000 2,batch_size=64时,生成的图片如图5所示。

图5 D1-D5各结构所生成数据图像比较
生成器D1-D5训练所需时间如表1所示。

表1 网络训练时间对比 s
从表1可以看出,在判别器和生成器学习率分别为0.000 2时,使用了Relu激活与Selu激活的时间相当,激活层和归一化层对训练时间无明显加长。
实验结果表明,利用DCGAN可以有效地生成图像数据,用于扩充数据集。在评价图像质量时主要采用人眼主观评价,通过手写体Mnist图像生成效果,可以明显发现,使用了一种自归一化激活函数的深度卷积对抗网络,生成的图片更清晰,且效果整体更稳定。如图5展示了整体比较效果,改进后的DCGAN网络生成完整轮廓或清晰纹理图像样本的数量更多,出现概率更大。其中D1、D2为DCGAN经典模型生成的手写体图像,类似结构D4只改变激活函数特性图像效果有所提升,但训练时间相对更长(见表1)。图6则展示了从判别网络中使用Relu和Selu生成图像中随机抽取的样本,通过‘2’、‘3’上下分析比较,下行样本质量明显更高更稳定,前者方法生成的图像存在更多模糊样本。最后选取D5结构得到的仿真结果表明,使用了a_Dropout算法的Selu函数网络模型,不仅没有降低图像质量,保持了一定的稳定性,而且由表1可知,相较于直接替换激活函数,其训练时间还有所减少。

图6 分别随机抽取使用Relu(上)和Selu(下)生成的样本图像
4 结束语
针对深度卷积网络做图像分类时数据集过小造成训练网络时带来的样本特征不足及网络过度拟合问题,利用DCGAN网络生成人造图像,引入Selu作为判别网络各卷积层后的激活函数,结合带参数归一化的Dropout方法成功实现对图像数据集的扩充,并就训练时间和生成图像样本质量,与使用Relu激活函数的DCGAN网络生成效果进行比较。实验结果表明,DCGAN网络可以极大地丰富数据集大小;在将激活函数Relu改为Selu并结合带参数归一化的Dropout方法后,在选取适当的生成网络和判别网络学习率和保持网络训练速度基本不变的情况下,改善了生成图像质量,从而更好地为训练分类网络提供了有利条件,实现了离线数据增强。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
软件(2017年6期)2017-09-23
