
改进贝叶斯的语义推送算法设计
2020-04-09 07:56:06冯锡炜窦予梓高天铸吴衍兵
计算机技术与发展 2020年3期
朱 睿,冯锡炜,窦予梓,高天铸,马 蕾,吴衍兵
(辽宁石油化工大学 计算机与通信工程学院,辽宁 抚顺 113001)
0 引 言
教育信息化越来越受到教育研究者的关注,随着各类学科的电子化,人们访问这类网站所产生的浏览数据量越来越大。通过大数据技术,对这些浏览数据进行分析后,可以根据每个用户群体不同的浏览数据习惯进行相关教育方面的信息推送[1-3]。
专业化教育资源本体库的建立对于教学信息资源的推送有着不寻常的实践价值[4-5]。在2017年教育部发布了《基础教育教学资源元数据》系列教育行业标准通知,里面包括了《基础教育教学资源元数据 信息模型》、《基础教育教学资源元数据XML绑定》及《基础教育教学资源元数据 实践指南》,这些标准对于建立相关教育信息化本体有着非常重要的意义。
文中利用Protégé,以计算机组成原理这一课程内容为本体设计数据来源,进行本体设计。基于百度指数中关于计算机组成原理的各项搜索数据,基于贝叶斯建立词汇频度分析模型,将百度指数中的搜索指数结合词汇频度分析模型进行计算,计算后的各个不同本体的词汇频度分析数据按照数值的从大到小进行推送。
1 教育信息化本体构建
1.1 教育信息化
教育信息化具有两层含义,一个在教育目标中加入信息素养,另一层指在教学与科研中加入信息技术手段,注重教育信息资源的探究与使用[6]。文中主要对后者进行阐述。在信息技术手段上利用大数据、语义分析及用户粘性等信息技术对教育工作者常进行浏览的网页记录进行分析,进而进行推送[7-8]。
1.2 教育资源本体
教育资源本体用来容纳和规范教育信息,根据实际的需求,将本体的属性分为数据属性(Data Property)和对象属性(Object Property)。数据属性定义域是本体的类,值域是数据类型。对象属性是表示所有个体之间的关系属性[9]。
数据属性:为使网络上分布的教育资源库有统一的语义标注标准,通过对《基础教育教学资源元数据》的每一个元数据项进行分析,然后整理出了数据属性。部分数据属性的定义与说明如表1所示[10-11]。
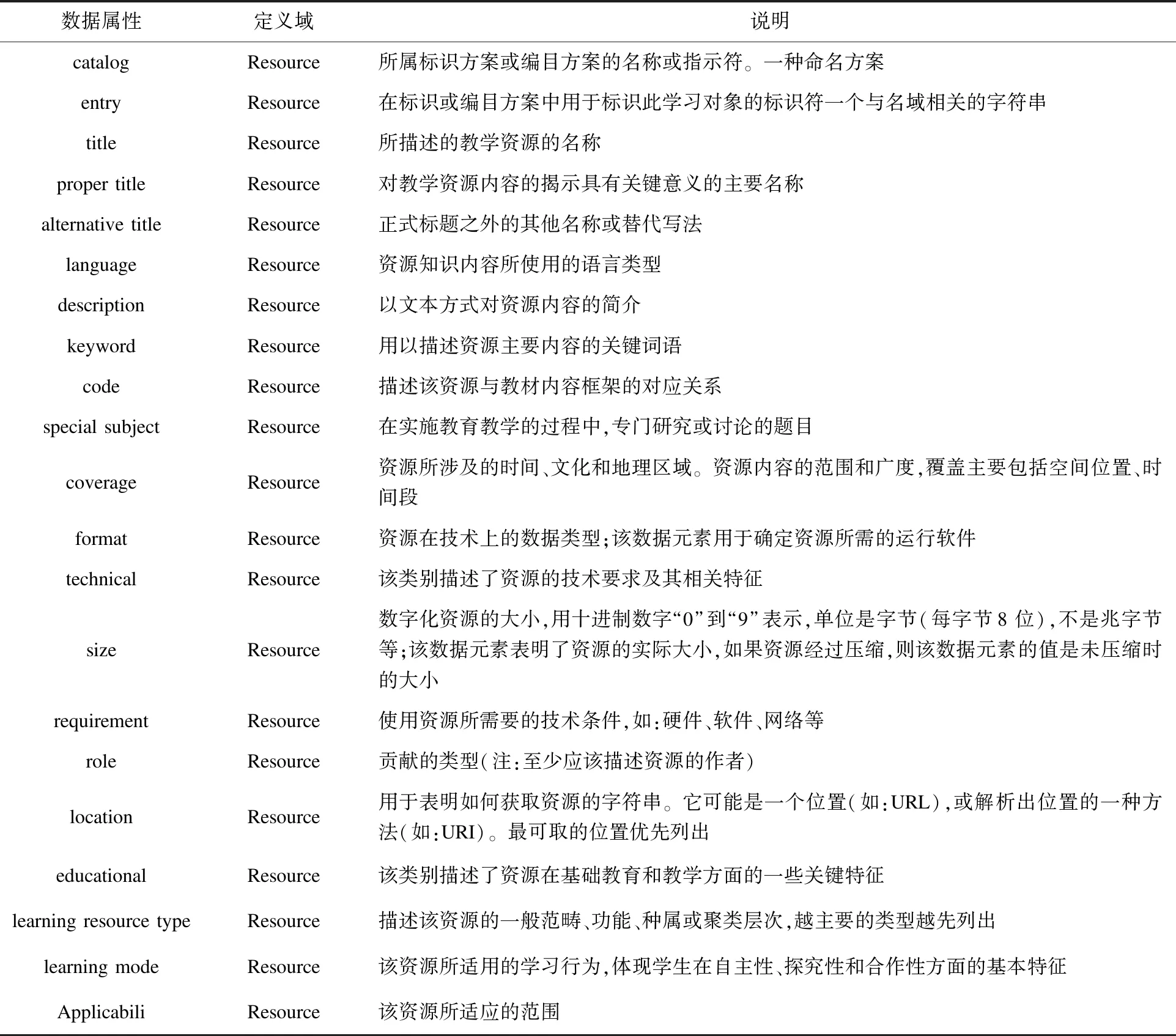
表1 数据属性定义及说明
对象属性:根据教育元数据进行教育资源领域的本体构建。主要对象属性是教育信息的对象属性[12]。教育资源之间存在丰富的语义关系,通过语义关系建立本体属性,利用这些属性进行本体推理和查询,作为教育资源语义搜索的基础[6]。
教育资源间属性关系,可根据教育信息的特点,对教育信息间关系进行分析抽象,得到表2所示的对象属性及对应公理。
其中对象属性的公理,为从离散数学当中借鉴过来的三种关系性质,分别是Transitive(传递性)、Asymmetric(非对称性)和Reflexive(自反性),具体对象属性及对应公理如表2所示[13]。
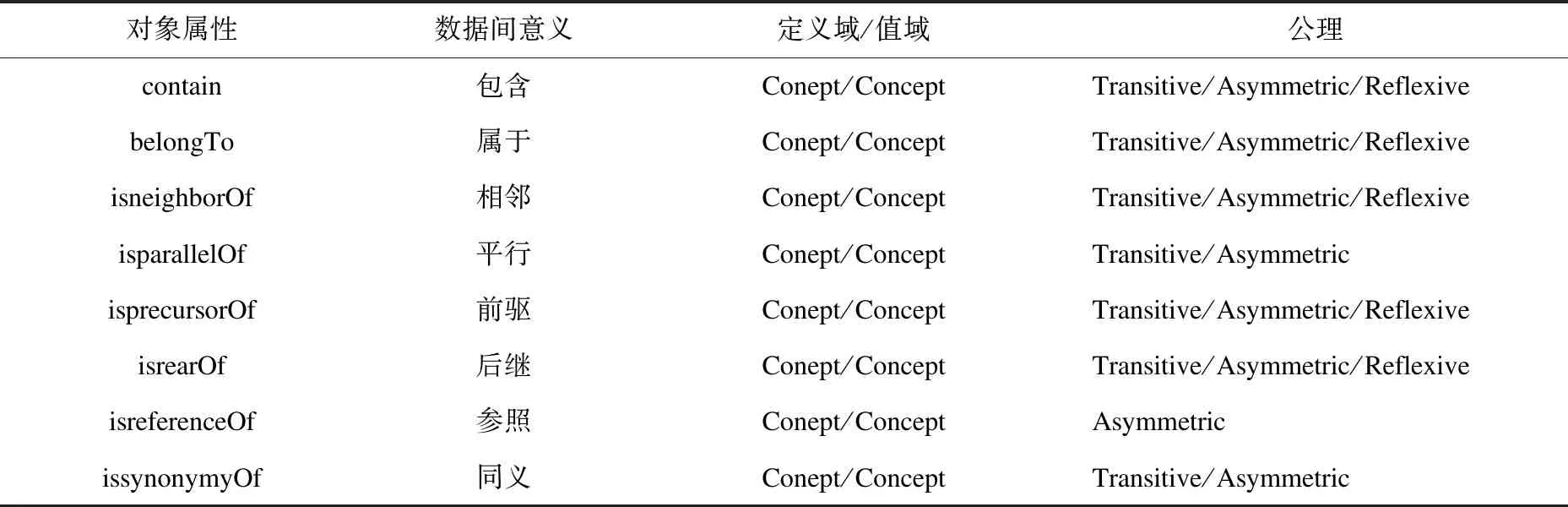
表2 对象属性及对应公理
1.3 教育资源本体
利用Protégé进行计算机组成原理这一课程体系及相关知识的本体构建。层级关系采用目前本科计算机类学生教学常用的《计算机组成原理》中对计算机组成的分类方式作为分类标准,主题上分四个大块,分别是概论、计算机系统的硬件结构、中央处理器、控制单元。采用树状方式进行存储,深度为4层。图1和图2分别是在Protégé进行本体构建的结构图和可视化界面图。Protégé会生成对应的owl及xml文件,可以方便在Hadoop中进行相关处理工作。
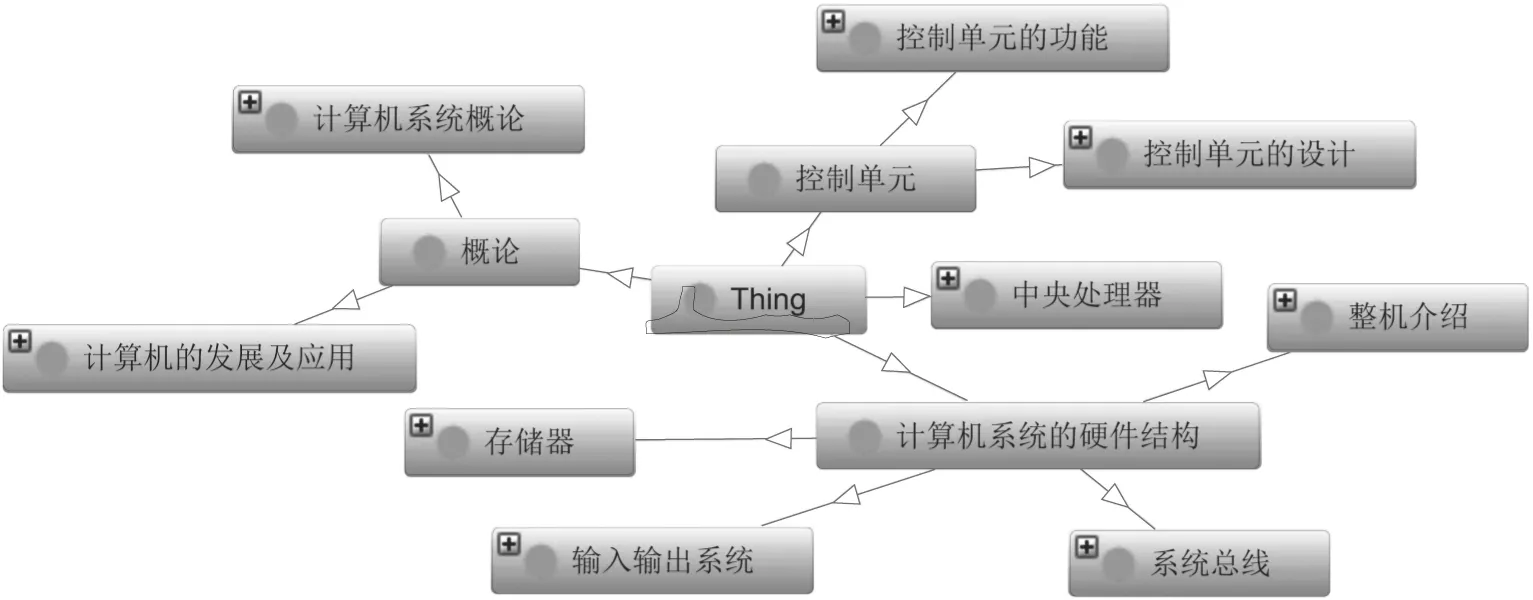
图1 Protégé本体之间结构关系简图

图2 Protégé本体之间可视化界面部分展开
2 教育信息化本体构建
教育信息之间的语义关系可以制定丰富的自定义推理规则[14-15]。这里假设a、b为教育信息,p、q表示属性,p具有传递性,p和q互逆:
传递性规则:(? a p ? b)(? b p ? c)->(? a p ? c)
如果教育信息a和b之间具有属性p,教育信息b和c之间也具有属性p,属性p具有传递性,则可以推理得到教育信息a与c之间也具有属性p。
互逆规则:(? a p ? b)->(? b q ? a)
如果教育信息a与b之间具有属性p,由于属性p和q互逆,则可以推理得到教育信息b和教育信息a之间具有属性q。
这里以计算机组成原理中的知识点为例,利用表2对象属性及对应公理中对象属性结合传递性或互逆规则,用JSJZC表示计算机组成原理的知识点作,在表3中写出为推理规则。

表3 教育信息本体间逻辑

续表3
属性约束,OWL使用属性约束来描述那些特定类的属性条件,属性条件的基数约束如表4所示[11]。

表4 属性条件约束规则
3 词汇频度分析模型
本体构建只是将零散的教育信息进行半结构化的数据构建过程,而词汇频度分析模型是将这类数据进行处理的模型。Hadoop作为一个分布式计算基本框架,在对大数据进行分布式计算的过程中,需要对数据进行整理和规划,而作为Apache公司推出的MapReduce可以在大数据以及半非结构化的概况下进行数据处理[16-17]。教育信息数据具有半非结构化,需要通过本体构建的方式构建起一个相对的结构体系,所以通过对MapReduce和Hadoop进行配合,进行相关的数据计算,能更好地对数据进行处理。
而词汇频度分析模型MapReduce对教育信息资源进行管理,词汇频度分析模型的处理和表示是分类器构建的一个重要过程[18]。词汇频度分析研究的是对教育信息资源进行推送的相关算法,在前面已经基于本体进行个元数据的分类及结构构建工作,但只有结构无法进行相应的推送工作,因为对于元数据来说,每个元数据在推送过程中都具有相同的推送价值[19-20]。为了更好的进行相关信息资源的推送,文中在基于语义构建元数据的基础上加入了基于改良后的贝叶斯概率统计计算公式。贝叶斯概率统计计算公式相较于传统的频数概率统计方式有所不同,其概率统计会保留不确定性[7]。
(1)
这与推送内容的目标用户对于推送内容的不确定性恰好吻合,而传统的贝叶斯公式如式(1)所示,其中P(A)代表A发生的概率,其概率值在[0,1],X代表在A之后进行测试的实验[7]。这个公式代表的含义是在已知P(A)(在推送中最开始的P(A)可来自该行业专家的初始定值或小范围内的问卷调查赋值初始概率)的情况下,每次新的变化会让概率在[0,1]之间不停的变化。当中需要对每个教育本体进行附加属性,通过这些附加属性进行词汇频度分析模型的构造。文中采用词汇频度分析模型来对各个标题进行赋值,从而在进行推送的过程中可以更加准确地进行相关信息的推送工作[21]。
W={w1,w2,…,wn}
(2)
wi={name,depth},i∈[1,n]
(3)
式(2)中的W代表本体库,式(3)中的wi为本体库中的本体,每个本体wi含本体名称和在本体库中的本体层数,规定根节点(在文中是计算机组成)层数为1,其中下角标i代表每个本体的标号,n代表本体库中最大本体数目。
htj={h11,h12,…,h1m,h21,…,h2m,…,hf1,…,hfm}
(4)
式(4)中htj是各个本体词汇在不同日期下的热度值,其中t代表日期,最大日期值为f,j代表所对应本体的标号。wi通过记录的字段name与htj在代表本体进行互相映射。
(5)
式(5)为预先处理数据,根据已构建的本体库,其存在层级关系,层级越低,其概括越大。而层级越高,其内容越细。计算在本体库中与wi具有较强连接度的本体数据的比例关系,进而得出与整体的关系。P(wi)代表的是每个本体与整体的连接概括关系,而dep(wi,wj)表示两个本体间的层级的距离,如果两个本体间越相近,其dep()值越小,P(wi)越大,其本体wi与其他本体的链接越紧密,在推送的时候更应该连带进行推送。此部分对应传统贝叶斯公式中的P(A)部分。
(6)
式(6)为计算在对应本体的热度值,该热度值的来源为各大搜索引擎的热词搜索数据(文中采用的是百度指数中的相关数据)。这里设每日该本体对应的热词比例公式为P(htj),htj和hTj分别为获取当前词汇的热度数和不同天数下的该本体的热度数。P(htj)值越高,代表htj在用户搜索中占有较重要的意义,htj所对应的本体wi的推送排名应该上升。P(htj)值越低,代表htj在推荐中应该进行排名下滑。
(7)
通过组合式(5)及式(6),可以得到简单的基于贝叶斯模型,如式(7)所示。但贝叶斯在进行统计概率的情况下,其容易受到单次数据较大波动导致统计概率发生较大的起伏,所以,文中在结合本体与贝叶斯统计概率公式的同时加入频数统计概率。
(8)
式(8)为当有相应的用户搜索数据后,计算用户搜索频度值。式(8)中的α值为加权自定义值,默认情况下为0。而β为本体加权变量,默认情况下为1。如果需要特殊优先推送,增加该本体的β值或者调节α值,增加β值可以对本体进行正向加权,让P(wi,htj)增加,而调节α即避免当前该信息过新无人查看P(htj)=0这种情况。
(9)
式(9)得到每个本体Wi所对应的粘性能量值Ei,推送系统根据Ei值进行相关内容的推送。Ei值越大,其推送排名越靠前;Ei值越小,其推送排名越靠后。
4 语义推送结果分析
基于逆概率的贝叶斯算法设计出的词汇频度分析模型和通过语义本体构建规则构建起来的半结构化教育信息本体结构,进行用户粘性模型教育信息推荐系统[22-23]的设计工作。通过在百度指数上的相关数据结合专业书籍及相关专业老师的意见,计算P(wi)及相关公式的结果Ei,得到计算机组成原理排名前10的词汇。教育信息推荐系统推送结果如表5所示。

表5 教育信息推荐系统推送结果
图3是用MATLAB生成的教育信息推荐系统推送结果展示图,以搜索计算机组成一词例推送出的相关信息,点的大小代表访问量,距离的远近代表相关性层级的远近。图4是MATLAB生成的按书目录一级标题推送结果。从图3和图4对比中可以大致看出,基于按一级目录进行推送的结果在大多情况下不如教育信息推荐系统的推送结果,教育信息推荐系统的推送结果具有信息量大,相关信息多的特点。
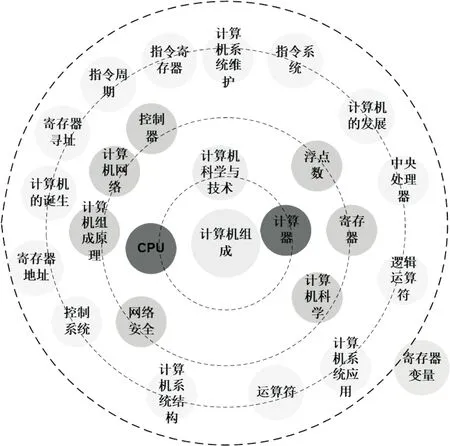
图3 教育信息推荐系统推送结果展示图
图4 按书目录一级标题推送结果图
对于表5当中的教育信息推荐系统的推送结果,选取了100名相关计算机专业的学生,通过给他们推送基于词汇频度分析模型及按书目录一级标题排列进行推荐可靠度打分,让其判断需要程度的排序,得出如图5所示的百名用户满意度记录。从图中可以大致看出,基于按一级目录进行推送的结果在百名用户中大多情况下不如教育信息推荐系统的推送结果。
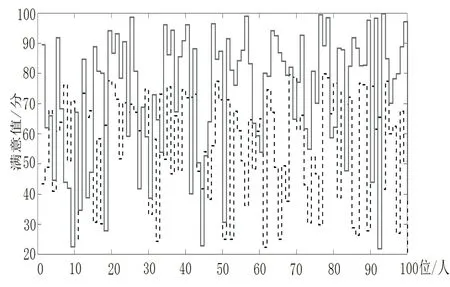
图5 百名用户满意值记录
数值判断方面,利用Jaccard Index(简称JS指数)进行用户对推送结果排序的符合程度计算。式(10)为JS指数计算方式,其中A为推送结果,B为用户希望推送结果。J(A,B)为JS指数计算结果,当JS指数大于0.70时为优秀,大于0.50时为良好,低于0.25时,该系统不利于进行推送。
(10)
将表5当中的信息推荐系统表和按一级目录排列的结果同时让100名自愿用户(计算机专业学生)评判是否符合心理推送预期。并且利用式(10)进行计算。
根据图5中百名用户满意值记录,进行平均值计算,结果比较如表6所示。从表中可以看出,利用词汇频度分析模型结合语义本体分析后的推送系统JS平均指数达到了0.73,达到了良好的标准,而根据一级目录进行推荐的推荐系统JS平均指数达到了0.57,明显比基于用户粘性模型及语义本体分析后的JS平均指数低。

表6 各类推荐算法比较表
对于表5当中的教育信息推荐系统的推送结果,从多名自愿用户(计算机专业学生)的学生中选出100个计算机专业常见词汇,通过测试推送基于词汇频度分析模型及按书目录一级标题排列进行打分,能推送出准确的结果为1,未能推送出结果的为0,未能推送出准确结果但能推送出其泛词(相同或相关的词汇)的结果为0.5。图6是100词汇测试结果记录图,其中实线代表教育信息推荐系统推送,虚线代表按照一级目录推送。
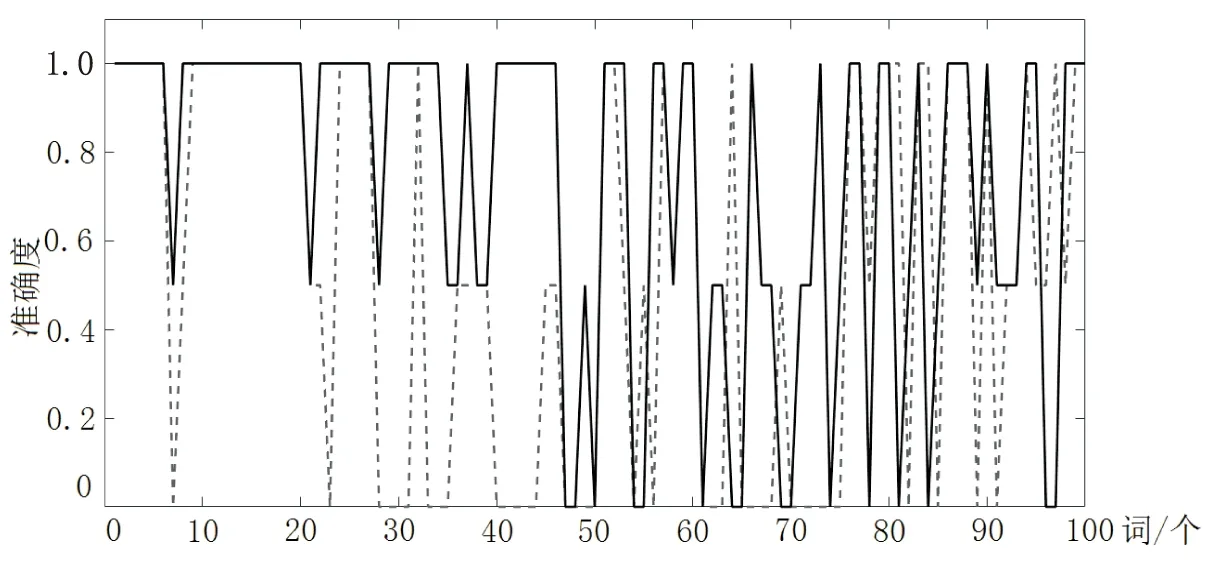
图6 100词汇测试结果
根据图6,将图中数据进行推荐度计算(推荐结果累加总分/词汇总数),结果比较如表7所示。从表中可以看出,利用词汇频度分析模型结合语义本体分析后的推荐度分数达到了0.73,达到了良好的标准,而根据一级目录进行推荐的推荐系统推荐度数仅仅达到了0.535,显而易见,教育信息推荐系统的推送结果的准确性要远远高于按一级目录推送结果的准确性。

表7 推荐算法比较
5 结束语
文中利用语义本体对教育信息进行本体构建,利用贝叶斯及频度统计概率的方式对构建的教育信息本体进行概率上的计算,得到每个本体的推送概率Ei,根据Ei值的大小进行教育本体信息的推送工作。对推送的结果进行满意度判断,并且进行统计后,利用JS指数对该推送结果进行分析。
为了使推送的内容更加准确,从算法的实用性和健壮性出发,在教育信息研究领域当中应用改进贝叶斯算法设计的词汇频度分析模型,其推送结果的准确性和适应性优于基于目录结构推送算法,能够更加精确地对所服务的人群进行相应数据的推送工作。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18 07:31:14
数理化解题研究(2017年4期)2017-05-04 04:07:54
妇女之友(2017年3期)2017-04-20 09:20:00
中国医学装备(2016年6期)2016-12-01 06:44:41
铁道通信信号(2016年6期)2016-06-01 12:10:20
电子器件(2015年5期)2015-12-29 08:43:15
燕山大学学报(2015年4期)2015-12-25 02:19:58
中国药物应用与监测(2015年5期)2015-12-11 03:15:55
郑州大学学报(理学版)(2014年2期)2014-03-01 04:20:49
土木建筑工程信息技术(2013年3期)2013-10-17 03:15:08
