
移动群智感知中面向用户区域的分布式多任务分配方法
2020-04-09 14:48韩俊樱张振宇孔德仕
计算机应用 2020年2期
韩俊樱,张振宇,孔德仕
(1.新疆大学信息科学与工程学院,乌鲁木齐830046;2.新疆大学新疆多语种信息技术实验室,乌鲁木齐830046;3.四川大学计算机学院,成都610065)
0 引言
移动群智感知(Mobile Crowd Sensing,MCS)是一种基于众包思想的新型感知模式[1-3],它利用普通用户随身携带的智能移动设备(智能手机、可穿戴设备等)形成兼具实时性及灵活性的大规模感知系统,进而完成传统静态感知设备无法解决的大规模感知任务[4-6],如:实时交通信息监测[7]、空气质量检测[8]、突发事件感知[9]等。
任务分配是移动群智感知中的关键问题之一,它的合理性对感知数据质量、用户参与水平、感知成本等都具有十分重要的影响[10-14]。任务分配属于组合优化问题,具有NP 难解性。Wang 等[15]引入任务的最小感知质量阈值来重新定义多任务分配问题,为每个工作者分配一组适当的任务使得感知系统效用最大化;Hu等[16]利用动态获取的时空知识提出了在线启发式算法,以提升空间众包任务分配的效率;Liu 等[17]分别针对少参与者多任务以及多参与者少任务两种场景设计了参与者选择框架TaskMe;Azzam 等[18]提出了基于群组的招募系统,利用遗传算法综合用户特征从而选择合适的用户群组执行感知任务。
已有方法存在以下局限:
1)面向用户实时位置的单一任务分配不利于隐私保护,且难以处理较大规模的实时多任务,因此需要将感知任务进行合理组合,构建弹性的任务分配模式,让用户去完成一个或多个任务。
2)没有参考用户意愿,将感知任务进行合理组合,导致最终分配的感知任务可能与用户期望执行的任务相悖,不利于维护用户的长时参与水平,因此需要构建一个定量分析激励报酬、移动距离与用户执行意愿之间关系的数学模型。
考虑到上述情况,本文提出了面向用户区域的分布式多任务分配方法Crowd-Cluster 以解决实时并发的多任务分配问题。
1 问题模型
给定用户区域集合A={A1,A2,…,Am},用户区域Ai={Ui,Pi}。其中:为该用户区域的用户集合;Pi为该区域的中心位置。面向用户区域的任务分配中,由于不需要获取用户的实时位置,用户模型简化为二元组ui={nti,nui}。其中:nti为用户历史接受感知任务总数;nui为用户接受但最终未执行的任务数量。地理位置因素是Crowd-Cluster 进行任务组合及路径优化的主要变量,而信誉度只用于最后的参与者优选。
T={t1,t2,…,tn}为某一时段并发的感知任务集合,感知任务,其中:tlj为感知任务位置,tnj为感知任务所需的用户人数。面向用户区域的多任务分配方法有两个优化目标:最小化参与者人数和最小化用户移动距离。两个优化目标之间并不冲突,可以一起进行优化,其形式化定义如下:

2 Crowd-Cluster方法
Crowd-Cluster方法流程如图1所示。
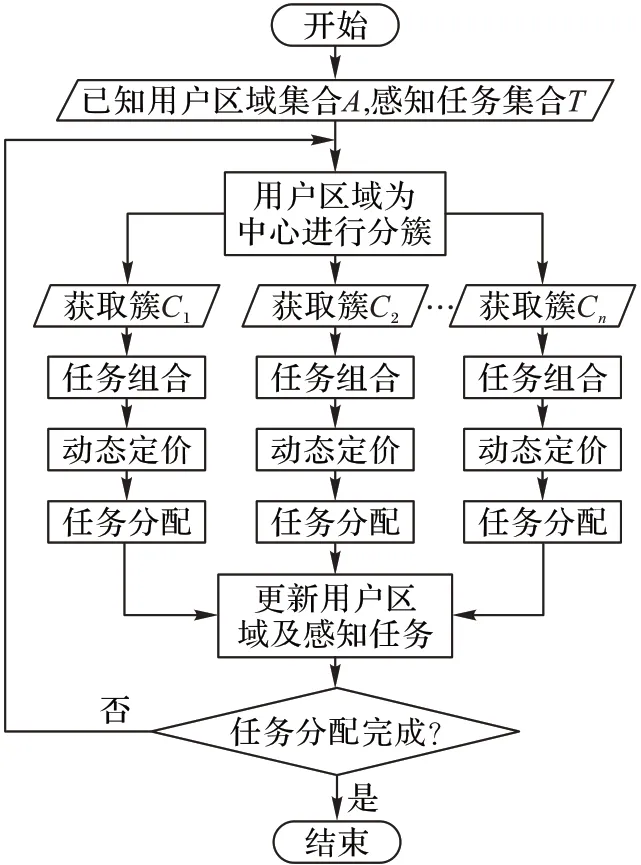
图1 Crowd-Cluster方法流程Fig.1 Flowchart of Crowd-Cluster method
2.1 全局分簇
Crowd-Cluster 采用贪心启发式分簇算法将全局用户区域和感知任务进行分簇,使得每个感知任务能够优先分配给与之最近的用户区域,以优化用户的移动距离,具体操作见算法1。簇集合C={C1,C2,…,Cn},每个簇包含一个簇头和多个成员,形式化定义为,其中MTi为一个任务集合,该任务集合的任意感知任务与Ai的距离均小于与其他用户区域的距离。簇头对应一个用户区域,感知任务则为簇内的普通成员。
算法1 贪心启发式分簇算法。
输入 任务集合T,用户区域集合A;
输出 簇集合C。
1)初始化簇集合C={C1,C2,…,Cn},集合中的簇Ci={Ai,MTi},MTi初始化为空;
2)选择距离感知任务t最近的用户区域Ai;
3)将感知任务t加入到MTi中;
4)对每一个感知任务t并行执行2)、3)步,直至所有感知任务均加入合适的簇中;
5)输出簇集合C;
6)结束。
2.2 任务组合
Crowd-Cluster 将簇内的多个感知任务进行组合,构成多条不定长任务路径(序列)。不失一般性,与现实场景出租车接单流程类似,用户更倾向于移动较短的距离去执行更多的任务。因此Crowd-Cluster 用任务平均距离Dm(λ)作为任务组合是否合理的评判指标,其形式化定义如下:

其中:numλ为任务路径λ 的长度(感知任务个数),totDλ为总移动距离,Dm(λ)含义为执行单个任务的平均距离。在获取任务路径的过程中,假设当前任务路径为λ,存在独立感知任务ti。将ti加入到λ 中组合成新的任务路径为λ*。若Dm(λ*)>Dm(λ),则任务路径λ*不合理,不能将λ 与ti进行组合,反之亦然。其次,任务组合最终获取的是任务路径,因此需要优化序列,类似于旅行商问题(Traveling Salesman Problem,TSP),寻找最优序列方案使得完成多个感知任务的总移动距离最小,该问题具有NP难解性。
为了提升效率将任务组合与路径规划同时完成,Crowd-Cluster 利用Q-learning 任务组合算法获取最优任务路径集合Λ,具体操作见算法2。该算法所获取的每一条任务路径具有以下特性:1)基于Dm(λ),任务路径是合理的;2)总移动距离是相同元素路径集合中最短的。
Q-learning 属于强化学习,其模式可以用四元组表示为(S,Act,P,r)。其中:S 为状态空间,Act为智能体的动作空间,P为状态转移概率,r为奖励。强化学习通过智能体与环境之间的交互,进行试错学习,最终学习得到智能体的策略。Q-learning基于特定状态下动作所对应的Q值进行决策。Q值为所获奖励的累积期望,智能体Agent 目标学习某一策略使得累积报酬最大化。Q值更新公式如下:
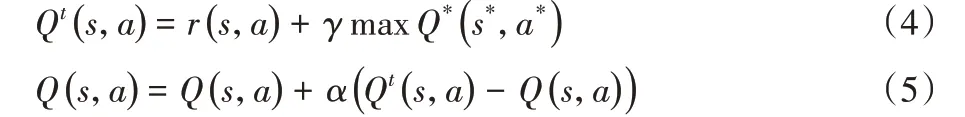
其中:Q(s,a)为状态s下执行动作a 所对应的Q 值,而r(s,a)为获得的奖励;α 为学习效率值;γ 为折扣参数。在构造任务路径时,将任意一个感知任务ta视作一个智能体Agent,其动作空间Act 为当前簇内的所有感知任务集合MT(不包括ta本身)。考虑到最终生成的任务路径节点数不定,因此在动作空间加入动作t0,用以代表空任务(即不选择任何邻居感知任务进行组合)。感知任务ta所对应的智能体Agent的状态可以表示为一个队列信息Qta,初始化时队列中只有ta一个元素。在每一个状态下会从MT 中选择一个任务加入到队列中,若所选任务已存在队列中,则不加入;同时将状态更新为新的队列,再进行下一次动作。每一次动作的奖励r 为-Dm(ct)。不失一般性,在实际场景中,每个用户其移动设备电量、网络流量、存储空间等感知资源有限,因此能够执行的任务数量是有限的,设置thr为任务路径的节点数量上限。
算法2 Q-learning任务组合算法。
输入 簇内任务集合MTi,簇头Ai,迭代次数E,贪心参数ε,任务路径节点数量上限thr;
输出 路径集合Λi。
1)初始化状态st=s0,智能体Agent 为感知任务ta。如果是第一次循环,则初始化QTable中的Q值为0。
2)根据常量参数ε 选取动作。以1-ε 的概率选取当前状态st下Q 值最大的动作;否则以均匀概率随机选取动作,选取的动作记为at。
3)根据动作at计算当前任务队列的效益作为奖励rt。
4)根据式(5)更新上一个状态st的Q值,同时更新队列状态st=st+1。
5)循环执行2)~4)步直至序列长度等于thr。
6)循环执行1)~5)步直至已迭代次数等于E。
7)根据学习好的QTable,选取每个状态下最大Q 值的动作加入到队列中,获得任务路径λa加入到路径集合Λi中。
8)对MTi中的每一个感知任务并行执行1)~7)步。
9)输出Λi。
10)结束。
簇内每个感知任务作为起点构成的任务路径集合Λi中可能会出现冗余,因此对于拥有相同感知任务的任务序列需要进行比较优选。Crowd-Cluster 通过任务路径分解算法用以保留总移动距离最短的任务序列,并将其余任务序列删除,具体操作见算法3。
算法3 任务路径分解算法。
输入 路径集合Λi;
2)选取任务序列λ,获取λ 中感知任务的最少所需用户人数Nmin,令λt=λ;
3)将λ t 中的所有感知任务所需人数减去Nmin,获取λt中未被完成的感知任务,构成新的任务序列λnew加入到Λi*中;
4)更新λt=λnew;
5)循环执行3)、4)步直至λt中的任务都能够被完成;
6)循环执行2)~5)步直至Λi中的所有任务路径都被分解完成;
8)结束。
2.3 动态定价
Crowd-Cluster 利用基于用户意愿的动态定价算法对每一个感知任务进行合理定价,以平衡任务与用户之间的供需关系,具体操作见算法4。不失一般性,用户是有限理性的,不一定完全基于最大化个人效益去选择任务,簇内的每一个感知任务都具有一定概率会被用户主动选择。因此,Crowd-Cluster方法构建了用户意愿模型,其形式化定义如下:
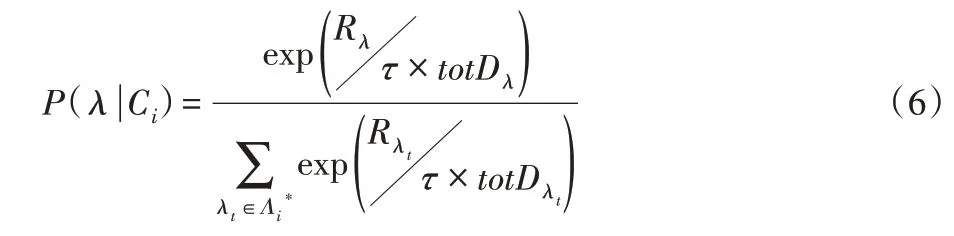
约束条件为:
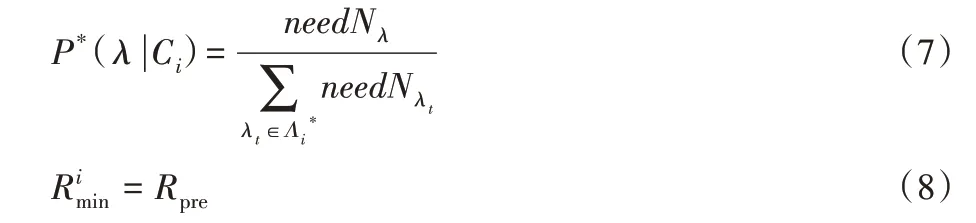
其中:P( λ |Ci)为在簇Ci内,用户主动选择执行任务序列λ 的概率;Rλ为任务序列λ 的报酬定价;τ 为一个0 到1 之间的常量参数。式(6)基于Boltzmann 分布使得每个感知任务都有一定概率被选中,并且定价越高、移动距离越小的任务序列有更高的概率被选中,反之亦然。
P*( |λ Ci)为能够平衡感知任务与用户间供需关系的任务序列λ 被用户主动选择的概率,当存在定价使得时,为λ的最终定价。
P*( λ |Ci)最小的任务路径的定价为一个先验值,即能驱动用户的最低定价。
算法4 基于用户意愿的动态定价算法。
输出 感知任务定价集合Ri。
1)初始化Ri为空;
2)选取任务序列λ,根据式(7)计算P*( λ |Ci);
5)输出Ri;
6)结束。
2.4 任务分配
Crowd-Cluster 利用基于信誉度的任务分配算法从簇内的用户区域Ai中选择信誉度高的用户执行任务序列,进而保障群智感知质量,具体操作见算法5。
算法5 基于信誉度的任务分配算法。
输出 感知任务分配方案Πi。
1)初始化Πi为空;
3)以P*( λ |Ci)为主要关键字,将中的任务序列进行降序排序;
5)按序从Ai选取用户ui加入到中,直至任务序列λ被完成,完成后将πλ加入到Πi中;
7)输出Πi;
8)结束。
3 实验评估与分析
首先通过一个简单案例描述Crowd-Cluster的分簇及任务组合流程,其多任务并发场景下的感知任务与用户区域分布如图2所示。
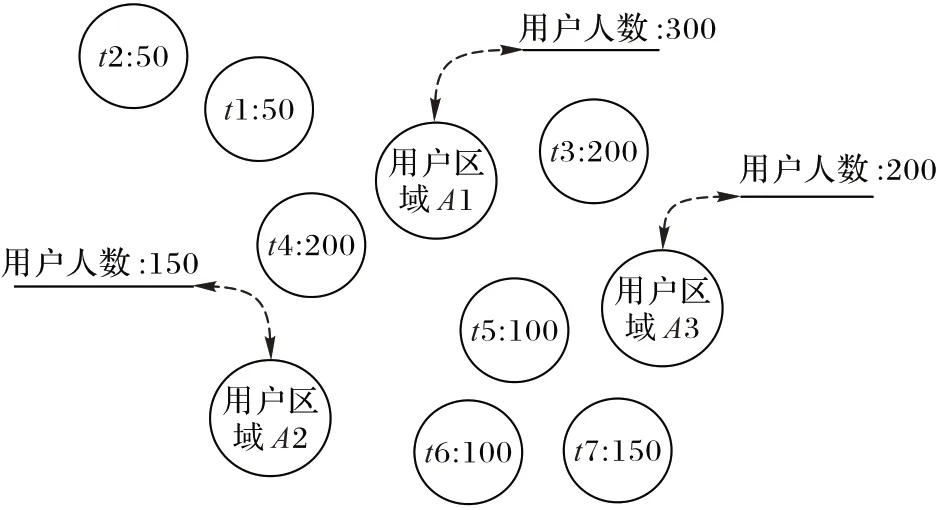
图2 感知任务及用户区域分布Fig.2 Sensing tasks and user area distribution
Crowd-Cluster 将图2 中的用户区域及感知任务基于欧氏距离进行贪心分簇,并采用Q-learning 进行任务组合,其结果如表1所示。

表1 图2的分簇及任务组合结果Tab.1 Clustering and task combination results of Fig.2
采用真实数据集mobility 进行正式实验评估,mobility 数据集由CRAWDAD 提供,为2008 年美国旧金山30 天内500 辆出租车的GPS 轨迹数据集。mobility 包括了车辆、纬度、经度、占用情况(0 表示出租车未使用,1 表示使用中)、时间(UNIX时间戳格式)。将占用情况为0 的坐标作为用户位置,占用情况为1 的坐标作为感知任务位置。将一个月内上午7 点至10点间的用户位置进行聚类,筛选人数最多的前10 个作为用户区域,共9 380 名用户。Crowd-Cluster 中的任务路径长度阈值设置为4,即最多只能将4个任务进行组合分配。用户的历史任务执行记录为1~30的随机数,用户失信记录比率为执行记录的1%~100%的随机数。
最小化移动距离、最小化参与者人数是两个主要的优化目标。本文将分配给用户单一任务的贪心算法Greedy-ONE作为基线算法。在不同的感知任务分布下,用移动距离、参与者人数、任务完成度等指标,评估比较Crowd-Cluster 与Greedy-ONE的性能差异。
全局范围内设置150 个感知任务,每个感知任务所需的用户人数为10到100之间的随机数。基于感知任务位置分布将分布情况分为三种类型:密集型、散点型以及混合型。密集型感知任务分布较为密集,相对距离较小;散点型感知任务较为分散,相对距离较远;混合型为部分区域呈现密集型分布,其余区域呈现散点型分布。由表2可得,Crowd-Cluster方法在不同感知任务分布情况下,其最终的用户参与人数均明显小于Greedy-ONE方法,能有效减少平台感知成本。
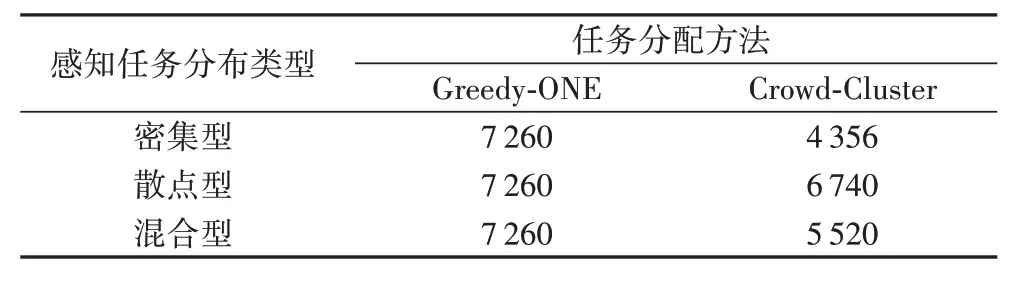
表2 不同任务分布下的参与者人数Tab.2 Participant number in different task distributions
由于Greedy-ONE 方法只分配单一任务,因此在任意的任务分布情况下,其最终所需用户人数都相同。而Crowd-Cluster方法将感知任务进行合理组合后,分配任务路径,如果感知任务过于分散则能够进行组合的任务就减少了,因此Crowd-Cluster 在较为密集的任务分布情况下具有更好的效果。
Crowd-Cluster 通过分配多个任务减少参与者人数,并通过Q-learning 对路径进行优化,因此在混合型感知任务分布下,随着任务数量不断增大,Crowd-Cluster 的用户移动距离小于Greedy-ONE,如图3所示。
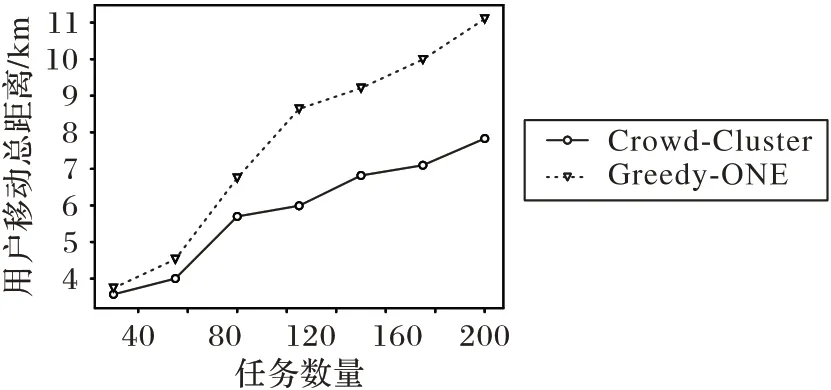
图3 不同任务数量下的用户移动总距离Fig.3 User movement distance under different task numbers
从图4 可以看出,在感知任务数量及分布不变的情况下,随着用户区域的用户数量不断减少,相比Greedy-ONE,Crowd-Cluster 能够明显降低用户资源不足对任务完成度的影响,进而保证感知质量。
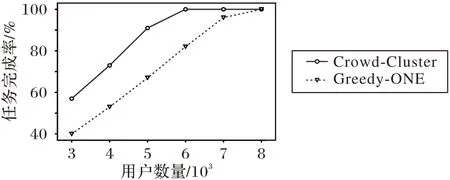
图4 不同用户人数下的感知任务完成度Fig.4 Sensing task completion degree under different user numbers
4 结语
本文面向用户区域提出了Crowd-Cluster方法以解决实际场景中的多任务分配问题。首先将全局的感知任务与用户区域进行合理分簇,每个簇内分布式进行任务分配。通过考虑移动较短距离执行更多任务的用户意愿,将任务进行组合构成任务路径。其次,通过构建符合用户有限理性的任务执行意愿模型对感知任务路径进行动态定价。最后,根据信誉度进行用户优选,将效益大的任务优先分配给信誉度高的用户执行。
Crowd-Cluster 仅考虑了感知任务的空间关联性,下一步需要完备考虑任务的时间、内容描述、数据类型等因素,将线上或线下的感知任务进行合理组合。其次,基于玻尔兹曼分布的意愿模型虽然能够体现用户的有限理性,但并不准确,如何从用户感知历史、移动轨迹中分析挖掘用户意图,构建准确个性化的用户意愿模型也是后续的重点研究方向之一。
猜你喜欢
小学生学习指导(低年级)(2021年12期)2021-12-31
发明与创新·小学生(2021年3期)2021-03-25
软件(2020年3期)2020-04-20
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生导刊(2018年34期)2018-12-18
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
思维与智慧·上半月(2018年11期)2018-11-30
北京教育·普教版(2017年1期)2017-02-05
母子健康(2015年1期)2015-02-28
