
基于数据增强和卷积神经网络的面部表情识别研究与实现
2020-04-08 09:30夏成静
电脑知识与技术 2020年3期
关键词:卷积神经网络
夏成静


摘要:针对面部表情数据集图片数量少、依靠人工选取特征的传统面部表情识别精度不高的问题,该文提出了一种数据增强和卷积神经网络(CNN)的面部表情识别方法。通过数据增强,使面部表情数据集Fer2013图片总数量变为原来的6.7倍左右。在传统的卷积神经网络中加入批量归一化(BN)和Dropout,能有效预防过拟合现象的发生,提高识别率。在Fer2013数据集上进行的实验结果表明:将Fer2013数据集进行数据增强后,采用本文提出的神经网络模型,训练集和验证集的识别准确率明显比未进行数据增强、仅采用CNN方法的准确率高。
关键词:卷积神经网络;数据增强;批量归一化;Dropout;面部表情识别
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2020)03-0213-03
面部表情是人们在日常交流过程中一种非语言传递的重要表达方式。面部表情识别在心理学、辅助驾驶、人机交互和计算机视觉等领域被广泛研究。1971年美国心理学家PaulEkman和Friesen…定义了六种基本面部表情:愤怒.高兴、悲伤、惊讶、厌恶和恐惧,并提出了面部动作编码系统(FACS)。罗元等[2]使用主成分分析(PCA)和支持向量机(SVM)相结合的方法分别提取面部表情特征和面部表情分类,其研究结果表明在平均识别率上这种方法比单独使用PCA和SVM方法有明显提高。刘涛等[3]采用高斯LDA方法对光流特征映射得到特征向量,并设计多类SVM实现面部表情分类和识别,在JAFFE和CK数据库中平均识别率分别是94.9%和92.2%。方彦[4]提出了一种基于卷积神经网络的人脸表情识别,采用了数据增强的方法人为扩充数据,在Fer2013数据库上的识别率达到66.38%。传统的面部表情识别系统包括:检测人脸区域、面部特征提取和面部表情分类,其中面部特征提取需要人为选择提取特征,特征选择的质量直接影响识别率的高低[5],因此鲁棒性差。随着计算机硬件水平发展,近年来深度学习迅速崛起,卷积神经网络是深度学习的经典算法之一,但是小样本集会影响神经网络模型的泛化能力,因此本文首先使用数据增强扩充图片数量,然后采用卷积神经网络进行特征提取和识别分类,可以提高分类识别率和鲁棒性。
1 基于数据增强和卷积神经网络的面部表情识别算法
本文的面部表情识别系统包括:数据预处理、模型学习、模型评估和新样本预测,总体框图如图1所示。采用监督学习方式,首先将数据集分为训练集、验证集和测试集,对三部分数据都进行数据增强,使图片数量成倍增长,其次用增强后的训练集训练模型,然后根据验证集的识别准确率调整超参数,最后选择最佳模型将新的人脸面部表情图片输入到其中实现面部表情的分类。
1.1 数据增强
Fer2013数据集图片数量相对较少,7类面部表情图片分布不均,有的类别图片数量较少,造成识别率低[6],使复杂、深层卷积神经网络的鲁棒性较差。为了提高训练模型对面部表情的识别率,使用图像增强方法,通过旋转、水平平移、垂直平移、透视变换、随机缩放和水平翻转一系列操作将图片数量增加为原来的6.7倍左右,增强后具体的图片数量如表1所示。
1.2 卷积神经网络
传统的卷积神经网络一般包括卷积层、池化层和全连接层[7]。在卷积层中,卷积核参数值通过反向传播优化后得到,并共享参数,每一层的每个输出都仅依赖一小部分的输入f稀疏连接),神经网络通过共享参数和稀疏连接可以减少权重参数,同时预防过拟合发生。在池化层中,池化方式有最大池化和平均池化,最大池化是选择每个过滤器的最大值,而平均池化是选择每个过滤器的平均值,在卷积层后连接池化层可以进行特征降维,压缩数据量[8]。在全连接层中,每个神经元与上一层的所有神经元相连接,可以综合卷积层和池化层提取的特征,从而得到每一类被准确识别的概率。
在神经网络学习中,权重初始值的设定影响到神经网络学习能否成功,在卷积神经网络中使用BN“强制性”地调整激活值的分布[9],使每层拥有适当广度,同时使得学习快速进行。Dropout是一种按照设定概率值随机删除神经元的方法。在训练过程中,随机选出隐藏层的神经元,然后将其删除,使其不再进行信号的传递[10],对于参数多、结构复杂的神经网络,使用Dropout能够有效地抑制过拟合现象发生。
本实验训练模型是一个10层神经网络,模型具体结构为每次卷积后,再经过四个步骤的操作:BN、Relu激活函数、最大池化和Dropout,共经过四次卷积处理,每次卷积后都重复上述四次操作,然后经过256个神经元全连接和512个神经元全连接,最后通过softmax激活函数获取7种面部表情分类的概率,根据最大概率确认识别的类别,本文的CNN结构如图2所示。神经网络每层参数如表2所示,输入是48*48像素图片,经过卷积后,输出图片的大小没变,但是通道数增加,再经过最大池化后图片的大小缩小为原来的一半,去掉冗余信息,使特征图减小,加快运行速度,最后输出1*7的向量。
2 实验结果与分析
本实验的硬件环境如下:Window7操作系统,i3-4170CPU、NVIDIA CeForce GTX 1060 3CB的CPU硬件环境。软件环境为Python 3.6.2.TensorFlow l.14.0,使用Keras 2.1.2搭建卷积神经网络。Keras是一个使用Python编写的高级神经网络API,可以使用TensorFlow作为后端运行,方便快速搭建神经网络,调整超参数。
2.1 实验结果
模型参数初始化是神经网络训练过程中的重要环节,合适的初始化数值能使模型快速趋于收敛,本实验模型参数的初始化如表3所示,批量處理尺寸(Batch Size)为128,总共训练轮数(Epoch)为200,优化器选择随机梯度下降算法(SGD),其中学习率(Leaming rate)参数设置为0.05,每次更新后的学习率衰减值(Decay)设置为le-5。
为了验证本文提出方案的可行性,使用Keras框架下的Im-ageDataGenerator进行数据增强,训练集、验证集和测试集的比例(8:1:1)保持不变,使用训练集和验证集调整面部表情识别的卷积神经网络框架的超参数,Epoch设置为200时,训练集和验证集的准确率变化曲线如图3中(a)所示,随着Epoch次数的增加,训练集和验证集的准确率随之提高,最后验证集上准确率是69.47%,损失值变化曲线如(b)所示,训练集和测试集的损失值随着Epoch的增加逐渐减小,Epoch值大于100后,验证集的准确率上升缓慢,损失值几乎不再下降。
2.2 实验结果分析
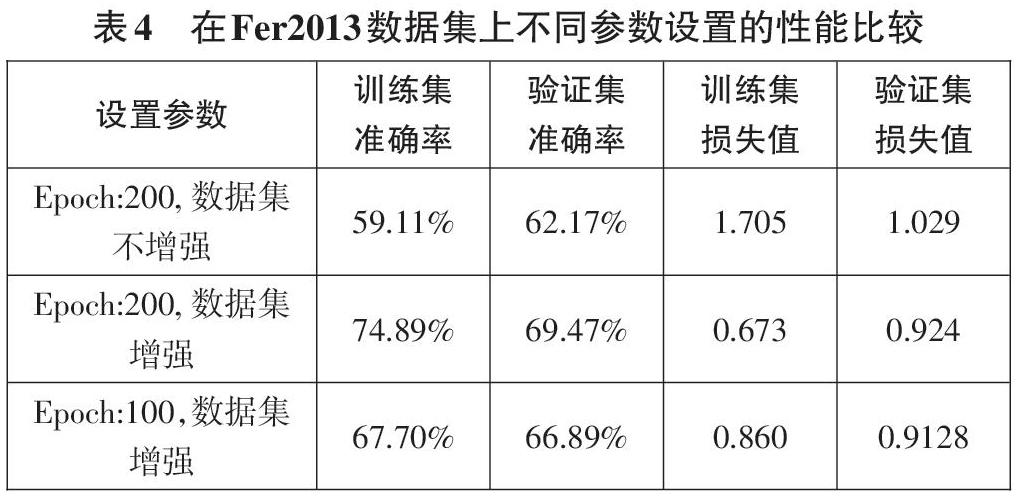
数据集是否进行数据增强,Epoch设置的大小都对训练集、验证集的准确率和损失值有较大的影响,本实验在Fer2013数据集上不同参数设置的性能比较如表4所示,第一列是实验中设置的参数,在实验过程中,Batch Size、优化器、Learning Rate等参数保持不变。当Epoch设置为200,数据集未进行增强时,训练集的准确率是59.11%,验证集准确率是62. 17%,由于验证集图片数量较少,验证集准确率高于训练集准确率,训练集的损失值比验证集的损失值高了0.676,为了提高在训练集和验证集上的准确率,需要增加训练轮数,即将Epoch设置为更大的数值。Epoch设置为100时,训练集和验证集的准确率变化曲线如图(c)所示,在数据集都增强且Epoch设置为200比Epoch设置为100时,训练集的准确率提高了7. l9%,验证集的准确率提高了2.58%,同时训练集的准确率和未进行数据增强的准确率相比提高了7.3%,Epoch为100时,训练集和验证集的损失值变化曲线如图(d)所示,当训练轮数达到100时,损失值还有下降趋势,由此可看出将数据集增强和Epoch设置为200时更合理,训练效果更好。实验结果表明通过数据增强扩充图片数量和设置合理的参数能提高训练集和测试集准确率,降低损失值。使用数据增强后的24000张测试集图片评估模型性能,平均准确率为70.05%,实验结果表明测试集上的平均准确率和验证集上的最高准确率几乎相等,模型泛化性能好。
3 总结
本文首先采用数据增强的方法对每张图片进行扩充,扩充后的图片总数量是原图片数量的6.7倍左右,然后提出了一种在卷积神经网络中加人防止过拟合现象的BN和Dropout操作的算法框架提取面部特征和面部表情识别。实验结果表明将Fer2013数据集进行数据增强后,训练集的准确率和未进行数据增强的准确率相比提高了7.3%,验证集准确率为69.47%,使用测试集评估了模型性能,表明模型的泛化能力好。
参考文献:
[1] Ekman P,Friesen W V.Facial ActionCoding System (FACS):A Technique forThe Measurement of Facial Action[J].Rivista Di Psichiatria, 1978, 47(2):126-38。
[2]罗元,吴彩明,张毅.基于PCA与SVM结合的面部表情识别的智能轮椅控制[J]计算机应用研究,2012,29(8): 3166-3168.
[3]刘涛,周先春,严锡君.基于光流特征与高斯LDA的面部表情识别算法[J].计算机科学,2018,45(10):286-290,319.
[4]方彦,基于卷积神经网络的人脸表情识别研究[J].现代信息科技,2019(14):81-83.
[5] Hua W T,Dai F,Huang L Y,et al.HERO:human emotions recog-nition for realizing intelligent Internet of Things[J].IEEE Ac-cess, 2019.7:24321-24332.
[6] Zhu X Y,Liu Y F,Li J H,et aI.Emotion classification with dataaugmentation using generative adversarial networks[M]//Ad-vances in Knowledge Discovery and Data Mining. Cham:Springer International Publishing, 2018: 349-360.
[7] Krizhevsky A,Sutskever I,Hinton G E.ImageNet classificationwith deep convolutional neural networks[J].Communications ofthe ACM, 2017,60(6):84-90.
[8]齋藤康毅,深度学习入门:基于Python的理论与实现[M].陆宇杰,译:人民邮电出版社,2018:1-285.
[9] Ioffe S,Szegedy C.Batch normalization:accelerating deep net-work training by reducing intemal covariate shift[C]//Proceed-ings of the 32nd International Conference on IntemationalConference on Machine Leaming - Volume 37, 2015:448-456.
[10] Srivastava N,Hinton G,Krizhevsky A,et al.Dropout:a sim-ple way to prevent neural networks from overfitting[J]. Thejournal of machine leaming research. 2014, 15(1):1929-1958.
猜你喜欢
科技创新与应用(2017年5期)2017-03-16
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
