
应用于嵌入式平台的实时红外行人检测方法
2020-04-08 03:38谭南林包辰铭
激光与红外 2020年2期
张 童,谭南林,包辰铭
(北京交通大学机械与电子控制工程学院,北京 100044)
1 引 言
随着智能驾驶和机器人在工业、军事和科学研究方面的快速发展,目标检测技术的发展显得尤为重要。智能驾驶的自动导航和避障受到了越来越多的关注,为了保障无人驾驶和机器人运动的安全性,必须有实时的目标检测技术。不同环境下的障碍物检测由于环境的不同、目标形态的多变性、光照不同的外部条件变化等,检测起来难度较高。
现有红外行人检测一般有两种方法,一种是基于人工提取特征进行特征学习并分类的方法[1],一种是基于深度学习提取特征的方法[2]。基于人工提取特征检测的方式,是在给定的一张图像上选取固定大小的区域,利用选取的区域人工设计提取特征(比如HOG[3]、SIFT[4]),对于提取的特征进行学习并用分类器进行分类(比如SVM[3])。此类方需通过滑动窗口实现,时间复杂度较高,且鲁棒性不强,很难保障红外行人检测的实时性。基于深度学习的方法是利用深度卷积网络[5]从图像中提取特征从而进行目标检测的方法,其特征一般要强于人工提取的特征,可分为one-stage和two-stage两大类。先提出来的two-stage通过产生潜在候选区域,根据训练的分类器来进行分类,代表性的网络为R-CNN[6]、SPPNet[7]、Fast R-CNN[8]和Faster R-CNN[9]等。One-stage的方法是直接通过神经网络预测出行人的位置,代表性网络有SSD[10]和YOLO[11]。随着YOLO[11-13]的提出和不断改进,YOLOv2[12]和YOLOv3[13]增强了模型的鲁棒性和准确率及检测速度,且准确率上已经超过了SSD。
综合考虑上述问题,本文提出了一种新型红外行人检测方法,可以应用于嵌入式设备。新方法的检测网络结构以YOLOv3模型为基础,对其模型参数进行优化,并结合MobileNet[14]网络将原始网络层进行压缩、简化,学习MobileNet网络的深度可分离卷积(Depth-wise Separable Convolutions)的思想压缩网络模型参数,同时利用YOLOv3的框架思路来提升网络的检测能力。
2 红外行人检测模型
2.1 YOLO网络结构
YOLO(You Look Only Once)是由Redmon等人在2015年首先提出来的[11],该模型不需要生成建议区域,直接对图像进行卷积操作,是一个End-to-End的网络。该模型利用整张图作为整个神经网络的Input,直接在输出层利用回归的思想计算出Bounding Box(边界框)的位置及其类别,随后通过非极大值抑制操作(NMS)去除多余的预测边界框,最终得到预测结果。Redmon等人于2016年提出了改进版YOLOv2[12],2018年提出 YOLOv3[13],对YOLO系列进行了革命性的改造,作者设计出高效的Darknet-53网络,使用了大量的1×1、3×3的卷积核,图像的大小缩减为1/32,即YOLOv3要求输入图片是32的倍数。
2.2 改进的YOLOv3红外行人检测模型
YOLOv3目标检测模型采用自主设计的Darknet-53网络模型提取特征,但是该网络模型有53层深度,且在卷积运算过程中参数众多,这导致在网络运行前向传播的过程中,特征提取模型参数文件大,耗费时间长,无法应用于嵌入式平台。
在红外行人检测中,检测目标单一(行人),红外图像的色彩丰富度较低。考虑到YOLOv3的Darknet-53网络模型是针对COCO和VOC多种类目标检测而设计,将其应用于红外图像的行人检测时,可以通过减少部分网络层数简化网络来提升红外行人检测速度。
现有神经网络优化方法多采用两种方式来取得较小且有效的网络。一种是压缩预训练模型;另一种是直接设计一个小型有效的网络模型进行训练。代表性的研究有:Christian Szegedy提出Inception网络[15],使用多尺寸卷积核去观察输入数据,并加入1×1的卷积核对数据进行降维处理;Bottleneck对Inception进行了改进[16],先用逐点卷积来降维,再进行常规卷积,最后逐点卷积来升维,该方法大大减小了计算量。Howard A G在Bottleneck的基础上提出了深度可分离卷积(Depth-Wise Separable Conv)[14],将标准卷积分解成深度卷积和逐点卷积,大幅度降低了模型的参数量和计算量,运算分解图如图1所示。
图1中,a为标准的卷积核,为Dk×Dk×M的标准卷积矩阵,b是Dk×Dk×1 的深度卷积矩阵,c为1×1×M的逐点卷积矩阵。
两种不同方式的计算量如下:
标准卷积计算量为:
Gs=Dk×Dk×M×N×DF×DF
(1)
深度可分离卷积计算量为 :
Gds=Dk×Dk×M×DF×DF+M×N×DF×DF
(2)
将深度可分离卷积和标准卷积对比:

(3)
当选取的Dk=3时,计算量大概为标准卷积的1/9,计算示意图如图2所示。图2中,a为标准卷积,b为深度可分离卷积,在深度卷积和逐点卷积之后都跟有一个BN和ReLU运算,标准卷积和深度可分离卷积运算之后的特征图尺寸和维度都相同。
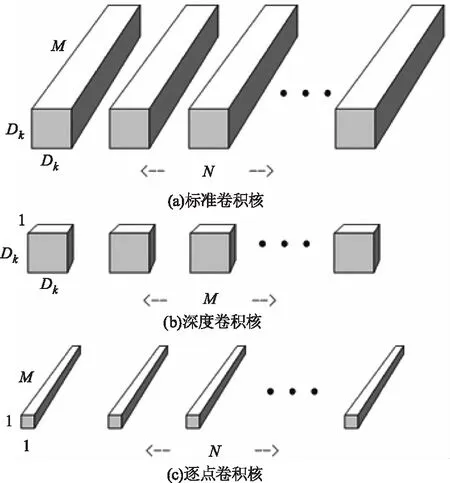
图1 深度可分离卷积运算

图2 Dk=3时标准卷积和DW卷积计算对比图
基于上述内容和红外图像的特点,我们结合改进后的深度卷积结构对YOLOv3模型主要进行了以下改进:
①采用MobileNet网络替换Darknet-53网络模型减少网络的计算参数和模型大小。针对Darknet-53网络模型较大,层数教深,不适合移植至嵌入式设备的问题,将其改进为Andrew G.Howard在深度可分离卷积基础上提出应用于嵌入式设备的MobileNet[11]网络,并将其原本的MobileNet-224网络修改为MobileNet-320以获得更好的准确率。
②将YOLOv3的辅助预测网络部分的传统卷积修改为深度可分离卷积。YOLOv3网络模型辅助预测层有较多3×3传统卷积,利用深度可分离卷积将传统3×3卷积优化为深度卷积和逐点卷积以获得更小更快的模型。
③在进行预测时,在CVC-09和CVC-14两个数据集上重新在三个尺度使用K-means方法聚类出9个Bounding box,平均 IOU准确率达到87.23 %。
改进后的YOLOv3网络结构如图3所示。从图3中可见,基础网络采用改进并去除最后全连接层的MobileNet-320网络,辅助预测的网络层使用经典的YOLOv3结构,在MobileNet-320中提取出三个不同尺度的特征图的进行多尺度特征融合进行预测。
3 模型训练方法
3.1 模型训练策略
模型的原始图片输入尺寸是320×320,在网络前向传播中,提取出三个通道的特征图输入到预测网络,其特征图尺寸为40×40×256、20×20×512和10×10×1024,图3所示的网络结构中,通过跳跃连接的两个特征图具有相同的尺度,两处的特征图的跳跃连接分别是20×20大小的尺度连接和40×40大小的尺度连接。在模型预测时,每一个Grid cell预测3个Bounding box,因为改进的红外行人检测模型采用的多尺度特征预测,一共在三个尺度进行预测,分别是10、20和40,所以Grid cell共有(10×10+20×20+40×40)×3个预测框,每个预测框有四个坐标参数(x,y,w,h)、一个置信度(obj_mask)和一个类别概率(class),相对于YOLOv3来说,该模型只预测行人一个目标,每一Grid cell对应的特征维数为3×(4+1+1)=18。

图3 本文提出的红外行人检测网络结构示意图
3.2 模型训练目标函数
在预测边框的时候,总的损失函数Lloss是四个损失函数相加,四个损失函数分别是预测行人框的中心点坐标误差Lxy、预测框的宽和高损失Lwh、预测行人的置信度损失Lconfi和预测行人的类别概率损失Lclass。
Lloss=Lxy+Lwh+Lconfi+Lclass
(4)
其中:
Lxy=∑[obj_mask×box_loss_scale×CEL(xygt,xypr)]
(5)
Lwh=∑[obj_mask×box_loss_scale×0.5×
(whgt-whpr)2]
(6)
Lconfi=∑[obj_mask×CEL(obj_mask,confi)
+(1-obj_mask)×CEL(obj_mask,confi)×
ignore_mask]
(7)
Lclass=∑[obj_mask×CEL(classgt,classpr)]
(8)
式中,obj_mask为预测的行人置信度;box_loss_scale为预测的行人框;CEL 代表二值交叉熵损失;xygt为行人框坐标的真实值;xypr为预测行人框的中心坐标;whgt为行人框的宽高的真实值;whpr为行人框的宽高;confi为行人的实际置信度;ignore_mask为IOU低于0.5但真实存在的标识;classgt为行人真实类别概率;classspr为预测的行人概率。
4 实 验
4.1 实验数据集
为了测试本文提出的实时红外行人检测网络结构的性能,我们首先选择了CVC的红外行人数据集进行红外行人检测实验,实验中使用到了三个数据集,分别是VOC 2007、CVC-09和CVC-14。本文将CVC-09和CVC-14数据集进行混合,将训练集、验证集和测试集按照7∶2∶1的比例进行重新划分整个数据集作为本文模型的数据集。图4中展示了CVC-09(如图4(a)、(b)所示)和CVC-14(如图4(c)、(d)所示)混合之后的红外行人示例图片。

图4 数据集CVC-09和数据集CVC-14的示例图片
4.2 评价标准
在检测本文提出的模型时,因为是应用于目标检测的模型检测,所以使用两个参数来评价模型的优劣,召回率(Recall)和平均准确率(mAP)作为红外行人检测的评价指标。
召回率、平均准确率计算公式如下:
(9)
(10)
(11)
4.3 红外行人检测模型的训练和测试
通过实验对本文提出的网络模型进行红外行人检测模型的训练和测试,将本文提出的模型和其他主流网络模型进行对比:YOLOv3和YOLOv3-Tiny。YOLOv3是YOLO系列最新的目标检测算法,也是现阶段主流算法之一,而YOLOv3-Tiny是YOLO系列的作者提出的一个小型且快速的检测网络。在下述的模型训练和检测都是在NVIDIA GTX1080显卡Ubuntu16.04同一平台下进行,实验采用的是上文介绍的CVC红外行人数据集进行检测。
实验共分为两轮,首先使用VOC2007数据集中的person目标类别粗调进行第一轮训练作为预训练模型。在预训练模型的基础上,使用混合好的CVC-09和CVC-14的图片集进行训练及验证。分别采用YOLOv3、YOLOv3-Tiny和本文提出的行人检测模型来进行训练与测试,得到了如表1所示的结果。图5展示的是在测试集的实验中,使用YOLOv3(图5(a)~(d))进行红外行人检测和使用本文模型进行红外行人检测的对比图(图5(e)~(f))。
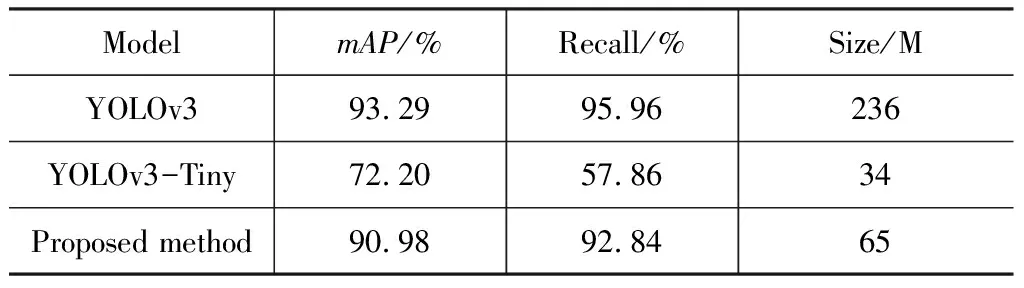
表1 使用CVC-09数据集进行红外行人检测的实验结果
从模型的测试结果可以看出,本文所提出的模型,在检测准确率和召回率上比YOLO-Tiny好很多,但是和YOLOv3相比的话,准确率和召回率有一些差距。主要原因是在网络的深度上进行了网络模型的压缩,基础网络由原来的53层网络变成了28层的网络,压缩了网络的深度和参数造成部分精度损失。




图5 模型CVC测试集效果图
4.4 网络模型嵌入式平台移植
现如今主流的Two-stage和One-stage目标检测算法测试基于台式机GPU,其功耗较大,难以做到嵌入式设备。在深度学习算法嵌入式设备移植中,本文所选取的是性能较好的NVIDIA Jetson TX2嵌入式GPU计算平台来移植本文所提出的模型。
在本次的移植实验中,针对本文提出的模型的正向传播的检测速度进行了对比实验,将网络模型部署在NVIDIA Jetson TX2嵌入式平台上,选取CVC测试集中的400张红外图像,网络模型中的输入尺寸320×320,使用上述参数对网络模型进行检测速度的测试,并使用HT35S远红外相机进行实时性验证,和现有的模型进行了对比实验,实验的过程和设备如图6所示。图6(a)采用YOLOv3检测,图6(b)采用YOLOv3-Tiny检测,图6(c)~(e)采及本文算法检测,实验结果如表2所示。

表2 红外行人检测速度在嵌入式设备TX2结果对比
从实验结果可以看出,在台式机的GPU(GTX 1080)上能够达到实时行人检测的算法如YOLOv3,在性能较好的嵌入式平台(Jetson TX2)上的检测速度仅有3FPS左右,而YOLOv3-Tiny虽然能够达到实时性的标准,但红外图像中行人检测的准确率和召回率却很低,难以实际应用于无人驾驶或机器人中。本文所提出的行人检测算法,准确率较高,实时性达到了11帧,比较适合应用于嵌入式系统如无人驾驶或机器人中进行红外行人检测。

图6 嵌入式平台红外行人检测
5 结 论
本文基于YOLOv3提出了一种适用于嵌入式设备的实时红外行人检测方法,利用深度可分离卷积操作简化分解普通卷积操作,不仅简化了整个深度神经网络模型的大小,还加快了运算的速度,使得其更适合移植至嵌入式设备。根据实验数据可以看出在嵌入式平台基本实现了实时红外行人检测。通过文章中的实验可以看出,深度可分离卷积和减少网络层数会影响红外行人检测的准确率和召回率,说明深度神经网络模型速度和精度是不可兼得的,提升速度是在损失一部分的准确率的条件下实现的。
猜你喜欢
环球时报(2022-05-23)2022-05-23
家庭影院技术(2021年7期)2021-08-14
金桥(2021年4期)2021-05-21
意林(2021年5期)2021-04-18
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
扬子江(2019年1期)2019-03-08
铁道通信信号(2018年2期)2018-04-18
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
