
基于最大稳定极值区域与主要旋转不变局部二值模式的复杂场景车牌检测方法
2020-04-08 08:18贾小云潘德燃
科学技术与工程 2020年4期
贾小云, 潘德燃
(陕西科技大学电子信息与人工智能学院,西安 710021)
在一幅图像中,如何定位车牌位置是车牌识别中的关键步骤。而目前常见的车牌定位方法大致可以分为下三类:一是基于车牌颜色特征的车牌定位方法[1],但该类方法只能适用于道路卡口或停车场管理等特定的应用场景,在复杂环境中由于角度位置各异、光照不同、背景变化等原因,很难达到满意的识别准确度;二是基于连通域分析的方法,随着自然场景文本检测的不断发展,应用MSER(maximally stable extremal regions)与SWT(stroke width transform)算法的车牌定位方法[2-3]也不断被提出。通过对连通域进行合理的分析,从而能够有效地定位车牌位置;三是基于滑动窗口[4-5]的方法,该类方法综合多种图像特征,利用滑动窗口结合机器学习或神经网络,能够精准地定位车牌位置,但其运算复杂,耗时较高。
本文提出一种基于MSER算法与DRLBP特征的复杂背景车牌定位方法。该方法充分利用车牌文本的上下文信息并设计出一种连通域分析器,该分析器通过对车牌字符进行合并从而完成车牌定位,此外还利用 DRLBP 特征对定位出的车牌进行再次检验从而提高定位的准确率。通过实验表明,该方法可以在多种场景下有效地对车牌进行定位,且对计算资源需求较小,基本不受车牌格式、颜色的影响。
1 多通道MSER候选区域提取
1.1 图像预处理
由于输入图像的分辨率不一,车牌的尺寸大小也会有较大差异,过大或者过小的车牌都会对检测造成一定的误判断。因此预处理的第一步就是将图像等比缩放到合适大小,所有图像均等比缩放到400 000像素左右。第二步提取灰度图像和红通道图像,由于车牌的字符颜色和车牌的底色具有明显的差异因此不需要在全部通道上进行MSER候选区域提取,而车牌底色和字符颜色又少有同时拥有红色分量,故本文仅在灰度图像和红色通道图像中进行候选区域提取。第三步,由于在缩放后的图像中车牌字符的笔画宽度通常不超过5像素,因此用5×5的结构元素分别对得到的灰度图像和红通道图像进行Top-Hat变换。Top-Hat变换可以消除不均匀的光照和增强暗的细节,从而减少MSER的漏检测。第四步,分别对变换后的图像提取Canny边缘,并用Sobel算子对边缘图像提取其垂直方向的边缘信息,从而消除掉大部分水平非字符边缘,而字符通常拥有丰富的垂直边缘信息,因此不会对车牌字符造成明显影响。第五步,对上一步得到的垂直边缘图像图进行高斯模糊,以模糊图中对应像素点的灰度比上模糊图中最大的灰度的比值乘以原图中的相应像素点的灰度值从而得到强调竖直边缘的灰度图像。第六步,由于处理后的图像对比度会有所降低,故分别对图像进行直方图均衡化,再进行伽玛变换以增强对比度。在实验中,由于光照强度不同伽玛得取值也有所不同,如在实验中白天光照充分伽玛取2.0~3.0,而在夜晚光照不充分时伽玛取9.0~10.0可以得到较好的结果。如图 1所示,分别是白天和夜晚的原图和预处理后的图。由图1(b)、图1(d)可以看到,预处理后图像中大多数变化平滑的区域几乎完全变为黑色,而车牌和一些竖直边缘密集的区域仍有较高的对比度。

图1 图像预处理Fig.1 Image pre-processing
1.2 MSER提取候选区域
MSER算法是一种检测图像中最大稳定极值区域的算法,最早应用于3D场景重建,目前在自然场景文本检测中也得到了广泛的应用。MSER算法的主要步骤是将一幅灰度图像以阈值从0~255进行多次二值化,从一幅纯白图像变为纯黑图像,或相反。其中每一幅二值图像中的黑色或白色的连通区域就是一个极值区域Q,即在原图像中该区域内的像素的灰度值都小于或都大于区域边界像素的灰度值。而在相邻阈值的二值图像中,极值区域Q1,Q2,…,Qi,…则构成嵌套关系,即Qi⊂Qi+1。当q(i)=|Qi+Δ/Qi-Δ|/|Qi|在i处取得最小值时,Qi即为最大稳定极值区域。而车牌字符又是显著的最大稳定极值区域,因此MSER算法能够有效地提取到车牌字符区域。但是MSER算法也会提取到很多非车牌字符的候选区域,因此需要对提取到的候选区域用简单特征进行筛选。文献[6]中所描述的可以快速计算的简单特征能够很好地除去大部分明显非车牌字符候选区域。具体MSER候选区域提取的步骤如下。
第一步,利用MSER算法对预处理后的图像进行候选区域提取得到一组候选区域;第二步,分别计算每一个候选区域的宽度、高度、边缘总长度、长宽比、占空比、紧密度这六个简单特征并排除掉不符合条件的候选区域,具体特征说明见表 1;第三步,用所有符合条件的候选区域为前景构造一幅二值图像,以此合并掉重叠的候选区域,在该二值图像中每一个连通区域即为一个候选区域;第四步,对其中的每一个候选区域用3×3的结构元素进行腐蚀运算,以此消除候选区域中细小的突出并使区域边界变得光滑;但如果腐蚀后连通域消失或者面积减小到1/9以下则说明候选区域的轮廓形状已经被显著改变,因此对于这类候选区域则跳过该步骤;第五步,用6×6的结构元素对面积小于500像素的候选区域进行膨胀运算以增大面积过小的候选区域;第六步,对每一个候选区域用3×3的结构元素再次进行闭运算,以填充区域内部的空洞、细小的裂痕并使得区域边界更加光滑。
对图 1中的两幅图像提取MSER候选区域的结果如图 2所示,车牌字符区域已经被提取出,但是由于场景复杂其中也包含很多非车牌字符区域。
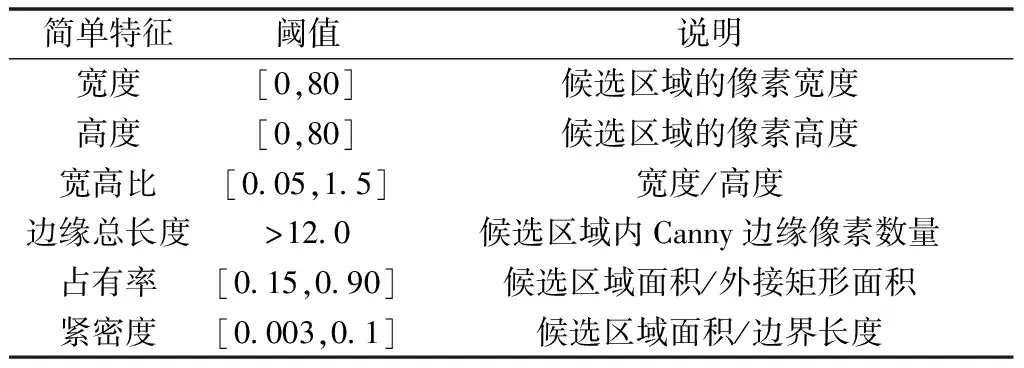
表1 简单特征说明及其阈值Table 1 Description of simple characters and its threshold

图2 车牌字符候选区提取Fig.2 License plate character candidate area extraction
2 基于MSER的车牌字符合并
在上步得到的二值图像中包含了车牌字符区域以及其他非车牌字符区域。但是由于复杂场景带来过多的噪声区域使得一些基于MSER的车牌合并算法不再适用。如文献[7]中通过构造最近邻对的方式进行合并,但此方法无法应对车牌区域过小而产生字符粘连的情况。由于车牌字符候选区域成线性排列、位置邻近、大小近似具有一定的规律性,而非车牌字符区域的位置和大小则相对任意。因此本文提出一种新的基于车牌字符合并的车牌定位方法。首先对于每一个候选区域计算五个属性,宽度、高度、面积、宽高比及方向。然后依据每两个区域的属性来判断是否将其合并。在判断每两个候选区域时,需要判断面积、宽高比、重叠度、位置相关度、方向及距离这六个方面。
(1)面积和宽高比:由于图像数据量在400 000像素左右,实验数据中车牌所占的像素尺寸通常在20 000像素以内。面积大于20 000像素或者宽高比大于4.0 的通常是非车牌区域不对其进行合并。
(2)重叠度:如果两个区域并集像素个数除以其交集像素个数的值大于0.75,则说明这两个区域具有较强的相关性,应当将其合并。
(3)位置相关度:该值为两个候选区域的最小外接矩形面积之和除以包含这两个候选区域的最小外接矩形面积,该比值用于评估两个候选区域的邻近度和相似度。当该值为1时,说明两个候选区域的外接矩形紧邻且形状相似。当两个区域相距较远、或大小不一都会使得位置相关度降低。将其阈值设置为0.7,即大于0.7时满足位置相关度条件。
(4)方向:候选区域的方向为其最小外接矩形中边长较长的边所指向的方向。能够合并的两个候选区域其方向需满足平行条件或者垂直条件,即两个方向最小夹角的角度需要在精度范围内。由于宽高比越小,其区域方向便越不稳定,故当两个候选区域中存在一个候选区域宽高比小于2.0时,精度范围取35°以内,否则为20°以内。即夹角小于35°或20°满足平行条件,大于65°或70°满足垂直条件。同时将候选区域面积小于2 000像素并且长宽都小于60像素的区域作为单个字符区域,否则为非单个字符区域。符合合并条件的候选区域需满足以下规则。
规则1若两个候选区都是非单个字符区域,那么两个候选区域的方向要满足平行条件,两个候选区域的中点的连线方向也要与两候选区域的方向满足平行条件。
规则2若两个候选区域中有一个是单个字符区域,由于单个字符区域的宽高比接近1.0,因此其方向并不稳定。此时只需两个候选区域中点的连线方向与非单个字符区域的方向满足平行条件即可合并。
规则3如果两个候选区域都是单个字符区域,则不需要对方向进行判断。
(5)距离:在两个候选区域面积相差较大的情况下,面积较小通常为噪声区域。将这些区域进行合并会意外增加另一个区域的面积,从而降低车牌字符合并的准确度。因此,能够合并的两个候选区域还需满足两个候选区域的距离应当小于面积较小候选区域面积开方的1.0倍。
当所有候选区域都不能再进行合并时,输出所有面积在400~20 000像素之间且宽高比大于2.0的区域即为车牌候选区域。
3 应用DRLBP特征的车牌再定位
通过基于MSER车牌字符合并的车牌定位方法能够有效地定位车牌候选区域,但也会存在一些误判的非车牌候选区域。而这些非车牌候选区域已经难以用简单特征进行有效的区分。因此本文在最后应用DRLBP[8](dominant rotated local binary pattern)纹理特征结合支持向量机(support vector machine,SVM)分类完成最后的精确定位。

图3 车牌定位结果Fig.3 The result of license plate location
DRLBP是LBP[9](local binary pattern)特征的扩展,对LBP特征增加了旋转不变特性并使用主要模式来代替uniform模式。LBP是一种基于图像像素的纹理特征,该特征及其相关拓展在目标检测中有着广泛的应用,如人脸识别[10]。它以中心像素为原点,以L为半径,在其圆周上等分采样P个顶点。如果采样点p的坐标不是整数,则对其坐标进行向上和向下取整。用邻近的四个像素的灰度对其进行双线性插值从而计算出点P的灰度。如果点P的灰度大于中心点,那么该点则标记为0否则为1。将这P个采样点的标记连接起来就是中点像素的LBP编码,取L=1,P=8则LBP编码共有256种。但是LBP编码与图像旋转相关,因此在不同起点得到的LBP编码中以值最小的作为该中心点的LBP编码,以增加旋转不变性即RLBP(rotated local binary pattern)。又因为LBP编码的uniform模式只允许编码中最多出现两次0-1或1- 0跳变。当图像的纹理主要是由直线构成或者弯折较少时,uniform模式可以有力地代表其纹理特征。但是对于复杂的纹理,如字符通常拥有较多的曲线弯折时,uniform模式则不能很好地表示其纹理特征。因此文字区域的特征采用DLBP(dominant local binary pattern),即使用主要模式代替uniform模式。DLBP是通过计算图像全部的LBP编码,根据不同LBP编码的出现的数量建立统计直方图,并对其进行降序排列。当前K个LBP编码的数量占据总编码数的80%时,则将前K个编码作为主要模式。根据Liao等[11]在Brodatz、Meastex、CUReT数据库上进行的测试,占全部编码数量80%的模式种类大约只占所有编码种类的20%左右。因此DLBP特征能够在有效捕获复杂纹理特征的同时只较少地增加数据维数。
结合RLBP与DLBP的特点,采用DRLBP,即主要旋转不变的局部二值模式作为候选区域的纹理特征并结合SVM分类实现对车牌候选区域的再次定位。结果如图 3所示,红色和绿色框即为基于MSER车牌字符合并的车牌定位方法的结果。通过应用DRLBP特征进行车牌再定位可以将非车牌区域排除,只保留最终的车牌区域,用绿色框标出。
4 实验结果与分析讨论
4.1 数据集及评价标准
实验数据集包含400张白天不同场景的车牌图像,其中300张作为训练图像,其余100张作为测试图像,另有300张夜晚的车牌图像,其中200张作为训练图像,其余100张作为测试图像。使用f-measure作为测量评价标准,其中包含召回率R、准确率P及F。每幅图像均包含一组真实的车牌区域T,用本文所述方法对其每幅进行车牌定位也可得到一组评估的车牌区域E。在一幅图像中任取一组(t,e)其中t∈T,e∈E,这两个区域交集的像素个数比上其并集的像素个数的值即为其m。而当m(t,e)=1时评估区域t则与真实区域e完全重合,当m(t,e)=0时,区域t与区域e则完全分开。召回率则是对每一个真实区域与所有评估区域计算其m,并取其最大值。然后所有真实区域的m相加并除以真实区域的个数。而准确率则是对每一个评估区域与所有真实区域计算其m并取其最大值。然后将所有评估区域的m相加并除以评估区域的数量。
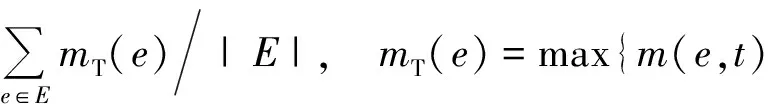
|t∈T}
(1)
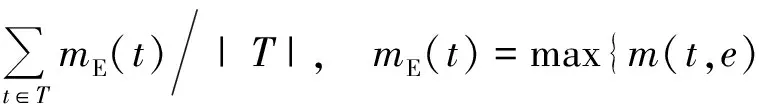
|e∈E}
(2)
F的大小由召回率、准确率和其权值α的大小共同决定。令α=0.5。F的计算方法如下:
F=1/[α/P+(1-α)/R]=2RP/(R+P)
(3)
4.2 车牌定位结果
实验采用以下四种算法进行对照。一是仅利用本文提出的基于MSER车牌字符合并的车牌定位算法;二是在算法一的基础上使用DRLBP结合SVM进行车牌区域再定位;三是文献[7]所提及的基于构造最近邻对的方法;四是文献[5]中所采用的基于Faster R-CNN结合VGG网络的车牌的定位方法。实验平台为Ubuntu 16.04系统,8G内存,Intel i3-3225, 3.3 GHz CPU。相关实验结果如表2、表3所示。
对不同国家的车牌在多种场景中进行定位的结果如图 4所示。
通过上述实验可得以下结论。
(1)提出的基于MSER车牌字符合并的车牌发现方法能够有效地定位车牌位置,在测试图像中其召回率为95%。
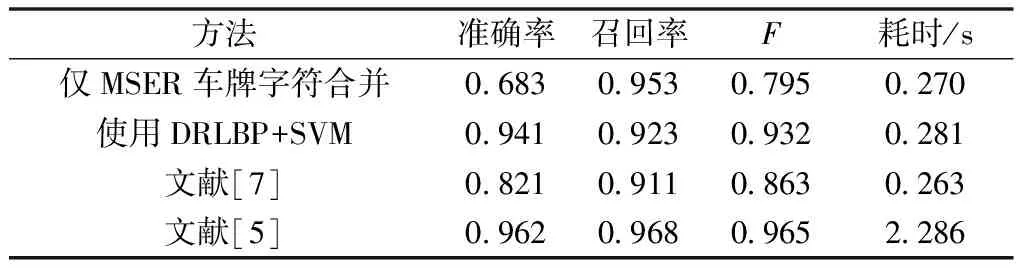
表2 白天车牌定位结果Table 2 License plate location in the daylight
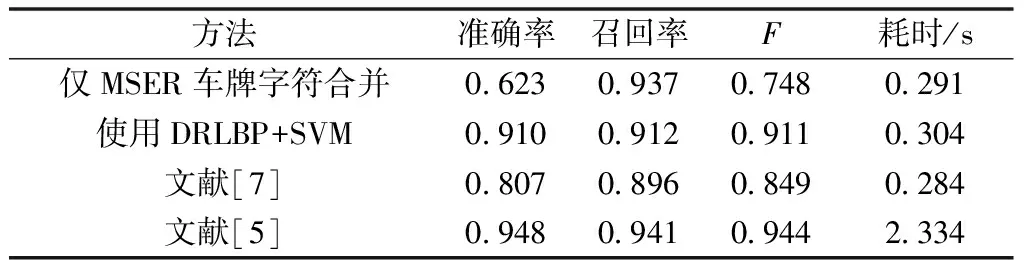
表3 夜晚车牌定位结果Table 3 License plate location in the night

图4 对不同国家的车牌进行定位的结果Fig.4 Locating license plate in different countries
(2)通过SVM结合DRLBP纹理特征进行再次定位后,能够显著地提高定位准确率而召回率只有略微的降低,显示本文方法的有效性。
(3)本文方法基本不受车牌颜色、格式的影响,对国内外各种车牌均有一定效果。
(4)文献[7]所提及的构造最近邻对的方法在复杂场景中易受过多干扰的影响,因此其准确率和召回率均低于本方法。其所设计的最近邻对合并方法也只针对于中国车牌。
(5)基于神经网络的方法虽然在准确率和召回率上均高于其他方法,但在缺乏GPU仅依靠CPU运算时,其耗时明显高于其他方法,因此不适于计算资源有限的情况。
5 结论
首先利用MSER算法以及自主设计的车牌字符合并算法进行车牌定位,其次采用DRLBP特征对定位结果进行进一步验证。实验表明对多种车牌均有较好定位效果。但实际环境纷繁复杂,实验难以囊括全部,而通过调整本文所述方法的参数,如预处理中的伽马、MSER算法的相关参数、文本合并算法的相关阈值,则能够使得本方法快速适应不同的复杂环境并得到满意的结果。
另一方面,本方法基于MSER算法。MSER算法的高召回率既是优点,也是缺点。在复杂场景中,MSER会带来非常多的难以通过简单特征筛选掉的非字符候选区域。大量的非字符候选区域会使得车牌字符合并变得困难。后续会对MSER候选区域提取的筛选能力做进一步提高。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
天津医科大学学报(2021年1期)2021-01-26
汉字汉语研究(2020年2期)2020-08-13
中国信息技术教育(2020年2期)2020-02-02
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年12期)2019-07-16
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
