
基于灰狼优化的反向学习粒子群算法
2020-04-07 10:48周蓉,李俊,王浩
计算机工程与应用 2020年7期
周 蓉,李 俊,王 浩
1.武汉科技大学 计算机科学与技术学院,武汉430065
2.智能信息处理与实时工业系统湖北省重点实验室,武汉430065
1 引言
粒子群[1](Particle Swarm Optimization,PSO)算法,又称粒子群优化算法或鸟群觅食算法,是由Kennedy和Eberhart 等提出的一种新型进化算法,该算法通过追随当前搜索到的最优解来寻找全局最优。由于该算法有实现容易、收敛快等优点,近年来被广泛应用于诸多领域,如医学[2]、图像处理、特征选择[3]等,并取得了较好的效果。但存在易早熟收敛[4-6]、算法后期收敛较慢等问题,近年来,众多学者对其不足,提出了一些相应的改进策略。
针对PSO存在的不足,研究人员做出了不同的改进措施,其改进主要体现在全局搜索性能和局部搜索性能两方面。为了提高全局搜索能力[4-5,7],文献[4]针对基本灰狼优化算法在搜索过程中不是线性搜索的问题,提出了一种基于预先规律变化的收敛因子,使得其在迭代前期,具有较大的收敛因子,增强其全局搜索能力,在迭代后期,即从比自己较优的粒子群体中随机选取一个个体进行学习,通过这种方式在提高粒子的搜索能力同时增强开采能力,但该算法本身的等级制度限制了其全局搜索的能力,该文献虽然对其进行了改进,但是其仍然存在易陷入局部最优的情况;文献[5]针对SLPSO 算法收敛速度慢等问题,将社会学习运用到粒子搜索的过程中,并利用选择交叉反向机制,提高种群的多样性以及算法的全局搜索能力,但该算法在面对混合函数优化问题时,其收敛效果不佳,易陷入局部最优;文献[7]对粒子群算法的速度项引入动态的惯性权重,即根据迭代过程及粒子的运动情况对其惯性权重进行线性或非线性的调整,模糊自适应方法在一定程度上可以提高算法的收敛精度,但这种方式牺牲了收敛速度。在提高局部搜索能力[8-10]方面,文献[8]将细菌觅食优化算法中的趋化算子嵌入到算法中,趋化算子的功能主要是其具有较强的局部搜索能力,与PSO算法本身所具有的全局搜索能力互补,从而提高算法的寻优效果,该算法虽然在收敛性方面有了提高,但是在复杂情况下还是会出现搜索停滞的情况,即会陷入局部最优。为了平衡算法的全局搜索和局部搜索性能[6,11-15];文献[6]采用多种搜索策略,对种群中的所有个体采用反向学习策略,增强算法的全局搜索性能,并对种群中部分较差个体分别采用柯西变异,对部分较好个体差分进化变异,从而增强算法的局部开采能力,且其收敛速度较快,该搜索策略的稳定性不够,在较为复杂的环境中,存在易陷入局部最优的情况;文献[11]通对种群分布和粒子适应度值的评估,采用实时进化状态估计方法,将其状态分为四种状态,并根据不同状态调整其各项参数,提高算法的搜索效率和收敛速度,据该文献的实验数据表明,其在某些优化问题中出现不收敛的情况,即该算法的稳定性较差;文献[12]根据单一的学习方式可能导致粒子的搜索陷入局部最优这个问题提出了一种自学习的策略,每个粒子都采用四种搜索策略来处理空间的不同搜索情况,避免其陷入局部最优的情况;文献[13]提出一种多策略融合的搜索机制,采用禁忌探测机制遍历整个搜索空间跳出局部最优,并利用局部学习策略提高算法的收敛精度,达到平衡全局搜索和局部搜索的目的。
上述的文献中采用各种方式针对基本PSO 算法进行改进,且在一定程度上提高了算法的搜索性能,但其存在具有易陷入局部最优和收敛速度较慢等问题。为了进一步提高算法的性能,本文以HPSO[6]为基础,提出一种基于灰狼优化的反向学习粒子群算法(Particle Swarm Optimization with Grey Wolf Optimization and Reverse Learning,HGPSO)。首先,对每个种群个体采用反向学习策略[16-18],增强粒子的多样性,提高算法的全局搜索能力;同时,利用改进的灰狼优化算法提高算法的局部搜索性能;最后,采用一种新型学习方式,合理利用所有粒子的信息,从而提高算法的搜索性能。
2 粒子群算法与灰狼优化算法
2.1 粒子群算法
PSO算法是一种群体智能随机搜索算法,对于一个D 维的优化问题而言,群体中的每个粒子可表述为一个可行解。在整个算法执行的过程中,其个体最优解和全局最优解均被用来引导粒子的位置和速度更新。假设当前种群的规模为N,维度为D,则粒子X 的位置可以表示为Xi=( xi1,xi2,…,xid,…,xiD),其中xid表示粒子X 在第i 维的第d 个分量;而粒子X 的速度可以表示为Vi=(vi1,vi2,…,vid,…,viD),其中vid表示当前粒子的第i 维的第d 个分量的速度,粒子的速度更新公式和位置更新公式如下:

其中,vid(t+1)和xid(t+1)分别为粒子i 在第t+1 代的速度和位置。ω 为惯性权重,c1和c2表示社会学习系数,r1和r2是[0,1]间均匀分布的随机数。
2.2 灰狼优化算法
灰狼优化(Grey Wolf Optimiztion,GWO)算法[19]是一种新型的群体智能优化算法,它模拟的是自然界中灰狼群体的社会等级机制和捕猎行为。在灰狼群体中,具有严格的社会等级体制。其中,α 狼是最高级别的灰狼,β 狼是α 狼的下属灰狼,而δ 狼则是β 狼的下属狼,则δ 狼要服从α 狼和β 狼的命令,等级最低的灰狼称为τ 狼。灰狼狩猎主要分为追踪、包围和攻击三个阶段。假设灰狼种群规模为N,搜索空间为D 维,第i 只灰狼的位置可表示为Xi=( xi1,xi2,…,xid,…,xiD)。
在包围操作中,其过程可以用数学描述如下:

其中Xp表示猎物的位置,X(t)表示的是第t 代时灰狼的位置,A 和C 为系数向量,r1和r2为[0,1]的随机数,a 为控制参数。A 和C 的更新公式为:

在灰狼优化算法中,种群中的粒子位置更新由Xα、Xβ和Xδ引导,其数学描述为:
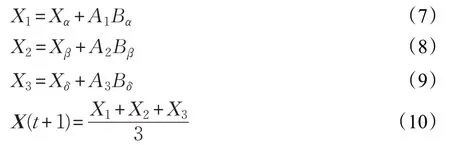
3 HGPSO算法
本文根据PSO 算法的在搜索方式,其学习的对象是当前的全局最优解和当前个体的个体最优解,即在其搜索过程中存在全局搜索能力差和收敛精度低等问题。针对基本PSO 存在的问题,首先利用反向学习策略(Opposition-Based Learning,OBL),通过提高种群的多样性,扩大种群的搜索范围,并对其惯性权重采用贝塔分布进行扰动,从而提高算法全局搜索的能力;其次为了进一步提高算法的局部搜索能力,根据GWO 算法的搜索方式可以看出,其寻优过程主要是围绕着最优解进行的,即在当前最优解的周围进行搜索,采用贝塔分布对其位置分布按照搜索前后期要求进行扰动,以提高算法的收敛精度和收敛速度。最后在每次迭代完成后,对两种搜索策略的结果进行重组,实现信息的交互,取其部分解作为下一代种群个体,通过这两种搜索策略达到平衡算法全局搜索和局部搜索的效果。
在反向学习搜索方式中,对于最优粒子在迭代前期采用随机反向学习,提高种群的多样性,扩大种群的搜索范围,而在迭代后期,采用交叉反向学习机制,根据随机概率,选择一般反向学习或最优解随机交叉反向学习,且最优解随机交叉反向学习的概率由迭代次数控制,根据算法迭代后期的特点,提高算法的收敛速度;对于其非最优粒子,采用一种新型的非最优社会学习方式,在比自己优秀的粒子中随机选取一个更优粒子进行学习,提高当前粒子自身的搜索性能,避免其因为只学习最优粒子而限制其开采能力,降低收敛速度。在改进的灰狼优化算法中,根据适应度值选取全局中的三个最优解,作为算法搜索过程的引导者,在迭代前期帮助条算法的收敛速度,而在后期则提高算法的局部搜索能力,提高算法的求解精度。
3.1 贝塔分布
PSO中的惯性权重ω 和GWO中的收敛因子a 是算法中的重要参数,其变化影响着算法的收敛速度及搜索性能,因此,本文引入贝塔分布(Beta Distribution)[20]。对其惯性权重和收敛因子进行扰动,使其分布更加合理。贝塔分布是满足二项分布和伯努利分布的密度函数,其分布在[0,1]之间。贝塔函数公式和概率分布函数为:
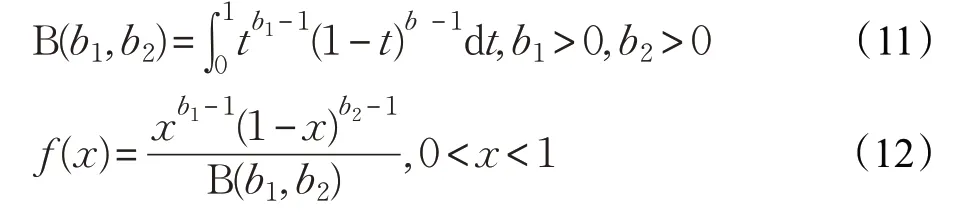
其概率密度函数如图1 所示,当参数b1和b2取不同值时,其分布情况不同。当b1=b2=1 时,贝塔分布属于均匀的状态;当b1<b2时,其函数靠左倾斜;当b1>b2时其函数靠右偏斜。

图1 贝塔分布概率密度函数图像
3.2 动态惯性权重
在PSO 算法中,惯性权重ω 在平衡算法的收敛速度和全局搜索能力方面有着重要的作用,研究表明,较大的惯性权重ω 可以提高种群的多样性,而较小的惯性权重ω 则可以提高算法的局部开采能力。参考文献[20-23]对惯性权重进行处理,其中赵志刚等[21]提出随机惯性权重,利用随机分布的方法控制惯性权重的变化,其生成公式为如下:
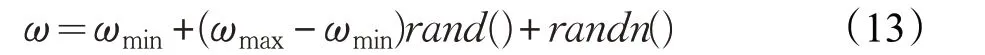
其中,ωmin和ωmax分别为惯性权重的最大值和最小值。
随机惯性权重是一种非线性的减小ω 的优化策略,利用随机变量的随机性调整惯性权重,第三项中的rand()是正态分布的随机数,与σ 结合来控制权重向期望权重方向进行移动,提高算法的搜索效率,但是在搜索后期,所有粒子都像最优解靠近,忽略了种群的多样性,使其收敛速度变慢,且有可能陷入局部最优的情况。针对以上的问题,本文提出一种新型的权重更新策略,该策略引入余弦函数和贝塔分布来引导惯性权重的非线性变化,其更新公式为:

其中,余弦函数的引入可以在一定程度上改善算法易陷入早熟的问题,同时可以提高算法的搜索效率。贝塔分布的引入主要是利用其随机性,提高算法后期的收敛速度和种群多样性。相关实验[24]表明,在给定的实验条件下,贝塔分布的性能与高斯分布和柯西分布相当,但在某些情况下,贝塔分布的性能甚至优于高斯分布和柯西分布。式中的ωmin和ωmax分别为惯性权重的最大值和最小值,这两项用来控制权重的取值范围为[0.4,0.9],相关实验表明,惯性权重在此范围内时能够使得算法取得更好的寻优性能。σ 为惯性权重的调整因子,与贝塔分布融合后控制惯性权重ω 的偏移程度,使得其更好地提高算法的收敛速度和全局搜索能力。
3.3 改进灰狼优化算法
针对PSO易陷入局部最优这一问题,本文嵌入改进的GWO 算法。在智能优化算法中,适应度函数值是衡量当前粒子位置是否最优的唯一标准,在粒子更新中起着至关重要的作用。从文献[25-26]对GWO算法的优化可知,在GWO算法中的收敛因子a 控制着参数A 和C的变化,而|A|>1 时,进行全局搜索,即扩大搜索范围,增强其全局性;当|A|<1 时,进行局部搜索,即缩小搜索范围,提高局部搜索性能,但在此过程中其收敛速度较慢。由基本灰狼优化算法可知,线性递减的收敛因子a并不能体现算法的最优搜索性能,所以本文引入余弦定理改变收敛因子的递减方式,并引入贝塔分布对其进行扰动,提高算法的搜索性能,其公式为:
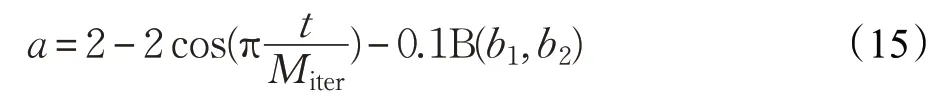
其中,t 表示当前迭代次数,Miter表示最大迭代次数,贝塔分布的b1和b2的详细介绍见3.2节。
3.4 HGPSO的算法描述
HGPSO的算法具体实现步骤如下:
步骤1初始化种群规模N、种群维度D、最大迭代次数Miter、种群粒子的初始位置X、初始化参数学习因子c1和c2、惯性权重ω 等参数。
步骤2计算种群的适应度值,并将种群按照适应度值进行升序排序,求适应度值最优的三个个体将其粒子位置保存在X1、X2和X3中,并更新个体最优解pbest和全局最优解gbest。
步骤3对于最优粒子,在迭代前期,若随机数r5≤0.5,则采用随机交叉反向学习,否则采用随机最优解交叉反向学习;迭代后期采用一般反向学习。
步骤4对其非最优粒子采用非最优社会学习策略,并保存更新的X 的值为Xnew1。
步骤5按照公式(15)更新a,按照公式(5)和(6)分别更新A 和C,根据公(10)更新X1、X2和X3的值,根据公式(15)更新X 的值,并保存更新的X 的值为Xnew2,合并Xnew1和Xnew2为Xnew。
步骤6更新适应度函数值,将其排序取前50%为新的种群个体,并更新个体最优解pbest、全局最优解gbest、X1、X2和X3。
步骤7判断是否满足终止条件,若满足则返回全局最优适应度值;否则返回步骤3进行循环迭代。
4 实验分析
4.1 实验测试函数
为了验证本文算法的适用性、有效性和高效性,选择CEC2017[27-28]中的29 个标准测试函数,与基本PSO、基本GWO、CPPSO[5]、HPSO[6]进行实验对比。其函数具体定义如表1所示。

表1 CEC2017测试函数
表中f1、f3 为单峰函数,f4~f10 为简单多峰函数,f11~f20 为混合函数,f21~f30 为复合函数。其中函数f2 由于其不稳定性,在此将不对其进行实验。
4.2 参数设置
4.2.1 基本参数
HGPSO 算法的各项参数设置为:种群规模N 为90,低维度D 为30,最大的迭代次数Miter为3 000,高维度D 为100,最大迭代次数Miter为5 000,学习因子c1和c2均为1.496 2,数据的取值范围为[-100,100]。在动态调整惯性权重中,文献[28]表明,当ωmin和ωmax分别为0.4和0.9时可以加快算法的收敛速度。通过实验证明,惯性权重在此范围内的实验效果是最好。实验环境为:Intel®Core™i5-5200U CPU@2.20 GHz,RAM 8.00 GB,Windows 10 操作系统,MATLAB 2016a。
4.2.2 惯性权重
在PSO算法中,惯性权重的调整可以提高算法的收敛效果,在本文提出了一种引用余弦函数和贝塔分布的惯性权重,在这里与随机惯性权重进行对比。其实验对比如表2所示,其中HGPSO_rand算法表示采用公式(13)的改进的HGPSO算法。

表2 惯性权重对比
从表1中可以看出,在相同的测试环境下本文提出的权重更新策略的求解精度比随机惯性权重的求解精度要高。
4.2.3 参数b1 和b2 选取
在惯性权重中融入贝塔分布,利用其随机性调整惯性权重,使其向期望权重的方向进化,从而提高算法的搜索性能。本文根据贝塔分布的函数分布情况,设置以下几组参数,并对其进行实验对比,其实验结果如表3所示。从表3的数据可以看出,当贝塔分布的参数b1为1,b2为2 时,其实验效果最好,所以在本文中,参数b1和b2的取值分别为1和2。

表3 贝塔分布参数b1、b2 对比
4.3 实验结果与分析
为了避免随机性和偶然性对实验结果造成的影响,此次实验中都对每个算法在低高维30 维和中高维100维上分别独立运行30 次,不同维度的选择是为了增加寻优难度,以便于验证HGPSO 算法在处理各种复杂问题时的能力,统计各函数的适应度平均值和方差,其实验结果如表4、表5和图2所示。其中,表4给出了HGPSO算法与其他四种对比算法在维度为30 上的实验数据,表5 给出了五种算法在维度为100 时的实验数据,在表中,加粗的部分表示同一函数上的平均适应度最优解和方差最优解。图2 是各个算法随机选取一次实验的收敛曲线,表现各算法在各函数中的收敛情况,由于篇幅有限,在这里仅选取部分具有代表性的函数的收敛曲线。
4.3.1 求解精度
从表4中的实验数据中可以看出,HGPSO算法在单峰函数和复合函数中的收敛效果和求解精度明显优于四种对比算法,在部分简单多峰函数中好于其他优化算法。其中,HGPSO算法在单峰函数f 1 上的相比于其他算法而言,取得了一定的优化效果,且取得了较高的稳定性和收敛精度;在简单多峰函数f 5、f 7 和f 8 上其收敛情况明显优于对比算法,在f 6 上其收敛效果与CPPSO 算法差距较小,但其稳定性明显优于CPPSO 算法,而基本PSO 算法在此类函数上陷入了局部最优;针对混合函数,HGPSO算法的收敛情况较差,而HPSO算法的收敛精度及稳定性明显优于其他四种算法;对于复杂函数,HGPSO算法在函数f 21、f 22、f 23、f 24、f 26、f 28 和f 29 上的优化效果明显优于对比算法,且其稳定性较高。
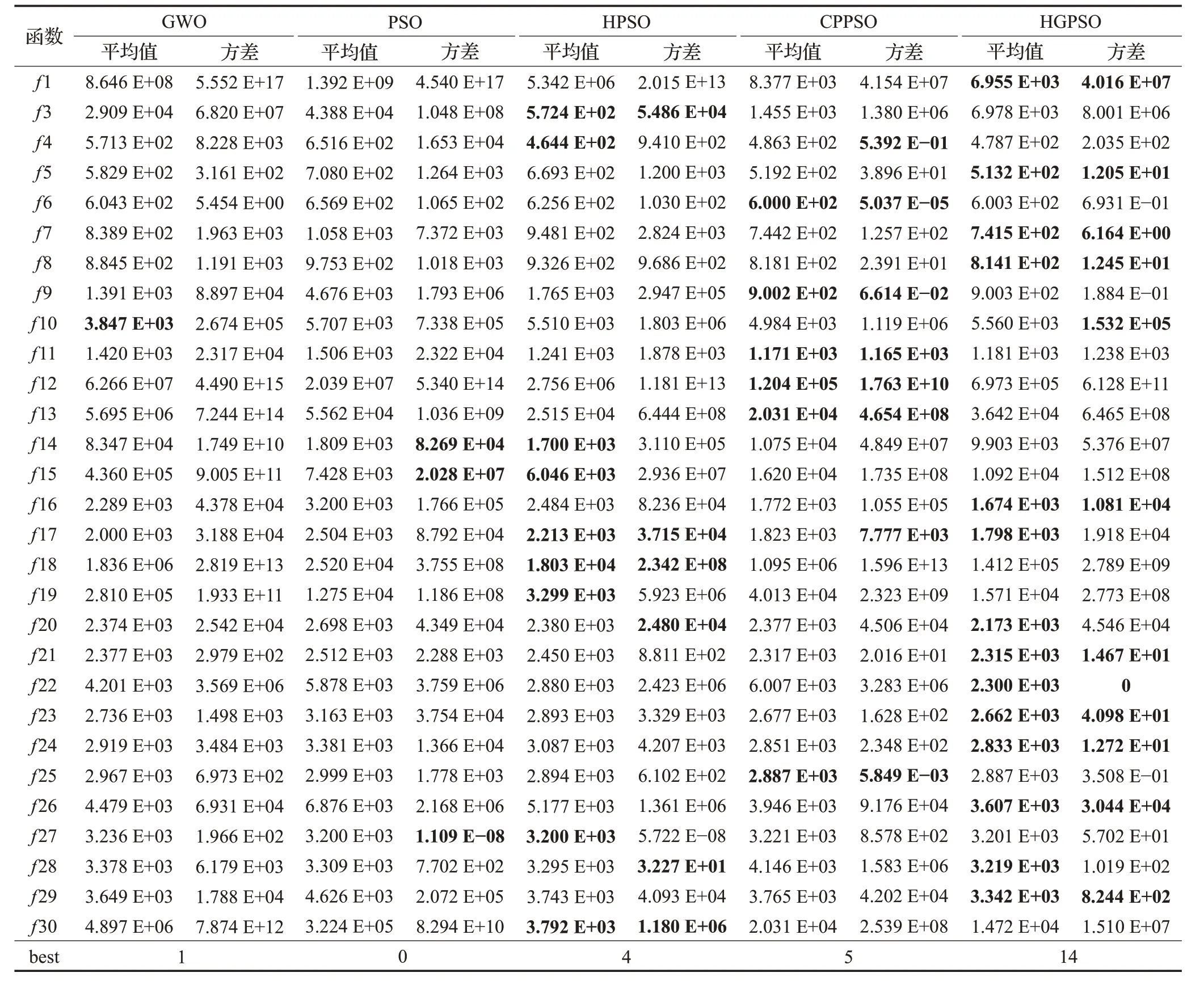
表4 算法在29个CEC_2017函数上的平均值(D=30)
从表5的实验数据中可以看出,HGPSO算法在简单多峰函数f 5 和f 9 上的收敛精度和稳定性明显优于其对比算法,且在f 7 和f 8 上的收敛精度较高,稳定性较好;对于混合函数,HGPSO 算法的收敛性能较好,但其稳定性较差,其中在函数f 15、f 16、f 17、f 19 上的收敛性能明显好于其对比算法;在复杂函数f 21、f 22、f 23、f 24、f 29 和f 30 中,算法的稳定性较好,且其收敛情况相比于其他算法有显著提高。
从表4和表5中可以看出,HGPSO算法在各函数上均有一定程度的提高,其在简单多峰函数和复杂函数上的收敛情况对比于其他优化算法有显著的优势。
4.3.2 收敛过程
为了直观地观察算法在各测试函数上的收敛情况,各算法在各函数上的收敛过程如图2 所示。但由于篇幅有限,在此仅随机选取具有代表性的函数实验图进行分析。
图2(a)~(c)展示的是五种算法在低维情况下的收敛过程。其中,函数f 5 是简单多峰函数,从图中可以看出HGPSO 算法不仅比其他算法的收敛性更好,在后期其搜索性能更优,因而取得了精度更高的值;函数f 16是混合函数,从图中可以看出其收敛效果较其他算法更好,且其精度更高;函数f 23 是复杂函数,从图中可以看出在函数f 23 中收敛精度与其他算法相当但其的收敛
速度更快。综合来看,在低维情况下,HGPSO算法在简单多峰函数和混合函数中具有更好的收敛情况和更高的求解精度。
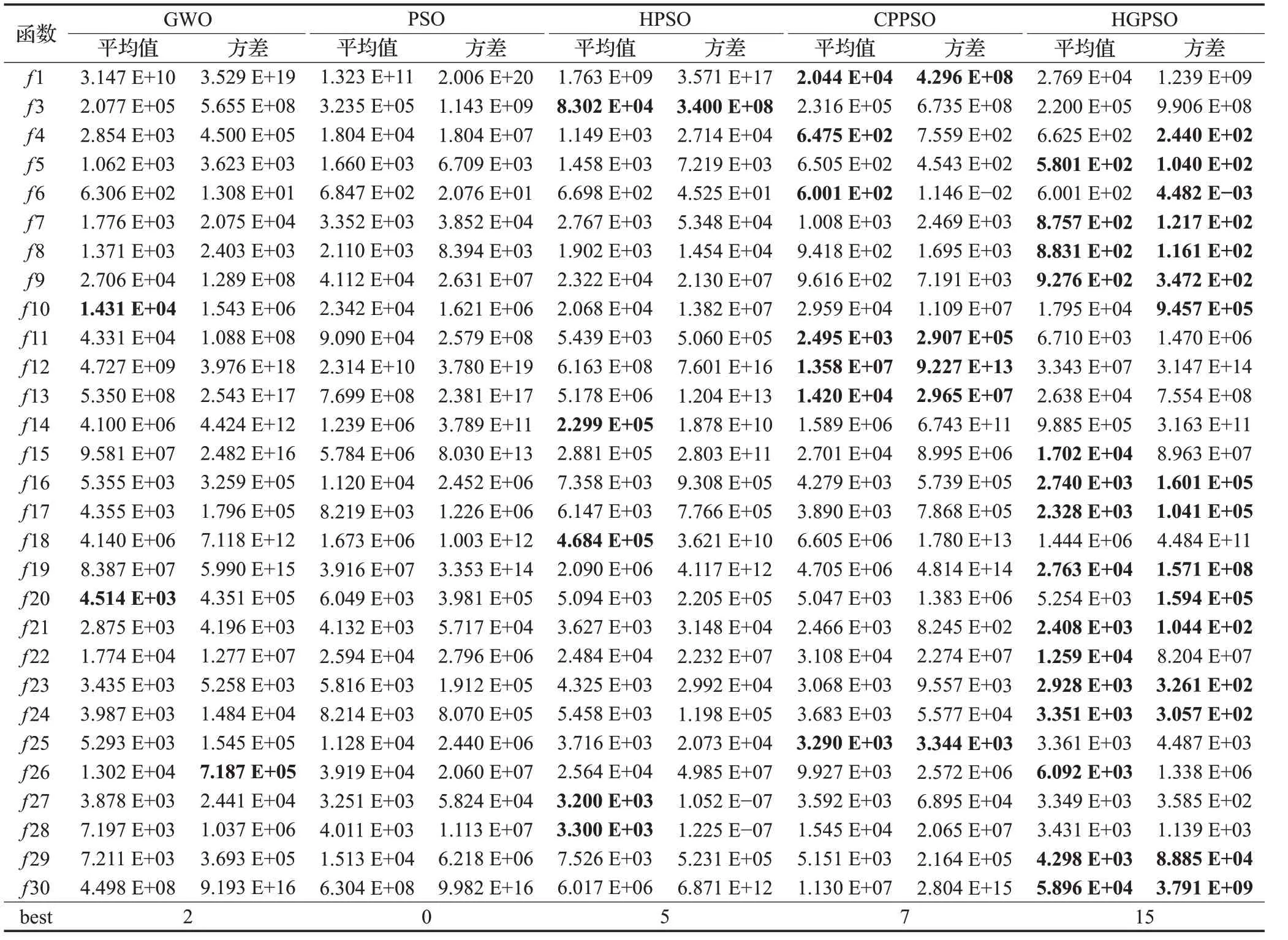
表5 算法在29个CEC_2017函数上的平均值及方差(D=100)
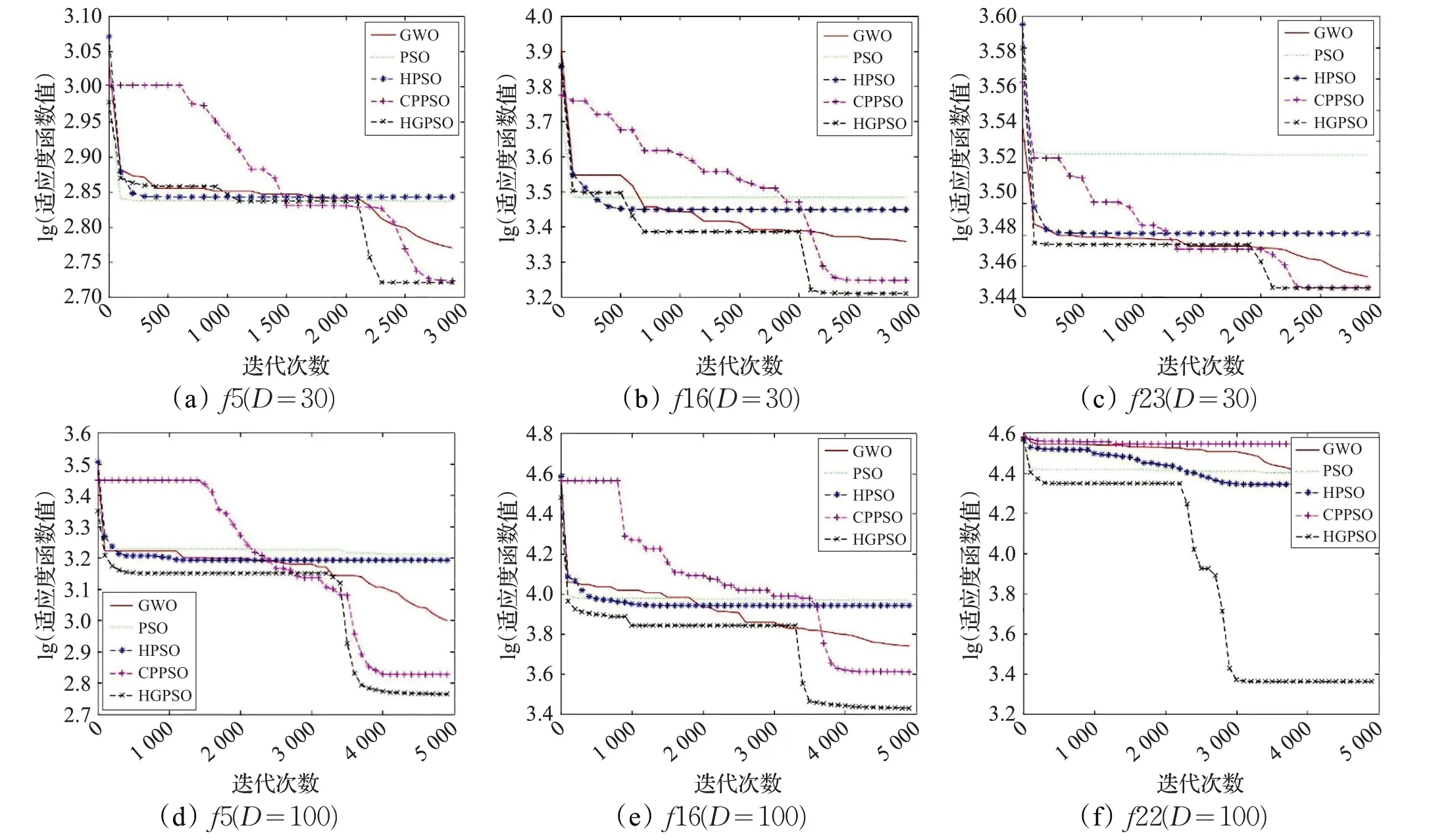
图2 几种算法在六个函数中的收敛曲线
图2(d)~(f)展示的是六种算法在高维情况下的收敛过程。其中,函数f 5 是简单多峰函数,从图中可以看出前期HGPSO 算法的收敛速度较快,且其在后期其搜索性能更优,因而取得了精度更高的值;函数f 16 是混合函数,从图中可以看出再迭代前期其收敛效果与其他算法相当,但在迭代后期收敛效果较强,即其精度更高;复杂函数f 22 的收敛效果较其他函数更优,且其收敛精度较高。综合来看,HGPSO 算法在低维和高维函的情况下,在简单多峰函数和混合函数中具有更好的收敛情况和更高的求解精度。
为了体现GWO 在本文提出的算法中的搜索性能,通过跟踪全局最优解在算法收敛过程中的位置更新变化过程,体现其收敛性能。在此,选择测试函数f 5 进行实验,全局最优解xbest 的位置更新过程如图3所示。为了更好地表现出其位置更新过程,在此设置维度为2。实验结果表明,当迭代次数为300 时已经取到最优解,即在此设置最大迭代次数为300,其他参数与4.2节设置的参数一致。
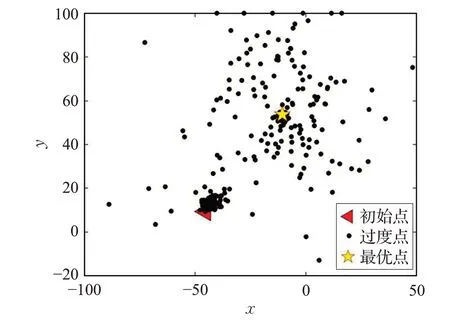
图3 最优解的位置更新变化过程(f5)
从图3中的位置分布可以看出,在最优解附近的密度较高,即其局部搜索能力较强,所以其算法的求解精度较高。
4.3.3 算法复杂度分析
根据基本PSO算法的执行流程可以看出,算法的时间度主要分为粒子的初始化部分和速度和位置更新部分,其时间复杂度为O(N×D)。从HGPSO 算法的流程描述中可看出,HGPSO算法主要包括:(1)初始化部分,初始化种群大小N、种群维度D、速度、位置、计算适应度值,该部分的时间复杂度都为O(N×D);(2)迭代部分,随机最优交叉反向学习的时间复杂度为O(N),一般反向学习和随机交叉反向学习的时间复杂度均为O(N×D),改进的灰狼优化算法的时间复杂度为O(N×D),即迭代部分的时间复杂度为O(Miter(N×D))。因此,HGPSO时间复杂度为O(N×D)+O(Miter(N×D))。通过对比可以看出,相比于基本PSO算法,HGPSO算法的复杂度较高,但是其求解精度和稳定性相比于其基本PSO算法要更好。
5 结语
本文针对PSO存在的易陷入局部最优、求解精度较低等问题,提出一种基于灰狼优化的反向学习粒子群算法,首先通过将反向学习策略增加粒子的多样性,扩大其搜索空间,避免其陷入局部最优;同时采用改进的灰狼优化算法的粒子群算法,提高算法的局部搜索性能和收敛精度。利用两种不同的搜索策略,平衡算法的搜索性能并提高其收敛精度。通过仿真实验表明,本文改进的算法在简单多峰函数和复杂函数中,具有较快的收敛速度和较高的寻优精度。根据这两类函数具有一个全局最优解和多个局部最优解的特点,本文采用全局搜索能力较强的反向学习搜索和局部搜索性能较强的灰狼搜索方式,合理利用所有粒子信息,平衡全局和局部搜索能力,避免其陷入局部最优,提高求解精度。未来的研究将进一步提升其搜索性能,并将其用于实际应用的优化。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
中学生数理化·八年级物理人教版(2022年3期)2022-03-16
小学阅读指南·低年级版(2021年3期)2021-03-19
小太阳画报(2019年1期)2019-06-11
数学大王·低年级(2018年5期)2018-11-01
金桥(2018年4期)2018-09-26
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
快乐作文·低年级(2017年3期)2017-03-25
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
