
一种高效的CABAC熵编码硬件设计
2020-04-07 06:11郑明魁陈志峰施隆照
福州大学学报(自然科学版) 2020年2期
傅 晨,郑明魁,陈志峰,施隆照,王 炎
(福州大学物理与信息工程学院,福建 福州 350108)
0 引言
视频信息是人与人之间联系的重要媒介,数字电视、视频监控、行车记录等各种视频系统成为现代各个行业和信息化建设领域的重点.视频编码联合组[1](joint collaborative team on video coding,JCT-VC)于2010年提出了新一代高效率视频编码标准H.265/HEVC,并在2013年正式成为国际标准.与前一代视频编码标准H.264/AVC相比,使用诸如四叉树的CTU划分[2]和更高效的熵编码[3]等新技术,HEVC在相同视频质量下可节省约50%的视频码流,但是其复杂度也成倍增加[4],这严重阻碍了其在各个领域的快速应用.并且HEVC熵编码模块只保留了复杂度较高且编码过程具有前后数据依赖关系的CABAC作为唯一的编码方式,同时还要求CABAC处理更多且更为复杂的语法元素及残差数据,这给CABAC的硬件实现提出了更高的要求[5-6].
近年来涌现出许多对优化熵编码硬件的研究: 文[7-9]提出流水线CABAC编码器架构和降低资源消耗、提高吞吐率的方案;文[10]提出多路并行方式的CABAC架构设计;文[11-13]从算法层面上提出一些方案用以优化编解码器架构,提高编码效率.但是对于流水线的CABAC编码器架构,上述文献并没有解释如何应对一些难以连续流水线作业的特殊情况,例如处理连续相同上下文模型的语法元素时,因为上下文需要更新而造成的难以完全流水这种情况.一些文献虽然提出了如何提高熵编码模块的编码效率,但是对于输入输出部分还可以进一步优化.对于CABAC的并行化架构,虽然可显著提高吞吐率,但是相应的硬件资源消耗也会变大.
通过优化架构,CABAC编码器在吞吐率方面有很大的进步,但是以往的研究存在难以实现完全流水或者硬件资源消耗较大的问题,并且熵编码部分与其他模块的接口数据格式还可以进一步优化.本设计从熵编码硬件实现出发,对硬件面积、主频和编码器吞吐率方面展开研究,在输入输出方式和算术编码的流水线实现进行优化,以此提高整体编码效率和吞吐率、降低硬件资源消耗.
1 HEVC与熵编码原理
H.265/HEVC作为新一代视频编码标准,整体编码框架与H.264/AVC类似,通过帧内帧间预测去除视频图像内的空域和时域冗余;采用变换量化将空间域的图像变换到频域,得到相关性较小的变换系数;使用滤波器提高压缩率,减小码流;最后经过熵编码将视频序列中的元素符号进行无损压缩得到最终码流.熵编码作为视频压缩系统的最后一步,基于统计属性将数据压缩到接近其熵的大小,是保证视频压缩效率的重要工具.

图1 CABAC编码器框架结构图Fig.1 CABAC encoder structure diagram
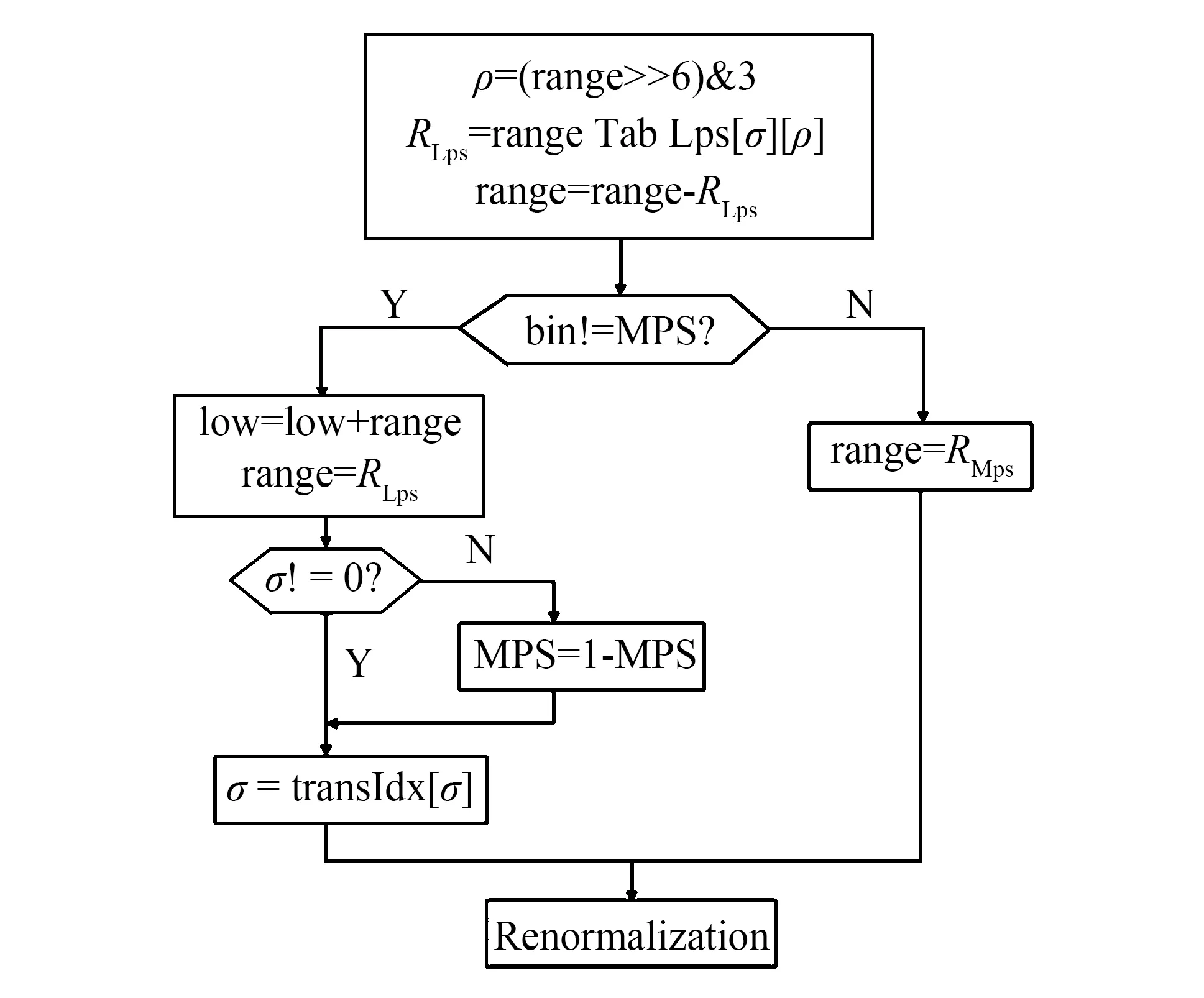
图2 常规编码流程图Fig.2 Flowchart of regular coding mode
熵编码模块的基本框架结构如图1所示,包括三个基础步骤,分别是二值化、上下文建模和二进制算术编码.其中二值化是将给定的非二进制语法元素例如残差系数和运动矢量等映射为一串二进制符号(bin)序列,使用的方法包括定长二值化(Fixed-Length,FL)、截断一元码(Truncated Unary,TU)、截断莱斯二值化(Truncated Rice,TR)和K阶指数哥伦布二值化(Exp-Golomb,EGK)等.通过先前编码的语法元素或Bin来估计当前Bin的概率,这个步骤称为上下文建模,通过动态更新一个存储着按类划分概率值的上下文表来实现.为降低复杂度,概率值是通过一组0~63的离散状态值表示的,同时还有一个指示位指定大概率符号(most probable symbol,MPS)是0还是1,和MPS相反的即是小概率符号(least probable symbol,LPS).二进制算术编码这一步骤将bin组成的序列转换为最终的码流.其算法包括常规编码和旁路编码两种方式,且都是基于递归区间划分的方式,在递归过程中保存编码区间(range)和区间下限(low).其中常规编码方式是利用自适应的概率模型进行编码,较为复杂且使用较多,需要不断的通过读写概率状态表(transIdx)更新概率状态;旁路编码则是使用等概率的方式进行算术编码,概率状态无需更新[14].
常规编码的流程图如图2所示.为降低复杂度,在传统的算术编码基础上引入查表代替运算中概率更新的乘法,即根据当前的概率状态索引σ和range的量化值ρ,通过查表得到LPS对应的子区间RLps,通过range减去RLps得到当前MPS的子区间RMps.若当前二进制符号是MPS则将RMps作为下一个二元符号的编码区间range,区间下限low不变;若当前的符号为LPS,则LPS的区间RLps作为下一个二元符号的编码区间range,区间下限L要增加RMps.更新low和range的同时,由σ和MPS组成的上下文模型也会相应更新.经过区间划分后得到的新的编码区间长度可能不在[28,29]之内,则需要重归一化过程将码流输出,同时更新range直至不小于28,low也做相对应的移位.
2 CABAC硬件框架与输入模块优化
2.1 CABAC整体硬件结构设计
如上节所述,熵编码的数据处理主要分成二值化、上下文建模和二进制算术编码三个部分,且每个部分数据处理的工作较为独立.由于每部分对数据的处理方式不同,交互的数据需要一个合理且高效的格式,并且各个部分内部也需要进行优化,达到一个整体高兼容且高吞吐率的效果.所以本设计使用了四路循环缓存输入、二值化PISO(parallel in serial out)输出、多路并行二值化架构、上下文模型初始化的ROM数据读取和模型RAM更新、算术编码PISO输出等方式来提高整体架构的容错和吞吐率.
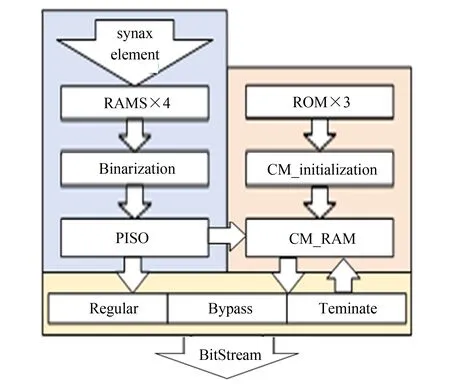
图3 CABAC硬件结构示意图Fig.3 Architecture schematic diagram of CABAC
根据HEVC的参考软件HM16.7的算法,提出熵编码模块硬件架构如图3所示.该架构主要分为3个部分: 数据输入及二值化部分、上下文建模部分和算术编码及码流输出部分.本模块的输入数据由视频编码的率失真优化模块和重构模块通过RAMS传输,输入的数据通过二值化模块变成需要编码的Bin,并且同时将编码类型、上下文模型索引等数据一并传入PISO中,通过PISO传入算术编码模块.上下文模型通过初始化模块写入双端口RAM中,并在编码时不断地对RAM中的概率模型进行更新.算术编码模块同时包含了常规编码,旁路编码和终止编码,编码完成后的码流通过PISO模块进行缓冲后最终输出.
通过使用RAMS存放熵编码模块与其他模块之间的交互数据,可以有效地将各模块分开并独立运行,并且因为输入数据是由不同模块写入的,可以实现各部分并行处理,降低整体架构的时延.因为输入数据可以并行读取,所以二值化模块可以适当并行处理语法元素,进一步降低时延,处理好的数据会按顺序放入PISO模块之中,可以有效减少熵编码时钟周期数,再通过1个clk输出一个Bin的模式将数据传输到流水作业的算术编码模块.因为码流是按照字节输出的,并且在输出码流时会由于进位的问题造成1个clk输出多字节数据,所以可以通过一个简易的并入串出模块来高效输出码流,实现整个算术编码模块的完全流水.
2.2 熵编码四路循环缓存输入及高效残差系数传输

图4 四路循环缓存输入Fig.4 Quad loop buffer input
在视频编码中,熵编码模块的前置模块数据处理速度和本模块的数据处理速度会有不同,并且由于熵编码模块难以并行,在整个视频编码是流水作业的条件下,为了不让编码过程拥堵在熵编码模块导致整个编码器的停滞,同时为降低编码器的时延,采用了如图4所示的数据输入结构,通过四路的RAMS将需要熵编码的数据进行循环缓存,每路RAMS保存一个CTU(coding tree unit)的全部数据,这样可以有效降低视频编码各模块之间的依赖性.其中输入数据存储的RAMS,包括Depth_RAM(包含CU深度、TU深度及PU模式等信息)、Intra_PU_RAM(包含亮度、色度方向)、Inter_PU_RAM(包含merge和amvp的相关信息)、Neighbor_RAM(包含当前CTU上侧和左侧CTU的相关信息)和Residues_RAM(包含残差数据)等.

图5 CABAC残差数据存储示意图Fig.5 CABAC residual data storage diagram
编码数据中最繁琐的是残差数据,因为不仅数据总量大,而且传输形式既需要考虑变换量化模块的系数输出方式,又要考虑熵编码模块的数据使用方式.对于变换量化模块,残差系数都是通过矩阵变换得到的,其系数多为通过行或列的方式进行输出,熵编码模块处理残差数据时,以CG块(4×4大小的残差块)为最小单元进行编码,所以设计了如图5所示的残差数据存储方式,可以很好地解决这个问题.将一个CTU(64×64)块的残差数据进行拆分后放入16个RAM中,其中每个地址存放4个残差系数,因为每个残差系数16位,所以RAM的存储宽度为64位,存储深度为8位.这样对于变换模块可以很方便地按行存储,同时熵编码模块可以4个周期读取数个CG的残差系数,提高效率.
2.3 多路并行二值化架构

图6 二值化结构框架Fig.6 Architecture of the binarization
输入的语法元素及残差数据通过部分并行架构进行二值化[15],根据对应数据类型得到bin字符串和其上下文模型索引.在HEVC中大多语法元素使用的二值化方案为截断一元码(TU)、截断莱斯码(TR)、K阶指数哥伦布编码(EGK)和定长码(FL).其余的语法元素使用各自对应的自定义二值化方案(Custom).因为二值化是各个语法元素分别做各自的,并且不是整个架构的瓶颈,原则上只需要这部分的平均处理能力在任何情况下都高于算术编码部分,即可满足整个架构的流畅高效.
为满足上述目标,本设计采用两级二值化方案,如图6所示.每一个Level支持4种二值化方案,并且与自定义二值化方案(Custom)三者相互独立,所以在一个周期内最多可输入3个语法元素.并且二值化后的每个数据都包含当前bin的数据、编码类型和上下文模型索引,一同输入到PISO模块中,同时PISO模块将数据按顺序,以每周期1个bin的频率,传入算术编码模块和上下文模型模块,实现整个熵编码模块的流水作业.
2.4 上下文模型初始化的ROM读取和模型RAM更新

图7 上下文建模框架Fig.7 Architecture of the context modeling
因为语法元素对应的上下文模型初始值并不是固定的,所以在开始熵编码之前需要根据QP值、Slice类型等参数计算出需要的语法元素的概率模型,以适配不同情况下语法元素概率之间的差异.设计了如图7所示的架构,更多利用memory资源,可以有效减小逻辑资源的消耗.上下文模型初始化首先需要给每一个上下文模型分配一个固定的初始值用于计算概率,于是将三种类型: I帧(134个初始值)、B帧(154个初始值)、P帧(154个初始值)中的各个语法元素初始值存放于对应的ROM中,再通过初始化模块读取计算得到最终上下文模型,并写入双端口CM_RAM(8位深度,7位宽度)中.最终所有的初始模型都存放在CM_RAM中,然后由后续的算术编码模块不断地对此RAM中的概率模型进行取值和更新.
3 算术编码模块优化
3.1 算术编码模块实现的瓶颈
算术编码的特点之一就是每次编码的bin都需要根据先前编码的概率区间值以及当前的大概率符号(MPS)来确定,这就导致了编码的数据之间存在着严格的前后依赖性,使硬件实现的编码效率很难提高.虽然编码的算法涉及很多的乘法运算,但大多都将计算过程简化成查表,而且如前所述,上下文模型更新、range的计算、low的计算和归一化过程都是层级进行的,这就给整个编码过程提供了流水线运算的可行性.但当面临一些特殊情况时就难以实现流水运算,例如对相同上下文模型的语法元素进行连续的算术编码时,由于更新上下文模型需要1个clk,并且RAM数据的读写也都会占用1个clk,导致后一个语法元素无法在相邻时钟周期从CM_RAM中读取到还未写入更新后的上下文模型;又如在码流输出阶段,由于进位的原因导致可能1个clk需要输出多byte的码流,而稳定的码流输出是1byte/clk.对于整个编码过程的流水实现,以及应对这些难以流水实现的特殊情况,本设计可以实现完全流水并且实现低资源和高主频的特性.
3.2 设计优化
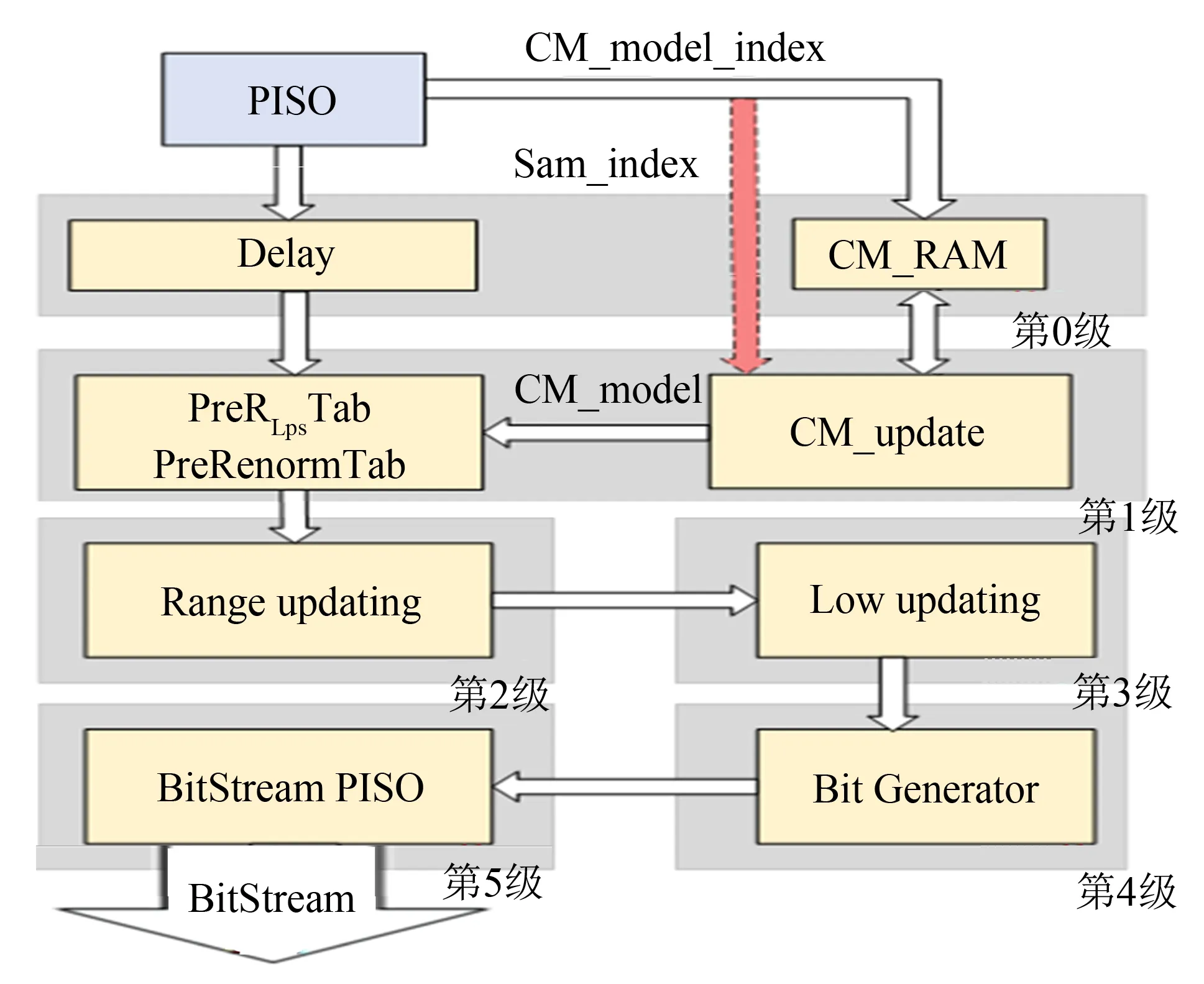
图8 常规编码硬件架构Fig.8 Hardware architecture of regular coding modemodeling
本设计是在前人的基础上通过预取上下文模型索引、预归一化及码流并入串出模块进行优化,以提高主频和吞吐率,降低资源消耗.整个算术编码模块被设计成如图8所示的六级流水线模式,这样的流水线划分方式可以有效地将关键路径延迟降低,并且由于上下文模型的更新操作是整个算术编码bin与bin之间强依赖关系的瓶颈,本设计可以有效地将这种依赖关系减缓到实现完全流水,代价只是在流水线上增加了1个clk和一些逻辑资源.码流输出模块也进行了设计和优化,用以实现整个模块的完全流水与稳定的码流输出.
流水线的第0级实现的是数据的准备工作,上下文模型索引、bin值以及编码类型的数据都是通过PISO模块最多每周期1组得到的,首先将上下文模型索引(CM_model_index)输入给CM_RAM得到上下文概率模型,然后将模型及bin值、编码类型等数据同时传入流水线的第1级,使流水线下一级可以同时得到所有需要的数据.
第1级流水线则是同时做2个工作: 1) range和归一化的预查表.对于range的更新需要2个步骤,首先是根据当前的range高两位和上下文模型中的σ查表得到RLps,然后通过计算得到新的range,对于归一化则是要根据RLps得到归一化参数,于是本设计提出只在第1级流水线上通过上下文模型的σ进行range及归一化的同时预查表,这样可以有效地将查表过程和计算过程分开,降低关键路径延迟,提高系统主频;2) 上下文模型的更新.根据上下文模型和输入bin值是否为MPS这两个条件,在概率状态表中查找出更新后的上下文模型,同时将其再存储到CM_RAM中实现更新.如果连续的多个时钟周期使用同一个上下文模型,由于RAM的读写都需要消耗1个时钟周期,后置的上下文模型无法在相邻时钟周期读取到前置更新后写入的数据,也就无法实现完全流水,于是提出预读取上下文模型索引的方法来解决这个特殊情况,提高吞吐率.实现方法就是将CM_model_index在每次传输时进行缓存,在当前周期输入给CM_RAM的CM_model_index与上一周期传输的值相同时,则通过Sam_index信号直接传给流水线的第1级,上下文模型直接通过内部的CM_update模块获取上一时钟周期更新后的模型,不再通过CM_RAM获取,去除模型在RAM中的读写时间消耗,只通过少量的资源消耗和流水线多1个clk就可以实现整个模块对于所有输入数据情况的完全流水.
接下来分别在流水线的第2级和第3级更新Range和Low,这是为了把计算过程分开,将关键路径延迟降低.当Low更新结束后则需要进行归一化处理,就是将Low更新后溢出的数据形成码流,由于溢出比特中可能包含进位,为了保证进位不丢失,在比特生成阶段缓存有可能进位的数据,于是设计了第4级的流水线比特生成模块.本模块可以将Low的溢出数据进行缓存整合,因为如果存在进位,则有可能在同1个周期输出多字节的码流,于是当确定是否进位后将可以将输出的码流按照字节的形式同时输出到BitStream PISO中,再通过简易的PISO模块使最终输出的码流在特殊情况下也可以是1周期输出1字节,让整个流水线可以适应所有的情况.
4 测试与仿真
本研究提出的CABAC架构设计已通过VerilogRTL实现,并且基于官方参考软件HM16.7进行功能验证.首先将HM16.7执行中的熵编码模块的输入输出数据打印出来,然后将输入数据传至本设计,最后对比输出数据是否一致即可验证模块功能是否正确.经过包含不同分辨率、不同QP的多个视频序列测试,本设计的电路功能正确.本设计架构包含了熵编码的所有模块,提出的四路循环缓存输入、上下文模型索引预读取、预归一化查表和并入串出码流输出模块可以在少量资源增加的情况下实现完全流水,提高平均吞吐率.
采用SMIC 90 nm工艺,在Synopsys Design Compiler下综合,综合结果为总逻辑门数43.49 K,最高工作频率370 MHz,最大吞吐率370 Mbin·s-1.该结果与其他同类型文献进行比对的结果如表1所示.

表1 仿真结果
注: *该值为二值化模块和上下文建模模块的逻辑门数之和.
文[7]也对整体熵编码过程进行了流水实现,为提高视频编码器的编码效率,本设计采用四路循环缓存输入方式及多路并行二值化方案,导致二值化和上下文建模模块的总电路门数多了约11.48%,但本设计对算术编码模块进行了大量优化,使整体门数小于对应文献,并且实现了更为高效的熵编码模块.文[9]的吞吐率会根据输入数据的不同而产生变化,有可能导致无法实现完全流水,而本设计可以应对所有输入情况,实现真正意义上的流水线,在总体门数上也节约了11.14%.文[10]针对熵编码的算术编码部分进行优化并实现了高吞吐率的多路并行架构,但是其代价是消耗了更多的硬件资源,相较于本设计其电路门数增加了约47.39%.
本设计严格按照HEVC编码标准进行设计及测试,因熵编码为无损压缩,所以对于编码器性能不会造成损失,相比于其他论文的设计,其可以实现完全流水线,并且有着较高主频,较低资源消耗的优势.并且在此基础上通过FPGA开发板进行了上板测试,已通过整个视频编码器的联调,可以实现1080 P视频数据30帧·s-1的实时编解码.
5 结语
由于视频编码标准HEVC复杂度的提高,熵编码过程的硬件实现也成为高清视频实时编码的瓶颈之一.为实现熵编码过程的高吞吐率,提出一种高效率流水线架构的HEVC CABAC编码器.本编码器不仅包含二值化、上下文建模和算术编码模块的实现,还通过四路循环缓存输入和码流并入串出结构提高编码器的效率,使用上下文模型初始化的ROM读取和模型RAM更新降低逻辑资源使用,通过预读取上下文模型索引、预归一化和六级流水线方案实现编码器的完全流水并提高主频.整个编码器采用SMIC 90 nm标准单元库进行综合,其包括内存在内的总电路门数为43.49×103,最高频率为370 MHz,最大编码吞吐率为370 Mbin·s-1.并且经过和其他模块联合测试,本设计可以在200 MHz以上时钟频率实现1 080 P视频30帧·s-1的实时编解码.
猜你喜欢
传感器世界(2022年4期)2022-08-05
传感器世界(2022年3期)2022-05-24
数字技术与应用(2021年1期)2021-03-24
——编码器
演艺科技(2020年7期)2020-08-13
当代工人(2020年4期)2020-05-11
儿童故事画报(2019年8期)2019-08-14
作文通讯·初中版(2017年11期)2018-03-31
小天使·二年级语数英综合(2017年9期)2017-10-20
永善文学(2017年1期)2017-07-18
中国信息技术教育(2017年11期)2017-07-01
