
基于多智体强化学习的接入网络切片动态切换
2020-04-06 08:47赵冠群
电子科技大学学报 2020年2期
秦 爽,赵冠群,冯 钢
(电子科技大学通信抗干扰技术国家级重点实验室 成都 611731)
以5G 为代表的未来移动通信系统,将广泛采用SDN 和NFV 技术,通过构建软件定义的移动通信网络,为用户提供灵活按需的网络传输服务[1-2]。在软件定义的移动通信网络架构下,将采用网络切片技术,来满足多样化业务的差异化服务需求,也越来越成为研究者的共识[2-4]。每个端到端网络切片服务于网络中某一类具有特定需求的业务,在逻辑功能层面对应相互独立的端到端虚拟网络,多个切片对应的不同逻辑虚拟网络,将通过映射部署到相同的物理网络之上。
当移动用户到达网络时,需要选择一个满足自身业务服务需求的切片接入网络。在实际的网络中,网络条件和用户业务需求动态变化,使得用户到不同接入站点的信道条件以及不同切片中的可用资源情况不断变化。因此,为了保证用户的接入和传输性能,需要根据用户的接入信道条件和可用资源情况,进行用户接入切片的动态切换。在传统的移动通信网络中,用户的接入切换只需要考虑从一个接入站点切换到另一个接入站点。而在基于切片的软件定义移动通信网络中,一个接入站点上往往部署了多个不同的网络切片,而同一切片可能覆盖多个不同的接入站点。由此,用户与接入站点二者之间的接入选择和切换问题,就变成了用户、切片和接入站点三者之间的优化匹配问题。
在移动通信网络中,用户的接入切换一直是研究热点[5-8]。但现有的研究主要关注传统移动通信网络中的用户切换问题,而对于如何在基于切片的软件定义移动通信网络中,进行用户接入切片的动态优化切换,保障用户业务的服务性能,还少有涉及。同时,在实际的通信系统中,切片的可用传输资源有限,接入同一切片的多个用户将竞争有限的传输资源。某一用户的接入选择,会改变接入切片中可用传输资源数量,进而对其他用户的接入和传输性能产生影响。因此,需要综合考虑网络中多个用户的接入决策之间的相互制约和影响关系,从提升多个用户整体传输性能的角度,设计多用户协同的接入切片动态切换机制。
本文重点关注了基于网络切片的软件定义移动网络中,移动用户接入切片的动态优化选择和切换问题。首先,考虑到多个用户共存的网络中,不同用户的接入选择将相互影响相互制约,结合移动通信应用场景下,动态的网络条件和业务需求对用户接入决策的影响,将网络中多个用户的接入切换建模为一个多人随机博弈问题。然后,通过多智体强化 学 习(multi-agent reinforcement learning, MARL)方法[9-11]对该问题进行求解,并提出了一种基于分布式多智体强化学习[12]的多用户接入切换算法。在此基础上,通过仿真实验,验证本文提出算法的性能。
1 系统模型
本文考虑的网络模型如图1 所示,M 个基站组成的移动网络中部署了N 个网络切片。多个切片部署在相同的物理网络之上,共享相同的物理传输资源,包括接入网的无线传输带宽和功率,以及核心网的传输带宽。一个切片可能覆盖多个基站,一个基站上也可能部署多个不同的切片,基站的无线传输资源将根据需求被分配给各个切片。在接入网,多个不同的基站之间可以通过Xn 接口相互连接,各个基站通过NG 接口连接到核心网中的AMF(access and mobility management Function)。AMF 负责切片的部署和管理,一个AMF 可以同时管理多个切片。AMF 通过与SDN 控制器的信息交互,可以获得切片在核心网中可用的传输资源情况,并通过NG 接口告知部署了该切片的各个基站。而一个用户可能处于多个接入站点的覆盖范围内,由此通过基站的广播信息,可以获得不同基站上可接入的切片状态信息,并从中选择合适的切片接入。为了便于分析,本文假设一个用户只产生一条业务流,用户和业务是一一对应关系。
当一个用户接入某一切片,其获得的服务速率,同时受切片在接入网和核心网中可用传输资源的限制。如果用户通过基站m 上的切片n 接入网络,则其在接入端获得的无线接入速率 rm,n将由用户到基站m 的信道条件,以及此时切片n 在站点m 上可用的无线传输带宽和传输功率共同决定。而用户在核心网能够获得传输速率 cn,则由切片n 在核心网部分的容量以及业务负载共同决定。因此,用户接入网络后可以获得的端到端服务速率bm,n=min(rm,n,cn)。由于如何进行切片传输资源的优化配置并非本文的关注重点,为了便于分析,本文简单假设切片覆盖范围内的用户信道条件相近,且切片可用的接入网和核心网传输资源平均分配给接入切片的多个用户。因此,用表示站点m 上的切片n 能够提供的总的最大传输速率,则当有K 个用户同时通过站点m 上的切片n 接入网络时,某一用户k 获得服务速率
由于基站m 通过与AMF 的交互,可以获得切片n 核心网部分的容量和负载。结合切片n 在基站m 获得的无线传输资源数量,基站可以得出当前基站m 上的切片n 能够提供的最大传输速率同时,根据当前接入用户数量,基站就可以计算出当前有新用户k 接入网络时能够提供的服务速率并且可以通过基站广播,把这一信息提供给用户。
2 问题建模
2.1 多用户切换策略
网络用户的移动及业务需求的变化,使得各个切片中服务的业务流不断到达和离开。由于每个切片在接入端和核心网可用的传输资源有限,切片负载的变化使得接入用户获得的服务速率动态变化。由此,考虑网络中的用户每隔一段时间,将根据当前网络状态的变化,判断是否需要进行接入切片的切换,以获得更高的服务速率。
用户在进行接入切换时,会带来相应的信令传输、处理时延等切换开销,频繁的切换可能导致过大的切换开销,从而降低用户体验和网络服务性能。因此,本文的设计目标是希望在通过用户接入切片的优化切换来提升用户服务速率的同时,尽量减少由此带来的切换开销。
2.2 多用户随机博弈模型
在实际网络中,往往多个用户同时处于多个切片的覆盖范围内,每个切片可用的传输资源有限,一个用户的接入选择,将对其他用户的可用传输资源和接入决策产生影响。因此,本文将动态网络条件下,多用户的周期性接入选择和切换决策过程建模为一个多用户随机博弈问题。
多用户随机博弈可以看作一个包含多个决策者的马尔科夫决策过程,并用元组(S,A1,A2,···,AK,r1,r2,···,rK,p)表 示,其中S 为系统状态空间, Ak为决策者k 的动作空间, rk:S×A1×···AK→R为回报函数,p 为状态转移概率。本文考虑将每个用户看作一个决策者,在每个决策时刻,用户k 执行动作ak,并且获得收益 rk( s,a1,a2,···,aK)。用户所处的状态s 会根据转移概率跳转到下一状态s’。
因此,在本文考虑的多用户切换对应的多人随机博弈问题中,每个用户周期性地根据当前网络状态,以最大化自身的累积收益为目标,进行接入切片的切换决策。多用户随机博弈问题中各个组成元素可以表示为:
1) 系统状态:用 s ∈S表示网络状态,其中S 为所有状态的集合。设网络中存在N 个切片,M 个基站,则某一时刻用户k 所处的状态可表示为表示决策者k 当前通过基站m 接入切片n,反应了用户当前的连接状态。的含义如第1 节所述,表示当前时刻,用户k 如果接入基站m 上的切片n 可以获得的服务速率。在实际网络中,往往很多基站上只部署了部分切片,因此如果基站m 上没有部署切片n时,可以在状态向量中将对应的去掉,从而降低状态空间的大小。同时,可以将传输速率表示为单位速率的倍数,通过将传输速率的离散化来进一步简化状态空间,则有其中表示通过基站m 上的切片n 能提供的最大服务速率。周期,用户k 采取动作 ak=(m,n)表示用户k 选择通过基站m 接入切片n,其中 ak∈Ak,Ak={(m,n)|1}为用户k 的动作空间。
2) 动作:在本文所考虑的切换问题中,将用户的动作定义为用户对接入切片的选择。在每个决策
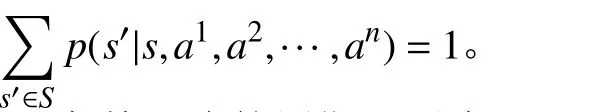
4) 回报函数:在某一决策周期,用户k 处于状态s 采取动作 ak后,获得的立即回报由两部分决定:一是用户采取动作后获得的服务速率;二是用户接入切片发生切换所带来的切换开销。
值得注意的是,本文考虑切片将可用传输资源平均分配给接入的多个用户,所以用户k 处于状态s 采取动作 ak后获得服务速率与系统跳转后的状态相关,受系统中其他用户的动作影响。因此用fk(s,a1,a2,···,aK)来表示在某一决策周期,处于状态s 的用户k 在所有用户采取联合动作(a1,a2,···,aK)后获得的服务速率。为了便于分析,假设用户获得单位服务速率的收益为1。同时,当用户k 采取动作 ak后,从状态 s= [Im,n,B1,1,···,Bm,n,···,BM,N]跳转到状态用户的接入切片可能发生变化,从而带来切换开销 gk( s,ak)。开销函数 gk( s,ak)定义为:
在多用户随机博弈过程中,用户之间的决策会相互影响。因此考虑每个用户都是以最大化系统的累积收益为目标进行切换策略的优化决策,从而将用户的立即回报函数定义为K 个用户的总收益,即:
在多人随机博弈问题中,如果所有决策者都具有相同的回报函数,则称为团队博弈。已有研究证明,在团队博弈中,存在全局最优均衡点[14]。本文采用多智体强化学习(MARL)方法来求解上述多人随机博弈问题。
3 模型求解与算法设计
3.1 MARL 方法
多人随机博弈可以看作一个多智体强化学习问题。在包含K 个智能体的MARL 中,设智能体k 的策略为 πk,则根据文献[12],其状态值函数可以表示为:
与传统强化学习相比,MARL 存在多个智能体,在求解对应的多用户随机博弈问题时,可以将传统的Q-Learning 方法[15]扩展到多智体系统。对于一个K 个智能体构成的多智体系统,对应的Q 函数可以表示为:
式中, α为探索率, (a1,a2,···,aK)和 (π1,π2,···,πK)分别为K 个智能体的联合动作和联合策略;rk(s,a1,a2,···,aK)为用户k 的立即回报,可由式(2)得到。
本文考虑的多用户切换问题中,在每个决策时刻,一但用户的联合动作 (a1,a2,···,aK)确定,则K 个用户的连接状态就确定了,由此可以确定系统的跳转状态 s′, 并得到 p(s′|s,a1,a2,···,aK)=1。则式(4)可以简化为:
由此,对应的多智体Q-Learning 算法中,Q函数的更新公式可表示为:
3.2 基于分布式多智体Q-Learning 的切换算法
在基于网络切片的软件定义移动通信网络中,(a1,a2,···,aK)相对应,这使得算法的状态空间和动作空间都较大,导致很高的算法复杂度。因此,本文考虑采用一种分布式的在线多智体Q-Learning算法,每个智能体只维护与自身动作相对应的Q 值函数,降低了算法的复杂度,同时算法运行过程中用户之间只需进行少量的信息交互。
本文设计的分布式Q-Learning 算法如下。在该算法中,每次迭代计算,智能体k 根据当前的网络s,独立 地 采取 ε− greedy策 略 选择自己 的 动作ak。由此,可以得到网络中的联合动作( a1,a2,···,aK)。利用SDN 控制器,可以方便地实现集中控制的多智体Q-learning 算法。由式(6)可以看到,集中控制算法中,Q 值函数与所有用户的联合动作执行动作后,智能体通过观察网络转移到的新状态s’计算得到的立即回报 rk( s,a1,a2,···,ak),并更新对应的动作值函数 Qk(s,ak)。
算法 1 基于分布式Q-learning 的动态切换决策算法
输入:S; A; r; α; γ;
1) 初始化 Qk(s,ak)=0, ∀ak∈Ak,k=1,2,···,K
2) Repeat
3) 获取当前s
4) if exploration then
5) 随机选择 ak∈Ak,k=1,2,···,K
6) if exploitation then
7) ak=argmaxaQk(s,a) ,k=1,2,···,K
8) for k=1,2···,K
9) 观 察 下 一 状 态s′,agent k 获 得 的 回 报 rk(s,a1,a2,···,aK)
11) s ←s′
12) end for
13) until(完成特定步数或所有 Qk(s,ak)都收敛)值得注意的是,分布式算法中,每个智能体只需要维护与自身动作相对应的动作值函数 Qk(s,ak),而不需要维护联合动作值函数 Q( s,a1,a2,···,aK)。但这并不表示在算法中,每个智能体完全独立地进行学习。由系统状态的定义可知,当智能体要判断当前所处状态时,需要获得网络切片当前可以提供的服务速率。这除了取决于智能体自身的接入选择决策外,也将受其他智能体接入选择策略的影响。此外,从算法第10)行可以看到,Q 函数的更新需要获得联合动作(a1,a2,···,aK)下的立即回报 rk( s,a1,a2,···,aK)。因此,为了计算立即回报,在此多智体系统中,智能体之间需要通过基站进行必要的信息交互。
3.3 算法复杂度
在本文的多用户随机博弈问题中,系统状态空间的大小为 |S|, 每个用户的动作空间大小为 |A|,设用户的数量为K。则可以得到,在对应的分布式Q-Learning 算法执行过程中,系统中所有智能体需要维护的Q 值表中状态-动作对的总数为 K· |S|·|A|。因此,在算法运行过程中,存储所有Q 值表所需要的存储空间复杂度和算法每次迭代运算的计算复杂度都是 K· |S|·|A|。
与本文中采用的分布式Q-learning 算法相比,传统的多智体算法中,动作值函数由所有智能体的联合动作决定,表示为 Q( s,a1,a2...,aK),则每个智能体对应Q 值表中的状态-动作对的个数就变为了|S|·|A|K。因此,系统中所有智能体需要维护的Q值表中状态-动作对的总数就是 K· |S|·|A|K。因此,传统的多智体Q-learning 算法运行过程中,空间复杂度和每次迭代的计算复杂度为 K· |S|·|A|K。相比于传统的多智体Q-learning 算法,算法1 采用的分布式多智体Q-learning 算法在计算复杂度和空间复杂度上都有明显的提升。
4 数值结果分析
在仿真实验中,考虑将设计的MARL 算法与多种传统算法性能进行对比,对比算法包括:
1) Fixed 算法:用户在到达网络后,固定选择一个切片接入,不进行切换;
2) RSS-based 算法:在每个决策时间点,用户总是选择RSS 最大的基站上的切片接入;
3) BW-based 算法:在每个决策时间点,用户总是选择能够提供最大服务速率的切片接入;
4) SAW (simple additive weighting method)算法:用户仅考虑自己采取的动作带来的收益,不考虑用户之间的相互影响。在每个决策时间点,选择收益最大的切片接入。
在图1 网络场景下进行仿真实验,仿真参数如表1 所示。假设每个基站覆盖范围内有业务不断动态到达或离开,业务的到达和离开服从泊松分布,对应的联合到达速率可以表示为 λ= (λ1,λ2,···,λM),其中 λm为基站m 上的用户到达速率,同理有µ=(µ1,µ2,···,µM)。本文中的数值结果为100 次随机仿真结果的平均值。

表1 仿真实验参数
图2 和图3 分别给出了系统中的累积回报和吞吐量随决策步数的变化关系。如图所示,在不同的算法下,系统累积回报和吞吐量的值都随着决策步数的增加而递增,其中本文提出的MARL 算法的性能总是优于其他算法。BW-based 算法和RSS 算法分别根据服务速率最大和RSS 最大进行切换决策,没有考虑切换开销带来的影响,可能导致较多的切换和较大的切换开销。Fixed 算法在用户接入网络后不进行切换,当网络条件发生变化时无法切换到性能更好的切片。而SAW 算法在进行切换决策时,不考虑其他用户决策的影响,可能导致多个用户选择相同切片接入,从而竞争有限的切片资源。而MARL 算法一方面综合考虑了用户服务速率和切换开销的之间相互影响和约束关系,另一方面也考虑了系统中多个用户间的相互竞争关系,因此能取得比其他几种算法更好的性能。
图4对比了不同算法下系统中的累积切换次数。从图中可以看出,除了Fixed 算法不会进行切换,MARL 算法的切换次数少于其他几种算法。其中,RSS 算法的切换次数相对较少,这是因为仿真中没有考虑用户移动,用户到接入站点的信道条件相对固定,当用户找到信道强度较好的基站就基本不再切换。而SAW 算法由于没有考虑其他用户接入选择的影响,容易造成多个用户竞争同一切片资源,导致切换次数较高。BW-based 算法只考虑了当前切片可以提供的服务速率,而没有考虑切换带来的开销,也会导致切换次数较高。
图5给出了切换开销 Kc与系统中累积回报的关系。随着 Kc增大,各算法的累积回报逐渐减小。当Kc值较大时,如图 Kc>5时,切换开销很大,用户通过切换获得的服务速率增益小于切换带来的开销,因此MARL 算法下,用户基本不进行切换,算法曲线与Fixed 算法重合。同理,SAW 算法在切换开销较大时也很少切换,使得累积回报基本保持不变。而BW-based 算法在进行切换决策时并没有考虑切换开销的影响,因此不会因为 Kc的增大额而调整自己的切换策略,使得其累积回报受 Kc影响较大,随着 Kc的增大而持续下降。
图6 给出了随着切换开销的增大,不同切换算法下,系统吞吐量的变化情况。由于 Kc较大时,为了避免较多的切换开销,MARL 算法倾向于较少的切换,使得很多用户不会切换到当前能够提供最大服务速率的切片,造成系统吞吐量下降。同理,SAW 算法吞吐量的变化规律与MARL 算法类似,同样随着 Kc的增大而降低。而其他3 种算法在进行切换决策时,没有考虑切换开销的影响,随着 Kc的增大,系统吞吐量基本不受影响。综合图2~图6可以看到,与其他算法相比,本文提出的MARL算法能获得较好的网络传输和服务性能。
最后,图7 和图8 给出了本文提出的MARL算法的收敛性能。如图7 所示,当 α= 0.2时,算法在进行约20 000 次迭代训练后逐渐收敛。图中结果显示,α的取值越大,算法的收敛速度越快,但相应的数值结果波动越大,反之亦然。在此基础上,图8 给出了所采用的分布式Q-Learning 算法中,对应Q 值函数的收敛情况。Q(s,ai)为系统处于状态s 时,采取动作ai得到的动作值函数。从图中可以看到,与图7 相似,在经过约20 000 次迭代训练后,Q 函数的取值趋于稳定。
5 结 束 语
本文研究了面向网络切片的移动网络中,移动用户接入切片的动态优化切换问题。考虑到网络中,多个用户之间的相互影响和制约关系,将多用户协同的接入切片切换过程建模为一个多人随机博弈问题。在此基础上,设计了基于多智体强化学习的多用户接入选择和切换算法。仿真实验的结果证明,本文提出的算法能够在提升网络服务性能的同时降低网络中的切换开销。
猜你喜欢
中国新通信(2022年4期)2022-04-23
中学生数理化(高中版.高一使用)(2021年3期)2021-06-09
科学与财富(2020年15期)2020-07-04
移动通信(2020年4期)2020-05-07
恋爱婚姻家庭·青春(2019年9期)2019-12-10
恋爱婚姻家庭(2019年26期)2019-09-14
移动通信(2019年4期)2019-06-25
现代信息科技(2018年4期)2018-07-12
探索科学(2017年4期)2017-05-04
中学化学(2016年10期)2017-01-07
