
Hadoop 大数据开发课程实践教学研究
2020-04-04 06:36胡新荣
计算机教育 2020年2期
梁 晶,胡新荣
(武汉纺织大学 数学与计算机学院,湖北 武汉 430073)
0 引言
随着获批“大数据与数据科学”专业数量和学生人数的快速增长,迫切需要加快厘清大数据相关课程的课程体系,规范教学内容,建设相应的实验环境。目前,大数据教学案例还不够丰富,课程体系建设还有待完善,有些课程的设置不能紧密跟随大数据的步伐,使得教学内容和形式还比较滞后[1]。从实践教学的教学过程和反馈来看,大数据技术课程、云计算技术等都具备较强的应用性和综合性特征,学生往往反映实践难度较大[2]。
Hadoop 作为开源的大数据平台,其分布式文件系统HDFS 和分布式计算框架MapReduce是大数据课程教学和企业大数据应用中的重要内容。Hadoop 系统可以作为单独的一门课程,也可穿插在并行计算、自然语言处理、数据挖掘或者云计算等课程中讲解[3]。
1 Hadoop实践教学内容
Hadoop 课程教学内容主要是分布式存储和分布式计算,其教学目标是让学生掌握以下几点内容:①理解计算与存储分离的架构在面向数据密集型计算时的缺陷,领会并行和分布式计算架构在可扩展性方面的优势;②掌握大数据存储和计算的特点以及所需要的技术,熟练使用HDFS 和MapReduce 编程;③理解HDFS 和MapReduce 在可扩展性和性能方面的特点,为进一步学习其他分布式计算框架打下基础[3-4]。在文献[1]和[2]中均描述了大数据课程的课程体系,Hadoop 课程涉及的分布式存储概念和分布式编程方法在大数据专业的整个课程体系中处于承上启下的中心位置。在Hadoop 课程的实践环节中,学生需要灵活运用操作系统、Linux 系统编程、面向对象程序设计和Java 语言编程等前导课程的知识,有一定的综合性。同时,由于大数据课程的教材建设时间较短,不同的Hadoop开发教材中实践教学内容有一定差异,受制于教材篇幅也很难在一本教材中展现实践教学的全部内容。因此,笔者对Hadoop 课程中涉及的实践教学内容进行了一些整理,选取了Hadoop 课程核心的实践教学内容,其主要包括Hadoop 系统安装和配置、Hadoop 系统的基本操作、HDFS 编程、MapReduce 编程和综合应用等几个部分,具体内容见表1。
表1 中列举的24 个学时实验涵盖了Hadoop系统的主要实践教学内容,在大数据工程应用中还包含数据转换、导入、清洗和数据展示等内容,实际教学过程中可以根据培养目标、学生接受程度、学时安排和实验条件等因素适当调整。可以将一部分实践教学内容作为实验任务,亦可以作为课堂练习或者课后作业,也可以如文献[2]描述将一部分实践教学内容穿插到其他相关课程中进行。
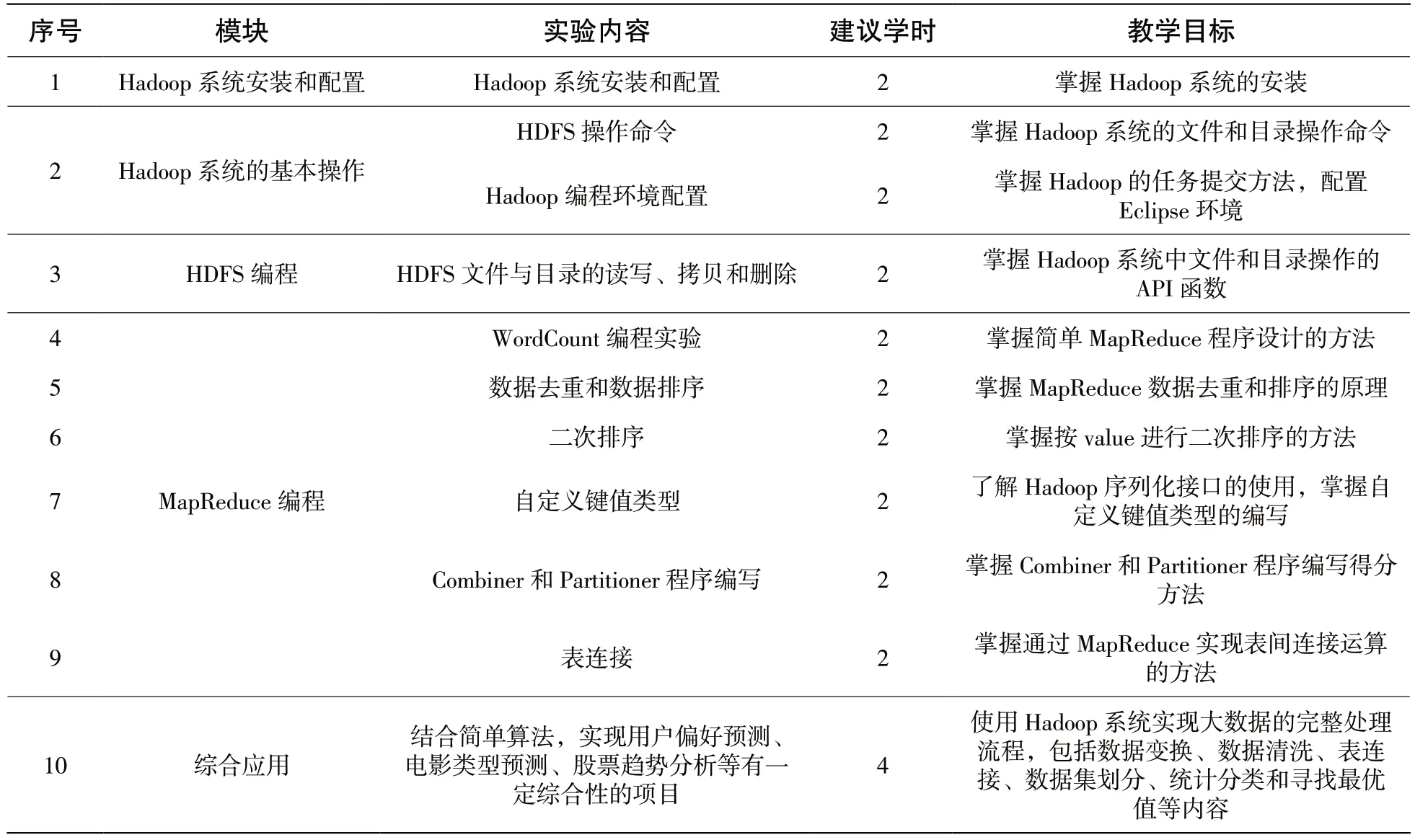
表1 Hadoop 实践教学内容
从表1 中还可以看出,MapReduce 编程是Hadoop 系统实践教学的主要内容,也是学生学习的难点,这个部分可以结合PPT 讲解、视频教学和理实一体化教学等多种教学方式,确保学生深入理解和消化实验中涉及的相关知识。
2 Hadoop实践教学的数据集选取
大数据任务的主要特点就是数据容量大(Volume),同时又对时效性(Velocity)有较高的要求。数据集的大小和构成是选择计算平台的主要因素,对学生来说,学会分辨一个数据处理任务是通过传统的方法处理,还是需要使用大数据平台来处理是一个重要的能力[5]。文献[4—6]中介绍了一些国外大学教学中使用的数据集,其中一部分见表2。

表2 部分数据集
在实践教学过程中,实验数据集的选择既要凸显大数据的特点,又要兼顾实验学时和实验条件的限制。针对数据集选择方面可参考以下几方面。
(1)实验中使用的数据集大小宜控制在1 000万至2 000 万条。数据量过小的数据集学生使用Excel 或者Mysql 数据库就可以处理,无法凸显出分布式存储和分布式计算的优势。反之如果数据量过大,由于实验室分配到每个学生的存储和计算资源有限,一方面HDFS 中dfs.replication 的配置会导致存储空间占用较多,另一方面会运算时间较长,在有限的实践教学时间内难以完成。
(2)数据集选取应尽量贴近实际应用,即数据集中的数据应选取真实的、有分析价值的数据。实际应用中产生的数据有较强的多样性(Variety),包含结构化和非结构化数据,其中既蕴藏了客观规律,又可能含有噪声数据,这些不确定性避免了实验结果千篇一律,有利于激发学生自主探索的热情,提高学习积极性。
(3)在课内实践学时有限的情况下,教师教学可以选用一两个有代表性的数据集来完成HDFS 和MapReduce 编程实践的主要教学内容。复杂数据集的预处理和分析计算需要更多时间,可以在课后作业或者课程设计中使用。如笔者在教学中使用了1 000 万条的user_login 作为数据集,内容仅包含某网站的用户名称和用户登录时间,基于该数据集设计了WordCount、去重和排序、二次排序、自定义键值等实验,目的是在有限的课堂学时内让学生专注于掌握Hadoop 的计算架构,提高教学效率。
(4)要求学生在课后和课程设计中自行准备合适的数据集,鼓励学生使用自己的数据集完成实验内容。例如,在排序和自定义键值的实验中,笔者要求学生提前下载noaa 全球气象数据集(https://www1.ncdc.noaa.gov/pub/data/gsod/),完成数据预处理和数据清洗,也有一部分同学通过政府开放数据平台data.gov 下载了其他感兴趣的数据作为数据集。这样既能有效增加数据集的多样性,又能让学生在实践过程中充分发挥自主能动性。
在条件允许的情况下,学校可以通过与国内互联网公司合作获取TB 或者PB 级的数据集,如零售、餐饮行业的数据等。学生通过对这些海量数据中蕴藏的规律进行探索和分析能够大大提高学生的学习兴趣,增强工程实践能力。
3 Hadoop实践教学的实验平台建设
由于国内大数据专业开设的时间较短,各学校在实验平台建设方面还处于摸索阶段,如何兼顾不同的大数据相关课程在实践教学内容、教学资源和资金投入方面的要求,仍面临较大的挑战。
3.1 现有的一些实践教学平台
在实践平台的建设和选择方面,在已经开设了Hadoop 相关课程的国内外大学中有一些成功的经验可以借鉴。文献[7]中采用了亚马逊的EC2 商业大数据环境作为Hadoop 的实践教学平台,因此需要考虑每次实验时长产生的费用开销。文献[8]列举了国内的商业大数据运行环境,提出了通过私有云和物理机混合组建大数据计算平台的方法。文献[9]和[10]阐述了通过Docker 构建弹性大数据实验环境的方法。文献[3]中总结了4 种在教学中经常使用的Hadoop MapReduce 计算平台。
(1)通过WebMapReduce Tool 提供的Web页面提交MapReduce 计算任务,适合对编程能力要求不高的场合。
(2)通过用户账户在共享的Hadoop 集群上提交计算任务,Hadoop 集群通过作业批处理依次运行各个用户提交的任务。
(3)在Linux 集群上通过虚拟化生成很多运行Hadoop 集群的虚拟机,每个学生在自己的Hadoop 虚拟机上执行计算任务。
(4)在云环境下,学生通过分配到的资源创建私有的Hadoop 集群完成计算任务。
通过上述资料可以看出,各个学校选择的Hadoop 实践教学平台搭建形式和使用方法不尽相同,需要综合考虑各方面因素,相应的实践教学手段和教学方法也稍有差异。
3.2 实践教学平台特点分析
结合目前国内高校中的实际应用情况,Hadoop 实践教学过程中各个平台的特点如下。
(1)通过商业云环境搭建Hadoop 实践环境,或者通过与互联网公司合作共建大数据实训环境。这种方法的优势是实践平台与企业实际应用环境高度一致,容易获取高质量的实训软件和训练数据集,有利于学生创业和就业,同时实验室也省去了维护成本。缺点是商业云环境每年都需要一定的费用开销。
(2)通过Linux 服务器集群和Docker 构建弹性大数据实践环境。这种方式是目前国内大数据教学平台提供商推荐较多的环境。其优势是提供弹性的云服务,适合动态扩容,能够根据实践教学需要灵活定制不同课程需要的环境,通过一次性投入可以满足多种课程的教学需要。这种实验条件下可以运行Hadoop 完全分布式环境,贴近生产实际。缺点是一次性投入较大,而且分配到每个学生的Linux 服务器集群资源有限,在设计时要准确估计并发的虚拟机节点数量和资源需求,安排上机时间时要错开高峰时段。
(3)在单台PC 机上通过VMware 等虚拟机软件安装Hadoop 伪分布式环境,或者在单机上运行多个虚拟机来模拟Hadoop 完全分布式环境,这也是很多Hadoop 教材案例中使用的方法。其优点是对硬件环境要求不高,适合预算较为紧张的情形,也适合学生自学使用。缺点是单机性能有限,且在学习过程中无法体验到分布式环境的优势。
3.3 灵活运用各种实验教学环境
为了在有限的时间内取得更好的教学效果,可以在教学实践过程中结合上述几种Hadoop 实践教学环境的特点,设计一套实践环境和配套的教学方法。在基础实践环境方面:①在大数据实验室的64 台PC 机上(I5-7500 CPU,8G 内存,500G 硬盘),单独划分Linux 分区,为每台PC 机都安装了Hadoop 伪分布式环境,并预先准备好部分实验数据集和编程的工程模板;②基于Linux 服务器集群和Docker 搭建了一个弹性大数据实践环境。该环境使用了3 台刀片服务器,每台服务器包含2 颗14 核28 线程CPU,256G内存,16T 硬盘,可以满足64 个学生同时上机,每个学生节点上运行1 个NameNode 和2 个DataNode;③基于Windows 环境下的VMware虚拟化软件,为学生准备了一个Hadoop 伪分布式环境,学生可以将该环境拷贝到自己的笔记本电脑上运行。
上述几个环境中的Linux 操作系统、Hadoop运行环境和Java 开发环境均保持一致,确保程序无需修改就能在其中任何一个平台上运行。在教学过程中可以根据不同的实践教学任务灵活使用上述几种实验环境,组织方法如下。
(1)对于验证形式的实验,如Hadoop 系统安装和配置、HDFS 操作命令、HDFS API 编程等都在实验室PC 机上的伪分布式环境中完成,这些实验易于上手,执行效率较高。
(2)对于设计型的实验,学生在PC 机上的伪分布式环境中完成编码,如果数据集不大,可以直接在伪分布式环境中执行任务。如果数据集偏大需要的处理时间较长,则将在PC 机上完成编码的任务提交到基于服务器集群的弹性大数据实践环境中完成。
(3)对于课后作业,学生可以在自己的笔记本电脑上完成编码,然后通过校园网登录到基于服务器集群的弹性大数据实践环境中提交任务,确保了课后作业质量。
(4)在课程设计时间段,由于数据集较大,现有的资源分配方式不能满足每个同学的上机需求。此时将3 名学生分为一个组,重新划分弹性大数据实践环境的资源分配比例,将账号数量调整至20 个左右。这样每个小组分配到的计算资源增加了3 倍,组内成员通过相互协调分时使用计算资源完成课程设计的计算任务。也有部分动手能力较强的同学,在课程设计中利用实验室的数台PC 机搭建一个Hadoop 完全分布式环境,同样可以获得较强的计算能力。
通过上述各种实验环境的灵活搭配和实践教学过程中的灵活运用,Hadoop 大数据开发课程的实践教学环节教学组织形式多样,既避免了照本宣科,也不再受制于特定的实验条件,更加接近于真实的生产环境。
4 结语
教学实践中,在对应用数学专业、计算机科学专业和大数据专业开设的Hadoop 大数据开发课程中使用了上述方法。经过2 个学期的课程教学实践,学生普遍反映实践环节上手难度不大,实践教学内容有较强吸引力而且从中受到的启发颇多。学生独立完成实践任务的意愿较高,提交的作业和实验报告中鲜有相互抄袭现象,取得了较好的教学效果。受制于教师水平和实验室条件,大数据相关课程的实践教学方法探索和实践环境建设是一个长期的过程,我们在今后的教学过程中还需要不断学习和总结,紧跟大数据与产业深度融合的时代潮流,不断提升教学水平和质量。
猜你喜欢
电气技术(2022年8期)2022-08-20
小学教学研究(2022年21期)2022-07-28
今日农业(2021年17期)2021-11-26
军民两用技术与产品(2021年5期)2021-07-28
汽车维修与保养(2021年8期)2021-02-16
学生天地(2020年17期)2020-08-25
软件(2020年3期)2020-04-20
数学大王·低年级(2020年3期)2020-03-12
知识就是力量(2018年4期)2018-04-13
广西教育·B版(2016年8期)2016-11-01
