
采煤机运行状态数据实时清洗技术研究
2020-03-31 03:20:02曹现刚姜韦光张国祯
煤炭工程 2020年3期
曹现刚,姜韦光,张国祯
(西安科技大学 机械工程学院,陕西 西安 710054)
随着煤炭行业的智能化发展,煤炭企业的管理方式正在逐渐由粗放型转变为精细化管理,中国大中型煤矿企业由设备产生的数据规模已经达到了PB级别[1]。煤矿设备种类繁多,采煤机作为综采三机之一,集成机电液为一体,实现了煤矿采集的机械化与自动化,其在工作过程中产生的设备运行状态数据成为了监测煤矿开采状态的重要依据。然而采煤机的工作环境复杂且恶劣,其运行状态数据的采集会受到诸多因素的影响,使得采集来的数据会出现大量的噪声点与缺失值[2],从而导致数据的质量不足以满足后续的数据分析工作。因此对采煤机运行状态数据的清洗工作必不可少[3]。
严英杰等[4]为提升输变电设备运行状态数据质量,利用时间序列分析对数据进行了清洗建模并验证了其有效性。韩福霞等[5]构建电力信息系统工程监理实时分析预测模型,为满足其实时性,使用了Storm平台与模型相结合的方案。吴克河等[6]提出基于Storm 平台和ARIMA模型的预测平台,分析不同类型电网时序数据的特点,预设模型参数以降低预测时间。马宏伟等[7]搭建了一种基于MapReduce的煤矿综采设备运行状态大数据清洗模型,该模型的采用双MapReduce协同工作,并将清洗结果按时间排序。综上所述,当下有关数据清洗的研究以及Storm的应用多处于电网设备这一背景之下,即便与煤矿设备相关,也偏重于研究非实时清洗技术。本文在上述研究成果的基础之上,建立了基于Storm的采煤机运行状态数据实时清洗平台,该平台旨在完成采煤机运行状态数据的实时清洗工作,为后续的数据分析工作提供基础。
1 采煤机传动系统运行状态数据清洗建模
1.1 采煤机传动系统运行状态数据
采煤机截割部传动系统可将电机的高转速低扭矩转换成能够驱动截割滚筒的低转速高扭矩,在这一过程中,会产生大量轴承以及齿轮的振动数据[8]。本文就以采煤机截割部传动系统的振动数据为研究对象,进行数据清洗平台搭建。采煤机常年在井下工作,环境复杂。为了达到测试目的,结合传动系统结构以及实际工况,本文以电机轴、惰轮轴以及滚筒轴的轴、径向为测点采集振动信号,具体测点信息见表1。

表1 测点信息
分别在轴、径向安装传感器是为了让这两者所采集的振动信号形成互补。如表1所示,电机轴、惰轮轴以及滚筒轴的轴、径向分别都布置了测点,并且每个部位都有对应的齿轮和轴承以及相关参数。
1.2 ARIMA模型适用性及噪声分析
采煤机传动系统某一时刻的振动数据是通过时间和数值的数组来描述的,多个振动数据组成时间序列。这些时间序列多属于非平稳序列。ARIMA适合处理平稳序列,而非平稳序列就需要通过ARIMA进行处理,该模型在处理前会对时间序列进行平稳化处理。
滚筒在截割半煤岩与硬岩时发生的力学耦合作用,会导致采煤机的急剧振动[9]。这种剧烈振动就会使采煤机运行状态数据中产生噪声点。在工程领域,样本标准差反应了数据的波动程度,因此可以将样本标准差作为噪声点的衡量标准如式(1)所示:
式中,Xt为t时刻数据;μt为Xt的对应的样本期望。根据正态分布性质,本文将|Xt-μt|>3σ的数据判定为噪声点。
1.3 基于ARIMA的时间序列预测模型
ARIMA即自回归求和移动平均模型,采煤机设备运行状态数据多是非平稳序列[10],因此在进行拟合预测之前先选择差分法作为平稳性处理方法。样本数据经过d阶差分后满足ARIMA(p,d,q)条件,可用式(2)表示:
φ(B)dXt=θ(B)εi
(2)
φ(B)=1-φ1(B)-φ2(B)2-…-φp(B)p
(3)
θ(B)=1-θ1(B)-θ2(B)2-…-θq(B)q
(4)
式中,p与q为ARIMA(p,d,q)中参数;φ与θ分别是自回归与移动平均模型的系数。
1.4 数据清洗步骤


图1 ARIMA数据清洗步骤
2 基于Storm的数据实时清洗平台
2.1 数据清洗拓扑设计
拓扑(Topology)以应用程序的形式实时运行在Storm中的。为了能够对实时的源源不断的各种煤矿设备状态数据做出相应的清洗工作,就需要一个具有数据清洗逻辑的拓扑。其功能主要包括读取海量测点数据、数据实时预测、噪声点实时判断与剔除,空缺值实时恢复。Storm的处理逻辑被封装在了Topology类中,其中包含了Spout类与Bolt类运行逻辑关系。


图2 数据清洗Topology
2.2 Spout与Bolt设计
上文对数据清洗拓扑中各组件的协作机制进行了总体的概述。现对拓扑中Spout与Bolt类的设计进行描述。由于Storm在运行过程中,主要调用的是Spout类与Bolt类中的nextTuple与execute函数,所以现对这两类函数进行详细描述。负责读取数据以及封装成元组Tuple的Spout中nextTuple函数见表2。
负责对数据进行预测以及数据清洗的ARIMA Bolt中的execute函数,见表3。

表2 Spout类中nextTuple函数

表3 ARIMA Bolt类中execute函数
3 实验分析
实验数据来自与某矿业公司采煤机截割部传动系统振动数据。实验所用的Storm集群搭建在IBM公司规格型号为S822LC的服务器上搭建而成,服务器配置为NVIDIA Tesla K80 GPU、256G内存、960G固态硬盘以及10T的磁盘存储阵列。
3.1 样本容量分析
样本容量N如上文所述,即ARIMA Bolt某时刻处理的数据个数,而前N-1个数据是作为训练集train,train的增加可以提高ARIMA预测的精确度,但也会增加计算机的处理时间。先对train与预测精度的关系进行实验探究。精度定义为某一训练集下的预测值与原始数据的残差绝对值期望,结果如图3所示。

图3 精度与训练集的关系
如图3所示训练集在达到100的时候其预测精度将很难通过增加样本容量而提高,因此本次实验样本容量取N=train+1=101。
3.2 数据清洗模型验证
本次模型验证选取采煤机传动系统电机轴轴承径向振动加速度数据(即表1中测点1的数据),并在数据中加入噪声点,将一个观测点的数据剔除,造成数据的缺失。轴承振动加速度原始数据和含有异常值的数据如图4所示,由图4中虚线可见,将t=141处的数据剔除造成数据缺失,在t=155到t=157处加入噪声点,在t=225处加入一个噪声点,生成一个异常数据序列。

图4 轴承振动加速度原始数据和含有异常值的数据
首先以异常数据的前101个数据即X1到X101作为样本数据,得出样本期望μ101=0.000997,样本标准差σ101=0.006681以及X101=-0.00478,由于|X101-μ101|=0.005777<3σ101,所以X101判定不为噪声点,不需清洗。同理可以依次对X101到X300的数据进行拟合、预测、判定、去噪和恢复工作。
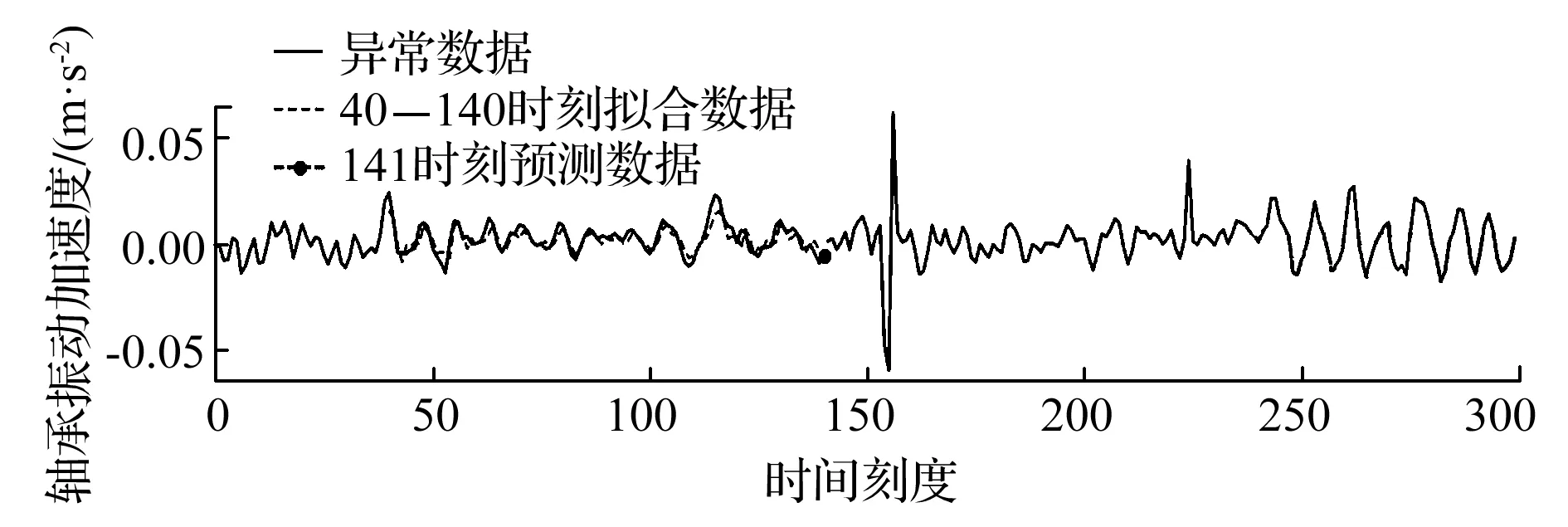
图5 X102到X141数据清洗效果


图6 BIC热力图


图7 X142到X157数据清洗效果
X142到X157数据清洗效果如图7所示,X142到X154时刻的数据皆判定不是异常数据;而X155到X157时刻与其对应的样本标准差的对比情况见表4。

表4 异常值与预测值对比情况
如表4可知,|X155-157-μ155-157|皆大于其对应的3倍标准差所以可将其尽数剔除,并使用预测数据进行恢复。

图8 X158到X225数据清洗情况
X158到X225数据清洗情况如图8所示,X158到X224时刻的数据皆判定不是噪声点;而|X225-μ225|=0.039663>3σ225,因此可以将t=225处数据判定为噪声点并用预测值恢复。
清洗结果与原始数据对比如图9所示,X141时刻的缺失值以及X225时刻的噪声点的清洗效果较为理想,残差很小;但是在X155到X157时刻的噪声点的清洗效果较不理想,残差较大。这是因为ARIMA适合预测一种渐变的趋势,比如在原始数据从X140=-0.00913到X141=-000659这一变化过程种,数值变化幅度较小,ARIMA能够较准确的进行预测;而原始数据X154=0008725到X155=-000797数值变化幅度较大,所以ARIMA在X155到X157时刻的预测效果受到影响,从而造成了较大的残差。不过总体来讲,ARIMA完成了所有噪声点与缺失点的剔除与恢复。

图9 清洗结果与原始数据对比图
3.3 数据清洗实时性分析
实时性可以理解为,数据清洗平台单位时间内清洗数据的数量,该数量可以通过Storm自带的Storm UI进行观察获取,先对Storm UI界面的主要参数进行说明见表5。

表5 参数含义
本次实时性分析实验Storm UI界面显示的相关参数的详细展示如图10所示。

图10 实时性检验结果
由图10可知,本次实验为ARIMA Bolt共分配了3个线程,任务数为3。execute函数的平均执行时间即处理一个样本花费时间(图10中方框)为0.195ms,即该数据清洗平台每秒钟约能清洗5128个数据,而本次实验测点的数据采集频率为5000Hz,所以可以证明该数据清洗平台的可以满足本次实验测点数据的实时清洗要求。
4 结 语
本文针对采煤机运行状态数据的特点建立了数据实时清洗平台,经实验证明,该平台可在保证一定数据恢复精度的情况下完成采煤机运行状态数据的实时清洗,为后续的数据分析工作提供基础。我们未来的工作将进一步研究煤矿各类设备的噪声特点,并根据这些特点对数据清洗平台做出相应的调整。
猜你喜欢
疯狂英语·读写版(2023年12期)2023-02-20 18:41:06
中国造纸(2022年8期)2022-11-24 09:43:38
China Report Asean(2022年8期)2022-09-02 05:31:26
防爆电机(2022年1期)2022-02-16 01:14:06
一重技术(2021年5期)2022-01-18 05:42:12
物联网技术(2020年12期)2021-01-27 03:34:08
电子制作(2018年10期)2018-08-04 03:24:26
汽车零部件(2017年4期)2017-07-12 17:05:53
河南科技(2014年18期)2014-02-27 14:14:58
河南科技(2014年4期)2014-02-27 14:07:18
