
基于CNN的舰船高分辨距离像目标识别
2020-03-28 11:20
雷达科学与技术 2020年1期
(1. 海军工程大学电子工程学院, 湖北武汉 430033; 2. 中国人民解放军91245部队, 辽宁葫芦岛 125000)
0 引言
高分辨距离像(HRRP)在雷达自动目标识别(RATR)领域具有重要的军事意义,其图像的尖峰和起伏代表了目标的精细结构信息,反映了目标散射特性沿雷达视线方向(RLOS)的分布,同时具有易获取、易处理的特点,因此在目标识别领域具有广阔的应用前景[1-5]。目前国内外学者对基于HRRP的目标识别进行了大量的研究,模板匹配法[3]、SVM[4]和PCA[5]是比较常见的目标识别方法,但以上对于HRRP的目标识别方法均基于特征提取这一关键步骤,很难挖掘目标数据中的深层特征,且泛化性能不强[6-11]。
近年来深度学习(DL)发展迅速,成为各个领域的研究热点,同样在雷达领域也可以通过深度学习算法实现信号与信息处理[12]。目前已有国内外学者将深度学习应用于HRRP-RATR领域中,文献[8]分别将SVM、NN(Neural Network)与SAE方法进行区分,通过比对实验发现SAE的识别率最高。西安电子科技大学雷达信号处理国家重点实验室的冯博团队在文献[13]中提出SCAE(stacked corrective autoencoder)方法,对SAE进行了改进,提升了HRRP的识别效果。文献[14]应用SAE和极限学习机相结合的方法进行分类,识别速度快。文献[15]采用RNN中长短时记忆循环神经网络(LSTM)对HRRP进行分类。文献[16]应用了深度置信网络(DBN)进行HRRP目标识别,该文献提出对样本进行t分布随机邻域插入处理,扩充了相应类型样本量。文献[17]利用CNN进行HRRP的目标识别,该文献对比了CNN和DBN对不同目标的识别准确率,CNN的准确率大于10%。
CNN作为一种端对端的识别方式,无需人工特征提取且不需要角度的先验信息,一般用于对图像数据的处理,其鲁棒性和抗干扰性较强。针对传统目标识别方法人工提取特征难以挖掘到数据深层次特征,且易丢失数据信息的问题,本文提出了将CNN应用于HRRP的目标识别方法;针对HRRP数据是一维的问题,本文提出了将HRRP序列重新排列,将一维数据变为二维数据进行输入,其具体方法为:将一维HRRP向量分为若干列向量形成“伪二值图像”,即二维矩阵,作为网络的输入数据。由于CNN网络对平移、扭曲、缩放具有不变性[18],因此将一维数据转化为二维数据并不会增加或减少数据所包含的信息量,并且基于此优越特性,解决了HRRP的平移敏感性。并在各层将数据可视化,可以更加直观地看出网络的训练过程;针对网络中参数的选择问题,本文详细讨论了网络中的参数对识别性能的影响并进行了优化。另外本文通过对数据集减半和添加噪声的方式验证了CNN具有较高的鲁棒性和较高的识别率。
1 基于卷积神经网络的高分辨距离像目标识别
1.1 高分辨距离像(HRRP)
HRRP是目标散射点子回波沿雷达视线方向的投影向量和,其生成示意图如图1所示。早期的雷达目标识别主要是通过窄带雷达对目标的有效散射截面积(RCS)进行研究的,随着带宽的增大,雷达的分辨能力增强,当雷达的带宽大到使雷达的距离分辨率远小于目标的尺寸时,目标的各等效散射中心在雷达视线上被分开,目标回波占据了多个距离单元,形成HRRP,它包含了目标的结构、大小、形状等重要信息[19],因此如何有效地获取并利用这些信息在目标识别领域中显得尤为重要。
1.2 CNN模型结构
CNN是一类特殊的前馈神经网络,最早始于20世纪60年代Hubel和Wiesel等人通过对猫和猴的视觉皮层细胞研究,发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,提出了感受野(receptive field)的概念,继而提出了CNN[20]。近年来,CNN被广泛应用于各个领域,在语音识别、人脸识别、通用物体识别、运动分析、自然语言处理等方面均有突破,它的基本结构如图2所示。

图2 CNN基本结构图
从图2可以看出,CNN与普通的人工神经网络相比在结构上多了卷积层和池化层,即“特征抽取器”,通过数据训练出的卷积核对于特定的特征才会有较大的激活值。卷积操作是利用卷积核对输入图片或者上一隐层的数据进行处理,更深层次的卷积层可以学习到更深层次的特征,其核心是可以减少不必要的权值连接,权值共享可以大大减少网络的参数量并且提高计算速度,每一个卷积层包含了若干个特征映射图(feature map),其表达式如下:

(1)

hi=pooling(hi-1)
(2)
池化操作包括最大池化、平均池化等,本文采用最大池化。在全连接层输出的每个神经元都和上一层每一个神经元连接。在输出层一般用softmax分类器进行分类,损失函数为
(3)
式中,Y为网络的输出,后一项为正则项,目的是为了防止过拟合,权重衰减系数λ可以控制过拟合程度,λ值过小可能会导致过拟合,反之可能会导致欠拟合。
1.3 步骤方法
由于HRRP是一维数据,因此本文考虑将HRRP数据重新排列转化为二维数据再进行输入。实验步骤分为数据预处理、训练网络、测试网络。
数据预处理:一般情况下初始HRRP都是复值数据,首先对复值数据进行取模运算,然后进行能量归一化,最后将一维数据重新排列转化为二维数据。
训练网络:在网络进行训练之前搭建CNN网络,初始化网络参数,本文采用标准初始化(normalized initialization)方法初始超参数,即
(4)
式中,U代表均匀分布,m为类别数,n为输出的全连接维度。将处理后的二维数据作为网络的输入,利用式(1)、式(2)进行前向传播计算,获得网络各卷积层和池化层的特征图h1,h2,…,根据得到的损失函数式(3)利用反向传播算法(BP)来实现网络中参数的更新学习,最终得到每一类样本的网络参数w和b并保存。
测试网络:将测试数据输入到训练好的网络模型中并与实际标签进行对比,计算网络的准确率。
2 实验结果与讨论
2.1 数据集
本文采用的数据是某实验室通过水声试验测量的舰船模型HRRP数据[21],舰船模型与实验装置如图3所示,实验示意图如图4所示。

图3 舰船模型与实验装置
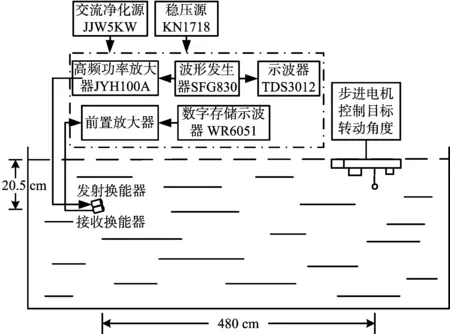
图4 实验示意图
实验共测得5类舰船在不同角度下的HRRP数据,5类舰船目标编号为目标A~E,其中A~C为军用舰船,D为渔政船,E为巴拿马型货船。每一类包含2 400个样本,平均覆盖180°姿态角,图5给出了5类目标在姿态角为0°时的归一化HRRP。
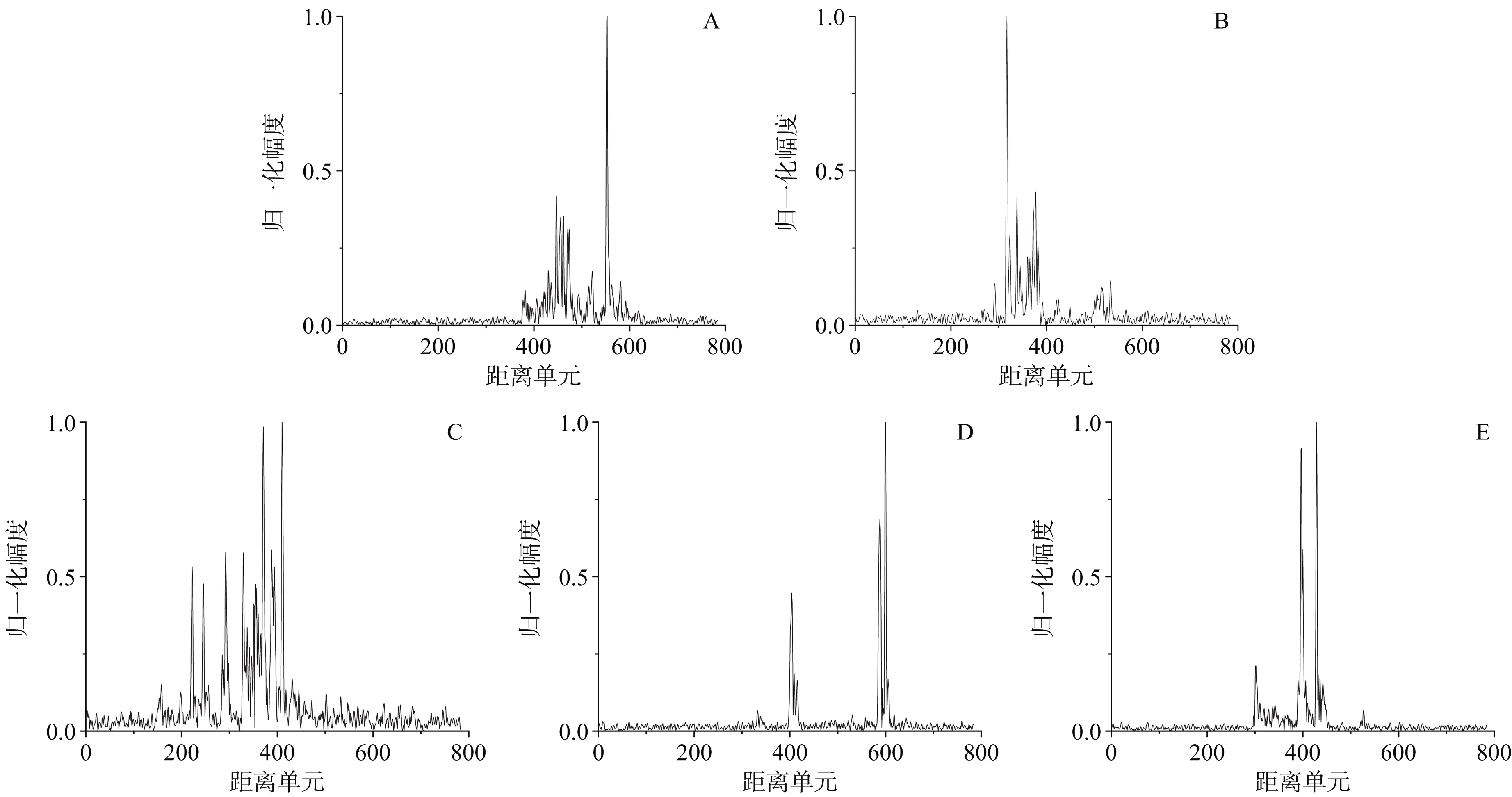
图5 5类舰船实测数据的HRRP
本文所采用的网络模型如图6所示。

图6 卷积神经网络模型
实验随机抽取80%的数据进行训练网络,剩余数据测试网络。设测试数据为Ptest,这里Ptest=2 400,测试数据中预测正确的样本数量为N,由于5类舰船数据量相同,具有对称性,因此本文定义目标识别率为
(5)
2.2 实验结果
实验基于MATLAB中的DeepLearn Toolbox,具体运行环境为Intel (R) Core(TM) i5-7500 CPU @ 3.4 GHz(8 G内存)。为了更加清楚直观地观察网络训练的过程,图7给出了可视化训练结果。
图7为某类样本在一次训练过程中的特征图,其中包括第一个卷积层的6张特征图和第二个卷积层的12张特征图(图中特征图的纵轴均为归一化幅度),网络层数越高代表了学习到更深层次的特征。由于sigmoid函数在信号的空间映射上有良好的效果,因此实验选取sigmoid作为激活函数,对应的公式为
(6)
在实验中,取学习率α=1,batches=50,采用批量随机梯度下降法训练网络,在不同的迭代次数下目标识别率如图8所示。

图8 CNN在不同迭代次数下的识别率
由图8可以看出,在迭代次数超过150时网络基本可以学习到数据的全部特征,训练损失曲线如图9所示。同时为了验证CNN方法对稳健特征提取与目标识别的有效性,文章将CNN与SVM进行比较,在SVM实验中,核函数取径向基函数(RBF),通过网格搜索算法对惩罚系数C和σ进行寻优,训练数据与测试数据完全相同,CNN迭代次数为300,识别率与识别时间如表1所示。

图9 训练损失曲线

表1 CNN与SVM的目标识别结果
从表1可知,CNN的识别性能在准确率与识别时间上都优于SVM,识别率可达到99.54%,并且识别速度较快,无需人工特征提取且无需了解姿态角的先验信息。
3 泛化性能
由上一节可知,在数据量充足的情况下CNN可达到较高的识别率,但由于舰船非合作目标的缺陷,往往会造成数据库角度数据的不足,数据集缺失,回波数据被噪声干扰等情况,本节将进一步探讨在训练数据不足且添加噪声的情况下CNN的识别性能。
取数据集中姿态角度为30°~60°,90°~120°,150°~180°扇形区间内的数据,训练集从中随机选取80%,即将数据集与训练集减少一半,测试集不变,仍从全数据集中随机选取20%,这样测试集中会有大约50%的数据没有在训练数据的扇形区间内。在此基础上,对数据加入高斯白噪声,使得处理后数据信噪比范围为-5~10 dB,CNN在不同的信噪比、学习率、迭代次数下识别结果如表2所示, 与此同时将实验测得SVM在相同数据集与信噪比环境下的识别率如表3所示,两种方法的识别结果如图10所示。
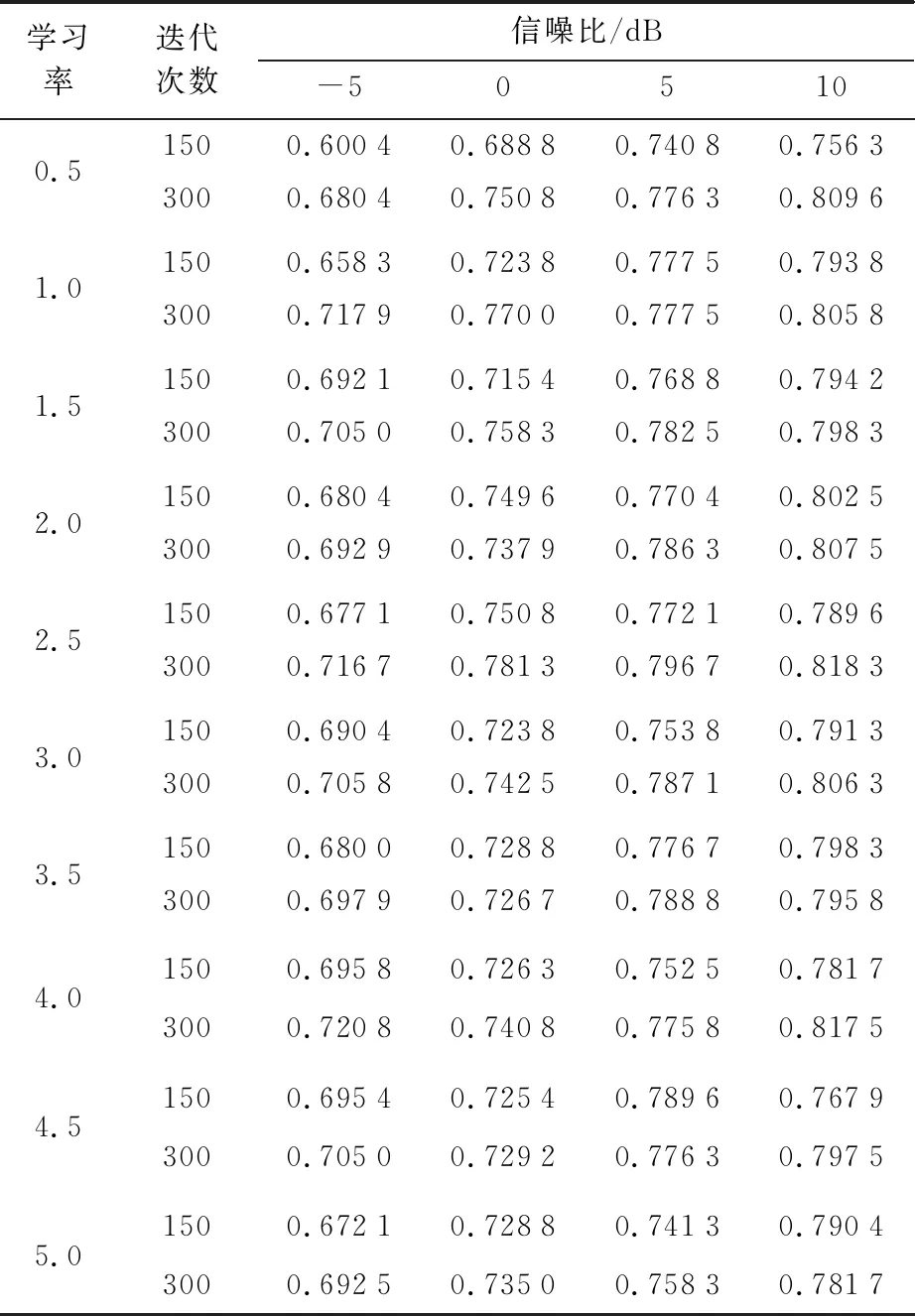
表2 CNN在不同条件下的识别结果

表3 SVM在不同信噪比情况下的识别结果

图10 CNN与SVM在不同信噪比情况下的识别率
从图10可以看出,在添加噪声并且测试集中有一半的数据集没有经过训练的情况下CNN仍有较高的识别率,信噪比为10 dB,训练数据减半时最高识别率可达到81.83%。学习率是深度学习中重要的参数,其取值对于梯度下降法有重要的影响,值过大可能会导致陷入局部极值甚至无法收敛,值过小可能导致收敛过程十分缓慢,因此学习率是决定目标函数是否能够收敛与何时收敛的重要因素。往往在训练深度网络的过程中学习率的取值多数凭经验选取,比如1等值,而适当的学习率的选择会提高目标识别的准确率,在图10中当信噪比大于0时,α=2.5时识别率最高,平均识别率可提高1.0个百分点。当学习率分别为1和2.5时网络的训练损失如图11所示。从图11可以看出,当α=2.5比α=1时网络会更加快速的收敛。
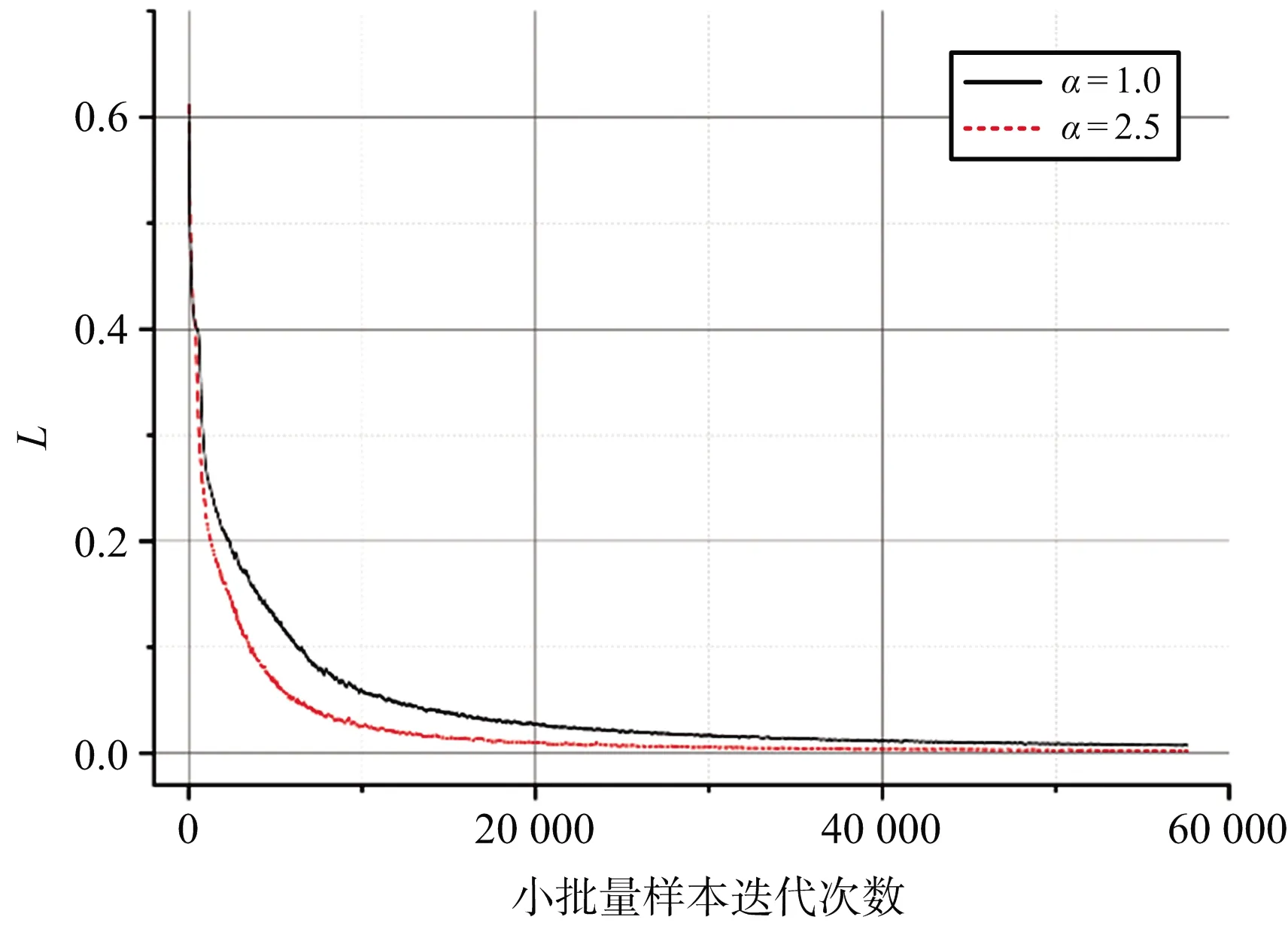
图11 不同学习率下的训练损失曲线
4 结束语
本文将卷积神经网络应用于高分辨距离像的目标识别中,将一维数据转化为二维数据,解决了在传统目标识别的过程中人工提取特征很难挖掘到数据深层次特征的问题。在数据量充足的情况下可以达到近百分之百的识别率,然后对网络的泛化性能进行了讨论,并与SVM进行了对比,验证了CNN的鲁棒性较强,最后对不同的学习率进行了对比,以往由于深度网络训练时间较长等原因,学习率的选择往往是易被忽视的一点,而本文提出的合适学习率的选择可以提高识别率,对雷达自动目标识别具有重要的意义。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
舰船科学技术(2022年10期)2022-06-17
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
舰船科学技术(2021年12期)2021-03-29
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
