
基于VGG-NET的特征融合面部表情识别*
2020-03-26 11:07:48李校林钮海涛
计算机工程与科学 2020年3期
李校林,钮海涛
(1.重庆邮电大学通信与信息工程学院,重庆400065;2.重庆邮电大学通信新技术应用研究中心,重庆400065; 3.重庆信科设计有限公司,重庆 401121)
1 引言
面部表情是人们传达情感和意图的自然而直接的手段,一个人的面部表情会无意识地流露出许多情感信息,如何让智能机器正确分析人类所表达的情感和情绪已成为人机交互领域中的研究热点,广泛应用于医疗检测、谎言检测和多媒体等领域。随着研究的深入,面部表情识别中的表情被分为7类[1,2],包括快乐、惊讶、悲伤、愤怒、恐惧、厌恶和中性表情。当前面部表情识别的主要任务是特征提取和分类,传统的特征提取方法难以在不同的肤色、年龄、性别和光照条件等复杂条件下选择特征提取。近年来,面部表情特征提取方法层出不穷,有采用基于面部子空间的特征提取方法(比如主成分分析PCA(Principle Component Analysis)[3]、线性判别分析法[4,5]等提取面部细节局部特征的方法)、基于空频变换的傅里叶变换法[6]、基于直方图的局部二值模式LBP(Local Binary Patterns)特征提取法[7,8]和基于频率域的Gabor小波特征提取法[9]等。Gabor小波通过图像纹理表示特征信息,但Gabor变换效率低下;LBP特征,即局部二值模式特征,是通过对图像纹理灰度进行分析得到的分类能力良好的LBP特征,这类特征具有灰度不变性和旋转不变性,但在表情的表达上容易产生较高的维数,影响识别速度。以上特征提取方法都需要人工干预,且面部静态图像存在受光照变换、不同的头部姿态以及面部阻挡等干扰问题。
深度学习技术的持续发展让人们看到了深度学习在图像领域的巨大潜力,对于面部表情识别的研究也逐渐从传统手工设计特征的方式转到以深度学习技术为基础的研究,使面部表情识别技术取得了突破性进展。李勇等人[10]通过改进LeNet-5网络架构,将网络中提取到的低层次特征和高层次特征相结合作为分类器的输入,在JAFFE表情数据库上实现了94.37%的识别率;Chang等人[11]构建了一种有效的卷积神经网络提取输入图像的特征,使用复杂性感知分类算法将数据集划分为简单分类样本子空间和复杂分类样本子空间,降低了面部表情识别因环境因素而导致的复杂性;Georgescu等人[12]将卷积神经网络学习的自动特征和由视觉词袋模型计算的手工特征相融合,使用支持向量机作为分类器预测类标签;Chen等人[13]提出一种强面部特征提取方法,提取表情表达峰值与中性面部表情帧中的差值表情帧特征,保留从中性面到表情面的过渡中改变的面部部分,在表情数据集上取得了较好的识别效果。
尽管已经有许多特征提取方法,但仍然存在一些问题,例如提取的特征单一化,特征受光照变化影响等。局部二值模式(LBP)侧重于图像局部纹理特征,由于其良好的旋转不变性和光照不敏感性,被广泛用于表情识别。本文提出了一种基于改进的卷积神经网络结合CNN(Convolutional Neural Networks)特征和LBP特征的面部表情识别方法,根据面部局部和整体信息的组合可以有效地描述面部的表情特征。所提出的方法结合2种类型的特征以获得更高的识别精度,并解决了对光照的鲁棒性问题。本文的主要工作如下所示:
(1)利用多任务卷积神经网络MTCNN(Multi-Task Convolutional Neural Network)算法定位面部图像关键点,对图像进行预处理。利用多尺度多关键点采样方法提取LBP纹理特征,并通过PCA进行特征降维。
(2)设计了一种基于VGGNet的改进卷积神经网络。从卷积层获得的特征以加权方式与LBP纹理特征合并,作为最终表情分类特征。
(3)与现有的面部表情识别方法相比,在CK+和JAFFE表情数据集上进行实验。结果表明,本文方法提高了面部表情识别的准确性,验证了其有效性。
2 基本理论
2.1 LBP算子
局部二值模式LBP算子是用于描述图像局部纹理特征的算子,对纹理细节特征提取能力显著。通过比较图像的中心像素值与周围8个像素的值大小得到LBP值,图像的局部纹理特征便用此值来描述。传统的LBP算子如下所示:
(1)
其中,(x,y)是中心像素点的位置,P为采样点个数,gp是邻域像素点的像素值,gc是中心像素点的像素值。S(x)是一个符号函数,表示邻域像素点的二进制值:
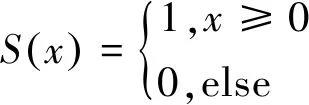
(2)
从式(1)和式(2)中提取的二进制代码被转换为十进制数,以便形成LBP图像。传统LBP算子不能满足不同尺寸的纹理特征,并且不具有旋转不变性。Ojala等人[7]提出了具有旋转不变性的 LBP 算子,并将其定义为:
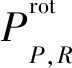
i=0,1,…,P-1}
(3)
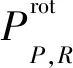
U(LBPP,R)=|S(gp-1-gc)-S(g0-gc)|+
(4)
(5)
其中,U(LBPP,R)表示0到1或1到0变化的次数,gc是矩形块中心像素的灰度值,g0,…,gP-1为中心像素邻域的P个灰度值,R为圆形邻域的半径。

Figure 1 VGG-16 network structure 图1 VGG-16网络结构
2.2 卷积神经网络
卷积神经网络CNN是一种特殊的专门用作处理具有类似网格结构数据的人工神经网络,网络前部是多个卷积和池化层的组合,最后连接多个全连接层与一个分类器作为输出,现已成为图像分析领域中的研究热点。与传统神经网络不同的是,卷积神经网络不需要网络中每个神经元与前一层的所有神经元都进行连接,其优势在于通过局部感知和权值共享可以减少网络参数。在图像特征中,每个神经元感知图像的局部信息,利用局部信息组合成图像整体信息,减少网络需要学习的参数数目;权值共享通过不同的滤波器(这种滤波器又称为卷积核)来提取图像中不同位置的不同特征的激活值。权值实际上是不同神经元之间的连接参数,权值共享的目的就是让若干个连接参数相同,再通过多个卷积核来提取图像特征,得到特征值。采样层又叫池化层,是对输入的图像的局部区域进行压缩,在降低维度的同时起到防止过拟合的作用,一般常见的采样方法为最大值(或均值)池化。牛津大学提出的VGGNet[14]网络结构,在分类任务中功能强大,也正因如此,VGGNet网络仍然被用作提取图像特征。
VGG-16由13层卷积层(conv)、3层全连接层(FC)以及Softmax输出层构成,如图1所示。所有隐层的激活单元都采用ReLU函数;使用3*3大小的卷积核来扩大通道数,以提取更复杂和更具有表达力的特征,通过零填充保证输出数据体的维度与输入相同。层与层之间使用大小为2*2,步长为2的最大池化方式进行采样,以捕获到更细微的信息,卷积核的数量随着卷积层数量的增加而增加,卷积层深度依次为64→128→256→512→512。
3 融合特征提取设计
本文提出了一种LBP特征和CNN特征相融合的表情识别方法,使网络能够学习更多具有区分性的特征,从而有效地对结果进行分类,提高识别准确性。第1类特征是LBP特征,第2类特征来自改进的卷积神经网络卷积层特征,使用自适应加权函数将它们组合以得到用于分类的特征。具体的方法框架如图2所示。
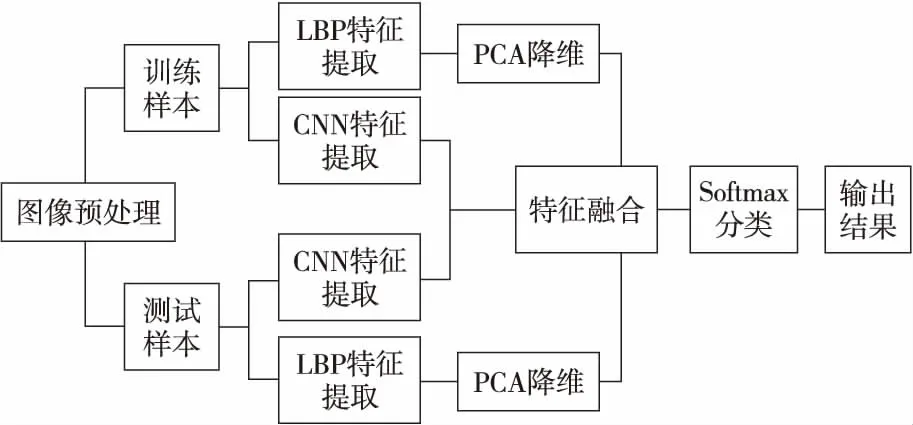
Figure 2 Framework of the proposed method图2 本文方法框架
3.1 LBP特征提取
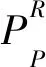
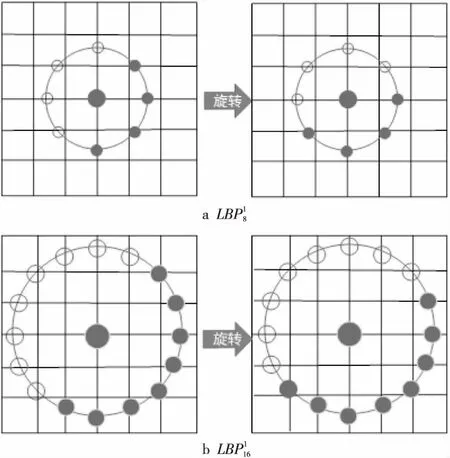
Figure 3 LBP operators of different scales图3 不同尺度的LBP算子图
在进行表情识别之前,需要通过面部检测处理来分离面部和非面部。我们使用MTCNN[15]算法对数据集中的面部表情图像进行面部检测和特征点定位。将面部表情关键点如左/右眼、鼻子、左/右嘴角作为采样区域并做仿射变换,校正面部,将面部区域图像缩放为3个不同的尺度,包括75*75,120*120,224*224像素大小。固定采样窗口的大小,即P=8,R=1。如图4所示。通过在单个关键点周围进行多尺度的采样来获取不同尺度上的局部特征,增加LBP特征的维数,并且不同的尺度使得提取到的特征既包含细节部分又拥有相对整体结构的信息,增强了特征的表达能力。考虑到数据的主要信息都集中在主成分上,因此采用无监督的主成分分析PCA方法对高维LBP特征进行降维,在降低信息的冗余度和噪声的同时尽量减小信息损失。PCA 降维处理的具体过程如下所示:
(1)设有M个面部训练样本,构成特征矩阵X,其中每个样本所对应的特征向量为xi,记为X=[x1,x2,…,xM]。则平均向量表示为:
(6)
(2)根据式(7)和式(8)将特征矩阵均值化,计算协方差矩阵P。将特征值从大到小排序取对应前k个特征向量构成矩阵U=[μ1,μ2,…,μk],其中U为经均值化后μi所组成的特征向量矩阵。经过X的k阶降维转换,得到低维空间的特征矩阵Y=X*U
(7)
(8)
由于是选取了5个关键点,采样的区域大小为4*4,使用了旋转不变的等价LBP模式将P固定为8,则 LBP模式数量为9种,再经过3次不同尺度的缩放,最终得到的LBP特征维数为2 160维(5*16*9*3)。即1个关键点区域包含432(16*9*3)维的特征向量,经过PCA方法降维后,每一个关键点区域包含60维,最终得到300(5*60)维的特征向量。通过上述步骤得到的图像特征维数与深度卷积提取的特征维数接近。
Figure 4 Face detection and multi-scale sampling LBP image图4 面部检测及多尺度采样LBP图像
3.2 改进的卷积神经网络特征提取
在VGG-16网络中,由于连续多次使用了小卷积核并且每一层的卷积核呈翻倍式增长,使得相应的输出特征映射的数量变得更多,占用了更多的存储空间。通过对原模型VGG-16进行实验发现,在第1个全连接层上会产生非常大的参数量,使得计算量巨大,消耗了更多的计算资源。此外,由于数据集的规模制约,中小规模的数据样本在深度网络上表现并不好,最后的实验结果远远低于预期,我们分析认为部分原因是数据规模较小产生的过拟合问题,导致模型泛化能力不足,并未能体现出深度网络VGG-16原有的优秀性能,而通过不同方式减少神经网络深度来减少参数量,在一定程度上是有助于防止过拟合的。受GoogleNet[16]和AlexNet[17]的启发,在高维特征图上使用大的卷积核直接降维,并没有产生过多的计算,且连续的大卷积核代替小卷积核能降低模型的复杂度,进一步压缩参数数量;减少部分全连接层并不会影响特征层的表达,反而降低了参数量。因此,本文对VGG-16结构进行以下改进:(1)在初始层的较大特征图上使用5*5卷积核,在后3层堆叠的卷积层上依旧使用3*3卷积核,有效地降低特征图占用的空间并保持模型的特征提取能力;(2)将第1层全连接层删去,直接与第2层全连接层相连,其次将剩余2个全连接层中的神经元的数量降为1 024和256,减少参数数量的同时可以促使最后一层卷积层得到的特征更具区分性,有助于提升融合效果。将改进后的网络命名为NEW-VGG,如图5所示。网络的输入数据维度为224*224*3。在网络中使用ReLU作为激活函数,并使用Dropout来解决过拟合问题。选取Softmax作为分类器用于分类任务,以估计M类中每个类标签的概率。通常,卷积神经网络需要在卷积层之后连接低维全连接层作为新特征层以减小特征尺寸,并且由卷积层获得的特征通常包含丰富的图像细节信息。因此,采用卷积层部分获得的特征作为待融合的特征。
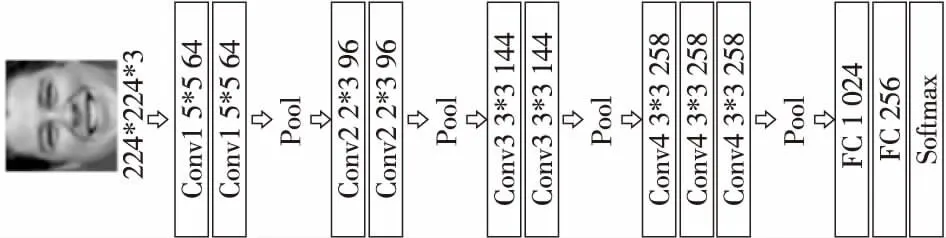
Figure 5 Improved convolutional neural network NEW-VGG图5 改进的卷积神经网络NEW-VGG
3.3 特征融合
本文采用特征向量拼接方法融合上述2种类型的特征。考虑到2个特征向量的不同尺寸将导致不同的特征点比,本文使用加权函数来融合2个向量,以生成新特征。具体的特征融合方法如下所示:
(1)LBP 特征和CNN 特征融合。
将n维LBP 特征向量记为VLj,VLj=(VL1,VL2,…,VLn);m维CNN特征向量记为VCj,VCj=(VC1,VC2,…,VCm)。新的融合特征向量Vfc=(VN1,VN2,…,VNN),VNi表示第i(i=1,…,6,代表6种基本表情)个类别,记为:
Vfc=αVCj+(1-α)VLj
(9)
其中,α是0~1的实数值,α和1-α分别对应于2种类型的特征的组合权重。假设有N个图像样本,每个样本的维度大小为D,基于表情识别共有6类。Softmax函数用于融合特征向量中估计6类中每个类标签的概率,如式(10)和式(11)所示:
(10)
(11)

(12)
根据式(10)~式(12)计算损失函数,使用基于随机梯度下降优化方法的反向传播来最小化式(13):
(13)
(2)对融合特征进行降维处理。
2种特征的融合是局部特征与全局特征的信息互补,因此存在着大量的冗余信息,这就导致融合后的新特征VNi维数很高。故本文在进行特征融合时,将网络模型最后一个全连接层的神经元数目设为256,相当于通过神经网络模型对拼接的2种特征进行降维操作,去掉冗余信息,从而产生新的有用信息。
融合后的特征具有更强的可区分性,可进一步提升特征对光照的鲁棒性,带来更好的识别效果。将融合特征输入到NEW-VGG模型的Softmax层中,可得到最终的分类识别结果。详细的融合步骤如下所示:
(1)对面部图像进行预处理。
(2)提取LBP特征。利用式(3)~式(5)在训练样本和测试样本上分别提取具有光不敏感性的 LBP特征,并采用 PCA 进行降维。
(3)对NEW-VGG网络模型参数进行初始化设置并提取CNN特征。
(4)融合2种类型特征。根据式(9)将CNN卷积层特征和 LBP 特征在 CNN 的第1层全连接层进行融合并降维。
(5)将已处理的特征导入Softmax层,以获得最终的分类结果。
(6)参数调整。根据式(9)调整特征向量参数。根据CNN网络调整权重参数,直到式(13)收敛到较小的值,调整完毕。
4 实验设计与结果分析
4.1 实验的准备工作
为了证明本文提出的特征融合的表情识别方法的有效性,本文设置了3组实验。实验数据来源于开源的JAFFE(the JApanese Female Facial Expression database)[18]和CK+(the extended Cohn-Kanade dataset)[19]表情数据集。CK+数据集用于训练好的网络模型性能测试。JAFFE数据集包含213幅图像,是10位日本女模特的7种面部表情(6种基本表情+1种中性表情)。CK+数据集包含123位受试者的593个图像序列,每个序列都在此数据集以中性表达式开头并继续达到表情顶峰,最后一幅表情都有动作单位的标签,共含6个基本面部表情。由于CK+数据集没有中性表情,故在实验过程中选取6种基本表情。考虑到数据有限以及VGG-NET网络的参数数量,本文将每种表情的标签图像进行一系列翻转、平移、旋转操作使表情样本数据增加130倍,最后使用10折交叉验证进行评估,其结果可直接反映网络训练情况和模型设计质量。2个数据集的示例集合如图6所示。

Figure 6 Examples of facial expression in JAFFE and CK+图6 JAFFE和CK+中的面部表情示例
4.2 环境配置和初始化设置
本文实验环境:台式电脑1台,CPU为Intel(R) Core(TM)i5,8 GB内存。GPU为GTX 1060。开发环境为基于Python语言的TensorFlow框架。在训练过程中,所有学习率设置为0.1,batchsize大小为1 000,动量为0.9,权重衰减为0.000 5,迭代次数设置为100,最大限制次数为10 000。使用随机梯度下降优化方法训练网络。
4.3 实验结果与分析
(1)参数α的影响分析。
为了探索参数α在融合特征中的作用,在JAFFE和CK+数据集上进行实验,以找到适合数据集的α值。我们将α的值从0逐渐增加到1,其中α=0表示融合特征中仅包含LBP特征,α=1表示融合特征中仅包含CNN特征。实验结果如图7所示。从图7中可以看出,随着α值的增加,训练模型的识别率在一定范围内逐渐增大,当权重α= 0.6时,CK+数据集上的识别准确度达到最大值,而JAFFE数据集上的准确度则在α=0.7时达到最大。后续α再变大时,2个数据集上的准确度都呈减小的趋势。这是由于当CNN特征增加时,融合特征中局部特征的比例减小,融合特征对光照的鲁棒性降低,因为当面角变化很小时,光照的影响更明显,为了减弱光照影响,本文更倾向加大融合特征中LBP特征的比重。鉴于此,最终取2个数据集上的平均准确度最大时的α值(即α固定为0.6)用于特征融合中。
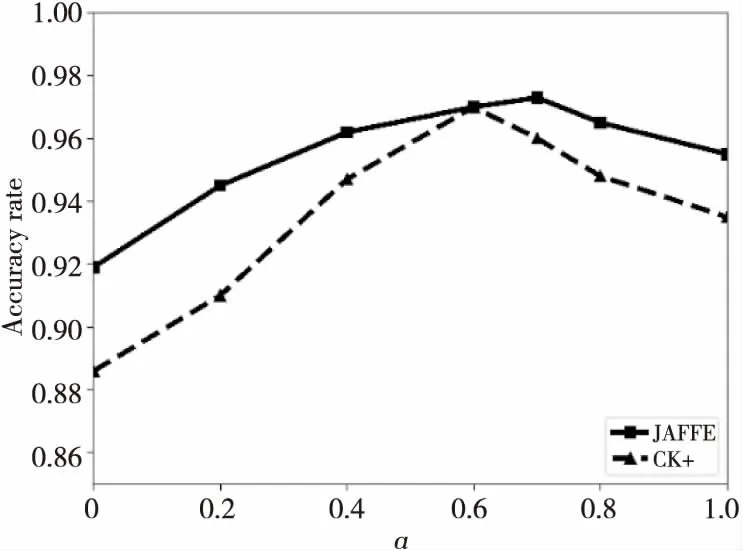
Figure 7 Evaluation of fusion weight α on different datasets图7 不同数据集上的融合权重α的评估
(2)网络模型的性能比较分析。
为了验证不同尺度数据集对NEW-VGG网络模型性能的影响,将2个增强数据集混合为1个数据集,命名为Data1数据集,共有104 780幅图像,其中80 000幅用于训练,其余用于测试,特征融合的权重α为0.6。将Data1分为100个批次,用Softmax训练该网络模型并进行反复迭代训练以减小损失值。经过反复实验发现,在初始设置20个epochs时,模型的损失值较大。上调epochs值到80之后,其损失值稳定在0.018,并且测试集上的性能也达到最高的99.15%。当设置更大的epochs迭代更多次时,平均识别准确度不再提高。我们认为NEW-VGG网络在反复迭代中学习了一些高频特征,这些高频特征对模型提升并无帮助,还会造成过拟合的状态,影响最终的分类任务,因此,该网络的性能没有进一步提高。如图8所示。
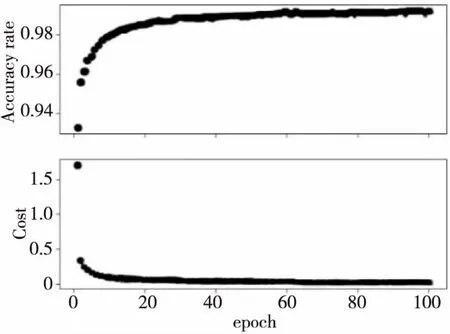
Figure 8 Training performance curve of NEW-VGG network model 图8 NEW-VGG网络模型训练性能曲线
最后,在Data1上分析了GoogleNet、VGG-16和NEW-VGG网络模型的性能。如图9所示,随着训练数据集大小的增加,3种网络的性能逐渐提高。当数据集大小达到近80 000时,NEW-VGG网络的准确度高于其他2个网络的准确度。同时发现,NEW-VGG网络架构在训练和测试速度方面明显快于其他2个网络结构,证明了NEW-VGG网络可以很好地处理更多数据,也证明了改善网络会影响面部表情识别的准确度。
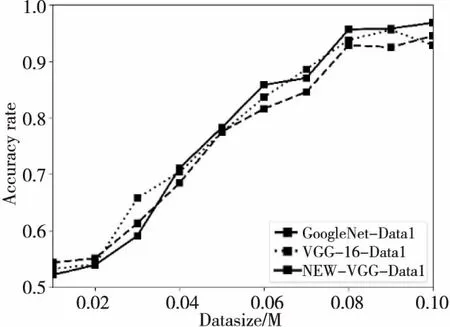
Figure 9 Recognition accuracy on different scale datasets图9 不同规模数据集上的识别准确度
(3)不同网络结构和特征维数比较分析。
为了验证不同网络结构与不同特征维数对识别效果的影响,本节使用VGG-16网络结构以及NEW-VGG网络结构在Data1数据集上进行实验,分别选取不同维数的特征用于对比识别准确度,结果如表1 所示。

Table 1 Influence of different dimensions on recognition results表1 不同特征维数对识别效果的影响 %
实验结果表明,随着特征维数的减小,2种网络识别精度并没有随之增加,反而是在128维时略微降低,说明特征维度在256时就足以表征Data1数据集,这256维特征包含了数据集里绝大部分的有效信息量。图10是2种网络结构各卷积层特征的对比图。NEW-VGG在浅层网络所提取到的纹理、细节特征要比VGG-16提取到的更丰富,尤其是一些关键特征,如眼睛特征信息等。而在更深层的网络中,NEW-VGG提取了更多的轮廓、形状等特征,特别是在最后一层卷积层得到的抽象特征,相对而言,这些特征更具有代表性。并且NEW-VGG网络没有因为简化结构使提取特征的能力下降,综上所述,本文采用256维的特征维度。

Figure 10 Features contrast of different convolutional layers of VGG-16 and NEW-VGG图10 VGG-16和NEW-VGG不同各层卷积特征图对比
(4) CK+和JAFFE数据集上的准确度分析。
本节将2个增强数据集各自进行10等分,取其中9组作为训练集,剩余1组作为测试集,进行10折交叉验证,通过这10组平均混淆矩阵得到最终的混淆矩阵。将10组数据做3种处理:一种是只将单一特征Basic_LBP(即传统LBP)用于网络训练并进行分类得到最终结果,另一种只取来自于NEW-VGG网络的特征并进行分类得到最终结果,最后一种是将Basic_LBP特征与CNN卷积层特征融合用于网络训练并进行分类得到最终结果。两者实验结果如表2~表4所示。

Table 2 Confusion matrix based on Basic_LBP feature (CK+)表2 基于Basic_LBP特征的混淆矩阵(CK+数据集) %
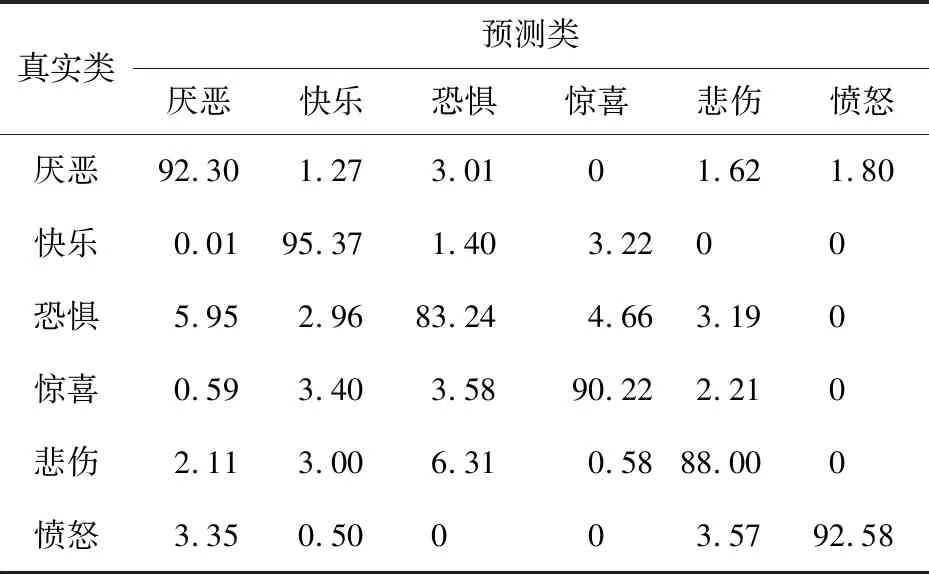
Table 3 Confusion matrix based on NEW-VGG CNN feature(CK+)表3 基于NEW-VGG的CNN特征的混淆矩阵(CK+数据集) %
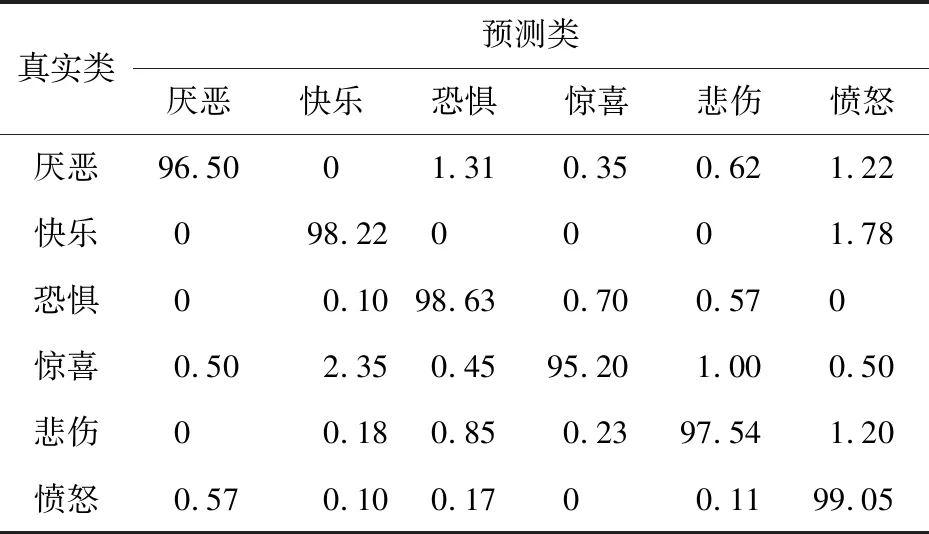
Table 4 Confusion matrix based on NEW-VGG fusion feature (CK+)表4 基于NEW-VGG的融合特征的混淆矩阵(CK+数据集) %
表2和表3是在CK+数据集上使用Basic_LBP特征和基于NEW-VGG的CNN特征计算出的混淆矩阵,表4是使用基于NEW-VGG的融合特征方法计算出的混淆矩阵。可以看出,网络在仅有LBP特征下时,最高的识别准确度来自于表达“快乐”的表情,达到了90.85%,最低的识别准确度来自于表达“恐惧”的表情,只有79.22%。平均准确度为86.51%。观察上述2表可知,“惊喜”的表情容易被错误预测为“快乐”的表情,“恐惧”的表情容易被错误预测为“惊喜”和“悲伤”的表情。这是因为在这几种面部表情中,有些面部图像中嘴巴呈闭拢状,有些面部图像中眼睛呈现惊恐状,使更注重提取局部细节的LBP特征增加了错误概率,难以进行正确的特征分类。此外,表3中的实验结果整体好于表2中的实验结果,但是仍在“恐惧”与“悲伤”表情的识别上存在特征区分不明显情况。而基于融合特征的识别方法,表情的平均识别精度为97.50%,最高的可识别表情是“愤怒”表情,达到了99.05%,增幅最大的是“恐惧”表情,增幅为19.41%。
表5和表6是在JAFFE数据集上使用Basic_LBP特征和基于NEW-VGG的CNN特征计算出的混淆矩阵,表7是使用基于NEW-VGG的融合特征方法计算出的混淆矩阵。基于Basic_LBP特征的方法获得了89.00%的平均识别准确度,“惊喜”表情的识别准确度最高(92.00%)。与Basic_LBP特征方法相比,CNN特征方法的平均识别准确度只增长了3.11%,“惊喜”与“愤怒”表情的准确度反而有所下降。反观使用融合特征的混淆矩阵,采用融合特征的识别准确度高于采用单一特征的准确度,准确度最高的仍是“惊喜”表情,达到99.85%,“恐惧”表情的识别度最低,只有95.00%,平均识别准确度达到97.62%,这个结果高于在CK+数据库上实验结果。这是因为CK+数据库中的表情图像有光照条件影响且表情姿势更加难以捕获。
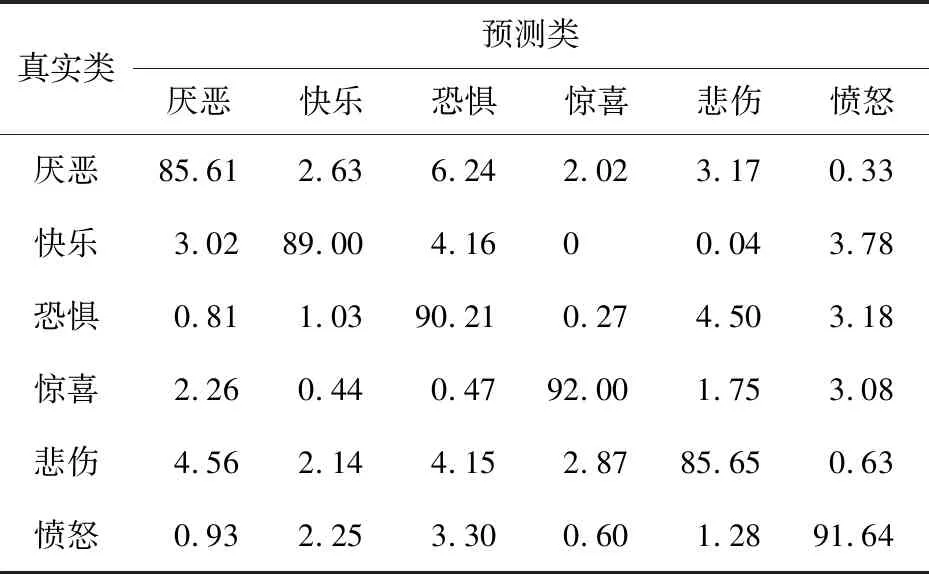
Table 5 Confusion matrix based on Basic_LBP feature (JAFFE)表5 基于Basic_LBP特征的混淆矩阵(JAFFE数据集) %
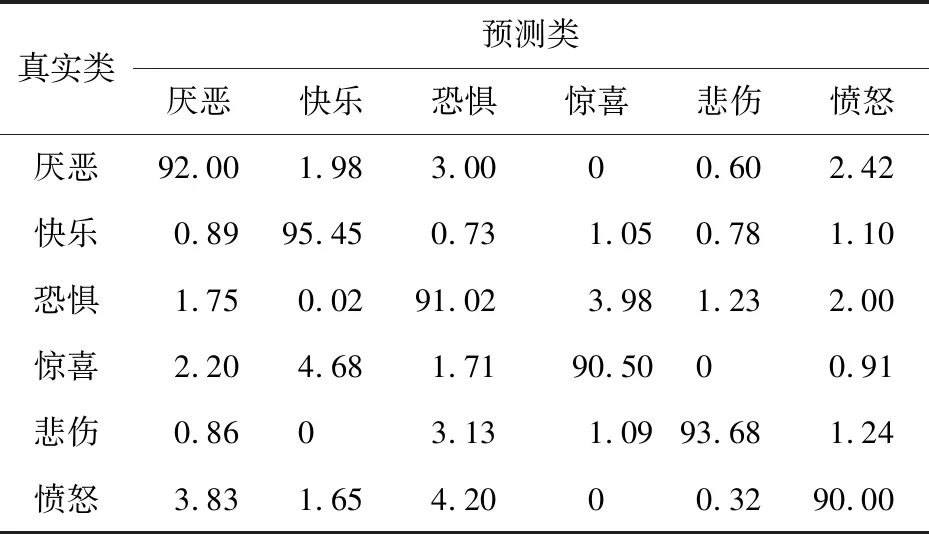
Table 6 Confusion matrix based on NEW-VGG CNN features (JAFFE)表6 基于NEW-VGG的CNN特征的混淆矩阵(JAFFE数据集) %
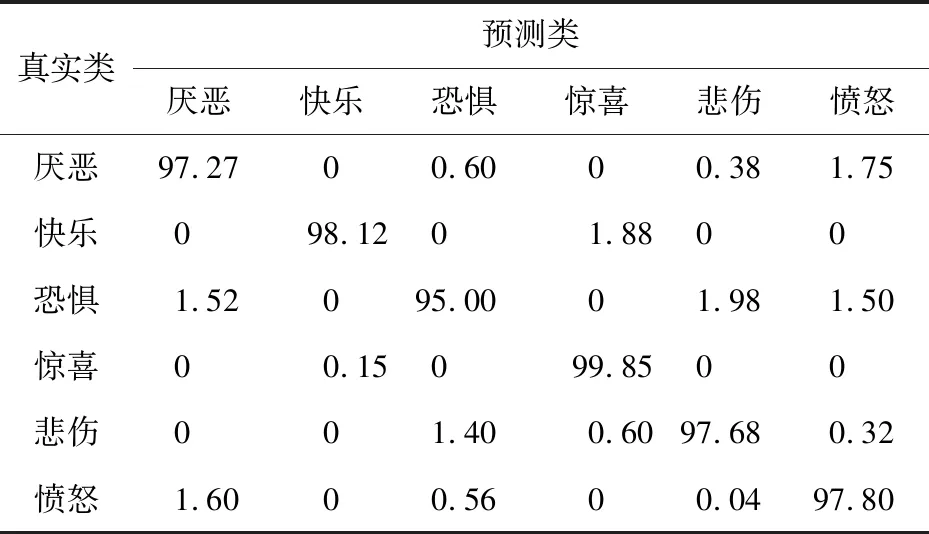
Table 7 Confusion matrix based on NEW-VGG fusion features (JAFFE)表7 基于NEW-VGG的融合特征的混淆矩阵(JAFFE数据集) %
本文还比较了在本文方法和其他现有方法2个数据集上的准确度,结果如表8所示。
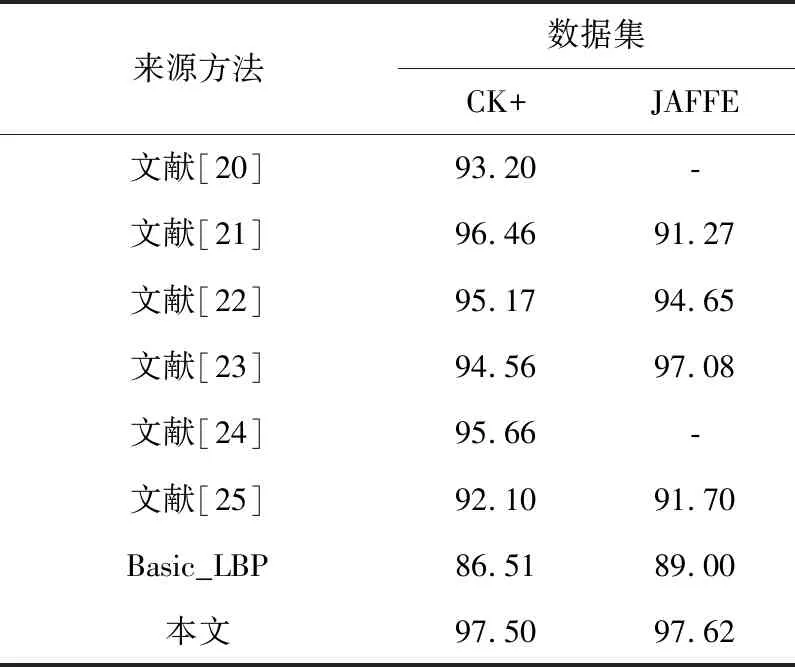
Table 8 Accuracy comparison among the proposed method and the existing methods表8 本文方法与现有方法准确度对比 %
实验对比结果表明,本文提出的特征融合方法在NEW-VGG网络的帮助下具有更好的表情分类能力,一定程度上提高了表情识别率。与没有进行CNN特征融合的Basic_LBP单一特征在CK+与JAFFE验证集上的准确度相比,其准确度分别由86.51%,89.00%达到了97.50%,97.62%。优于其他大多数方法,说明本文所提出的特征融合方法在识别不同数据集中的6个基本表情时的性能良好,有较好的泛化能力,不仅在光照变化的CK+数据集上带来性能提升,也可增强对其他变化因素的鲁棒性。
5 结束语
本文提出了一种基于NEW-VGG网络的CNN特征和LBP特征相融合的表情识别方法。一种类型特征取自LBP特征,其使用旋转不变的等价LBP模式,另一种特征取自卷积神经网络的卷积层,通过权重α融合2种特征,以便更充分地利用局部特征与全局特征信息。通过不同规模的数据集验证了改进的NEW-VGG网络的有效性,2个基准数据集上的实验验证了本文方法在识别6个基本表情方面的有效性,实现了更准确、更有效的面部表情识别,尤其是可以准确地识别“快乐”和“愤怒”,还可进一步采取微调策略来修正诸如“惊喜”和“恐惧”等错误分类情况。此外,与其他现有方法相比,本文方法在CK+和JAFFE数据集上分别达到了97.50%和97.62%的平均准确度。然而,与Li等人[26]提出的方法相比,本文的网络仅使用最基本的损失函数Softmax进行分类验证,还没有深入探讨损失函数对表情识别准确度的影响,这是未来将要开始探索和研究的内容。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电子制作(2018年19期)2018-11-14 02:37:08
建筑科技(2018年6期)2018-08-30 03:40:54
数学物理学报(2017年5期)2017-11-23 07:51:31
自动化学报(2017年11期)2017-04-04 02:52:58
中国交通信息化(2016年5期)2016-06-06 03:51:43
噪声与振动控制(2015年4期)2015-01-01 07:08:21
天津冶金(2014年4期)2014-02-28 16:52:58
机电信息(2014年35期)2014-02-27 15:54:30
