
基于机器学习的高校图书馆个性化智能推荐服务方案*
2020-03-26 02:09柳益君蔡秋茹吴智勤
图书馆研究与工作 2020年3期
柳益君 罗 烨 蔡秋茹 吴智勤 何 胜
(1.江苏理工学院计算机工程学院 江苏常州 213001)
(2.江苏理工学院图书馆 江苏常州 213001)
1 引言
个性化推荐是高校图书馆个性化服务的重要内容之一,准确而深入地了解用户是个性化推荐的前提。“互联网+”、社交网络等技术在图书馆的应用给用户分析提供了多源数据,学者们重点关注如何挖掘用户的偏好和兴趣并通过推荐服务满足之。李树青等人[1]根据图书馆借阅记录,挖掘图书阅读相关性,利用图书类别相关性链接关系,提出用户个性化模式的表达方法,从长期兴趣和短期兴趣两方面为用户提供个性化图书推荐服务。刘海鸥等人[2]融合图书馆用户的情境信息进行面向大数据的协同过滤推荐。王刚等人[3]根据用户社交行为,通过分析用户之间社交密切程度、资源使用情况和用户近期偏好因素,为用户提供个性化推荐服务。柳益君等人[4]提出一种基于社交网络分析的阅读推荐方法,发现用户的多样兴趣,进而提供主题多样性的阅读推荐服务。刘爱琴等人[5]应用SOM神经网络对用户Web访问行为进行聚类和优化,识别用户的兴趣点,进而提供主题推荐、图书推荐和专家推荐。
图书馆个性化推荐服务受到广泛关注,取得了诸多成果,但是依然面临着挑战。图书馆发展至今,文献、资料、内容日趋繁多复杂,个性化推荐服务面临的“信息过载”“信息迷航”“情感缺失”问题仍然严重。用户兴趣是情感的显性表达,用户需求则是潜在的隐性情感需要。现实中,推荐符合用户显性兴趣的资源往往并不能满足用户潜在需求。例如,一位计算机专业的学生借阅了图书《数据结构》,显示了他对“数据结构”有明显兴趣,但是如果给他推荐此类图书文献,他很可能未必需要。也许他会觉得一本《数据结构》已经够了,不需要更多,他需要的是算法分析和设计类书籍。初景利[6]指出,图书馆依附于用户而存在,用户需求是图书馆存在的基础与发展的动力。图书馆要留住用户、壮大用户群,仅着眼于用户显性兴趣是不够的,更应捕捉用户的潜在需求。分析目前的研究,推荐的个性化主要体现在满足用户的显性偏好和兴趣,对于如何满足用户的潜在需求尚缺乏深入探索。为了实现以用户为中心的推荐服务,有必要研究如何满足用户深层潜在需求,而非仅仅是显性兴趣,从而最终提供用户高满意度的个性化推荐服务。
2 机器学习在构建个性化智能推荐服务中的优势
目前,我国各行各业都在推进人工智能技术的应用。通过人工智能、大数据、物联网等现代信息技术,对行业实行颠覆性重构和革命性改造。人工智能在图书馆应用甚多,使图书馆升华为智能图书馆的新形态,图书馆服务也走向适应时代的智能服务[7-9]。在智能服务的背景下,图书馆需要提升传统推荐服务的智能化水平。个性化智能推荐服务是传统个性化服务的进一步发展,充分利用智能技术,不仅能够发现用户的显性兴趣,也能够深入挖掘用户的深层需求,实现升级的个性化推荐服务,主动为用户推荐其所需的资源,全面、深层地满足用户个性化需求,并提高资源的利用率。
作为人工智能的重要分支之一,机器学习在分析用户数据,发现用户需求,进而提供个性化智能推荐服务上有很大优势。《人工智能标准化白皮书(2018版)》指出,人工智能的特征之一是“由人类设计,为人类服务,本质为计算,基础为数据”[10],而机器学习是一种基于数据的重要智能技术。我国著名机器学习专家周志华教授[11]在专著《机器学习》中谈到,机器学习在大数据时代是必不可少的核心技术,没有机器学习技术分析数据,则数据利用无从谈起,“数据分析”是机器学习技术的舞台,各种机器学习技术已经在这个舞台上大放异彩。物联网、移动互联网、社交网络等技术在图书馆日益广泛的应用使图书馆积累了海量用户数据。用户数据中既有宏观层面群体涌现的大数据,也有微观层面个人和团体的小数据,蕴含了大量的特征、模式和关系,为用户分析提供了宝贵资源,也为机器学习提供了用武之地。
梁少博等人[12]认为,机器学习的相关工具、算法能够帮助图书馆分析用户行为数据、业务处理数据等,从而为用户提供更加智能的信息服务。张坤等人[13]指出,个性化推荐服务是机器学习在图书情报领域的重要应用之一,应用机器学习技术可以对用户的检索、阅读、浏览等记录进行识别与分析,进而判断出用户的潜在信息需求及兴趣偏好,最终提供满足用户需求的资源。机器学习在深入分析和学习用户数据,提取数据智能,进而深层地洞察用户、理解用户中有巨大的应用前景,是构建个性化智能推荐服务的支撑技术。
3 基于机器学习的个性化智能推荐服务方案
本文设计基于机器学习的图书馆个性化智能推荐服务方案,如图1所示。该方案由图书馆用户数据采集与清洗、个性化兴趣提取和需求发现、个性化智能推荐三部分组成。其中,机器学习主要用于个性化需求发现。

图1 基于机器学习的高校图书馆个性化智能推荐服务方案
3.1 用户数据采集与清洗
在数据采集与清洗阶段,全面收集高校图书馆用户数据。除了用户基本信息、借阅记录、网站行为(点击、浏览、下载、收藏等)、“互联网+”、物联网、社交网络等现代信息技术在高校图书馆的应用产生了各种新类型的用户数据。高校图书馆应用微博社交平台开展服务产生了社交数据,学校的教务系统和科研系统可以提供师生的学习数据、科研数据等,移动图书馆、眼动仪、生理监测仪等智能终端可以提供关于用户情境、生理、状态等各方面的感知数据。对多源异构的用户数据进行清洗、规范化和整合,为进一步分析用户数据并从中进行个性化兴趣提取和需求发现奠定基础。
3.2 个性化兴趣提取和需求发现
3.2.1 个性化兴趣提取
个性化显性兴趣是用户情感的显性表达,而个性化潜在需求是用户的隐性情感体现。在个性化兴趣提取和需求发现阶段,首先通过关键字提取、协同过滤、统计分析等传统的方法技术获取用户情感的显性表达,提取用户的个性化显性兴趣;然后通过机器学习技术,进行用户隐性情感挖掘,克服图书馆资源推荐服务面临的用户情感缺失的困难,发现用户的个性化潜在需求。
3.2.2 基于机器学习的个性化需求发现
图书馆用户的个性化需求发现主要包含三部分内容:当前需求挖掘、需求趋势预测、需求特征识别。①当前需求挖掘:当前需求挖掘旨在发现用户在当前较短一段时间内的需求,比如当前一个月、一周的需求,甚至一个学习或一个科研场景下的需求。②需求趋势预测:用户对资源的需求常常具有时间上和内容上的连贯性,需求趋势预测旨在根据用户当前的兴趣和需求去预测用户未来一段时期内的需求。③需求特征识别:需求特征识别旨在发现某个个体用户或某个群体用户的特有的需求,例如,一位从事数据结构课程教学的教师会需要这门课程的多种教材和教学参考书,一个研究图书馆服务的团队特别需要图书馆学、图书馆管理、读者工作等相关方向的图书、论文等文献。
采用监督学习、无监督学习、主动学习、半监督学习等机器学习方法发现个性化需求。机器学习主要研究在计算机上从数据中产生模型的算法,即学习算法,把经验数据,即训练数据提供给学习算法,学习算法就能基于这些数据产生模型,面对新情况时模型能给出判断和预测。用于机器学习的用户数据可以分为有标记和无标记两类,具有已知标签或结果的训练数据是有标记数据,反之是无标记数据。根据训练数据是否有标记信息,机器学习任务大致分为监督学习、无监督学习两大类,它们分别用于从有标记数据和无标记数据中学习。此外还有主动学习、半监督学习,用于从有标记和无标记的混合数据中学习[11]。应用各类机器学习算法在海量用户数据中进行分布探索、关系探索、特征探索、异常探索、推测探索、趋势探索等,发现高校图书馆用户在学习、科研、教学等方面潜在的个性化需求。
(1)监督学习和无监督学习在需求发现中的应用
在监督学习中,输入的训练数据具有已知标签或结果,对训练数据集进行训练以构建模型,并通过接受反馈预测对模型进行持续改进,当模型在训练数据上达到期望的精度时学习停止;在无监督学习中,训练数据没有标注已知结果,通过探索训练数据中存在的结构而生成模型,该模型可能是提取一般规则、通过数学过程减少冗余,或者通过相似性测试组织数据[14]。
从服务对象的角度看,高校图书馆个性化智能推荐服务对象可以是个体用户,比如一位学生、一位教师,也可以是某一特定用户群,比如一个科研团队。无监督学习适于在众多用户中识别特殊用户群体,并对其进行需求分析。监督学习在发现个体用户需求中更有优势,如预测用户对资源的评分或情感,克服用户的情感缺失。表1列出了常用监督学习和无监督学习算法及其在个性化需求发现中的应用。

表1 常用监督学习和无监督学习算法及其在个性化需求发现中的应用
(2)主动学习和半监督学习在需求发现中的应用
监督学习要求所有训练数据均有标记信息,而现实中图书馆的很多数据标记不完全。例如,通过推荐系统向用户推荐文献时请用户标记出需要的文献,以获取用户对于推荐结果的反馈,但并非所有的用户都愿意花时间来提供标记,愿意这么做的用户常常是少数。专门组织大量人力来标记数据显然不现实。主动学习和半监督学习为图书馆充分利用大量的未标记数据提供了方法和技术。主动学习在模型训练过程中选取一部分最有价值的数据请用户或专家进行标注,通过与外界的交互使部分未标记数据获得标记,最终不需要大量标记数据便能获得高效的模型。半监督学习同时使用未标记数据和标记数据来进行模式识别工作,建模过程不需要与用户或专家交互[11]。有了半监督学习和主动学习,大量未标记数据也可以用于图书馆用户当前需求挖掘、需求特征识别、需求趋势分析等。
3.3 个性化智能推荐
根据所提取的个性化兴趣和发现的个性化需求关联书目库、论文库、专利库、知识库等数据库中的资源,形成个性化智能推荐列表提供给用户。个性化智能推荐列表由基于个性化兴趣的推荐和基于个性化需求的推荐两部分组成,且以基于个性化需求的推荐为主。这样,兴趣和需求相结合、以需求驱动为主的个性化智能推荐服务得以实现,有助于高校图书馆获得用户高满意度。
4 基于机器学习的个性化智能推荐服务应用案例
本文以“图书推荐服务”为例,提出机器学习应用下的高校图书馆个性化智能推荐服务。应用朴素贝叶斯算法发现目标用户的当前图书需求,为其提供个性化智能图书推荐服务。
4.1 用户图书服务信息
用户U1是目标用户,即推荐服务的对象。近一个月内用户U2-U5与目标用户U1有部分相同的借阅书籍。对用户U2-U5的图书借阅记录进行分析,以发现目标用户U1的当前需求。5位用户U2-U5近一个月内图书借阅目录如表2所示,他们共借阅8本图书b1-b8。用户对图书的评分如图2所示,由于目标用户U1未借阅图书b5-b8,故对b5-b8的评分用“?”表示。评分分数有1、2、3、4、5五种,根据评分判断用户情感,若用户对图书的评分大于等于3分,则将用户对该图书的情感归为“正向”类,否则归为“负向”类。将图2用户-图书评分矩阵转换为图3用户-图书情感矩阵,用表情图表示正向和负向情感。图3展现了用户对图书的显性情感。

表2 用户图书借阅目录

图2 用户-图书评分矩阵
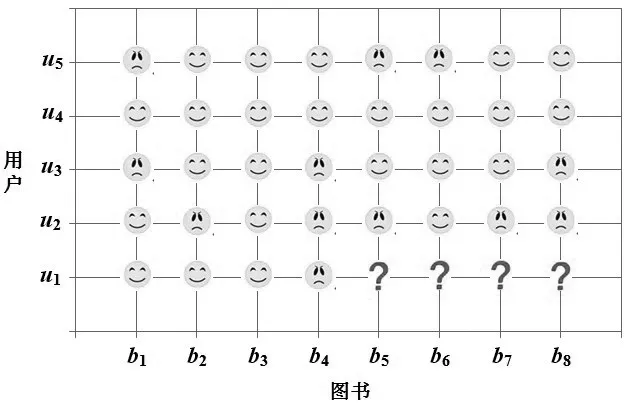
图3 用户-图书情感矩阵
个性化智能图书推荐服务兼顾用户的显性兴趣和潜在需求,首先提取目标用户显性兴趣,基于兴趣进行推荐,然后应用机器学习算法挖掘目标用户对图书资源的隐性情感,克服情感缺失,发现用户当前潜在需求,进行基于需求的推荐,最终为目标用户提供符合兴趣且以满足潜在需求为主的图书推荐。
4.2 个性化兴趣提取
由图3可见,目标用户U1对图书b1-b4表达了显性情感。U1对图书b1、b2、b3的情感是正向的,说明他对这3本图书有显性兴趣,而U1对图书b4的情感为负向,说明他对图书b4缺乏兴趣,如表3所示。
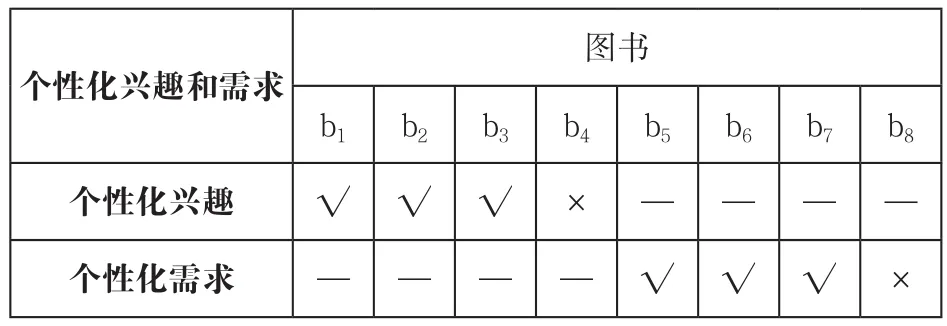
表3 目标用户的个性化兴趣和需求
4.3 基于机器学习的个性化需求发现
在众多机器学习算法中,朴素贝叶斯算法(Naive Bayes Algorithm,NBA)是一种简单有效且应用广泛的监督学习算法[15]。它基于概率论,具有数学基础坚实、分类效率稳定、对缺失数据敏感性不高等优点。在近期借阅记录数据上训练得到的朴素贝叶斯分类器可以预测用户对图书的隐性情感,进而发现用户的当前图书需求。
朴素贝叶斯算法的思想和过程如下[11]。假设类别标记集合C={ci} (i=1, 2, …, n),样本a有m个属性aj(j=1,2, …, m),朴素贝叶斯分类器采用“属性条件独立假设”,按公式(1)计算类条件概率P(ci|a):
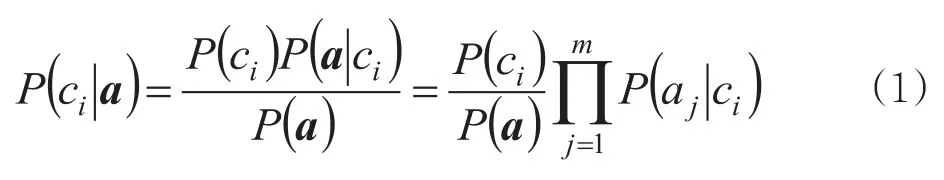
选择能使P(ci|a)最大的类别标记作为样本a的分类。由于P(a)对每个类别都相同,贝叶斯判定准则见公式(2):

训练朴素贝叶斯分类器的过程就是根据训练数据集来估计类先验概率P(ci),并为每个属性估计条件概率P(aj|ci)。
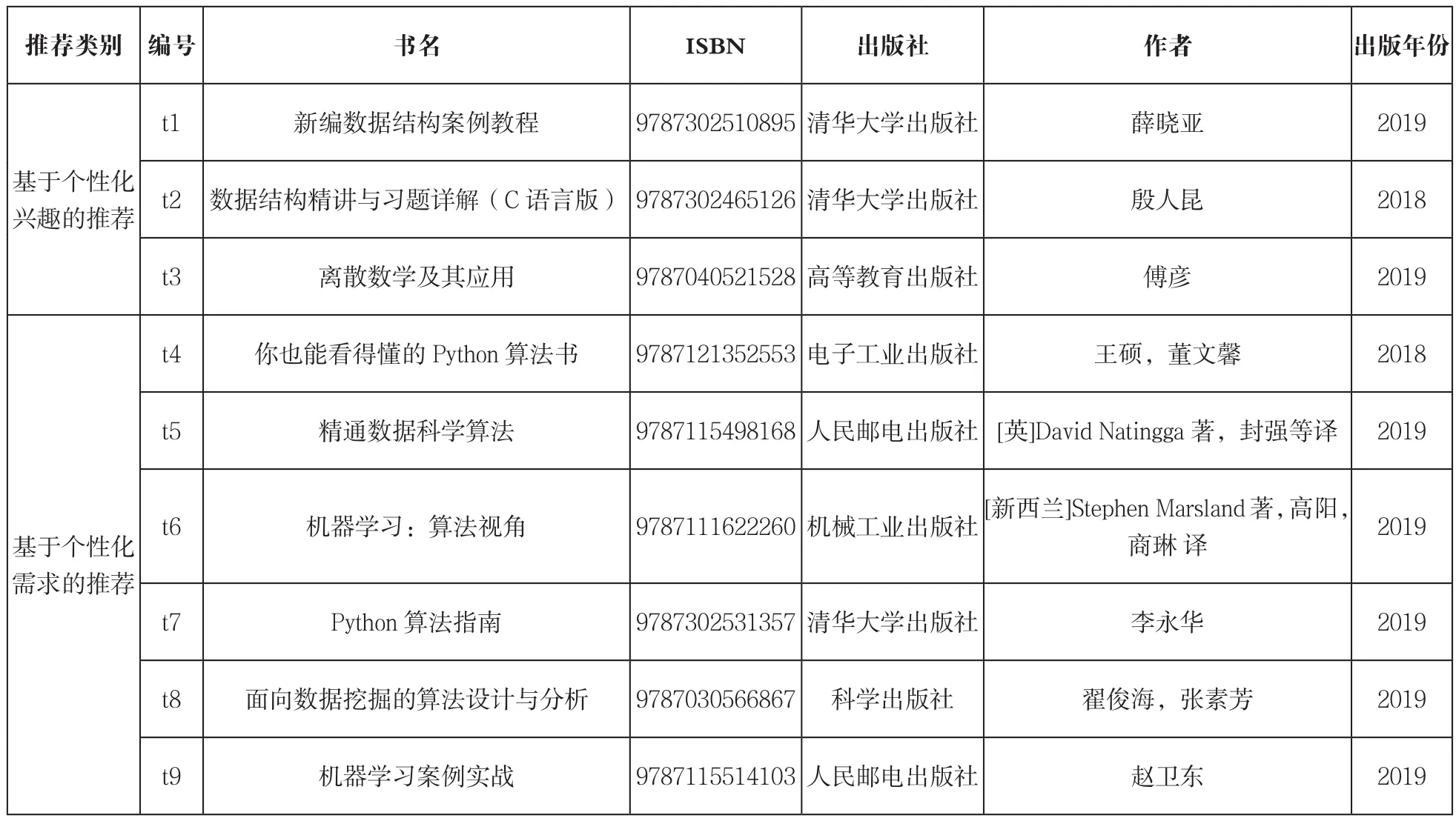
表4 个性化智能图书推荐列表
应用朴素贝叶斯算法,根据图3所示的用户-情感矩阵预测目标用户U1对未评分图书b5-b8的隐性情感,即判别隐性情感类别。情感分为“正向”和“负向”两类,类别标记集合C={C1=正,C2=负}。属性aj(j=1, 2, …, 8)表示对图书bj的情感,例如,用户U5对图书b1情感是“负向”,则用户U5这个样本在a1的属性值是“负”。由朴素贝叶斯算法判别得到目标用户U1对图书b5-b8的隐性情感依次是“正向”“正向”“正向”“负向”。U1对图书b5、b6、b7具有正向的隐性情感,说明U1对这3本图书具有潜在需求(如表3所示)。
4.4 个性化智能图书推荐结果
个性化智能图书推荐列表如表4所示,由基于个性化兴趣的推荐和基于个性化需求的推荐两部分组成,共9本图书。
由表3可知,目标用户对于图书b1、b2、b3具有个性化兴趣。采用基于图书的协同过滤得到与b1、b2、b3相似的3本图书,包括《新编数据结构案例教程》《数据结构精讲与习题详解(C语言版)》和《离散数学及其应用》,将其作为基于兴趣的推荐结果。
由表3可知,目标用户对于图书b5、b6、b7具有个性化需求。首先,将目标用户U1具有潜在需求的3本图书b5、b6、b7,即《你也能看得懂的Python算法书》《精通数据科学算法》《机器学习:算法视角》加入表4基于个性化需求的推荐部分。其次,通过协同过滤得到与图书b5、b6、b7相似的3本算法类和机器学习类图书《Python算法指南》《面向数据挖掘的算法设计与分析》和《机器学习案例实战》,也将其加入表4基于个性化需求的推荐部分。
表4所示的推荐列表不仅考虑到了用户个性化显性兴趣,更洞察了用户对图书的隐性情感,为其推荐满足当前个性化潜在需求的图书,因此获得了目标用户的高满意度。
5 结语
机器学习是人工智能最重要的分支之一,已经有效应用于互联网搜索、医学数据分析、客户信息分析、天气预报等诸多领域,也必将在智能图书馆建设和图书馆智能服务构建中发挥重要作用。本文对应用机器学习技术构建图书馆个性化智能推荐服务进行探讨,提出了基于机器学习的个性化智能推荐服务方案,以传统统计分析、协同过滤、关键字提取等方法从用户数据发现个性化显性兴趣,以机器学习方法进行用户的个性化当前需求挖掘、需求特征识别、需求趋势分析等,为用户提供合乎兴趣而又满足潜在需求的智能推荐服务。最后给出图书推荐服务的案例,应用经典机器学习算法之一的朴素贝叶斯算法在近期借阅记录中提取显性化兴趣并发现当前潜在需求,为用户高满意度的个性化智能推荐服务。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
成都信息工程大学学报(2021年3期)2021-11-22
南风(2020年22期)2020-09-15
文苑(2020年4期)2020-05-30
小学生优秀作文(低年级)(2019年5期)2019-04-25
电影(2018年8期)2018-09-21
小学阅读指南·低年级版(2017年12期)2017-12-26
汽车与新动力(2016年6期)2017-01-04
小天使·四年级语数英综合(2015年7期)2015-07-06
