
基于可见光图像和红外图像决策级融合的目标检测算法
2020-03-26 05:36侯志强刘晓义马素刚余旺盛
空军工程大学学报 2020年6期
白 玉, 侯志强, 刘晓义, 马素刚, 余旺盛, 蒲 磊
(1.西安邮电大学计算机学院, 西安, 710121;2.西安邮电大学陕西省网络数据分析与智能处理重点实验室, 西安, 710121;3.空军工程大学信息与导航学院, 西安, 710077)
目标检测作为计算机视觉领域的重要研究内容,广泛应用于目标跟踪、行人识别、医学图像、视频监控和智能机器等方面[1-5]。目标检测的主要任务是对图像中预定义类别的实例目标进行高效、精确的识别与定位。
近年来,随着深度学习技术的迅速发展,出现了越来越多与之相关的目标检测算法。按照是否有区域候选框(Region Proposals)生成阶段,可以将基于深度学习的检测算法分成2类:基于区域候选框的检测算法和非基于区域候选框的检测算法。基于区域候选框的检测算法首先生成区域候选框,然后使用深度学习网络进行特征提取,以获得特征对应的类别信息和坐标信息。这类算法的检测精度较高,但是速度较慢,主要算法有SPP-NET[6]和Faster R-CNN[7]等。非基于区域候选框的检测算法不产生候选框,直接使用深度学习网络对图像中每个位置存在目标的可能性进行预测。这类算法具有速度快、泛化能力强等优点,主要算法有SSD[8]和YOLOv3[9]等。
以上所有的目标检测算法均是对可见光图像进行检测,但在一些特殊场景中,红外图像比可见光图像的表现更好。与可见光图像相比,红外图像主要呈现目标的温度信息,能够抵抗遮挡等情况,在一些光照不足的环境或者隐蔽场合中,能够很好地突出目标,例如,夜间监控场景下的行人和复杂海天背景下的船舶等。检测算法可以使用在精度和速度方面都有很好表现的基于深度学习的目标检测算法[10-11]。但是,红外图像存在对比度较低、细节信息缺失严重等问题,因此,将可见光图像和红外图像进行融合可以实现信息互补,以达到提高检测精度的目的。
为了实现这一目标,针对可以同时获取可见光图像和红外图像的应用场景,本文提出了一种基于决策级融合的目标检测算法,主要工作如下:建立并标注了包含可见光图像和红外图像的实验数据集,用于重新训练YOLOv3网络。提出了基于决策级图像融合的方式,用于对可见光图像和红外图像的检测结果进行融合,并将融合后的检测结果作为对应的融合图像中目标的检测结果,从而实现对融合图像的准确检测。通过实验验证,将本文算法和其他算法的检测结果进行对比,本文算法可以检测到更多的目标并且减少误检,进而提高目标检测的准确性。
1 检测网络与融合方式
1.1 YOLOv3检测算法
YOLOv3网络通过主体网络Darknet-53进行特征提取,并使用检测网络进行多尺度预测。其中,Darknet-53在全卷积的基础上添加了残差(Residual)结构[12],残差层的结构如图1所示,带加号的圈表示相加的操作,表示如下:
R(x)=x+F(x)
(1)
式中:x和F(x)分别是残差层的输入,F(x)是x经过2次卷积之后得到的结果。
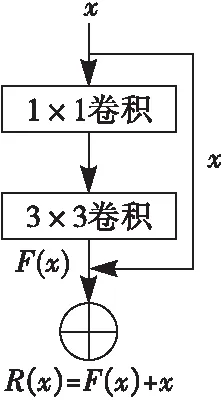
图1 残差层结构图
在Darknet-53之后使用特征交互层,在每个特征图上预测3个锚点框(Anchor Boxes),进而实现目标位置的预测。在输出预测结果之前,先进行特征融合,使用步长为2的卷积操作进行下采样,然后对得到的特征图进行拼接,使特征获得更加丰富的语义信息。
在特征图中,每个像素点网格预测3个边界框,如图2[9]所示。其中,cx和cy分别是网格的坐标偏移量,bx和by分别是边界框中心点的横坐标和纵坐标,bw和bh分别是边界框的宽和高,pw和ph分别是预设的锚点框映射到特征图中的宽和高,σ是sigmoid函数,tx和ty分别是网络预测的目标中心点的横坐标和纵坐标,tw和th分别是网络预测的目标的宽和高。
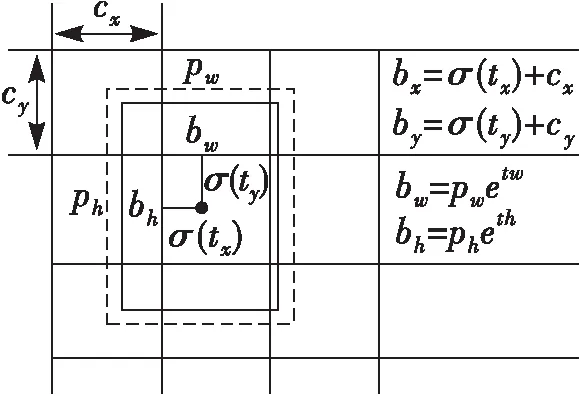
图2 边界框预测
最后,使用非极大值抑制(Non Maximum Suppression, NMS)算法[13]对边界框进行筛选,获得最终的目标边界框。
1.2 图像融合方式
图像融合是通过对多个原图像的信息进行相加得到融合图像,然后对融合图像进行分析处理的过程。根据融合处理的特点和抽象程度,将图像融合方式[14-15]分为3类:像素级图像融合、特征级图像融合和决策级图像融合。
像素级图像融合是指选取融合策略对严格配准的源图像的像素点进行处理,从而得到融合图像的过程,例如使用基于金字塔变换[16]和小波变化[17]这类算法。这种融合方式的准确性较高,但是对像素之间的关系考虑不够全面,处理时的计算量较大,容易产生大量的冗余信息。
特征级图像融合是指提取源图像中感兴趣区域的目标特征,并对这些特征信息进行融合,最后得到融合图像的过程,例如使用文献[12,18]这类算法。在特征提取过程中,只保留重要的信息,对于不重要的信息和冗余的信息通常借助降维等方式去除。这种融合方式压缩了源图像的信息,计算速度有明显提升,但是会丢失一些细节信息。
决策级图像融合是一种基于认知模型的融合方式,以特征提取为基础,对图像的特征信息进行识别和判断,并根据实际需要,选择合适的决策方式对图像进行全局最优处理的过程,例如使用文献[19-20]这类算法。这种融合方式的算法复杂度不高,具有一定的灵活性,针对特殊场景更加容易实现,容错能力强。本文使用了决策级融合方式对可见光图像和红外图像的检测结果进行融合。
2 基于决策级融合的检测算法
本文提出的基于决策级融合的目标检测算法主要包括3个部分:建立实验数据集;使用YOLOv3作为基础网络对可见光图像和红外图像分别进行检测;设计决策级融合方式对检测结果进行融合。
2.1 数据集的构建
2.1.1 数据集的分类
实验使用的图像均来源于李成龙团队建立的RGBT210数据集[21],从该数据集中选取了5 105幅可见光图像和相应的5 105幅红外图像,并确定了10类目标,分别为“kite”“dog”“car”“toy”“ball”“plant”“person”“bicycle”“umbrella”和“motorcycle”。表1为实验数据集中10类目标的占比情况。

表1 数据集目标占比情况
2.1.2 数据集的处理
本文使用标注工具LabelImg进行图像标注,以不同颜色和尺寸的矩形框确定目标的类别和位置。为了提高实验数据的数量,通过加噪、改变图像对比度和直方图均衡化等图像增强方式对原始图像进行处理,共获得了15 315幅可见光图像和相应的15 315幅红外图像,并从中随机选取了对应的12 000 幅图像作为训练集图像,3 315幅图像作为测试集图像。
2.1.3 标注结果样例
图3为实验数据集中4组图像的标注结果图,从图中可以看出,对图像中不同位置和不同尺寸的目标“car”和“person”进行了标注。其中,第1行是可见光图像的标注结果图,第2行是与可见光图像分别对应的红外图像的标注结果图。

图3 数据集标注结果样例
2.2 网络训练与融合前检测
由于红外图像和可见光图像携带不同的信息,存在一定的差异性,而且YOLOv3网络的预训练模型是通过对可见光图像进行训练得到的,不适用于对红外图像进行检测。因此,为了保证检测结果的准确性,本文使用可见光图像数据集和红外图像数据集中的训练集分别对YOLOv3网络进行训练。
在进行网络训练之前,修改目标类别为10,初学习率为0.000 01,批尺寸(BatchSize)为64,迭代次数为500 000次。然后,进行代码编译,编译通过后开始训练,并对训练过程中生成的模型进行保存。最后,使用训练完成的网络模型对相应的可见光图像测试集和红外图像测试集进行目标检测。
2.3 决策级融合
为了更好地表达本文提出的决策级融合的设计思路,下面以可见光图像中某一目标A的实际检测结果为例进行详细说明。
2.3.1 判定目标A是否在可见光图像中被准确检测
如果目标A的检测框的置信度小于阈值α,说明检测结果不准确,则舍弃该结果;如果检测框的置信度大于或等于设定的阈值α,说明检测结果准确,并保留该结果。
Dbv≥α,IoU(bv,br)<β
(2)
式中:Dbv是bv的置信度;bv和br分别是目标A的检测框和相应的红外图像中与目标A同类别的检测框;IoU(bv,br)是bv和br的交并比;α和β均为阈值。
这种方法同样适用于判定红外图像中某一目标的实际检测结果是否准确的情况。其中,阈值α(0≤α≤1,步长为0.1)的选择见表2。

表2 选择阈值α
从表2可以看出,当α≥0.5时,算法的平均准确度较高并呈现递增趋势,因此,当目标A的检测框的置信度大于或等于0.5时,表明目标A的检测结果是准确的。
2.3.2 判定目标A是否在红外图像中被准确检测
结合式(2),在确保目标A在可见光图像中的检测结果是准确的前提下,从相应的红外图像中选择与目标A的检测框类别相同的检测框,并计算这些检测框与目标A的检测框的交并比IoU。如果IoU<β,说明红外图像中的这些检测框检测的不是目标A,即目标A只在可见光图像中被准确检测到,并将该结果作为融合图像中对应目标的检测结果;如果IoU≥β,说明红外图像的这些检测框中存在目标A的检测框,进而从中选择与目标A的检测框的中心点距离最小且置信度大于或等于阈值α的检测框,则该检测框为目标A在红外图像中的检测框,即目标A在可见光图像和红外图像中被同时准确检测到。这种方法同样适用于判定在红外图像中被准确检测到的某一目标是否在相应的可见光图像中被准确检测。其中,阈值β(0≤β≤1,步长为0.1)的选择如表3所示。
Dbv≥α,Dbr1≥α,IoU(bv,br)≥β
(3)
式中:Dbr1是br1的置信度;br1是与bv的中心点距离最小且置信度大于或等于阈值α的检测框;α=0.5,β=0.6。
从表3可以看出,当β≥0.6时,算法的平均准确度较高并呈现递增趋势。

表3 选择阈值β
2.3.3 加权融合目标A的检测结果
本文通过加权融合的方式对可见光图像和红外图像中同时准确检测到的目标A的检测框位置进行融合,从而得到融合图像中对应目标的准确检测框位置。其中,加权融合的计算表示为:
Rf=θvRv+θrRr
(4)
式中:Rv和Rr分别是可见光图像和红外图像中目标A的准确检测框位置;θv和θr分别是Rv和Rr对应的权值;Rf是目标A在融合图像中对应目标的检测框位置。
加权融合的过程如表4所示。本文以不同权值组合下得到的检测结果对应的平均准确度作为判断依据,选择最高的平均准确度对应的权值组合,表中粗体数据为最优的平均准确度。

表4 不同权值组合下的平均准确度对比
从表4可以看出,当θv=0.7,θr=0.3时,可见光图像和红外图像中同一目标的检测结果的平均准确度最高。因此,本文选择θv=0.7,θr=0.3作为最终的权值组合,通过式(5)对目标准确检测结果进行合并:
U=U1+U2
(5)
式中:U1是只在可见光图像或只在红外图像中检测到的所有目标的准确结果;U2是在可见光图像和红外图像中同时检测到的所有目标的准确结果;U是可见光图像和红外图像的融合图像中所有对应目标的准确检测结果。
综上可知,本文使用的决策级融合方式,不仅对目标检测结果的准确性进行判断,而且对准确的检测结果进行了处理,最终获得了融合图像中目标的准确检测结果。
2.4 算法整体框架
本文算法的具体步骤见表5,检测过程见图4。

表5 一种基于决策级融合的目标检测算法
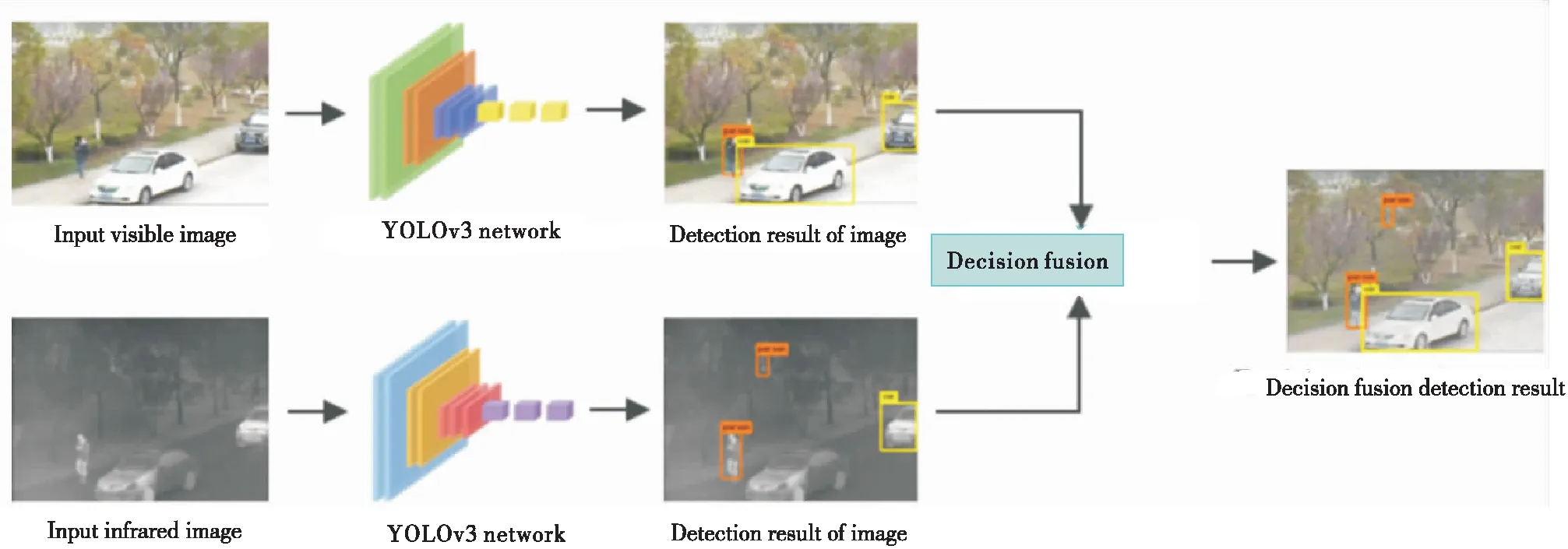
图4 本文算法框架
3 实验结果与分析
为了验证本文算法的有效性,在Ubuntu 18.04,64位操作系统和NVIDIA GeForce GTX 1080Ti的处理器下搭建Darknet-53框架和MATLAB环境进行实验。使用平均准确度(mean Average Precision,mAP)、召回率(Recall)、F1分数和检测速度(Frame Per Second,FPS)作为评价指标,从定性和定量2个方面对算法的检测性能进行分析。
3.1 定性分析
为了验证决策级融合算法在目标检测过程中的有效性,将本文算法的检测结果与使用YOLOv3网络分别检测可见光图像和红外图像的结果进行比较,如图5所示。从图5可以看出,YOLOv3网络检测可见光图像时漏检了远处的“person”,网络检测红外图像漏检了“car”,本文算法在对应的融合图像中同时检测到了漏检的“person”和“car”。YOLOv3网络检测可见光图像漏检了左下方的“person”,检测红外图像时漏检了与可见光图像不同的另一个“person”,而且出现了误检“car”的情况,本文算法在对应的融合图像中不仅同时检测到了2个漏检的“person”,而且修正了误检目标的情况。
为了进一步验证本文算法的检测优势,将本文算法与其他算法的检测结果进行对比,由于目前没有通用的决策级融合目标检测算法,因此,将本文算法的检测结果与3种基于特征级图像融合的检测算法的结果进行比较,如图6所示。
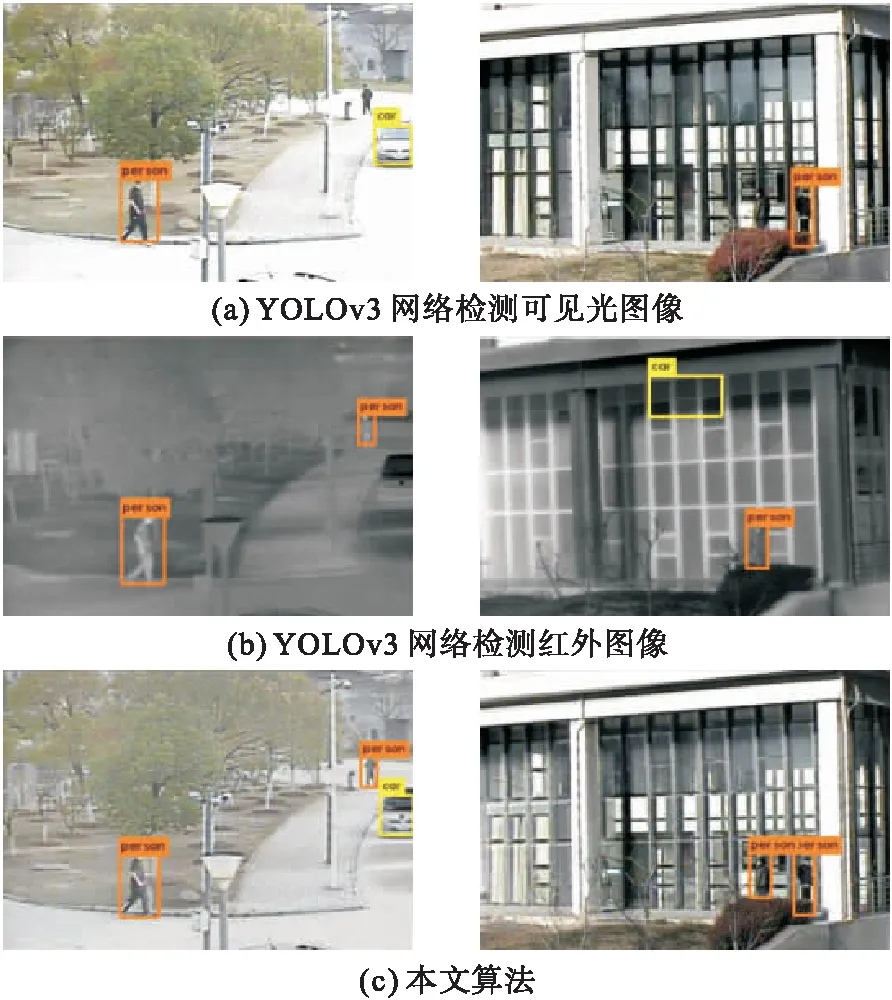
图5 实验结果对比

图6 本文算法与3种基于特征级图像融合的检测算法的实验结果对比
图6中,基于特征级图像融合的检测算法分别为先使用VSM-and-WLS算法[22]进行图像融合,再使用YOLOv3网络对融合图像进行检测(VSM-and-WLS+YOLOv3);先使用LatLRR算法[23]进行图像融合,再使用YOLOv3网络对融合图像进行检测(LatLRR+YOLOv3);先使用DenseFuse算法[24]进行图像融合,再使用YOLOv3网络对融合图像进行检测(DenseFuse+YOLOv3)。
从图6可以看出,VSM-and-WLS、LatLRR和DenseFuse算法在对融合图像进行检测时,均出现了漏检目标的情况,或检测不够准确。本文算法检测到了图像中的所有目标,降低了目标的漏检率。本文算法不仅检测到了所有漏检的目标,而且提高了检测的准确性。
从以上图例的检测结果可以看出,决策级融合检测算法与单独检测可见光图像和红外图像的算法相比,减少了漏检和误检目标的情况;与基于特征级图像融合的检测算法相比,检测性能也均有提升,说明本文算法具有一定的优势。
3.2 定量分析
通过比较本文算法和5种算法在相同测试集下的检测结果,进一步分析验证了本文算法的检测性能,结果见表6。粗体为最优的目标检测结果。
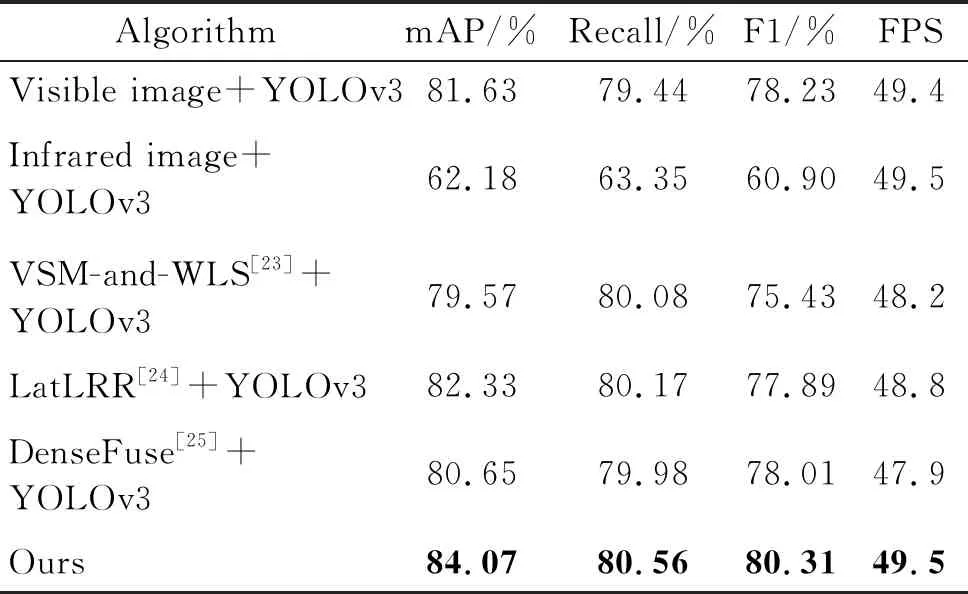
表6 本文算法与5种算法的检测性能对比
从表6可以看出,与单独检测可见光图像和红外图像的算法相比,本文算法的检测精度分别提升了2.44%和21.89%,召回率分别提升了1.12%和17.21%;与3种基于特征级融合检测的算法相比,算法的检测精度分别提升了4.5%、1.74%和3.42%,召回率分别提升了0.48%、0.39%和0.58%;同时,F1分数和速度均有较好的表现。通过实验比较可以证明,本文提出的基于决策级融合的目标检测算法可以对融合图像进行准确的目标检测。
4 结语
本文对可见光图像和红外图像的融合检测问题进行了研究,提出了一种基于决策级融合的目标检测算法。算法在使用YOLOv3网络对可见光图像和红外图像分别进行训练的基础上,借助基于决策级融合的方式对目标检测结果进行处理,进而获得了融合图像的准确检测结果。相较于其他算法,本文算法的检测性能均有不同程度的提升,实现了对融合图像的准确检测。在融合过程中,本文使用的手工选择阈值和权重的方式存在一定的局限性,在接下来的工作中,我们将对融合策略进行改进,考虑加入自适应学习过程,并且使用更多的数据集进行实验,在保证算法鲁棒性的基础上,进一步提高目标检测的性能。
猜你喜欢
环球时报(2022-05-23)2022-05-23
成都信息工程大学学报(2021年3期)2021-11-22
纺织科学研究(2021年9期)2021-10-14
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
金桥(2021年4期)2021-05-21
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
决策(2018年8期)2018-12-10
决策(2018年11期)2018-11-28
