
基于BiGRU 与方面注意力模块的情感分类方法
2020-03-24 03:49宋焕民张云华
智能计算机与应用 2020年11期
宋焕民,张云华
(浙江理工大学 信息学院,杭州 310018)
0 引言
方面级别的情感分类是情感分析中的一项细粒度任务[1],它能够提供更完整,更深入的结果。本文在方面级别的情感分类任务中发现,句子的情感极性与句子内容以及所属的方面高度相关。例如,句子“I liked the service and the staff,but not the food”中包含“service”和“food”两个方面。“service”方面它是积极的,而在“food”方面则是消极的。同一个句子中不同方面的情感极性可能不同,甚至是相反的。神经网络已在各种NLP(Natural Language Processing)任务中达到了非常好的性能[2]。如机器翻译、语义识别和智能问答等。但是,处理方面级别情感分类的神经网络模型还处在初期阶段。Zhou等人[3]提出基于特定方面的关系分类模型;Liu 等人[4]利用区域卷积神经网络和分层长短期记忆网络结合的深度分层网络模型,处理方面情感分析任务。现有方法可以提取特定方面的隐藏特征信息,但每次只能处理句子的一个特定方面。对于包含多个不同方面的句子需要重复输入,存在计算及训练时间过长的问题。
为了解决上述问题,本文提出基于BiGRU 结合方面注意力模块[5]的情感分类模型。首先采用双向GRU 神经网络编码输入,然后使用多个方面注意力模块解码获得分类结果。解码时,多个方面注意力模块可以同时对句子中不同方面进行情感分类,解决了传统方法重复输入的问题。将句子的输入向量通过BiGRU 层编码,缩短了模型的训练时间;BiGRU 层的输出向量结合注意力机制,能充分提取句子的关键信息,取得更好的分类效果。
1 相关工作
机器学习的方法已较广泛地被用于方面级情感分析任务。如Vo 等人[6]采用多种词向量、情感词典和池化函数,以自动特征抽取方式,提取对应方面的情感极性。Kirit 等人[7]采用情感词典结合SVM 的方式,抽取方面级的情感极性。但是,机器学习方法基于复杂的特征工程,且依赖于大规模的文本预处理。
近年来,深度学习在自然语言处理任务中表现优异,相比机器学习方法,极大的减轻了模型对特征工程的依赖,是目前处理情感分类问题的主流方法。如Tang 等人[8]提出的以目标词为中心,将文本拆分为两部分,分别以正序和倒序输入到LSTM 中的TD-LSTM 模型。相比传统的LSTM 模型不仅效果更佳,且提出的TC-LSTM 模型在TD-LSTM 的基础上,让目标词与上下文之间关联,能达到更好的效果。Bao 等人[9]提出了基于双向LSTM 网络和词语位置信息权重建模模型,相较于传统LSTM 模型及利用手工特征的机器学习算法效果更好。Wang 等人[10]提出基于注意力机制的LSTM-ATT 模型,该模型能够根据不同方面关注句子的不同部分,在方面级情感分析任务中取得了较好的效果。Augenstein等人[11]提出的BiLSTM 网络模型,能同时捕捉词语的前后时序关系,获得词语间的前后依赖关系。刘洋等人[12]基于GRU 网络对时间序列建模,有效提高了预测的准确性;李骁等人[13]采用BiGRU 网络处理互联网信息输入序列,能快速准确的提取信息;Rozentald 等人[14]提出了BiGRU 网络结合卷积神经网络的模型,经过多次池化操作再提取文本特征信息进行文本分类。
综上所述,相关工作大多集中在BiLSTM 或BiGRU 神经网络结合attention 模型的研究上,且在情感分类任务上有不错的表现。本文方法是以前人研究成果为基础,采用结构简单、计算量少、所需存储空间小的BiGRU 神经网络和方面注意力模块混合的网络模型,用于方面情感分析。该方法能使句子中的不同方面同时输入模型并同时处理,为此采用了多个方面注意力模块。每个方面注意力模块具有独立的方面信息及注意力参数,能对特定方面的特征信息进行提取,能够很好的识别不同方面的情感极性。
2 相关技术及BiGRU-AAM 模型
2.1 相关技术
2.1.1 GRU
由于LSTM 内部结构复杂计算量大,在模型训练上不仅需要的时间长,而且模型所需参数也较多。2014 年GRU 模型被提出,其模型结构如图1 所示。

图1 GRU 神经元结构Fig.1 GRU neuron structure
GRU 模型结构简单,收敛性好;合并了LSTM的隐层状态和单元状态,需要更少的参数,且效果不低于LSTM 模型。该模型由两个门控单元组成,一个门控控制更新,另一个门控控制重置。更新控制被带入的前一时刻的状态信息程度;重置控制前一时刻的隐层信息被忽略的程度,忽略的信息越多值越小。GRU 模型更新方式如下:

其中,zt为更新门控在t时刻的状态;rt为重置门控在t时刻的状态;ht'是t时刻对应的候选激活状态;ht是t时刻的激活状态;ht-1是(t -1)时刻的隐层状态。
2.1.2 BiGRU
文本情感分类任务中,要求模型能充分学习文本上下文的信息,将前一时刻的状态及后一时刻的状态关联,得出当前时刻的状态,以提取文本深层次的特征。BiGRU 是由两个单向的、方向相反的GRU 构成。每一时刻,两个方向相反的GRU 同时处理输入,共同决定当前时刻的输出。图2 展示了一个沿着时间展开的BiGRU 网络,其中每个时间步t的输入为xt。
如图2 所示,把BiGRU 看作两个单向的GRU,则前向隐层状态和反向隐层状态加权求和,得到t时刻的隐层状态。相关计算如式(5)-式(7):

公式中的GRU()函数表示对输入的词向量进行非线性变换,对词向量编码,得到对应的隐层状态;wt是t时刻双向GRU的前向隐层状态的权重,vt是相应的反向隐层状态的权重;bt是t时刻隐层状态的偏置。

图2 BiGRU 神经网络结构Fig.2 BiGRU neural network structure
2.2 BiGRU-AAM 模型
BiGRU -AAM 模型是一个编码解码器结构,如图3 所示。输入层和BiGRU 层是编码器部分,解码器部分是由多个方面注意力模块构成。
该方法由如下几步完成:
(1)输入
对输入进行预处理,通过词嵌入操作,用词向量表示每个词。
(2)BiGRU 层
BiGRU 神经网络从2 个方向对输入进行语义特征提取,得到每个时间步上的隐层状态和句子的向量表示。
(3)方面注意力模块
BiGRU 层输出的隐层状态结合方面信息,通过注意力操作,可以得到句子特定方面的向量表示。
(4)输出
特定方面的向量表示在全连接层利用softmax函数处理,得到句子的最终分类结果。
本文的情感分类任务是判断输入句子中的各个方面的情感极性。每个方面信息投影为一个多维连续的值向量,第i个方面的方面向量可以表示为va,i∈Uk,k是方面向量的维度。
2.2.1 编码器
编码器部分提取句子的语义特征,包括向前和向后的两个方向。通过BiGRU 网络,获取第t个时间步上的隐藏层状态ht,对于长度为n的句子,隐藏层输出矩阵为:H=[h1,h2,…,hn],即H∈Ud x n。其中,ht∈Ud,d为BiGRU 输出维度。利用式(8)计算句子的整体向量vs。
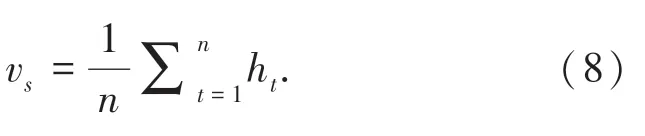
2.2.2 解码器
解码器部分是多个方面注意力模块,分别对应数据集的不同方面。对于包含多个方面的句子,编码获得的输出H分别送入对应的方面注意力模块中。方面向量va,i是每个方面注意力模块中的方面信息。各个方面的注意力模块独立执行操作,提取特定方面的隐藏特征。方面注意力模块由注意力部分、概率部分及重构部分组成,结构如图4 所示。

图4 方面注意力模块Fig.4 Aspect attention module
注意力部分将方面向量va,i与输入H中的各个隐层状态拼接,然后执行注意力操作。加权平均获的特定方面文本的向量用vc,i表示,计算公式如下:

其中,i表示第i个方面注意力模块;Wa,i∈Ud + k表示注意力的权重矩阵;b a,i∈U表示注意力的偏置。
概率部分得到各个情感极性的分类概率。特定方面文本的向量vc,i经过全连接层,由softmax 函数计算输入样本在每个分类上的概率并输出。计算公式如下:
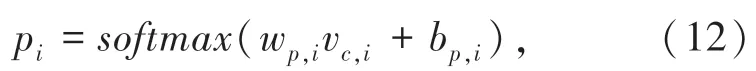
其中,pi=[p i,1,pi,2,…,p i,C];Wp,i∈UC×d是全连接层的权重矩阵;bp,i∈UC是全连接层的偏置;c是类别数。
重构部分对有关特定方面文本的向量vc,i进行重构,得到句子整体向量vs在特定方面的情感分类的新向量。通过分类概率对vc,i重构,可以获得多个重构文本,重构文本的向量ri=[ri,1,ri,2,…,ri,C],计算公式如下:

其中,ri,j∈Ud,j=1,2,…,c是类别数。
2.3 模型训练
BiGRU-AAM 网络模型的训练采用Pytorch 深度学习框架,编程语言为Python3.6;运行环境为Pycharm Ubuntu16 系统,内存大小为16GB。实验模型的训练使用反向传播算法,利用式(12)中的损失函数优化模型。该损失函数由2 个折页损失函数组成。L(θ)函数让每个方面注意力模块输出中,真实情感极性概率尽可能大,且让其它类别的概率尽可能小;J(θ)函数使每个方面注意力模块输出的重构文本的向量表示中,真实情感极性的向量表示与句子整体向量表示vs趋近。计算过程如下:

其中,m表示第m个输入样本,ym,i表示第m个输入样本在第i个方面的真实情感极性。
3 实验与分析
3.1 实验数据
由于方面情感分类任务需要判断其不同的方面的情感极性,实验采用SemEval2014 任务4 中的restaurants 数据集进行。在restaurant 数据集中,包括5 个方面和3 种情感极性,数据中每个句子涉及一个或多个不同方面。实验数据详情见表1。

表1 restaurants 数据集Tab.1 Data set
3.2 实验设置
实验中,词向量采用word2vec 技术[15]进行初始化,单词向量的维数、方面嵌入及隐藏层大小均为300。采用均匀分布U(-0.01,0.01)进行采样,来初始化其他参数。训练的更新规则采用Kingam 等人[16]提出的Adam 规则。训练过程中使用dropout机制防止数据的过拟合。批处理大小为25,初始学习率为0.01。
3.3 实验结果分析
为验证本文方法的有效性,将本文提出的BiGRU -AAM 模型与Bi-LSTM、ATAE-LSTM 和BLSTM-AAM 等经典情感分析模型,在restaurant 数据集上进行对比实验。实验结果见表2。

表2 不同模型的实验结果Tab.2 Experimental results of different models
实验结果对比可以看出,加入方面信息或使用注意力机制,能明显改善分类效果。体现在评价指标性能方面,就是提高准确率、查全率、F1 值。但是,由于attention 层突出信息的功能是通过不断加权计算进行的,因此增加了时间代价。BLSTMAAM 模型的时间代价相对较高。因BLSTM 神经网络计算相对复杂,增加了计算时间,并且attention 层在突出重点信息的同时也增加了加权计算时间。BiGRU-AAM 模型在实验的评价指标方面优于BLSTM-AAM,这两个实验模型均结合了attention层,且具有相同的模型结构;不同的是前一个模型第一层采用BiGRU 神经网络,另一个采用BiLSTM神经网络。由实验结果可以看出,由于BiGRU 神经网络比BiLSTM 神经网络结构简单,减少了计算及参数,使之达到更快的收敛速度。在时间代价指标上,从F1 指标上可以发现,BiGRU 与Attention 的结合更有效,在方面级情感分类任务中效果更优。
4 结束语
本文提出一种基于BiGRU 与方面注意力模块的情感分类方法,与广泛使用的BiLSTM 网络结合attention 的混合模型相比,本文方法能够提高方面级情感分类的准确率并降低损失率,取得很好的F1评价指标,达到了较好的分类效果,有效地降低了模型的训练时间。实验结果表明BiGRU 结合attention的有效性以及本文方法在方面级情感分类的有效性。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
软件(2017年6期)2017-09-23
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
