
基于大数据和支持向量机分类法的图书馆中转站构建研究
2020-03-23 06:06杨志腾孙萍朱天怡苏冠文马俊隆
价值工程 2020年5期
关键词:大数据
杨志腾 孙萍 朱天怡 苏冠文 马俊隆


摘要:经济增长,群众的物质需求得到满足后,文化需求就会相对增加,书籍作为重要的文化载体,正在重新被我们拾起。但是在众多场所中,例如社区居民,大型工厂,存在借阅不平衡的问题,大量的图书资源集中在高校图书馆以及市区少量的公共图书馆,无法辐射到大量的有需求群众集体,文章将以大数据为背景,结合支持向量机分类法,以高校图书馆为起点,探讨建立中转借阅体系,以解决图书借阅运营模式相对落后,无法充分利用资源的问题。
Abstract: When the economic growth and the material needs of the masses are met, the cultural needs will increase relatively, and books, as an important cultural carrier, are being picked up by us again. However, in many places, such as community residents and large factories, there is a problem of unbalanced borrowing. A large number of book resources are concentrated in university libraries and a small number of public libraries in the urban area, and can not radiate to a large number of mass collectives in need. This paper will take big data as the background, combined with support vector machine classification, and take the university library as the starting point, to explore the establishment of a transit lending system in order to solve the relatively backward operation mode of book lending. The problem of not being able to make full use of resources.
关键词:图书馆中转站;借阅平衡;大数据;支持向量机分类法
Key words: library transit station;loan balance;big data;support vector machine classification
中圖分类号:TP18 文献标识码:A 文章编号:1006-4311(2020)05-0216-03
0 引言
2016年,教育部九部门发布《教育部等九部门关于进一步推进社区教育发展意见》,意见指出,社区教育是我国教育事业的重要组成部分,是社区建设的重要任务。作为教育事业繁荣的标志,图书馆极大的方便了大部分群众的借阅需求,如今在各大高校都建设了较为完善,图书种类齐全的图书馆,这些图书馆在原有图书借阅的基础上,还拥有资料查询、文献检索、文献典藏等众多功能。然而,高校以外的众多社区尚缺乏方便的借阅条件。而这些社区又潜在着巨大的借阅需求,短时间内,很难通过建立大量的公共图书馆来满足这一需求。数据显示,2018年美国图书的销量为6.96册,比上一年增长1.3%[1],同样的增长也发生在中国,图书需求正在与日递增。通过问卷调查的方式发现,高校图书馆图书借阅功能使用率正在下降,一方面是因为高校图书馆图书类目的不断完善,图书数量增多,图书数量快速增多的同时,高校图书借阅需求未能快速增长或者趋于饱和,导致图书借阅率下降,大量书籍一直处于书架闲置状态。另一方面,阅读方式的转变,例如电子书的出现,也降低了部分阅读者对图书借阅的需求。然后,在公共社区,这一现象却截然相反,快速增长的阅读需求往往得不到满足,文章将利用大数据的方法和支持向量机分类法对借阅图书进行分类,进而构建高校图书馆的图书中转站,以达到借阅平衡的一种状态。
不仅如此,高校图书馆作为图书资源丰厚的资源库代表仅能达成有限的资源共享。在大数据时代,高校图书馆扮演者图书中转站的角色,作为影响社会的指明灯推进图书资源的流通,可渐渐带动社区群之间、省市之间图书资源的共享。现如今,随着时代更替速度的加快,要求获取信息的速度与质量下,确保图书公共资源的合理应用配置也显得尤为重要。基于大数据计量分析多种图书资源库的使用效率,为图书采购等提供有效的数据支撑。
1 支持向量机分类法基本思想与模型
支持向量机分类法基本思想:支持向量机(Support vector machines,SVM)与遗传算法、鲁棒模型等研究方法类似,都是学习型的。通常分类的过程都是学习的过程。它的基本思想是在两个(甚至是多个)类别的样本集之间寻找一个最优分界面,将其分开且分隔距离最大。它分为线性的和非线性。考虑到图书的借阅种类与数量的关系,文章采用线性可分的支持向量机分类法。
线性可分的支持向量机分类法的模型:
对于给定的一组线性可分的样本S={(x1,y1),(x2,y2),…,(xk,yk)},其中x为n维特征向量;y取1或-1。分类就是寻找n维空间上的一个实值函数,以根据决策函数推导出某一模式x对应的y值。支持向量机分类法是去寻找一个最优的分类超平面,试图将两类样本正确分开。
2 图书借阅的现状
2.1 高校图书馆馆藏的增加
高校在推进基础设施及提高办学条件时,图书馆馆藏的扩增往往是一项非常重要的工作,众多高校热衷于扩增图书馆馆藏,这一工作满足了学生的阅读需求,提高了高校的办学条件。但与此同时,出现了图书借阅率不高的现实问题,通过数据显示,以天津理工大学为例,该校2018年全年借阅量为153507册,而据该校图书馆官网显示,该校图书馆馆藏已经达到200万余册,即使在不考虑全年借阅图书借阅重复率的情况下,图书的借阅率也不是很高,甚至在某些高校中出现了部分图书常年无借出的情况。因此一些高校的图书馆存在较为严重的资源过剩甚至资源浪费的情况,因此如何将这些过剩或者浪费的资源利用起来,是一个值得思考的问题。
2.2 居民社区借阅资源的缺乏
我国城市化进程中,城市居民社区的国模得以扩大,尤其是在一些较为发达的地区,社区的规模越来越大,社区的居民数量也有很大的增加,社区居民阶级城市不断地丰富,这就必然地造成了图书借阅需求的不断扩大,但与此同时,绝大部分社区图书资源相对较为落后,甚至几乎处于零状态,社区没有图书借阅这方面的资源,自然就会导致社区居民借阅资源的缺乏,在我国,公共图书馆的建设在一定程度上解决了部分社区图书借阅的问题,不过公共图书馆的建设范围有限,以目前公共图书馆的数量,难以满足绝大部分的借阅需求,另一方面,公共图书馆高度依赖于政府的投资,段时间内很难快速地建立起大面积的公共图书馆,成为促进社区教育事业发展的一个阻碍。
2.3 借阅的不平衡
一方面部分高校图书馆借阅率不是很高,甚至出现一定时期零借阅率的情况,而另一方面,社区图书馆建设的不完善,资源的缺乏以及管理的不健全,导致了图书节约的不平衡,高校图书馆出现图书过剩的情况,这得益于我国对高校教育良好的政策投入,作为高校基础建设的一部分,图书馆馆藏的数量在一定方面,也能反映高校的基础建设实力,多数高校在近几年来,图书馆馆藏规模有了很大的提升。另一方面,社区作为一个城市的基本单元,其覆盖的人群可能比高校还要多,人们生活水平的提高,慢慢的已经不再满足于物质生活的需求,对文化方面的需求就会提高,当前现状来说,在部分发达地区,社区已经出现了许多图书馆,这些图书馆从一方面来说方便了社区居民的生活,满足了社区居民的借阅需求,社区居民可以很方便的借阅到一些需要的书籍。然而依然存在运作机制不完善,图书资源缺乏,图书种类单一等问题,尤其是在图书资源方面,是限制社区图书馆发展最大的原因,大量的社区有着强大的借阅需求,而部分高校又存在资源过剩,借阅率低的现状,因此,便产生了一个借阅的不平衡,这样的一个不平衡状态,长期导致了资源的浪费,图书资源是有限的,需要大量的财力来购买图书资源,短时间内,很难通过购买大量书籍来满足大部分社区居民对于图书借阅的需求,因此,这样的一个不平衡状态,将长期制约高校和社区的借阅需求的满足。
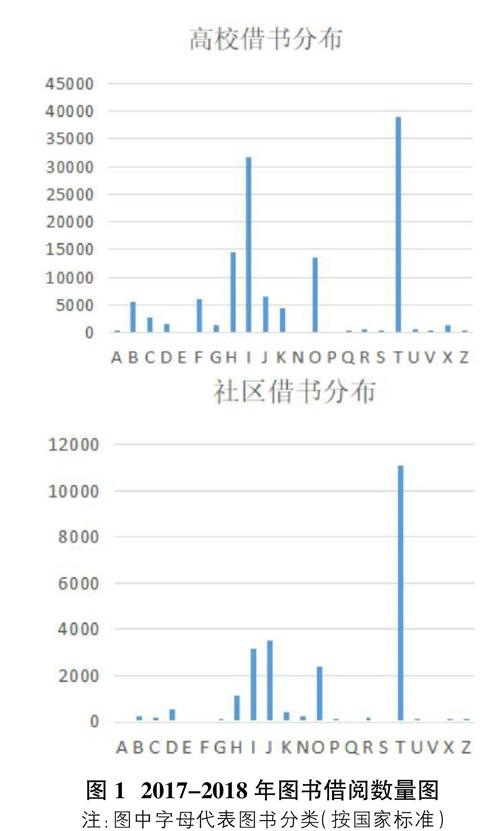
在加快高校图书馆与社区图书馆信息资源共享问题上,针对目前高校图书馆所存在问题和管理现状,首要问题应解决高校图书馆图书资源的更新以及如何实现高校同社区信息资源上的互补。针对南开区观园公寓、阳光100等五个社区居民地问卷调查结果显示,在800份调查样本中,近8成的居民认为有必要完善社区图书馆的建设,但其中仅有不到10%的居民偶尔或经常使用社区图书馆的资源;在选择很少使用社区图书馆的样本中,超过65%的居民反馈社区图书馆书籍热门书目种类数量有限、过时书籍较多,可供挑选的有价值的书籍过少,远远满足不了社区的实际需求。在走访天津市内六区数十家社区阅览室,统计得出公众借阅需求主要在故事小说类、名人传记类、休闲养生类和成人教育类。相比于社区图书馆资源不平衡的问题,高校图书馆也屡见不鲜,针对不同的借阅对象,高校借量最多的为专业领域相关书籍、文献,与社区借阅需求成相反趋势。由此可见两者之间若实现书籍信息匹配、共享,则可一举两得解决图书利用率和借阅量的问题。图1分别为近两年天津理工大学、附近社区借阅图书的数量分析。
3 应用支持向量机分类法图书分类
针对书籍分类和资源配值问题,许多文献利用集成性分类,依据图书管理信息系统的多元化进行优选;利用层次分析法,对书籍种类与对象匹配进行权重比较、评价;针对不同人群,借用多重指标分类方法对书籍利用率进行对比分析;或是遗传算法、鲁棒模型、聚类分析方法等研究方法。而支持向量机分类法相比于以上研究手段,能更为直接和方便的筛选出适合于不同用户群的书籍种类。
一般我们在使用支持向量机算法对样本集进行分类时,都尽可能地將其划分归类清晰,会容易产生过学习的状况;有干扰性训练样本分类出错的情况发生。文章是在MATLB操作系统环境下完成的,数据选用2017年和2018年天津理工大学图书馆大学生经常借的4种图书进行分类,采用基于距离的训练过程,根据运行情况相应减小正常样本,降低分类器的泛化能力。我们通过对比四种核函数的支持向量机的分类性能,选用线性核函数■。支持向量机分类的结果如表1。
4 中转站的构建的背景
4.1 中转站构建的设想
基于大数据时代背景下高校图书分类及合理再利用对策为响应政府号召,现当代高校图书馆在保证高校在校生的书籍借阅的基本需求下,应有针对性地服务社会群体,充分利用好高校图书馆储存文明、传递文明、提升国民综合素养的基本特性。这就要求高校图书馆不但提供与时俱进的资源需求供给和合理的图书管理分类方式,还要具备更加完备的系统化、科学化的信息互通网络建设。
4.2 采用分类管理,合理分配图书资源
为提高社会高校间图书资源使用率、发掘潜在价值,用合理的方法实现价值最大化,基于支持向量机分类方法的前提,利用书籍资源数量以及借阅量(周转率)两个指标进行针对性划分。根据社区图书借阅数据分析,所筛选出来的使用价值较高、重复利用率较好的书籍可在满足高校需求的前提下,适当的从高校图书馆资源库进行向社区图书馆抽调,从而丰满社区图书馆资源,满足公众所需。同时,对于部分使用价值较低、重复利用率较少图书,高校图书馆可根据实际需求进行处理,适当控制未来一段时间的采购计划。
4.3 基于大数据整合共享社区教育资源
4.3.1 开放共享学校图书资源
利用大数据平台,尽可能跟踪图书借阅在各数据库或平台中浏览、下载、引用、分享等指标,记录对某类图书关注度比較高的来访者。充分利用社区周边大学、职业学校、中小学、成人技术学校等各类教育机构的图书资源,为其推荐研究领域相近或学科互有交叉的相关书籍。利用资源建立起漂流站形式的中转站,社区可以通过中转站借还书籍,使得一些原本闲置的图书资源能够发挥作用,高校图书资源能够和社区资源实现共享,解决借阅不平衡的问题。为广大读者提供个性化、动态化、可视化的图书资源。
4.3.2 共同维护社区中转站
社区图书维护可以由高校和社区居委会共同完成,高校通过数据分析,共享闲置而又符合社区需求的书籍,社区居委会为中转站建设提供场地、电力支持,组织工作人员或者志愿者对图书中转站进行维护,必要时可以通过募捐进行书籍损耗维护。长远看来,政府也可加大对社区图书中转站建设的支持,图书中转站建设提供资金,也可以凝聚社会力量,通过福利机构,慈善基金等维护社区图书中转站。
4.3.3 社会效益最大化
通过将社区周围高校闲置的资源利用大数据分析的方法整合共享到社区中去,有利于充分发挥资源的价值,在不影响周边高校图书借阅的情况下,较好的满足了社区居民图书借阅的需求,其带来的社会效益远远超出于社区借阅本身,长期下来,对推进社区教育发展、提升社区居民教育水平将起着重要的作用。
5 结语
大数据环境下,图书数据库不仅是为用户提供图书资源的重要渠道,也是提供知识情报分析的重要平台,需要不断地与时俱进,优化升级。为进一步推进社区教育发展,图书馆中转站的建设是一个较为可行的方式,通过大数据的背景,建设图书馆中转站,将有利于社区居民获得更好的阅读资源,创建便捷的社区图书借阅环境。并建议通过提升智能化数据处理技术,深度分析大数据之间的关联,利用政策机制、激励机制促进街道社区主动参与图书馆中转站建设等多种手段,满足以读者对文化的需求,为构建文化交流圈,使高校图书库成为充满活力的资源共享和学术交流服务创新平台。
参考文献:
[1]子柚.美国纸书销量连续六年上涨[N].国际出版周报,2019-01-21(001).
[2]朱碧纯,吴爱民,张以舒,郭桑.大数据环境下医学高校机构知识库建设现状调查与策略探析[J].图书馆学刊,2019(11):73-78.
[3]余辉,赵晖.支持向量机多类分类算法新研究[J].计算机工程与应用,2008,44(7):185-189.
[4]刘晓亮,丁世飞.SVM用于文本分类的适用性[J].计算机工程与科学,2010,32(6):106-108.
[5]krebel U.Pairwise classification and support vector machines [C].Schuolkopf B, Burges C J C, Smola A J.Advances in kernel Methods: Support Vector Learning.MA: Cambridge, MIT press, 1999: 255-268.
[6]Knerr S, Personnaz L, Dreyfus G.Single- layer learning and training a neural network[C]. NeuroComputing: Algorithm, Architectures and Applications.New York: Springer- Verlag, 1990.
猜你喜欢
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
