
遗传算法在路径规划上的应用①
2020-03-22 07:42:32程智锋
计算机系统应用 2020年8期
李 敏,黄 敏,程智锋,周 静
1(招商局重庆交通科研设计院有限公司,重庆 400067)
2(中山大学 智能工程学院,广州 510006)
3(广东工贸职业技术学院,广州 510510)
随着城市化建设的不断发展,路网日趋复杂,出行者的路径选择更趋于多样化,为此,出行者如何选择最优路径并高效快捷地到达目的地成为其关心的问题[1].目前寻找最优路径的算法主要采用启发式算法和最佳式算法,启发式算法能够在一定的时间内找出近似最优解,常见的启发式算法有遗传算法、神经网络、蚁群算法等.最佳式算法能够找出最优解,但一般时间复杂度较高,具有代表性的算法有Dijkstra、BFS 算法等[2].
对比其他路径寻优算法,遗传算法是一种全局优化算法,能够有效地进行概率意义的全局搜素,具有较强的鲁棒性,应用较为广泛,适合于求解复杂的优化问题[2].为此,本文旨在运用遗传算法,为出行者找到一条综合权值最优的路径.针对出行者路径选择的多样性,结合前人研究[2,3],影响出行者路径选择因素诸多,主要表现在行程时间、行程路程、交叉口的个数、沿途风景等[3,4].本文初步选用以行驶路程和交叉口的个数作为综合指标,定义综合指标最小的路径作为最优路径,并以广州大学城中山大学为例,采用遗传算法的方法,找到从广州大学城入口到中山大学的最优路径,从而验证遗传算法在路径规划应用上的有效性.
1 交通路网模型
城市道路路网是由若干路段(弧段)和交叉口(结点)组成的网状结构,描述了道路和交叉口之间的关系.在基于拓扑路网的情况下,交通路网数据可包含道路几何中心线、路网弧段、路网结点3 个部分[5,6].其中三者之间的关系如图1所示.本文采用弧段-结点模型来描述路网,定义以下路网模型,G=(V,E)表示路网;其中V={vi|i=1,2,···,n}是G的结点集,表示路段的端点,如道路交叉口或断头路口等,E={ei=(vk,vl)|i=1,···,m;vk,vl∈V}是G的弧段集.ei为从vk到vl的有向弧,vk为起点vl为终点.为了更好地描述道路交叉路口处的交通限制以及转向信息,在路网模型中引入结点-弧段夹角及结点的逻辑连通关系[2].

图1 道路路网数据地图
2 遗传算法基本概念及算法模型
2.1 遗传算法基本概念
遗传算法是一种借鉴达尔文提出的生物进化论的思想,利用计算机科学与自然遗传学相互结合去解决一些复杂的优化问题[7,8].在遗传算法中存在一些遗传学与进化的概念,如染色体、种群、适应度等概念,为此阐述其各自的定义.染色体:英文全称为chromosome,染色体又可以称作为个体,一条染色体代表着一个可行解.种群:英文全称为population,表示每代染色体的总数,一个种群表示解决该问题的部分解的集合.基因:英文全称为gene,基因是染色体的组成元素,用来表达个体的基本特性.适应度:英文全称为fitness,适应度表示衡量对环境的适应程度,每条染色体都有对应一个适应度值.
遗传算法的过程主要分成以下几个过程即种群的初始化、适应度值计算、选择、交叉、变异、产生新种群.接下来分别介绍种群中染色体在指路标志诱导系统中的编码、适应度函数的设计、选择、交叉、变异等操作.
2.2 种群的初始化
在种群初始化之前,需要进行染色体编码,本文遗传算法采用的编码方式不同于传统的遗传算法中的0-1 编码,本文中遗传算法的染色体是由一系列路网的结点组成,形成一条完整的路径,为此将这种编码方式称为路径编码方法.这种方法规定每条染色体中的基因不允许有重复编码的基因,但对于染色体的长度并没有强行规定即染色体的长度是变化的,但其长度需要满足小于路网的结点总数.染色体编码即为从源节点到目的节点的队列组成,以图2的路网为例.
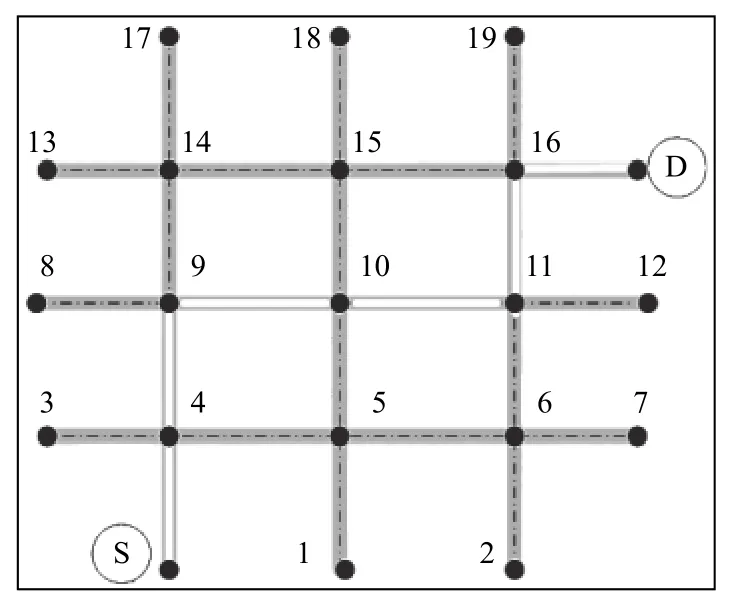
图2 路由路径与其编码表示
图2中一条从节点S 到节点D的一个染色体,其编码可为:S-4-9-10-11-16-D,其中染色体编码的第一位置基因(节点)是源节点,第二位置基因是从与源节点连接的其他节点中随机选择或启发式选择.选择的节点从结构信息库中删除,避免重复,再重复过程直到目的地节点D.种群可以根据路网的大小来设定初始的染色体数量.
2.3 适应度函数设计
本文主要考虑行驶路程和交叉口的个数作为综合指标,以综合指标最小的路径作为最优路径.由于两大指标存在量纲差异,为此需要对其进行归一化处理,本文借鉴前人研究成果,将两大指标转换成时间消耗成本[7,8].出行者从始发地到目的地的时间总消耗由路段时间消耗与节点时间消耗组成,其中路段时间消耗取决于路程的长度、行驶的速度等因素,本文假定车辆在道路上匀速行驶,为此单位长度下的时间消耗是固定的,从而路段总消耗时间可用路径总长度乘以单位长度下的时间消耗得到[8].节点时间消耗取决于交叉口的类型、转向方向等因素[8],为此节点总消耗时间即通过每个交叉口时间消耗的累加.根据交叉口信号配时经验,绿灯配置时间从长到短依次为直行方向、右转方向、左转及掉头方向,然而在时间消耗上则成反向,假定左转及掉头方向的时间消耗是直行方向的2 倍,右转方向的时间消耗是直行方向的1.5 倍[8,9].基于上述分析,适应度函数可以表达如式(1)所示.
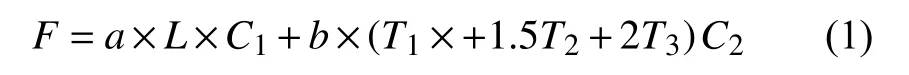
其中,F—适应度函数值;
a、b—权重系数,本文认为两个指标影响程度一致,为此将二者权重比设为1:1;
L—行驶路径总长度(km);
C1—单位路段长度所需消耗的时间;
T1—交叉口所有直行方向的次数;
T2—交叉口所有右转方向的次数;
T3—交叉口所有左转及掉头方向的次数;
C2—单个节点上直行方向上所需消耗的时间.
根据式(1)可知,适应度F值越小,则时间消耗越少,即路径选择越优.
2.4 选择-复制
选择操作是用来确定交叉个体,以及产生多少个子代个体.在选择过程时应保持种群的整体数量不变.计算种群中各个染色体的适应值,并按照适应度由小到大排序将染色体中适应度最小的个体直接保留到下一代,然而个体适应度值越小,则被选择的概率就越高,相同染色体只保留一条染色体.
2.5 交叉
通过选择得到的两个个体,将其部分结构相互交换,生成新个体.不同于传统的单点交叉,两个染色体选择一个公共的基因(节点)作为交叉点;一般选择第一个公共节点,若交叉后代与父代染色体一样则改选其他公共节点.以图3为例.父代染色体:Chromosome1:S-4-9-10-11-16-D与Chromosome2:S-4-5-10-15-16-D;其两条染色体的公共基因结点为4、10、16;因此按照公共基因的选择规则,首先选择结点4,发现并无新的染色产生,则选择另一个公共结点10,通过交叉后得到新的两条子代染色体Chromosome1*:S-4-9-10-15-16-D与Chromosome2*:S-4-5-10-11-16-D;其中交叉后染色体如图4所示.

图3 交叉前的染色体路径
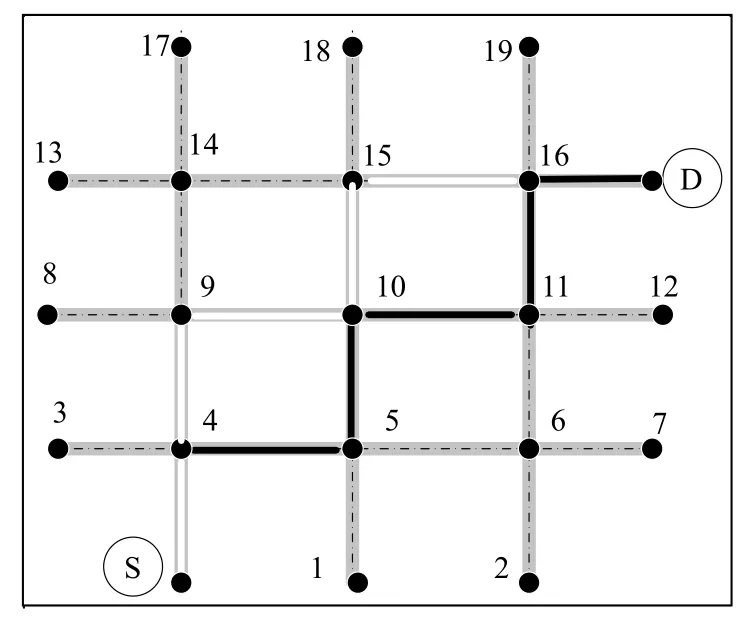
图4 交叉后新的染色体路径
2.6 校正
交叉后产生的新个体中不能产生环路,即满足同一节点只能选择一次原则,为此需要对染色体进行校正操作.以图5为例,父代染色体为Chromosome1:S-4-5-10-11-16-D与Chromosome2:S-4-9-14-15-10-5-6-11-16-D;其中假设选择公共结点10 作为交叉点,则交叉后的子代染色体为:Chromosome1*:S-4-5-10-5-6-11- 16-D与Chromosome2*:S-4-9-14-15-10-11-16-D;很明显子代染色体1 需要校正,经过校正处理后,得到校正后的染色体为Chromosome1**:S-4-5-6-11-16-D.
图5 校正前后的染色体路径
2.7 变异
变异以很小的随即概率改变染色体上的某些基因,找回较好的基因,与种群大小无关.同时变异操作是一种局部随机搜索,选取适应度最差的或者满足突变概率的染色体.假设需突变染色体Chromosome1:S-4-5-10-9-14-15-16-D,如图6所示.从染色体中随机选择一个基因作为突变基因(假设10),则从源节点到变异点的基因保持不变,变异点之后的基因则从连接的基因随机选择,直到目的节点.突变后染色体Chromosome1*:S-4-5-10-11-16-D,如图7所示.
2.8 算法流程
章节2.2~2.7 分别阐述了在交通拓扑路网下,利用遗传算法寻找最优路径的具体运算步骤.算法的主要思路为:根据给定的起点生成相应的初始种群,接着计算各种群中染色体的适应度值,并将最优染色体直接保存于下一代,再在种群中进行选择、交叉-校正、变异操作产生新的种群,重复上述过程直至到达指定的进化代数后停止进化.其中算法流程如图8所示.算法中用到的符号如下:
OptV:起点集合,针对多入口路网;
Gen:迭代的次数;
K:起点的个数;
F:各种群中染色体的适应度值;
L:行驶路径的长度;
T:交叉口的个数;
Fcpti:第i次进化时的最优的适应度值.
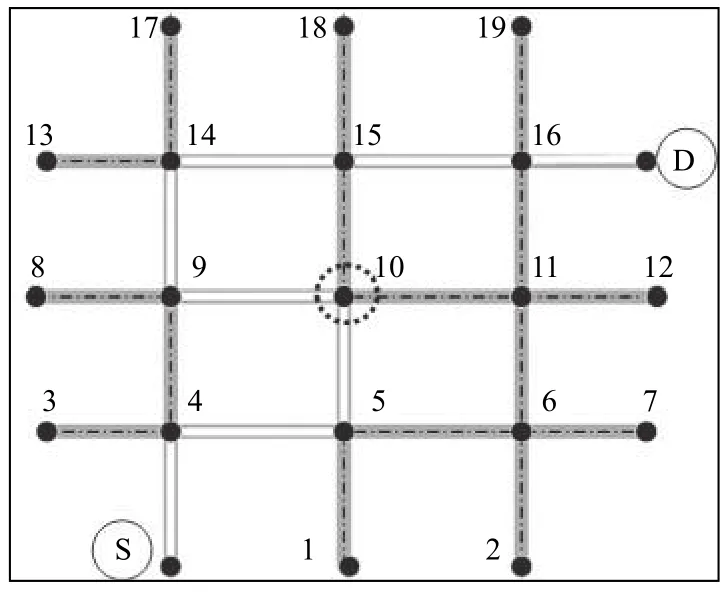
图6 变异前的染色体路径
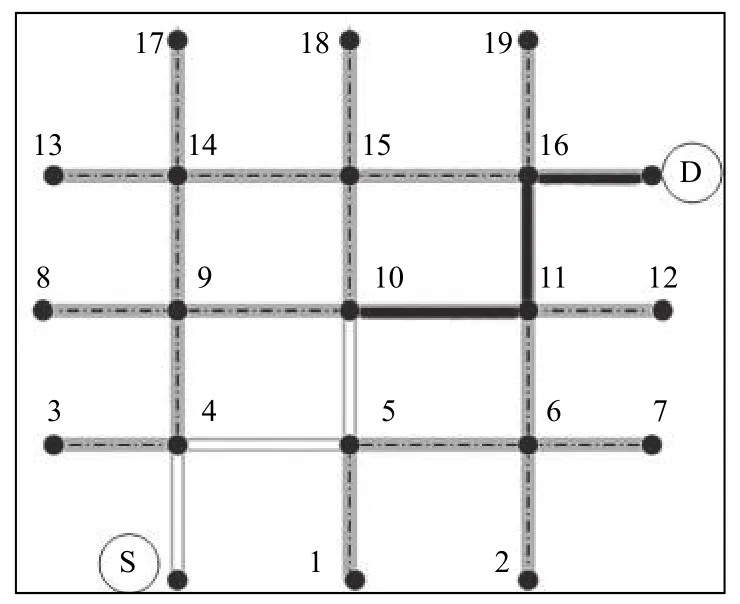
图7 变异后的染色体路径
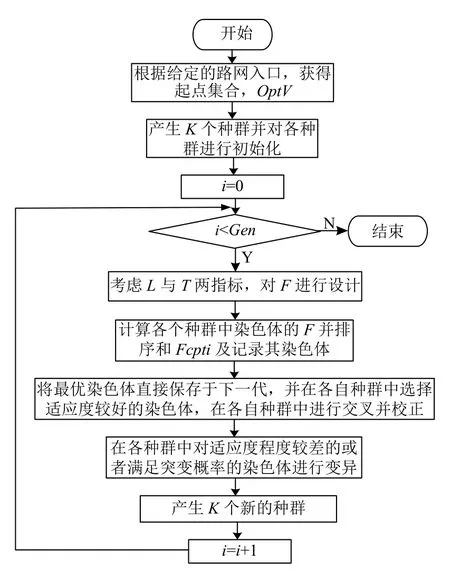
图8 算法流程图
3 实例应用
本研究基于C#与ArcGIS的开发下,采取广州大学城作为实例,将上述算法应用于该路网中,路网的入口O1、O2、O3、O4、O5如图9所示,目的地(D)为中山大学,路网中各个路段的权值如图10所示.
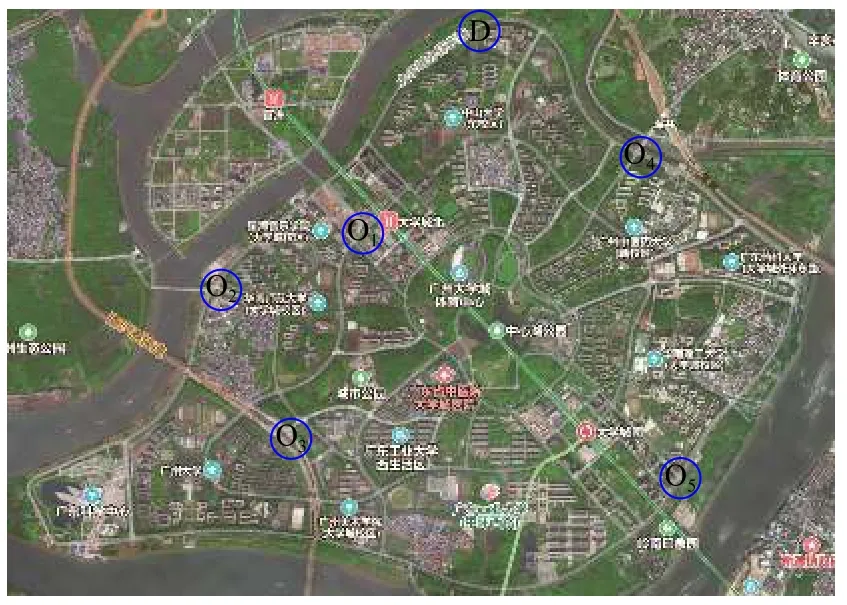
图9 广州大学城出入口示意图
对于适应度函数参数的设定,参照《城市道路路线设计规范》CJJ193-2012和《城市道路交叉口设计规程》CJJ152-2010,并结合广州大学城车辆运行的实际情况,本文采用50 km/h的速度作为车辆的平均行驶速度,从而单位长度上的时间消耗为1.2 min.根据前人研究成果[7,9–11],直行方向消耗的时间为0.5 min,从而适应度函数可以表示为F=1.2L+0.5(T1+1.5T2+2T3).对于算法中的参数:根据相关资料[7–9]及多次试验,设定种 群中染色体数为40、最大进化代数为40、交叉概率为0.9、变异概率为0.1.最终总的最优路线如图11所示,其中各入口到中山大学的最优适应度值及相关指标如表1所示.
图10 广州大学城道路距离权值图
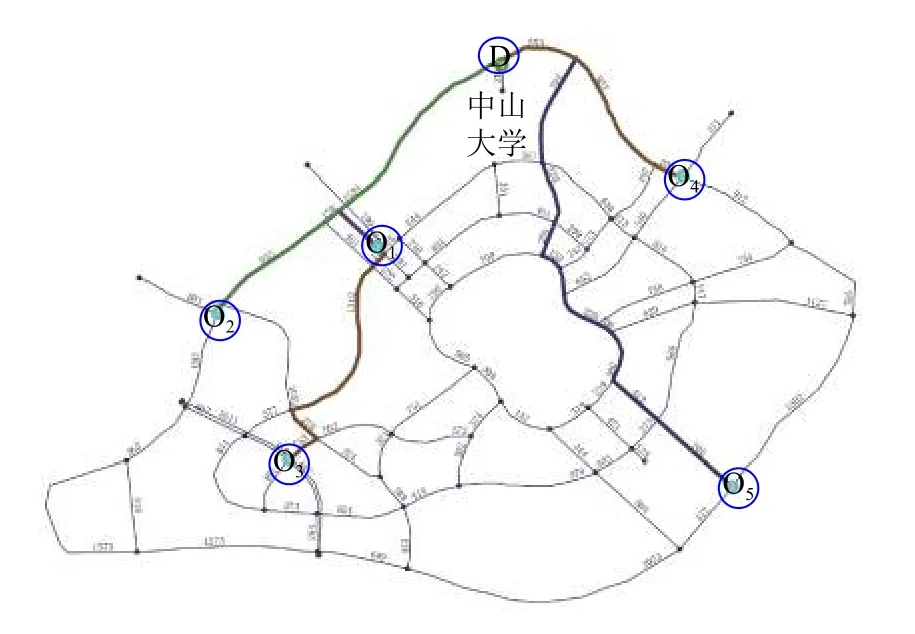
图11 总的最优路径规划图
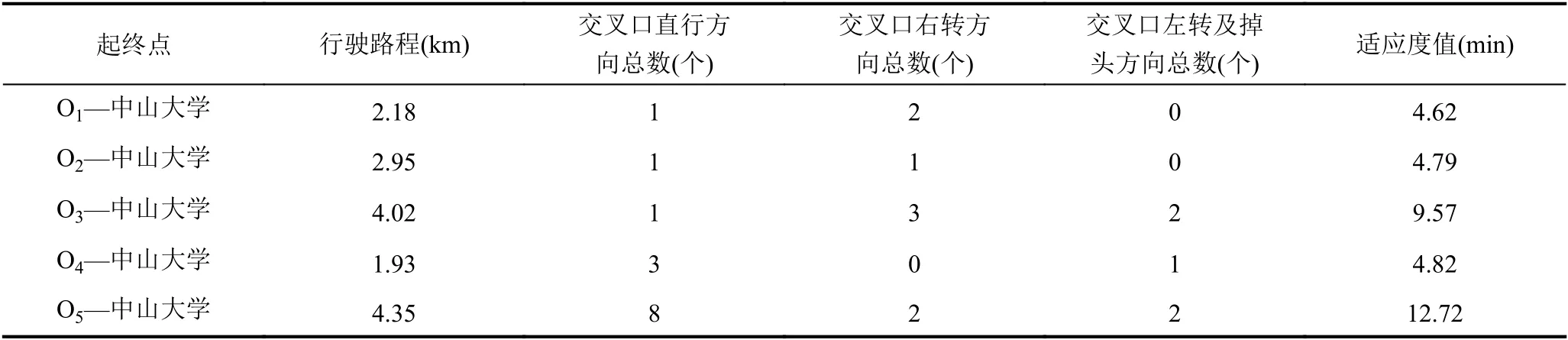
表1 各入口到中山大学最优路径下的相关指标及适应度值
4 结语
本文采用遗传算法对路径寻优问题进行了探讨,在明确起终点条件下,以行驶路程和交叉口个数作为综合指标,找到了一定路网范围内的最优路径,验证了遗传算法在路径规划上的有效性.但本文只考虑了行驶路程和交叉口个数作为出行者的考虑因素,在后续的研究中将对出行者的路径选择进行综合分析,从综合影响因素出发,系统地对路径规划进行研究,进一步提高算法的科学性与合理性.
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
环球飞行(2018年7期)2018-06-27 07:25:54
数学物理学报(2018年1期)2018-03-26 08:16:42
中国公路(2017年11期)2017-07-31 17:56:30
中国公路(2017年7期)2017-07-24 13:56:29
中国公路(2017年10期)2017-07-21 14:02:37
中国塑料(2016年11期)2016-04-16 05:26:02
电子设计工程(2014年12期)2014-02-27 11:58:23
教育与职业(2014年16期)2014-01-19 01:24:36
舰船电子工程(2010年1期)2010-04-26 05:06:48
