
面向堆垛机路径优化的局部搜索自适应遗传算法①
2020-03-22 07:42:24史勤政李冬梅田月
计算机系统应用 2020年8期
史勤政,王 嵩,李冬梅,高 岑,田月
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
近年来,随着物流行业的发展,现代仓储物流企业对自动化仓库AS/RS (Automated Storage and Retrieval System)的效率要求也越来越高,在AS/RS 中,出入库货物搬运任务完全由自动化巷道式堆垛机来负责完成,堆垛机作为AS/RS的核心设备,其调度问题对仓库的管理效率起决定性作用,目前,仓库的堆垛机调度路径往往采用直接指派的方式,导致堆垛机的运行效率低、时间和能耗较高.良好的堆垛机存取路径优化可以降低仓储成本,提高AS/RS的利用率,对仓库管理效率的提升具有很大的现实意义.
通过对堆垛机的运动模式和物理特性进行分析,发现其调度问题要考虑时间、能耗、作业效率等因素,这3 个因素显然不能同时达到最佳,那么就需要一些方法来进行协调,传统的方法是将多个目标函数通过权重分配的方式降维成单个目标函数,转换成单目标优化的问题,这种方式存在权重量化设定困难和易于陷入局部最优等问题.本文采用多目标优化方式[1]来解决路径优化问题,对多个无法同时达到最优的目标进行协调,产生一组Pareto 最优解[2]路径,供仓库控制系统自行选择.
针对堆垛机调度问题,关榆君等[3]采用引入了交算子和交序列的猫群算法,但无法得到Pareto 最优解集,依旧是单目标优化的变种.针对多目标优化问题,Srinivas和Deb 在NSGA的基础上提出了NSGA-Ⅱ算法[4]来求pareto 最优解集,NSGA-Ⅱ算法使用了快速非支配解排序算法降低复杂度、引进了精英策略来保证优良个体得以保留、采用拥挤度替代了共享适应度,NSGA-Ⅱ算法以运行速度快、解集收敛性好、简单有效等特点在多目标优化领域得以广泛应用,尤其对于低维多目标优化问题具有明显优势[5],但仍存在着容易陷入局部最小值、局部搜索能力不足等问题[6].因此,本文在NSGA-Ⅱ的基础上进行改进与优化,对NSGA-Ⅱ算法易陷入局部最优的问题采用引入自适应遗传算子的方式进行了改善,并新增了局部随机搜索策略增强局部搜索能力.通过实验证明了新方法对比NSGA-Ⅱ算法在堆垛机调度问题中的有效性.
1 堆垛机调度模型
1.1 问题描述
以连云港某家氨纶公司的自动化无人仓库为研究对象,该仓库为同端出/入布局,即入库口与出库口在巷道的同一侧,货架沿通道排列,堆垛机按指令沿通道运行,进行货架上货物的拣选作业.图1为部分示意图.

图1 自动化无人仓库部分示意图
本文主要研究的是单一堆垛机面对多任务时,如何合理的设计调度路径.从时间、能耗、批作业效率3 个方面考虑,这3 个指标不能同时达到最优,故运用算法产生一组Pareto 最优解,供仓库控制系统自行选择,从而节约堆垛机的使用费用,提高仓库的搬运效率.
1.2 模型建立
堆垛机的运行可以归类为TSP 问题,即机器从起点出发,一次性经过多个拣选点又回到起点的路径问题.考虑到堆垛机在运行过程中的时间、能耗以及作业效率,对堆垛机的调度路径进行建模.分别从时间、能耗、批作业效率3 个方面建立优化目标.
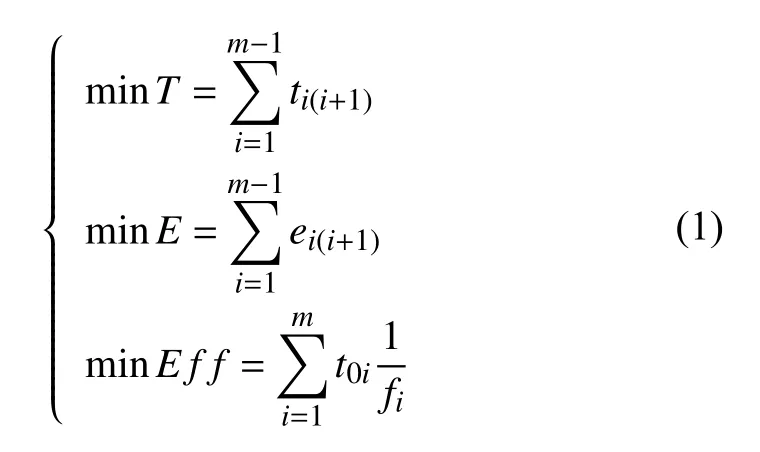
其中,ti(i+1)表示从堆垛机从第i个货位点到第i+1 个货位点的时间,ei(i+1)表示堆垛机从第i个货位点到第i+1 个货位点的能耗,t0i表示堆垛机从初始位到第i个货位点的时间(即第i个货位任务的等待时间),fi表示第i个货位点货物的优先级(数字越小表示优先级越高),T表示堆垛机完成一批次调度任务的总耗时,E表示堆垛机完成一批次调度任务的总耗能,Eff表示批作业的效率.
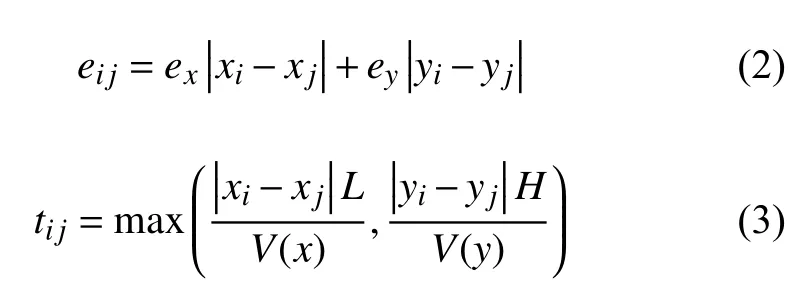
其中,(xi,yi)表示第i个货位点在货架中的坐标,L为一个货位的长度,H为一个货位的高度,ex为移动单位货格长度的基础能耗,ey为移动单位货格高度的基础能耗,V(x)为堆垛机变加速运动过程的平均速度,仅与移动距离有关.
2 基于局部随机策略的自适应遗传算法
在解决多目标优化问题时,NSGA-Ⅱ算法作为较为经典的一种算法一直得到广泛的应用,但将其应用到堆垛机调度问题中时,发现NSGA-Ⅱ算法容易陷入局部最优,并在搜索能力上有所不足,因此,本文在NSGA-Ⅱ算法的基础上从遗传算子着手进行了改进,并加入了局部随机搜索策略,得到了一种加入局部搜索策略的自适应遗传算法(IMOGA).
2.1 染色体编码
本文采用对堆垛机的货位点拣选顺序进行编码的方式,染色体由多个基因组成,每个基因表示货架上的货格编号,以25 列20 行的货架为例,采用行优先的方式对货格进行编号,第1 行第1 列编号为0,第1 行第2 列编号为1,依次类推,一直到编号4999.以长度为5的染色体为例,染色体[43,54,2,386,123]表示堆垛机共经过5 个点,依次为43,54,2,386,123 号货位.
2.2 自适应遗传算子
在进化过程中,出现堆垛机路径序列部分货位点相邻的情况,以25 列20 行的货架为例,对于55 号货位,20、54、56、80 号货位都与它相邻,如图2所示.为了保证堆垛机的运行效率,对于这样的相邻货位点序列,在交叉变异过程中,应当保证相邻货位点序列不被破坏.出于以上考虑,对交叉、变异操作进行了改进.
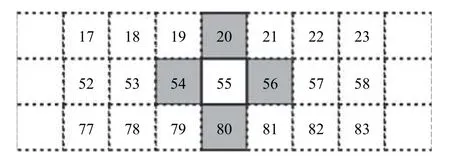
图2 货位示意图
交叉操作采用改进的基于位置的交叉,首先根据染色体长度L与随机位置数z的关系公式z=,随机生成z个随机交叉位置,在初始待优化序列中找到对应位置的基因,作为保留位置基因,并在基因的左右位置上进行探测,是否存在该基因对应的临近货位编码基因,若存在,扩展进保留位置基因中,父代两个个体间保留位置基因依序交换,然后依次在未保留位插入剩余基因.譬如,对于初始待优化序列[45,287,2,467,3642,264,2182,20,466,9],随机生成3 个位置1、4、10,对应保留位置基因45、467、9,对于两个父代[264,466,9,2,45,20,3642,2182,467,287]和[2,9,20,2182,3642,466,467,287,264,45],搜索临近位置基因,发现存在相邻货位点基因序列[45,20]和[466,467],拓展保留基因为[45,46][466,467][9],基于交叉位置进行交换,依次在未保留位插入剩余基因,得到子代,如图3所示.
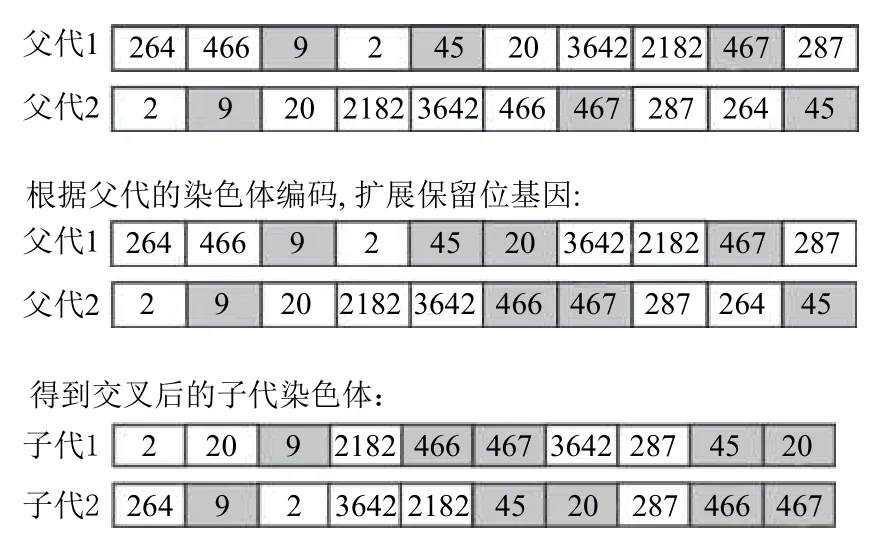
图3 改进后的交叉操作
变异操作采用随机位置的互换操作,根据染色体长度L与变异点z的关系公式z=,随机生成z个变异点,若变异点左右位置上存在该变异点基因对应的临近货位基因,则将变异点进行延拓,循环交换这z个变异点的基因段.譬如,对于父代[264,45,20,9,2,466,467,287,2182,3642],随机生成3 个变异点2、7、9,对应基因45、467、2182,在变异点临近位置上进行探测,发现存在相邻货位点基因序列[45,20]和[466,467],延拓变异点基因段为[45,20][466,467][2182],循环交换基因段,如图4所示.
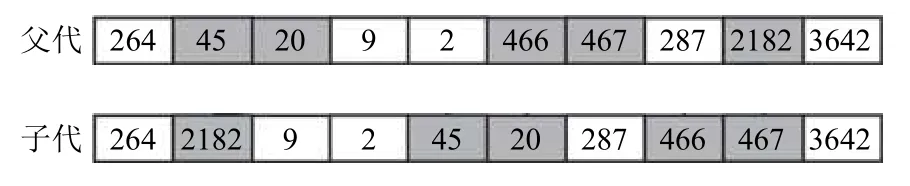
图4 改进后的变异操作
在研究过程中发现,遗传算子的交叉、变异概率对在很大程度上将影响算法的结果.对于适应度较差的个体,应当给予更高的交叉变异概率,而对于适应度较高的优秀个体,应当给予较低的交叉变异概率[7],因此,根据自适应的思想,使交叉率变异率按照适应度的Sigmoid 曲线进行调整[8],尽力保留优秀个体的同时跳出局部收敛,将遗传交叉变异概率做如下改进.
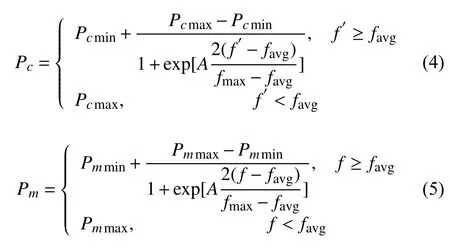
其中,pc为交叉概率,pm为变异概率,Pcmax为最大交叉概率,Pcmin为最小交叉概率,favg表示种群的平均适应度,fmax表示种群最大适应度,f′表示待交叉个体中较大的适应度,Pmmax为最大变异概率,Pmmin为最小变异概率,f表示待变异个体的适应度,A=9.903 438,依据Sigmoid曲线特性得来.
2.3 基于模拟退火算法的局部随机搜索策略
遗传算法在前期的搜索过程中主要是对解空间进行全局寻优搜索,能够搜索到最优解集的大致范围,到了迭代的后期,解集较为集中,就需要考验算法的局部搜索能力,由于NSGA-Ⅱ算法局部搜索能力不足,难以得到问题的真正解集.出于以上的考虑,本文针对NSGA-Ⅱ遗传算法局部搜索能力不足的问题,进行了改进,采用了局部随机搜索策略来帮助算法改善搜索过程.
模拟退火是一种随机寻优的算法,具有比较强的局部搜索能力,其Metropolis 准则允许一定的概率上接受劣于原解的新解,从而使算法能够跳离局部最优的陷阱[9],理论上,只要迭代次数足够,就能够搜索到全局最优.因此,本文采用基于模拟退火思想的局部随机搜索策略.模拟退火算法依据Metropolis 准则来判断是否接受搜索过程中得到的被原始解所支配的新解,新解的接受概率公式为:

其中,f(x1)为新解的目标函数值,f(x0)为原始解的目标函数值,k为Boltzmann 常数,T为进化代对应的热度,由上式可以看出,接受概率P与热度T有关,T热度越高,对被支配解的接受概率越大,T热度越低,对被支配解的接受概率越小,热度T的迭代公式为:
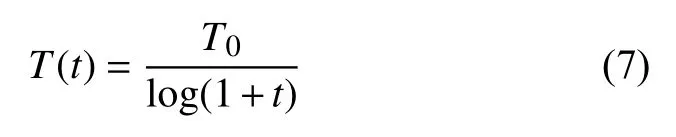
其中,T0为模拟退火的初始状态温度,t为迭代次数,可以看出,T热度随着迭代次数的增加而降低,使得算法迭代前期能够保留一些“潜力解”,使解空间具有更多的可能性,增加了全局搜索能力,在算法迭代后期,热度降低,接受被支配解的概率降低,避免丢失较优解,并有一定的概率让陷入局部最优陷阱的解进行“自救”.基于模拟退火的局部随机搜索策略步骤如下:
Step 1.设置初始参数:初始状态温度T0,迭代次数上限n,邻域内搜索次数m,邻域内搜索上限M次.
Step 2.遗传算法进化得到非劣解集S,非劣解集S中解用xi表示.
Step 3.若在解xi的一定邻近范围内随机搜索得到新解yi,计算ΔE=f(yi)−f(xi),若ΔE<0,则接受新解yi取代xi,跳至Step6;若ΔE≥0,则随机生成概率r,跳至Step 4.
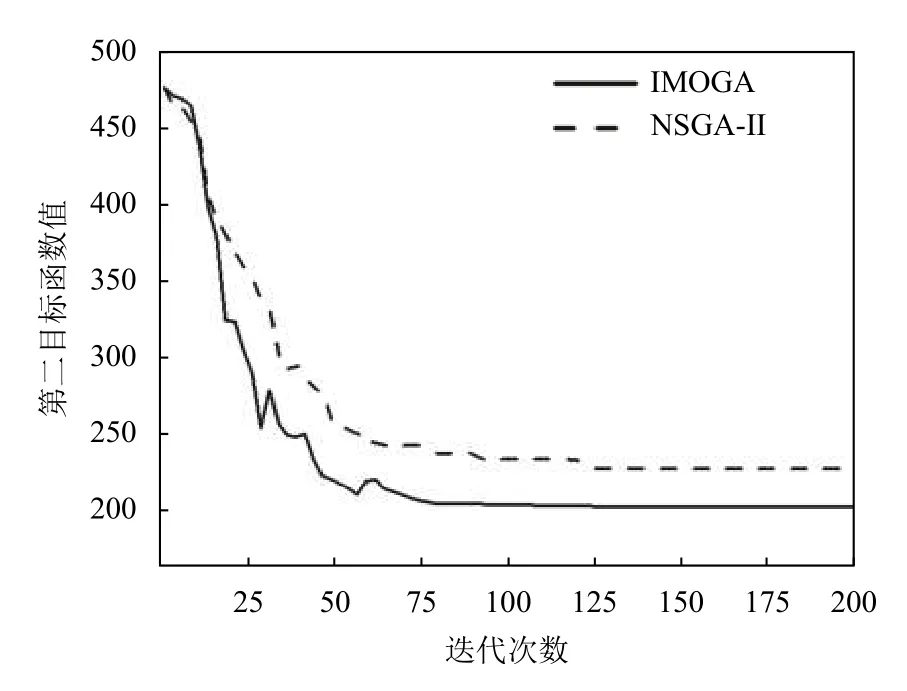
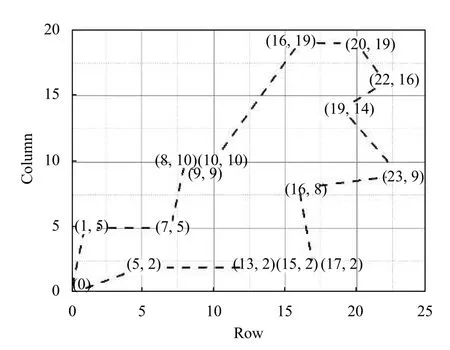
Step 4.按照新解接受概率公式,若r Step 5.若m Step 6.更新温度T,迭代次数若超过最大次数,终止.否则,返回Step 2. 为了验证本文所述的改进算法IMOGA的性能,针对具体的调度序列,分别采用NSGA-Ⅱ和IMOGA算法进行求解.以连云港某氨纶公司的自动化无人仓库为例,货架有11 排,每排有25 列20 层,单个货位的长和高均为1 m,一台堆垛机负责一个巷道内的出入库操作,依照货位点依次拣选作业,堆垛机货位拣选点坐标测试数据如下: 针对上述货位拣选点,分别使用NSGA-Ⅱ、IMOGA算法对堆垛机路径进行优化.算法参数:初始种群大小100,最大迭代数200,NSGA-Ⅱ的pc=0.8;pm=0.05.IMOGA 算法的M=10;pcmax=0.9;pcmin=0.5;pmmax=0.1;pmmin=0.01;T0=700,两算法迭代过程如图5~图7所示. 图5 时间原则算法迭代过程 图6 能耗原则算法迭代过程 图7 作业效率原则算法迭代过程 由图5~图7可见,IMOGA 较NSGA-Ⅱ收敛速度更快,趋于稳定的代数更早,在各个目标函数上的值最优,IMOGA 在收敛过程中存在一些拐点,证明IMOGA在局部随机搜索策略帮助下,能在一定概率上接受劣解来跳出局部最优.IMOGA 算法求得测试数据(图8)的一组路径坐标Pareto 解如图9~图11所示. 图8 初始序列路径图 图9 Pareto 解1 路径图 图10 Pareto 解2 路径图 图11 Pareto 解3 路径图 采用Knowles,Corne 提出的解集与参考集的距离指标DIR[10]来衡量解的质量,DIR越小,解的质量越高,DIR公式如下:其中,S j为求得的解集,S∗为参考解集,dxy为解y在N维目标空间中到解x的距离,fi∗(·)表示解·的第i个目标函数值.dxy公式如下: 分别用NSGA-Ⅱ、IMOGA 算法相同条件下运行20 次得到各自的解集,合并并去除非劣解,得到非劣解集作为参考集S∗.得到趋于稳定的平均迭代次数和DIR指标如表1所示. 表1 算法平均性能比较 由表1可以看出,在堆垛机调度问题中,IMOGA算法的DIR与趋于稳定的平均迭代次数均少于NSGA-Ⅱ算法,证明IMOGA 算法的解集质量更高,具有更快的收敛速度,针对堆垛机路径优化问题具有更强的有效性. 本文对同端出入立体仓库中的堆垛机调度问题进行建模,针对NSGA-Ⅱ算法容易陷入局部搜索能力不足的问题进行了改进,并引入了一种局部随机搜索策略来帮助算法跳出局部最优,提出了一种根据自适应遗传算子和局部搜索策略进行改进后的遗传算法IMOGA.通过实验分析表明,在堆垛机调度问题上,IMOGA 相较于NSGA-Ⅱ,不论是解的质量还是收敛速度,都具有一定的优势,证明了算法的有效性.3 实验分析






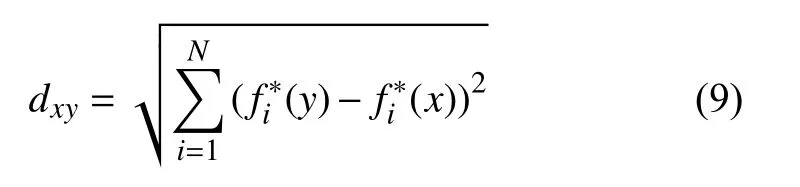

4 结语
猜你喜欢
物流技术与应用(2021年11期)2021-12-27 05:17:20物流技术(2020年5期)2020-06-27 13:05:30初中生世界·八年级(2019年6期)2019-08-13 18:41:18计算机与数字工程(2018年11期)2018-11-28 09:47:00制造业自动化(2018年10期)2018-11-02 09:51:40小学生导刊(低年级)(2016年6期)2016-07-02 22:17:33电测与仪表(2016年13期)2016-04-11 11:23:34管理现代化(2016年6期)2016-01-23 02:10:59计算机工程(2015年8期)2015-07-03 12:19:54振动、测试与诊断(2014年6期)2014-03-01 01:14:47
