
基于GRU的电力调度领域命名实体识别方法①
2020-03-22 07:42王汉军
计算机系统应用 2020年8期
吴 超,王汉军
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
1 引言
电力调度是为了使各类电力生产工作有序进行,保证电网对内可以自身安全稳定运行、对外能够可靠供电所采取的一种有效的管理手段.具体工作内容是根据各类信息采集设备反馈的数据信息或监控人员报告的信息,结合电网在实际运行过程中的电流、电压、负荷、频率等相关参数.综合考虑工作中的各种情况,对电网运行状态进行判断,通过系统或是其他方式自动发布操作指令,指挥现场操作人员或自动控制系统进行有效调整,比如调整发电机出力、调整负荷分布、投切电容器、电抗器等,使电网能够持续安全稳定的运行[1,2].
电力领域与互联网的结合,使得电力调度向自动化方向发展的速度加快.长久以来形成的电力调度管理系统在自动化的过程中,需要构建电力领域的知识图谱.在知识图谱的构建过程中,命名实体识别(NER)[3]是知识图谱构建中的一个重要环节,该任务是从互联网、电力调度运行数据中抽取出电力调度领域的命名实体.
命名实体识别是自然语言处理中的一项关键任务,在1995年的MUC 会议上被第一次提出,提出的目的是识别文本中特定的名称或者是有意义的短语[4].
早期的命名实体识别很多都是基于规则和统计机器学习的方法[5,6].最初的时候,需要相关的专家制定命名实体过程中所需要的规则以及相关的知识库,然后采用匹配的方式进行命名实体识别.但是在实际的应用过程中,首先是规则的编写非常困难,并且制定的规则只可以用于特定的任务,并不能重用于其他的任务;并且知识库的编写也是一项很大的工程.因此该种方式的效率比较低下,并不是一种命名实体识别的一项有效技术.
在机器学习发展的过程中,机器学习模型中的最大熵模型(maximum entropy)[7]、支持向量机模型(Support Vector Machine,SVM)、条件随机场模型(Conditional Random Fields,CRF)、隐马尔科夫模型(Hidden Markov Model,HMM)等一系列模型别用于命名实体识别[8–13].机器学习模型的应用在总体上提升了命名实体识别的应用效率和识别的准确率,其中应用较多的模型是隐马尔科夫模型和条件随机场模型,这两个模型在识别效果或是在迁移学习方面取得的效果都好于之前基于规则的方式.但是机器学习模型的局限性也是很明显的,首先根据任务提取很多的特征(特征工程,feature engineering),特征的提取对最后的训练结果有着直接的影响;在训练的过程中也需要大量的时间和大量的资源;而且同规则一样还需要特定的知识库.因此此后发展出的深度学习为命名实体识别提供了更高的效率.
2011 年Collobert 提出基于窗口的深层神经网络模型,该模型自动学习输入句子的特征,不需要像机器学习那样需要人工提取特征,然后通过BP 算法训练参数,性能上超过了前面所提到的算法.但是改模型的局限则是输入句子的长度必须是一样的,而且不能处理文本中句子的上下文相关信息.因此在解决该问题的基础上,RNN (Recurrent Neural Network,RNN)被用于自然语言处理任务,并且在命名实体识别中也取得不错的效果.RNN 基础上发展而来的LSTM 神经网络的良好的序列记忆能力,成了命名实体识别的主要神经网络[14–20].在此基础上LSTM与CRF 所结合形成的LSTM-CRF 模型成为命名实体的基础架构之一,然后在此模型上进行扩展或以此模型为基础进行发展的众多模型在命名实体识别上被用于多个平行领域或是垂直领域.
本文所使用的Transformer-BiGRU-CRF 模型是以BiLSTM-CRF 模型为基础进行改进的模型.因为BiLSTM 在训练中,LSTM 结构单元的多个门的运算复杂性,训练所需要的时间和资源都比较大,因此希望可以使用一种既可以达到BiLSTM 网络所能达到的效果,网络的结构也相对简洁,从而取代BiLSTM模型,通过相关论文与实验的证明BiGRU 模型[21]可以达到相应的要求.另外,在以前的模型训练过程中,首先需要通过Word2Vec 将文本中的句子转换为词向量(word embedding),然后将词向量输入模型进行训练,但是Word2Vec 不能保留文本的上下文信息,而且Word2Vec是基于统计的模型,因此在本文的模型中使用Transformer 模型[22]代替Word2Vec 模型部分,将文本句子直接输入Transformer 中,去掉分词和词向量部分.整个模型为Transformer-BiGRU-CRF 模型,该模型的训练方式使用了2 种训练方式.第1 种方式是Transformer部分不进行训练,直接使用训练好的模型,只训练BiGRU-CRF 部分;第2 种方式是将整个模型一起训练,不使用Transformer 所训练好的模型,最后得到整个模型的参数.
2 Transformer-BiGRU-CRF 模型
Transformer-BiGRU-CRF 模型结构如图1所示,整个模型分为3 个部分.首先通过Transformer 模型进行语料的预训练得到输入语料的语义表示的字向量,然后将字向量序列输入BiGRU 中进行语义编码,最后在CRF 层通过分类得到标签所属的类别.
与传统模型相比,使用Transformer 取代了Word2Vec得到词向量步骤,不再需要Word2Vec 得到词向量之前要先进行分词处理,而是直接将语料输入Transformer模型就可以得到上下文相关的字向量的表示,可以表征字的多样性,增强了句子的语义表示;在BiGRU 阶段,BiGRU 训练的过程中需要的内存资源相对于BiLSTM 会少一些.在训练方式的选择中,第1 种是固定Transformer 模型的参数,只是训练BiGRU + CRF模型部分的参数;第2 种是将Transformer-BiGRU-CRF做为一个整体进行训练,训练整个模型的参数.第1 种训练方式少了Transformer 模型部分的参数训练过程,只需要训练BiGRU + CRF 模型的参数,因此可以减少整个模型的训练时间.
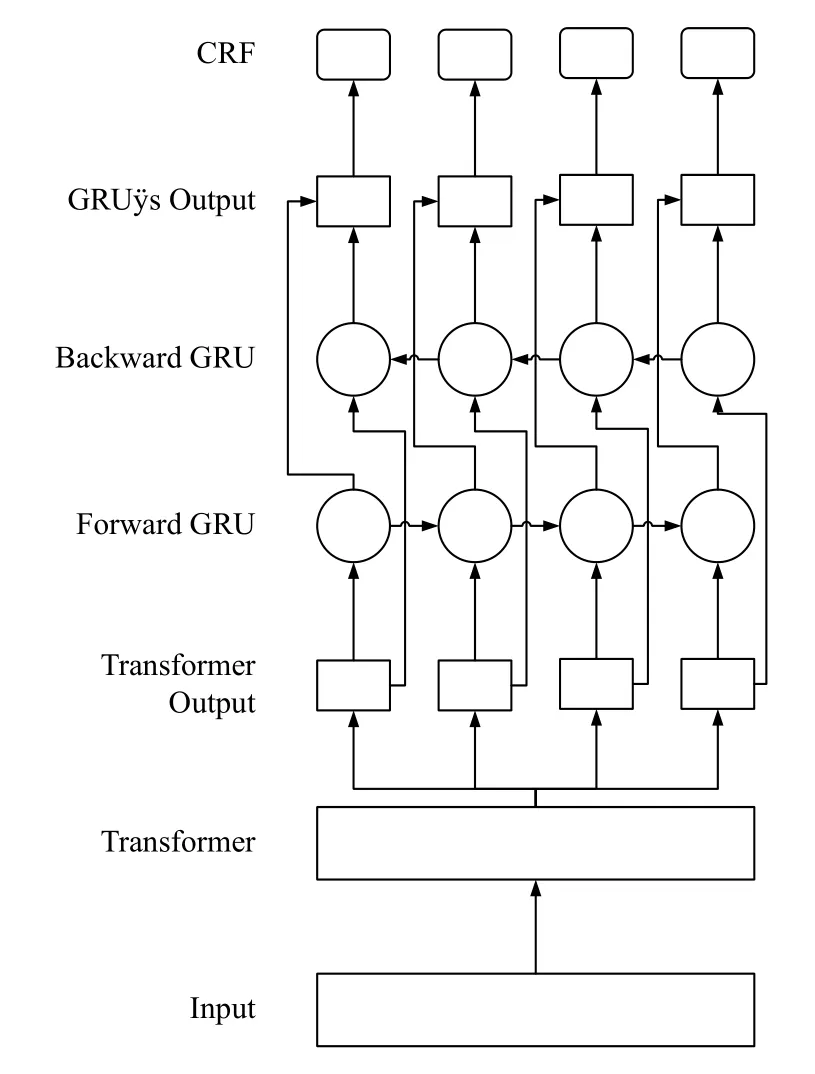
图1 Transformer-BiGRU-CRF 模型
2.1 Transformer 模型结构
Transformer是一种基于encoder-decoder 结构的模型,如图2所示.
在encoder 中,encoder 由6 个layer 组成,即图中的Nx,这里为Nx6,layer 就是图2中的左侧部分.每个layer 由两个sub-layer 组成,它们分别是multi-head self-attention和feed-forward network,每个sub-layer都有residual connection和normalisation,因此sublayer的输出可以表示为式(1):
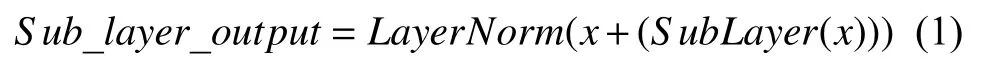
在Decoder 中,有encoder 中的multi-head attention和feed-forward network 部分,除此之外,还比encoder多一个masked multi-head attention,最后经过Linear和Softmax 输出i位置对应的的词语的概率分布.
图2 Transformer 模型结构图
Transformer 在数据预处理部分使用的是positional encoding,将encoding 后的数据与embedding 数据进行求和,加入了文本中词语的相对位置信息,最后学习出一份positional embedding.
在整个Transformer 模型中,self attention 机制起到了很大的一个作用,self attention的表达式为式(2):
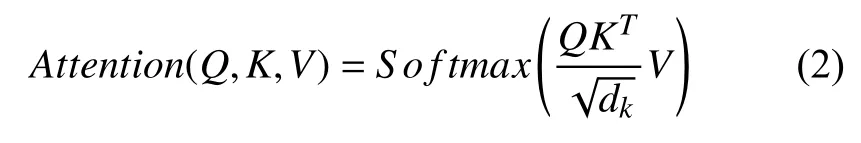
虽然selft attention 机制没有在模型中简单直接的使用,但是使用的multi-head attention是由多个self attention 构成的升级版本,multi-head attention的结构图如图3所示,multi-head attention的表达式为式(3)和式(4):

Multi-head attention 将同一个词向量从多个维度进行self attention,从不同的角度的到不同的结果,最后将不同的结果合并到一个结果中得到一个张量.
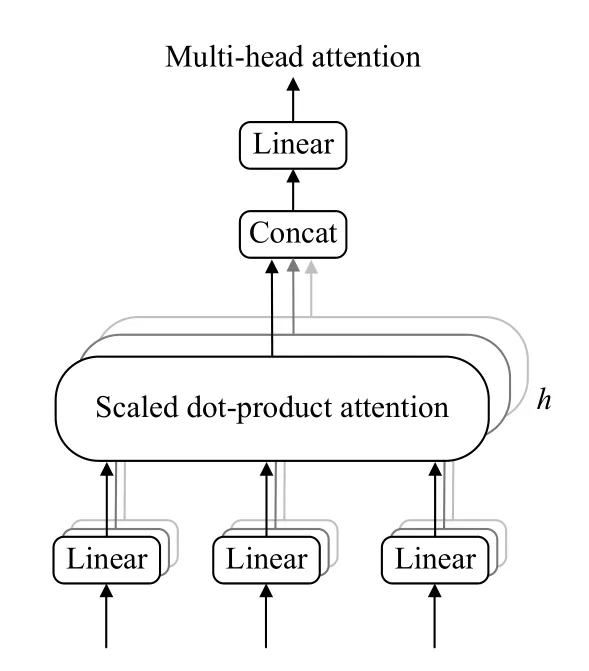
图3 Multi-head attention 结构图
使用Transformer 代替Word2Vec.在Word2Vec中是将一个句子里面的每个单词转化为one-hot vector,再将one-hot vecotr 输入CBOW 模型或是skip-gram模型,然后进行降维处理就得到句子中相关词的词向量.但是Word2Vec 得到的词向量都是长度固定的向量,在任何语境中都被表达成同一个意思;不能够进行多维度的解释一个词语.而Transformer 模型中,在encoder 中对其中的词向量进行multi-head 分析之后,有add&norm 结果的残差处理以及layer normaliztion的归一化处理,最后通过position-wise feed-forward networks 部分进行特征提取和降维,再传入到decoder中,通过对encoder的信息和之前历史时刻经过masked multi-head attention 处理过的output 信息进行处理,最后得到i 时刻的输出,最后得到学习的positional embedding.不仅达到了对句子的序列化处理,更是得到了不同维度的信息,解决了Word2Vec 词向量只能表达同一个意思的问题.
2.2 BiGRU 模型结构
输入层的句子通过转化成字面向量,通过双层的GRU 神经网络模型进行标记,如图4所示.
在解决自然语言处理中,通过引入双层循环来处理序列化数据.在BiGRU 模型中,其结构模型分成3 层,分别是输入层(input layer)、隐藏层(hidden layer)、输出层(output layer),其中在隐藏层部分将双层的细胞单元进行前后相连,使当前节点的信息可以传递到下一个节点,作为下一个节点输入的一部分,用此方式达到序列数据节点的“记忆”功能.
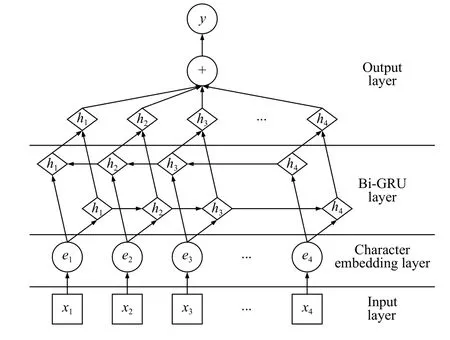
图4 BiGRU 模型
相比于RNN 在处理任意长度的序列时可能发生的梯度消失问题以及难以学习长期依赖特征,GRU(Gated Recurrent Unit)首先是一种特殊的RNN 神经网络,并且GRU是在LSTM的基础上进一步发展而来,因此GRU 可以同LSTM 一样解决需要解决长依赖问题的问题.
如图5所示,xt表示t时刻的输入向量,ht表示隐藏状态,也是细胞单元的输出向量,这个向量包含前面t时刻所有的有效信息.zt表示更新门,控制信息进入下一个状态;因为zt经过Sigmoid 函数激活,所以zt的值为0~1 之间.Rt表示重置门,控制哪些信息需要保留,哪些信息会被遗弃,这两个门共同决定隐藏状态的输出.在GRU 细胞中,其中前向传播计算公式为式(5)~式(9)
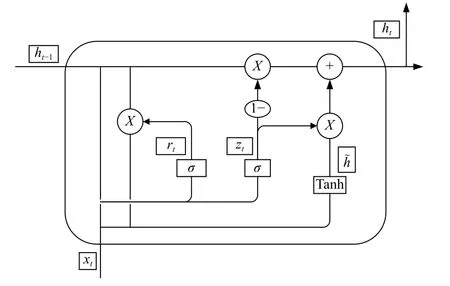
图5 GRU 细胞单元


其中,[]表示两个向量相连,σ表示Sigmoid 函数,*表示矩阵的Hadamard 积.
在模型的训练过程中,前向传播过程中的公式中需要学习的参数有Wr、Wz、Wh˜、Wo,其中公式表示为式(10)~式(12):
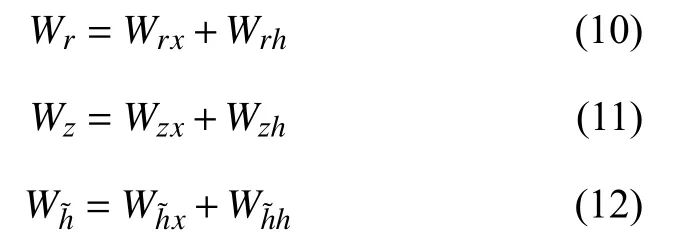
在输出层部分,设在t 时刻输出层的输入为式(13),输出层的输出结果为式(14),损失函数为式(15),那么某个样本整体在训练过程中的损失函数为式(16):
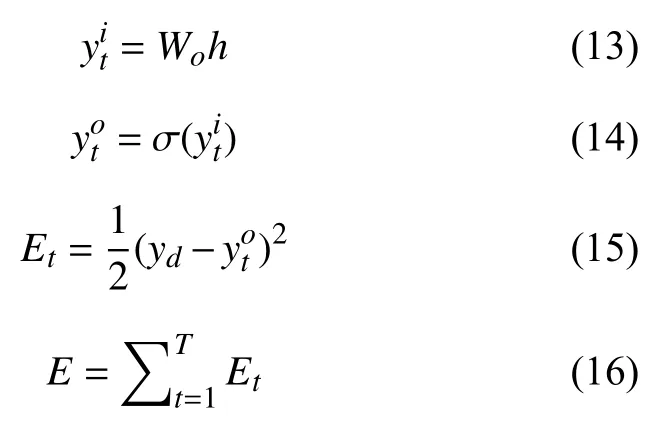
根据式(13)~式(16)可以推导出式(17)~式(28):
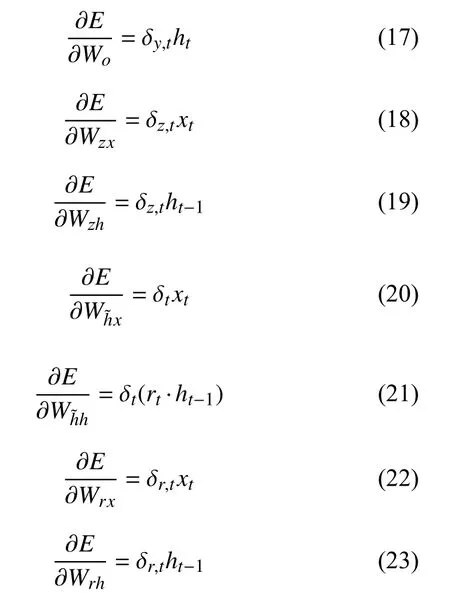
其中,在式(17)~式(23)中,有:

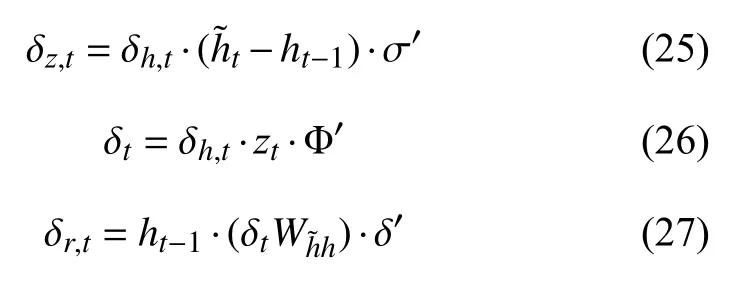
其中,在式(25)~式(27)中的参数 δh,t表示为式(28):
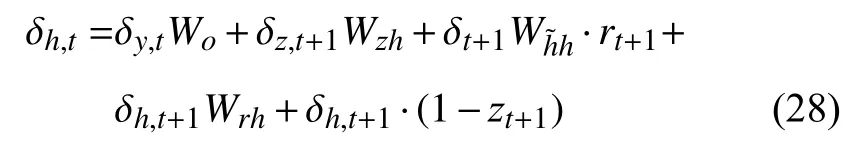
从训练上看,以上训练公式可以知道神经网络的结果最后趋于收敛;从结构上比较,GRU 相比LSTM具有更加简单的结构,门结构只有了更新们和重置门,因此参数也更少,可以加快训练的时间.同时GRU 具有良好的序列建模能力,因此本文将GRU 用于自然语言处理中的命名实体识别.
2.3 CRF 模型结构
CRF (Conditional Random Filed)由Lafferty等于2001年提出,结合了最大熵模型和隐马尔可夫模型的特点,是一种无向图模型,在分词、词性标注和命名实体识别等序列标注任务中取得了较好的效果.条件随机场是一个典型的判别式模型,其联合概率可以写成若干势函数联乘的形式,其中最常用的是线性链条件随机场.若让x=(x1,x2,···,xn)表示被观察的输入数据序列,y=(y1,y2,···,yn)表示一个状态序列,在给定一个输入序列的情况下,序列标注通常公式化为式(29),tk(yi−1,yi,x,i)是一个转移函数,代表在标注序列中,第i–1 个和第i个的标注与整个观测序列之间的特征关系;sl(yi,x,i)是一个状态函数,代表标注序列中第i个标注于此时相对应的观测序列中的值的特征:λj和µk的值均是从训练数据中进行估计,较大的负值代表其对应的特征模板可信度低,而较大的非负值代表其队形的特征事件可信度高,其中Z(x)代表归一化因子,公式为:
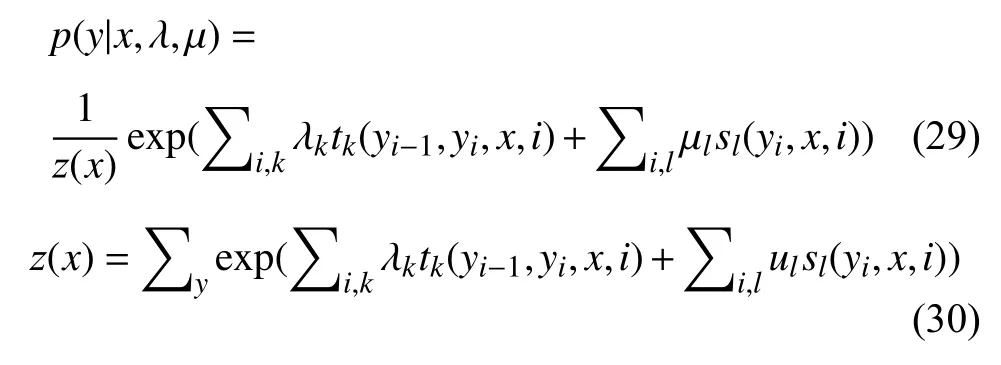
最终的最优化输出序列计算公式为:
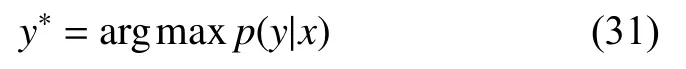
以往的研究表明,特征选择在传统的概念抽取中起着重要的作用.NER的性能在很大程度上取决于不用意见的领域知识的构建和研究.
3 实验分析
3.1 数据
本文数据集来源于某电网公司内的电力调度方面的数据.该数据集包含训练集和测试集两个部分,其中训练集包含34.2 K 个句子,1547.8 K 个字;测试集包含2.9 K 个句子,109.3 K 个字.
3.2 标注策略与评价指标
命名实体识别的标注策略有BIO 模式、BIOE 模式、BIOES 模式.本文采用BIOES 标注策略,其中B(Begin)表示实体开始,I (Intemediate)表示中间部分,O(Other)表示其他与标记无关的字符,E (End)表示结束,S (Single)表示单个字符.
命名实体识别的评价指标有准确率(P)、召回率(R)和F1 值.公式中的参数定义如下:Tp为模型识别正确的实体个数,Fp为模型识别出的不相关的实体个数,Fn为相关的实体但是模型没有识别出的个数,其中公式表示为式(32)~式(34):

3.3 实验过程
Transformer-BiGRU-CRF 模型的训练方式有2 种.第1 种方式是将Transformer 模型的参数进行固定,只训练BiGRU和CRF 模型的参数;第2 种方式是训练Transformer-BiGRU-CRF 整个模型中的所有参数.实验过程中会使用这两种方式进行试验验证.
在第1 种训练方式中,Transformer 模型部分不进行训练,只训练BiGRU和CRF 部分,BiGRU的输入层根据语料句子的最大长度设定为20 个输入,但在实际训练过程中根据句子长度实际变化,多出的部分直接进初始化为0,中间层根据多次训练尝试的结果设定为40 个单元,训练的参数规模达到900 MB 级别,训练的轮次达到15 000 次.在第2 种方式中,transformer 模型部分也跟着训练,其中共有6 个encoder和6 个decoder共12 层,12 个multi-head attention,共有110 MB的参数数量,因此加上transformer 部分的参数,整个模型的参数规模达到1200 MB 级别,最后的训练轮次达到17 500次级别.但两种训练方式都进行了20 000 轮次的训练,在训练的过程中记录下每一轮的训练后的准确率,最后两种方式的准确率如图6所示.从图中可以发现,在使用T–1 方式训练的时候,开始时准确率比T–2 方式的准确药膏,并且可以较快的将模型训练训练完毕;使用T–2 训练方式的时候,模型的准确率提升速度较快,并且最后的准确率高于T–1的训练方式.
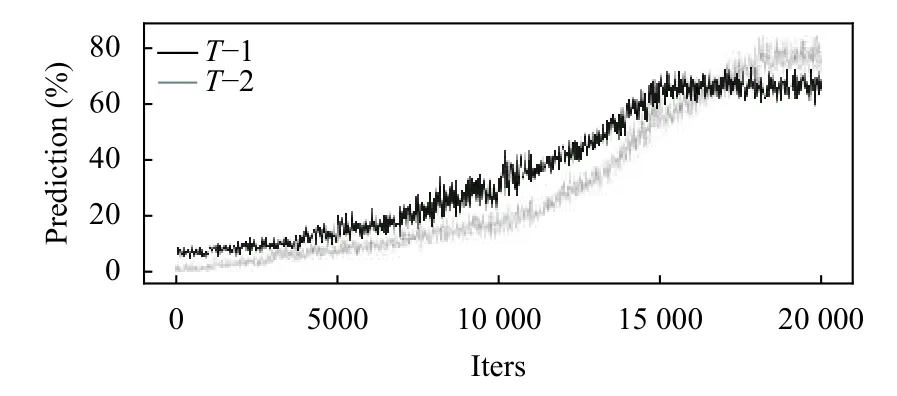
图6 T–1和T–2的准确率
3.4 实验结果分析
将该模型与以下几个模型进行对比,从表1中的实验结果可以发现,基于深度学习的LSTM和GRU 模型在总体效果上都好于基于机器学习的CRF 模型.在训练的过程中发现,基于BiGRU 模型与基于BiLSTM模型在准确率上差距不大,但是在训练过程中发现基于BiGRU 模型训练所需要的时间比基于BiLSTM 模型所需要的时间少.最后通过Transformer 代替Word2Vec最后的准确率相比BiGRU-CRF 模型有着较大的提升.

表1 各个模型的对比结果(单位:%)
4 结论与展望
本文通过将机器学习模型C R F和深度学习Transformer、BiGRU 进行结合的Transformer-BiGRUCRF 模型用于电力调度领域的实体命名识别.为了电力调度专业领域的命名实体识别,使用Transformer的字符级别向量化代替Word2Vec的词向量化,可以联系文本中字符间的含义;BiGRU 相比于BiLSTM 可以减少模型的训练时间.最后得到的结果相比于用于通用领域模型的结果,该模型具有更好的效果.但是该模型在电力调度领域没有达到预期中与通用领域接近效果,为了提高该专业领域命名实体识别更好的效果,以后需要在更多的地方做出改进.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
中国诗歌(2017年12期)2017-11-15
