
复杂噪声中基于MFCC距离的语音端点检测算法
2020-03-19 13:10:44韩云霄符玉襄
计算机工程 2020年3期
韩云霄,邵 清,符玉襄,郭 庆
(1.上海理工大学 光电信息与计算机工程学院,上海 200093; 2.中国电子科技集团公司第三十六研究所,浙江 嘉兴 314000)
0 概述
端点检测也称话音活动检测,主要目标是检测输入信号中语音的起止点,完成语音与非语音的分离。在语音识别中,背景的复杂噪声会严重影响语音信号的可懂度和识别性能,而提升复杂噪声中端点检测的准确率可以减少语音识别工作的计算量,并且提高识别结果的准确率。同时,对于某些需要不间断、长时间人工值守的通信侦察、无线电监听等特殊应用场景,端点检测可以显著减少人工复听或监听的工作量。
目前语音端点检测可分为两类:一类是以机器学习[1-3]、深度学习[4-6]、建模[7-9]等为基础的模式识别方法,另一类是基于语音特征[10-11]直接进行分类的规则性语音端点检测方法。在复杂噪声环境下,第1类方法相比于第2类方法具有更高的准确率,但是它需要对海量数据样本进行训练,且抽取的特征需要具备全面、精准的特性,算法相对繁琐,计算量较大。因此,该方法不适用于实时应用。基于语音特征的方法计算复杂度相对较低,且具有响应速度快、实时性高的优点,更符合实际应用的需求。
语音噪声可分为加性噪声和卷积噪声。针对加性噪声,文献[12]在语音的端点检测过程中,先对含噪语音使用最小均方(Least Mean Square,LMS)误差自适应滤波减噪,再利用双参数双门限进行平滑处理,提高了在低信噪比环境下检测结果的准确率与稳健性。文献[13] 采用分类和回归树(Classification and Regression Tree,CART)利用多个特征进行语音端点检测,并在语音拨号手机的隔离语音识别算法中进行验证,结果表明,在低信噪比环境中采用多种特征的方法比使用单一特征的方法效果更好。针对卷积噪声,文献[14]使用卷积传递函数估计语音和房间脉冲响应幅度谱图,通过学习模型进行2个阶段的迭代,其处理的数据在算法中能获得更优的去噪效果。
实用的语音识别系统需要在复杂噪声环境中具有较强的鲁棒性和较快的计算响应速度,但因为短时能量特征极易将复杂多变环境中的非平稳噪声误判为语音,而计算复杂度低、实时性高的过零率特征对噪声鲁棒性较差,所以只利用单一的语音特征很难处理复杂的噪声情况,目前研究者一般都采用双门限算法。本文采用多个特征进行算法判定修正,以MFCC距离特征作为主要判断依据,同时结合其他特征的优势,建立组合规则,通过自适应噪声模型匹配方法实现复杂噪声中语音信号端点的准确检测。
1 多维语音信号特征参数计算
1.1 语音信号的预处理
由于实际的语音信号是模拟信号,因此在对语音信号进行数字处理之前,首先要将模拟语音信号s(t)以采样周期T采样,将其离散化为s(n),采样周期的选取应根据模拟语音信号的带宽(奈奎斯特采样定理)来确定,以避免信号的频域混叠失真。
对离散后的语音信号进行量化处理的过程会带来一定的量化噪声和失真。语音信号的频率范围通常是300 Hz~3 400 Hz,一般情况下取采样率为8 kHz。本文对语音信号的预处理过程包括重采样、加窗以及分帧。
重采样的目的是将输入语音信号的采样率统一为8 kHz,以方便后续处理。设语音波形时域信号为x(n),加窗函数为w(n),分帧处理后得到的第i帧语音信号为yi(n),则yi(n)满足:
yi(n)=w(n)×x((i-1)×Linc+n)
1≤n≤L,1≤i≤fn
(1)
其中:w(n)为窗函数,一般为矩形窗或汉明窗;yi(n)是一帧的数值,n=1,2,…,L,i=1,2,…,fn;L为帧长;Linc为帧移长度;fn为分帧后的总帧数。
对yi(n)进行傅里叶变换,计算MFCC距离,使用滤波器和归一化处理数据使得其能更好地匹配建立的模型,并以短时过零率、短时能量和MFCC距离差分累加和这3个特征作为判定条件,对语音信号和非语音信号进行数值判断并标识。
1.2 短时过零率
语音信号的短时过零率是指单位时间内信号波形穿过横轴(零电平)从而改变符号的次数。当窗起点为i=0时,信号的短时过零率用Z0表示,它对相邻2个取样点改变符号的次数进行求和,计算如下:
(2)
其中,sgn[x]为符号函数,其含义为:

(3)

在复杂噪声环境中,单一过零率特征不具备良好的辨别特征,尤其是在强噪声环境中,过零率数值的持续增加,在一定程度上增加了语音与噪声的判别难度。
1.3 短时能量
短时能量是短时平均能量的简称,语音信号进行分帧等预处理后,每一帧的短时能量值等于该帧内样点值的平方和。计算第i帧语音信号yi(n)的短时能量公式为:
(4)
短时能量特征参数在以下几方面具有较好表现:1)可以作为区分清音和浊音的特征参数;2)在信噪比较高的情况下,短时能量可以作为区分有声和无声的依据;3)在复杂噪声环境下,可以作为辅助的特征参数与其他特征参数相结合用于语音识别。
1.4 MFCC距离差分累加和
由于环境复杂多变,因此在语音信号中可能同时存在加性和卷积两类噪声。为了把卷积噪声转换为加性噪声,本文采取倒谱分析方式,等同于求取语音倒谱特征参数。通过对时域语音信号做傅里叶变换,取对数,然后再进行反傅里叶变换,最后得到加性时域信号。倒谱分析可以分为复倒谱、实倒谱和功率倒谱,由于在语音信号领域功率谱特征性明显,因此本文采用功率倒谱进行倒谱分析。
1.4.1 MFCC特征
MFCC与普通实际频率倒谱分析不同,其着眼于人耳的听觉特性,Mel频率与实际频率的具体关系公式计算为:
Mel(f)=2 595lg(1+f/700)
(5)
其中,f为实际频率,单位是Hz。
为了将卷积信号转换成加性信号,需要把预处理后的信号yi(n)进行从时域到频域的转换。首先计算其幅度谱Yi(k),计算公式为:
(6)
其中,L是帧长,K是DFT长度。
然后计算其功率谱Pi(k),公式如下:
(7)
由此得到频域特征值Pi(k)。本文通过Mel滤波器组对频域的幅值进行精简,去除冗余的频域信号,使得每一个频段用一个值来表示。
由于人耳对声音的感知与信号幅度大致呈对数关系,通过取对数运算,可以使语音信号呈现线性关联。
本文取Mel滤波器系数为Xmel,与功率谱相乘可得滤波后的信号频域值MelValue,然后对其进行log运算使得MellogValue更符合人耳对声音的辨识关系。
MelValue=Xmel×Pi(k)
(8)
MellogValue=lg(MelValue+eps)
(9)
式(9)中使用eps函数增加取对数后频域信号精度。
1.4.2 MFCC距离特征累加和
为了保存数据原始特征,加快计算速度,本文未采用常规MFCC方法。常规MFCC方法通过离散余弦变换(Discrete Cosine Transform,DCT)来获取频率谱的低频信息,并且对数据进行降维压缩,获得最后的特征参数,本文采取对滤波后取对数的数据MellogValue进行中值滤波和平滑滤波的措施,从而得到Ci,直接对相邻帧的特征参数进行差分运算,公式如下:
dt=Ci-Ci-1
(10)
通过条件判定计算MFCC累加和并作为语音端点判定条件之一,其伪代码如下所示:
算法1Sum of MFCC Distance
输入对数运算结果MellogValue;
输出差分累加和distanceFinal
1:function Valuefiltering(MellogValue)
2: CiMellogValue
3:return Ci
4:function sumDifferencing(Ci,Mi)
//Mi(n)是模型值
6:dtCi
7:while dt>0 do
9:return distance&sum
10:function Ranging(oldDistance,distance,sum,mZ,mE)
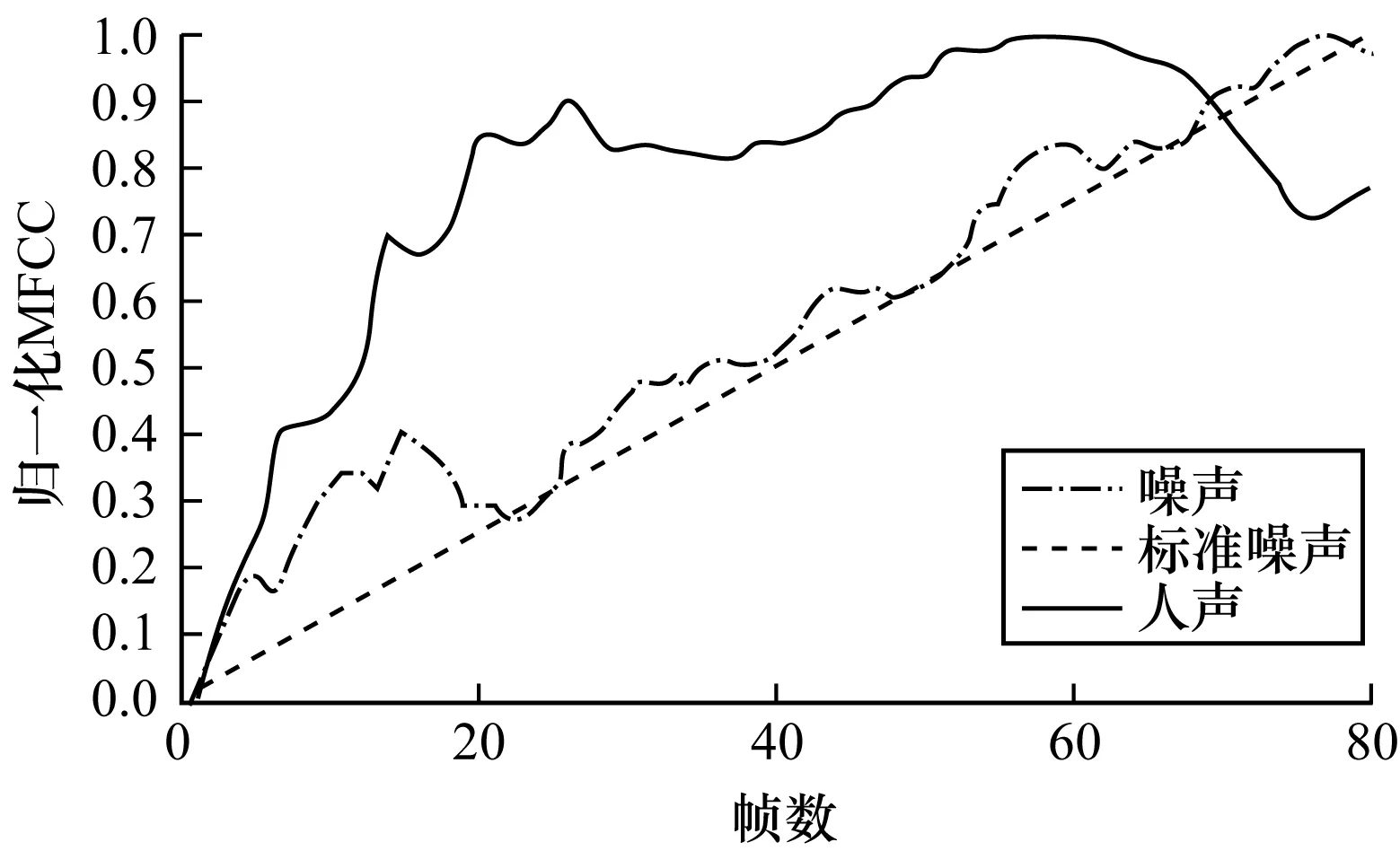
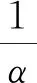
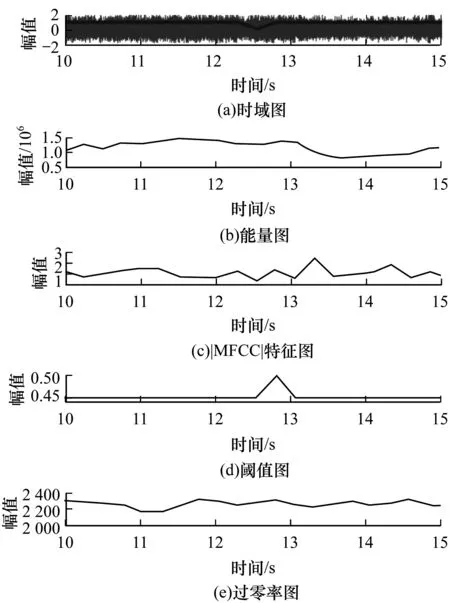
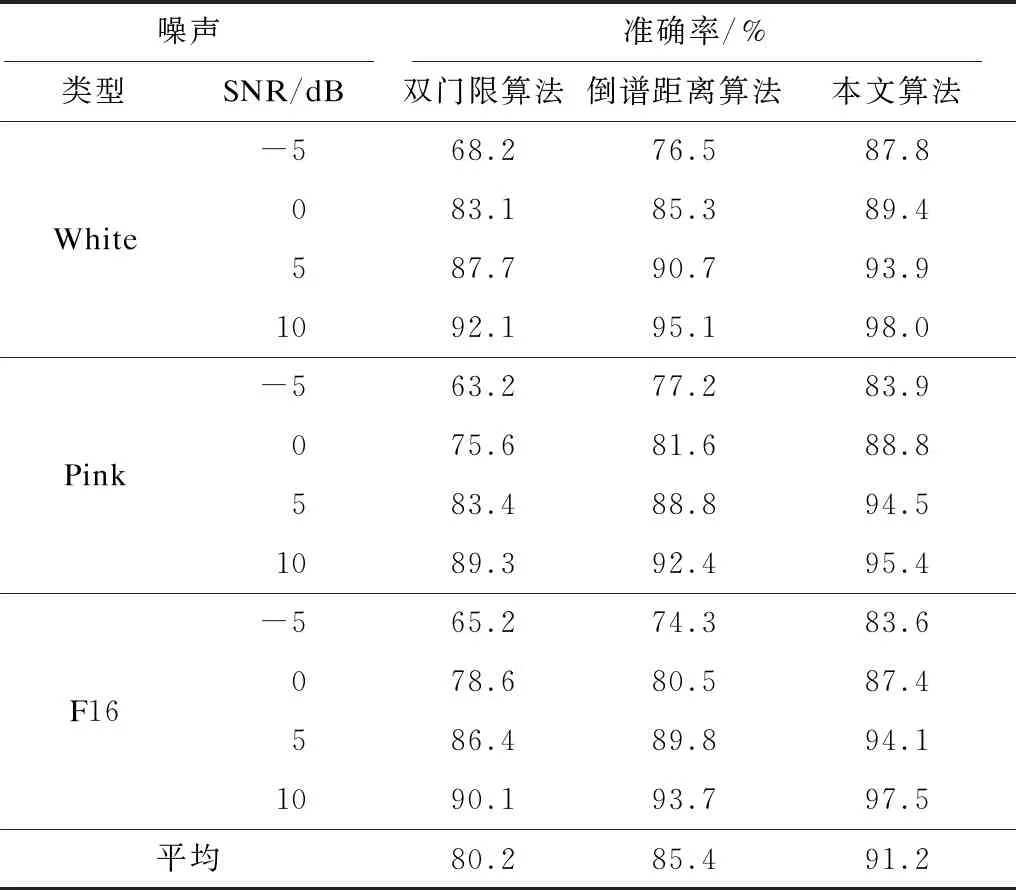
11:while distance>oldDistance||distance 13:else 15:return distanceFinal 自适应噪声模型在普通噪声模型的基础上,对模型参数进行阈值判定并更新,使其能更灵活地应用于各类噪声模型。假设在某段连续的短时间内,复杂噪声MFCC距离值Mp(i)的概率密度函数符合如下公式: (11) (12) λ值越小,说明MFCC距离分布越集中,即MFCC距离波动越平稳。 Mp(i)占信号主导地位的时间极短,所以,本文将在短时内的值作为噪声特征。根据大量实验数据分析,本文假定噪声特征在500 ms ~700 ms(设其包含l帧)内保持分布的同一性,并根据其中前80 ms~400 ms信号(设其包含r帧)MFCC距离值对均值μ和均方差σ进行估计。μ和σ计算如下: (13) (14) 其中,n-1为前r帧的总采样点数。 滑动分析窗长度为l帧,由前r帧信号预估噪声模型参数,并确定阈值θ。 (15) 其中,α(0<α<1)表示灵敏度系数,可根据不同情况适当修改。根据阈值θ,检验后l-r帧信号的MFCC距离特征符合噪声还是语音。每新输入一帧信号,分析窗滑动至下一帧,并校正分布模型,重新计算μ、λ和θ,自适应噪声模型如图1所示。 图1 自适应噪声模型示意图 在语音信号端点检测领域,特征提取极为重要,可以从时域进行特征提取,例如短时能量、熵等,也可以从频域提取特征,例如Mel谱系数、差分熵等。为了最大程度地优化规则,本文对语音特征的选择原则是:被选特征应尽可能从多个方面反映语音信号和噪声信号之间的差异。虽然每个特征都能在其特定环境中作为最优端点检测手段,但是在其他环境下并不能保证总是有效。本文采用的短时能量特征、短时过零率特征和MFCC距离,相互间冗余性小,增强了端点检测的鲁棒性,且这3个特征计算复杂度为O(n),计算响应速度较快,对于实时应用更好。 基于MFCC距离匹配的算法具体步骤如下: 步骤1对语音信号进行降低采样率、预加重和分帧操作,帧长0.5 s,帧移50%,完成预处理过程。 步骤2对第m帧信号加窗并进行N点(N≥4 096)离散傅里叶变换,获得离散变量,便于其他变量计算使用。 步骤3计算各频谱分量的短时过零率Zm,作为特征之一。 步骤4计算各频谱分量的能量Pm(k)(0≤k 步骤5通过在Mel刻度上均匀分布的三角带通滤波器组与Pm(k)相乘,并求其对数,得到本文MFCC特征。 步骤6对MFCC进行中值滤波和平滑滤波,使得数据能具备良好的分离性能。 步骤7计算MFCC差分累加和。 步骤8计算阈值。 步骤9计算MFCC距离Lm并根据距离阈值θ和θ+η修正,得到Ln。 步骤10若Ln>θ,则该点为语音,否则标注成噪声。 步骤11输出结果。 由于数据形式非单一性,存在多种复杂环境,因此本文通过多次滤波与归一化处理后,使得差分MFCC距离值与所建噪声模型能进行相似度匹配与分离。 本文数据集来自实际样本和TIMIT标准语音库,每组信号长度不等,采样率不同。标准语音库语音样本所含背景白噪声来源于NOISE92标准噪声数据库。为了使得数据具有可比性,本实验将采样率调整至相同频率(8 kHz)并截取等长数据段(3.84 s)进行数据分析。 取N=4 096的实际噪声样本和同样长度TIMIT标准人声语音样本,频率降采样至8 kHz,在基于MFCC距离匹配的算法中计算归一化平滑MFCC,结果如图2所示。 图2 噪声、标准噪声和人声对比曲线 通过大量实验,对噪声建立模型函数如下: 图3为一个端点检测实例,输入信号截取自45 s语音中的5 s,内容为一段信息播报,整段录音全部存在强噪声,主要为实录的强电磁流噪声。在区间10.00 s~12.29 s和12.54 s~15.00 s中,有语音(男声)且语音能量较弱,基本被强背景噪声所掩盖;在区间12.29 s~12.54 s中,无话音,为说话停顿间隔。在实际应用中,为了避免因漏检语音段而造成无法挽回的损失,本文适当放宽语音判定阈值。 图3 端点检测实例 图4为TIMIT库中SA类型测试库中2种女生纯声语音实例。在图4(a)中,flag为人工标注,flag=0为噪声,flag=1为语音。SA类型针对同一音素在不同方言中的发音进行测试,语音内容为“She had your dark suit and ingressive wash water all year.”。从实验数据可以看出,发音方法也是影响语音检测的因素。本文方法针对轻音也能准确检测出语音端点。 图4 TIMIT语音库2种纯清音方言语音检测结果 Fig.4 Detection results of two pure voiceless dialects in TIMIT speech database 为比较本文算法与双门限能量检测[15]和倒谱距离[16]这2种经典算法的性能差异,在多种环境条件下进行大量实验,算法准确率以标注出语音信号帧数为评判标准,即准确率为正确标记语音信号帧数占人工标定有效语音总帧数的比例。 如表1所示,传统的双门限算法在较低信噪比情况下已经无法正常工作,虽然倒谱距离算法在某些情况下性能优于双门限算法,但依旧无法满足实际应用需求。 表1 多种噪声环境语音信号截取准确率比较 Table 1 Comparison of speech signal interception accuracy in various noise environments 噪声准确率/%类型SNR/dB双门限算法倒谱距离算法本文算法White-568.276.587.8083.185.389.4587.790.793.91092.195.198.0Pink-563.277.283.9075.681.688.8583.488.894.51089.392.495.4F16-565.274.383.6078.680.587.4586.489.894.11090.193.797.5平均80.285.491.2 本文算法相比于对比算法在性能上有以下改善: 1)在3类噪声环境下信噪比越高识别准确率越高。这是因为本文采用自适应阈值来浮动定义噪声阈值,以防检测过程中噪声能量骤变影响判断结果,这也是语音在较小信噪比下其准确率依然超过80%的原因之一。并且本文判断算法采用改进的MFCC距离差分累加和算法,具有不压缩数据维度的优点,两者结合更有利于辨别能量近似的噪声和语音。 2)本文算法在白噪声环境下识别准确率效果最好[17],这是由于白噪声具有平坦功率谱的性质,可以当作常数进行处理,特征极其明显。 3)在粉红噪声环境下本文算法准确率提升了9.213%,提升程度最高,这归因于粉红噪声是一种集中在中低频频率的噪声,在一定范围内音频数据波形具有相同或类似的能量,而本文算法结合了短时能量与短时过零率的优势能更好地辨别能量相似的噪声。 在实验过程中仍然会出现一些轻声误判现象,因此可以考虑在阈值更新阶段加入清辅音[18-19]检测来进一步提高识别的准确率。 在实际应用环境中噪声变化多样,采用单一特征无法满足语音端点检测准确率需求。本文通过观察大量信号,分析各个特征的特点,结合MFCC、短时能量和短时过零率对传统算法进行改进,设计一种新的算法实现语音端点检测。实验结果表明,该算法在复杂噪声环境中能够有效避免如瀑布、下雨、机舱运转等环境影响,在信噪比较低的情况下,大幅提升准确率,并且在信噪比较高的诸如办公室电话录音、访谈等环境下均能精准地识别结果。但在本文实验中,一些有规律的响声也可能被判断为语音。下一步将针对该问题,使用模式识别方法对规律进行提取,判断其是否包含特定信息信号,若为无用信号则可根据小波变换进行滤波处理。2 自适应噪声模型的建立

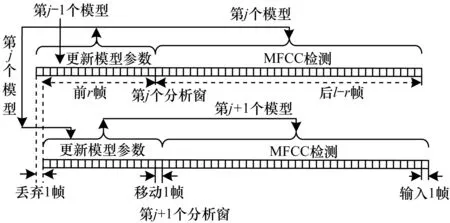
3 基于MFCC距离匹配的检测算法
4 实验与结果分析
4.1 实验数据集
4.2 噪声模型校验
4.3 多样性实验

4.4 对比实验
5 结束语
猜你喜欢
数学物理学报(2022年2期)2022-04-26 14:08:34健康之家(2021年19期)2021-05-23 11:17:39医学食疗与健康(2021年27期)2021-05-13 18:46:23农业科技与信息(2021年2期)2021-03-27 07:27:38中学生数理化·教与学(2019年8期)2019-09-18 15:08:40阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44电子制作(2019年14期)2019-08-20 05:43:38电子制作(2019年9期)2019-05-30 09:42:10小说界(2018年5期)2018-11-26 12:43:42中国交通信息化(2018年5期)2018-08-21 03:37:40
