
基于机器学习的文本情感倾向性分析
2020-03-18 03:44陈平平耿笑冉谭定英
计算机与现代化 2020年3期
陈平平,耿笑冉,邹 敏,谭定英
(广州中医药大学医学信息工程学院,广东 广州 510006)
0 引 言
随着互联网的发展,网络已经成为人们生活所必需的部分。越来越多的人在不同的网络平台上发表自己的评论及观点[1-2]。这些评论多是以文本方式出现,从而使文本分类成为处理和组织大量文档数据的关键技术[3]。利用计算机进行文本的分类成为自然语言处理和人工智能领域一项非常有意义的研究课题[4]。从大规模的电影评论信息文本中进行情感倾向性分析,分析文本所蕴含的情感以及判断该电影评论文本对电影的看法,是当前自然语言处理所应研究的一个主要方向,其对于研究电影的口碑、进行电影推荐也具有非凡的意义[5]。
近年,基于机器学习的文本情感分类被应用于更多的领域[6-7]。例如:Opinion Observer通过对网络上的丰富评论资源进行分析处理,提取出消费者对其产品的评价,并给出可视化结果[8];TMSVM,完整的基于Libsvm与Liblinear的文本分类系统,直接输入训练样本,并配置相应参数,即可进行建模及预测[9]。
在国内的基于机器学习的文本情感分类研究并不是很多,但也存在着不少的研究成果。例如,THUCTC是由清华大学自然语言处理实验室提出的中文文本分类工具包[10-11],能够高效地实现用户自定义分类语料的训练、评测、分类功能,对于开放领域的长文本具有良好的普适性,不依赖于任何中文分词工具性能,具有准确率高、测试速度快的特点[12]。
1 情感倾向性分析
1.1 情感倾向性分析的基本原理
情感分析又称意见挖掘,按照处理文本的粒度不同可以分为词语级、短语级、句子级和篇章级[13-14]等,通过结合文本挖掘、信息抽取、机器学习、自然语言处理等文本处理技术对主观性文本进行分析、处理和归纳[15]。情感分析近几年持续成为自然语言处理领域研究的热点问题,可以广泛应用到很多的自然语言处理问题中,如信息抽取、自动问答、产品口碑等。目前,情感倾向性分析领域主要存在2种方法[16]:
1)基于情感词典及规则的无监督学习方法。
情感词典是按照不同的情感倾向对情感词分类后的词典[17]。基于情感词典及规则方法,顾名思义,即按照人工构建的情感词典和指定的相关规则来进行情感倾向性判定的方法[18]。
但是,在语义复杂的情况下,情感词典无法做到很好地分辨出各种词语的语义,会有很大程度上的错误,而基于机器学习的情感分析便能更好地解决这种情况[19]。
2)基于有监督的机器学习方法。
由于情感倾向性判别的识别结果是褒义、贬义等类别,因此该任务可以采用机器学习的方法,作为分类任务完成[20]。在这种方法中,首先,一般以词汇(例如一元特征)或数字(例如情感词出现次数)等作为特征[21],对标注好的训练语料进行特征提取;然后结合学习模型,典型的例如朴素贝叶斯、最大熵、支持向量机、逻辑回归,对语料进行模型训练;最后通过训练出的分类器对测试语料进行分类[22-23]。
1.2 情感倾向性分析的基本流程
情感分类模型的建立,便是通过对文本进行人为地分类,将评论数据人为地分为正面以及负面的2种情况,并以此为训练集,通过用机器学习的方法,实现对训练集的训练,比较各种方法的准确率,得出最优的算法,作为情感分类模型。其流程如图1所示。
如图1所示,情感模型的建立主要是训练以及测试2大部分,先用训练集训练模型,然后经由测试集测试模型的准确率,通过比较各分类模型的准确率,得出最优情感分类模型。
2 文本预处理
文本预处理就是将原始的文本数据处理成适合机器学习算法训练的过程,其包括分词、停用词处理、数据集标注、特征选择、特征提取等过程,经由这些处理之后,能够将原始数据放于机器学习算法中训练。其文本预处理流程如图2所示。
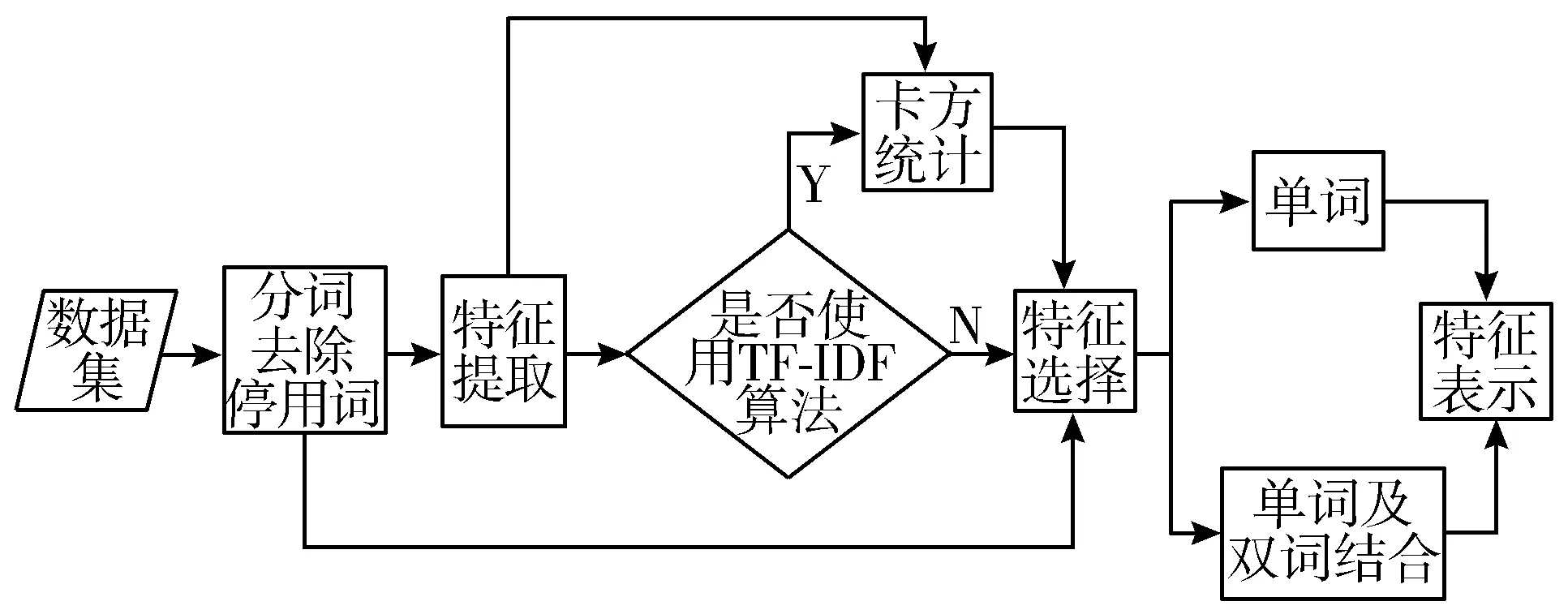
图2 文本预处理流程图
2.1 数据爬取
本文通过实现豆瓣的模拟登录和Python的beautifulsoup4实现对豆瓣多部电影评论网页内容的解析,然后通过find函数实现对评论内容以及评论分数的抓取,最终根据分数的高低,分为正面以及负面2种评论,分别存入pos_movie.txt以及neg_movie.txt中,其中正面评论57845条,负面评论34700条,其数据保存如下所示:
“人物关系、表演、对白都莫名其妙。时代气氛的展现也够差的”
“超难看,看完很不爽”
“盛誉之下,难负其实。”
……
2.2 jieba分词
中文分词是情感分析的第一步,jieba分词是Python中文分词里面用户较多且效果较好的一种中文分词。
jieba分词具有3种分词模式,分别为精确模式、全模式以及搜索引擎模式。其中,精确模式可以将句子以最精确的方式切分,常被用于情感分析。全模式则是将句子中的词全部分解,尽可能分出全部的词。搜索引擎模式则是将部分还能再分的词切分,得到比精确模式更多的词。
由于本文是做电影评论的情感倾向性分析,故选择jieba分词的精确模式,用jieba的精确模式对全部的电影评论进行切分,其部分的切分效果如图3所示。

图3 用jieba对电影评论切分效果图
如图3所示,jieba的精确模式能把评论都精确地切分出来,其分词效果不错。
2.3 停用词去除
由于每一段评论存在着一些停用词,如“啊”“的”“而”等,这些词的存在并不会对分析用户的情感有帮助,反而因为这些词的高频性,会影响到情感分析的准确性。故此,需要把这些影响分析结果的词去除,防止因为这些停用词的高频性而导致分析的效率降低,从而提高情感倾向性分析的准确率。
目前,网络上存在着大量的停用词表,较为出名的有百度停用词表、哈尔滨工业大学停用词表。本文所用的停用词词典是哈尔滨工业大学停用词表,停用词的加载代码如表1所示。
表1 停用词的加载

1.def get_stopwords(self):2.stopwords=[]3.with open(self.stop_word_path,'r')as f:4.for line in f.readlines():5.stopwords.append(line.strip())6.return stopwords分析:通过这部分代码,读者可以清晰了解到如何利用Python加载哈尔滨工业大学的停用词表。1.定义获取停用词表函数2.创建停用词列表3.打开词典,进行读取4.读取文件中的每一行5.添加停用词到列表中6.返回停用词列表
根据返回的停用词表,去除评论中经过分词的停用词。
2.4 数据集标注
对爬取的数据进行标注,标明其分类的类别,主要做情感倾向性的标注,如正面、负面等,为后期的实验提供数据。
2.5 特征提取及特征选择
情感倾向性分析主要是判断一段语料的正面以及负面性,而作这类的判断主要的依据是特征的正确表征,一件物件的特征很多时候是其与其他物件的本质上的区别。例如,在“感觉很难看,没看懂。刘涛和梁佩诗都是打酱油的角色。”的评论中,“难看”“没看懂”“打酱油”便是这句评论的主要特征,而这些特征也是评论该评论是正面或者负面的主要依据。
在情感倾向性分析中,进行特征选择的方法一般有单词,双词,以及单词、双词组合。例如,“这电影真好看。”经过分词、去除停用词后,最后是剩下“电影”“真”“好看”等词。当使用双词作为特征时,就会有“电影真”“真好看”等特征。
但是,假如不对数据进行特征提取,当数据量达到一定量的时候,特征就会非常多,从而可能影响情感分类的性能,这便需要减少数据的特征,对数据进行降维,即是对数据进行特征提取。常用的特征提取方法有卡方统计、互信息、词频等[12]。本文主要使用的特征选择的方法有卡方统计下的单词、卡方统计下的单词及双词组合、jieba的TF-IDF特征提取下的单词、jieba的TF-IDF特征提取下的单词及双词组合、经过jieba的TF-IDF特征提取然后再经过卡方统计信息量下的单词、经过jieba的TF-IDF特征提取然后再经过卡方统计信息量下的单词和双词组合等6种方法。
2.6 文本表示
由于电影评论文本是以自然语言的形式存在的,机器无法识别自然语言,故此,需要对这些文本进行文本表示,使得其能够被机器识别。如将“真”“好看”这2个特征,表示为:[{“真”:True,“好看”:True},“pos”]。
3 情感分类模型的建立
文本预处理后,通过不同的机器学习算法对已处理的数据进行训练以及测试,及通过对不同算法性能的比较,找出最优的特征提取及特征选择方法,并找出最适合进行情感倾向性分析的算法。
本文所用的机器学习算法有:线性支持向量机(SVM)、多项式贝叶斯(Multinomial NB)、逻辑回归(Logistic Regression)、决策树(Decision Tree)、近邻(K-Neighbors Classifier)、BP神经网络(Back Propagation Neural Network)。
3.1 线性支持向量机算法
SVM是基于统计学的VC维理论与结构风险最小原理的有监督二分类器[13],根据给定的输入数据及学习目标,输入数据的每个样本的特征构成特征空间,学习目标是二元变量,正类与负类,即为情感分析中的正面与反面,寻找一个最优超平面,使2类样本的间距最大,此平面隔离不同类别的样本数据,进而实现分类。
3.2 多项式贝叶斯算法
贝叶斯文本分类算法是一个经典的文本分类算法,要求在事件B发生的情况下事件A发生的概率,可由条件概率公式导出:
使其一般化,集合{Ai}表示事件集合中部分事件的集合,那么:
本文使用后者公式进行多项式贝叶斯模型实验,即[24]:
其中,|V|是训练样本中总单词数,Nki是wk在类别ci文档中出现的次数。
3.3 逻辑回归算法
逻辑回归算法是在线性回归的基础上,将线性模型通过一个函数转化为结果只有0/1的分类模型,依次经过构建函数、寻找决策边界、求解代价函数、梯度下降求偏导4步骤解决文本分类问题。
3.4 决策树算法
决策树是由节点和分支组成的树状图,分支由节点和子节点组成,其中节点代表学习或者决策过程中考虑的属性,最后的叶节点表示分类结果,其核心是一种贪心算法,常见的决策树算法有ID3、C4.5、CART方法。
3.5 K近邻算法
K近邻分类属于向量空间模型,将整个数据集作为训练集[25],通过确定待分类样本与训练样本之间的距离,找出距离待分类样本最近的K个样本作为待分类样本的近邻,然后把待分类样本分到K个近邻中文本数目最多的类别中。
3.6 BP神经网络算法
BP神经网络是一种多层前馈神经网络,具有输入层、隐含层、输出层,它是根据某一种学习规则,不断进行训练,直到达到期望的输出结果时停止。在此模型中输入层为数据训练集,隐含层可以有多层,输出层即为分类结果。在使用此模型训练时,要注意确定参数值及激活函数,进而使模型的准确度更高。
4 实验结果分析
4.1 不同特征选择下算法分类的准确率
本文主要使用的特征选择的方法有卡方统计下的单词、卡方统计下的单词及双词组合、jieba的TF-IDF特征提取下的单词、jieba的TF-IDF特征提取下的单词及双词组合、经过jieba的TF-IDF特征提取然后再经过卡方统计信息量下的单词、经过jieba的TF-IDF特征提取然后再经过卡方统计信息量下的单词和双词组合等6种方法。表2为各种情况下的分类准确率。
表2 各种特征选择下的不同机器学习算法的分类准确率
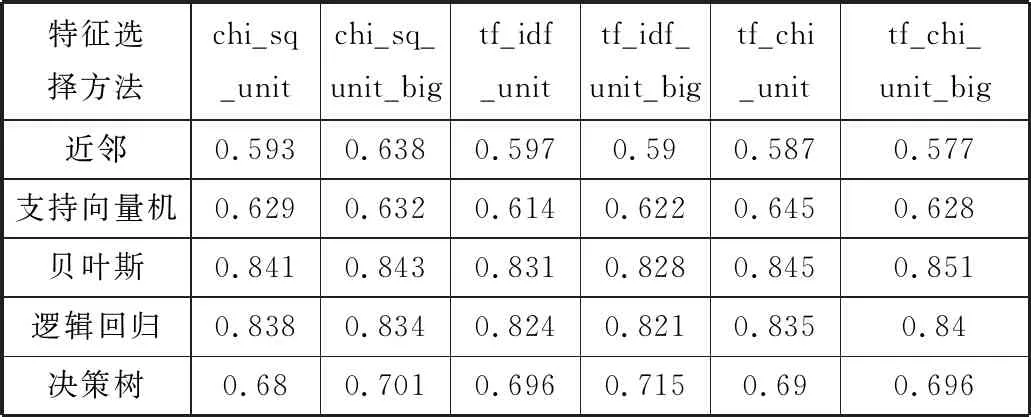
特征选择方法chi_sq_unitchi_sq_unit_bigtf_idf_unittf_idf_unit_bigtf_chi_unittf_chi_unit_big近邻0.5930.6380.5970.590.5870.577支持向量机0.6290.6320.6140.6220.6450.628贝叶斯0.8410.8430.8310.8280.8450.851逻辑回归0.8380.8340.8240.8210.8350.84决策树0.680.7010.6960.7150.690.696
表2中的chi_sq_unit代表的是卡方统计下的单词,chi_sq_unit_big代表的是卡方统计下的单词及双词组合,tf_idf_unit代表的是jieba的TF-IDF特征提取下的单词,tf_idf_unit_big代表的是jieba的TF-IDF特征提取下的单词及双词组合,tf_chi_unit代表的是经过jieba的TF-IDF特征提取然后再经过卡方统计信息量下的单词,tf_chi_unit_big代表的是经过jieba的TF-IDF特征提取然后再经过卡方统计信息量下的单词和双词组合。
其分类准确率图如图4所示。
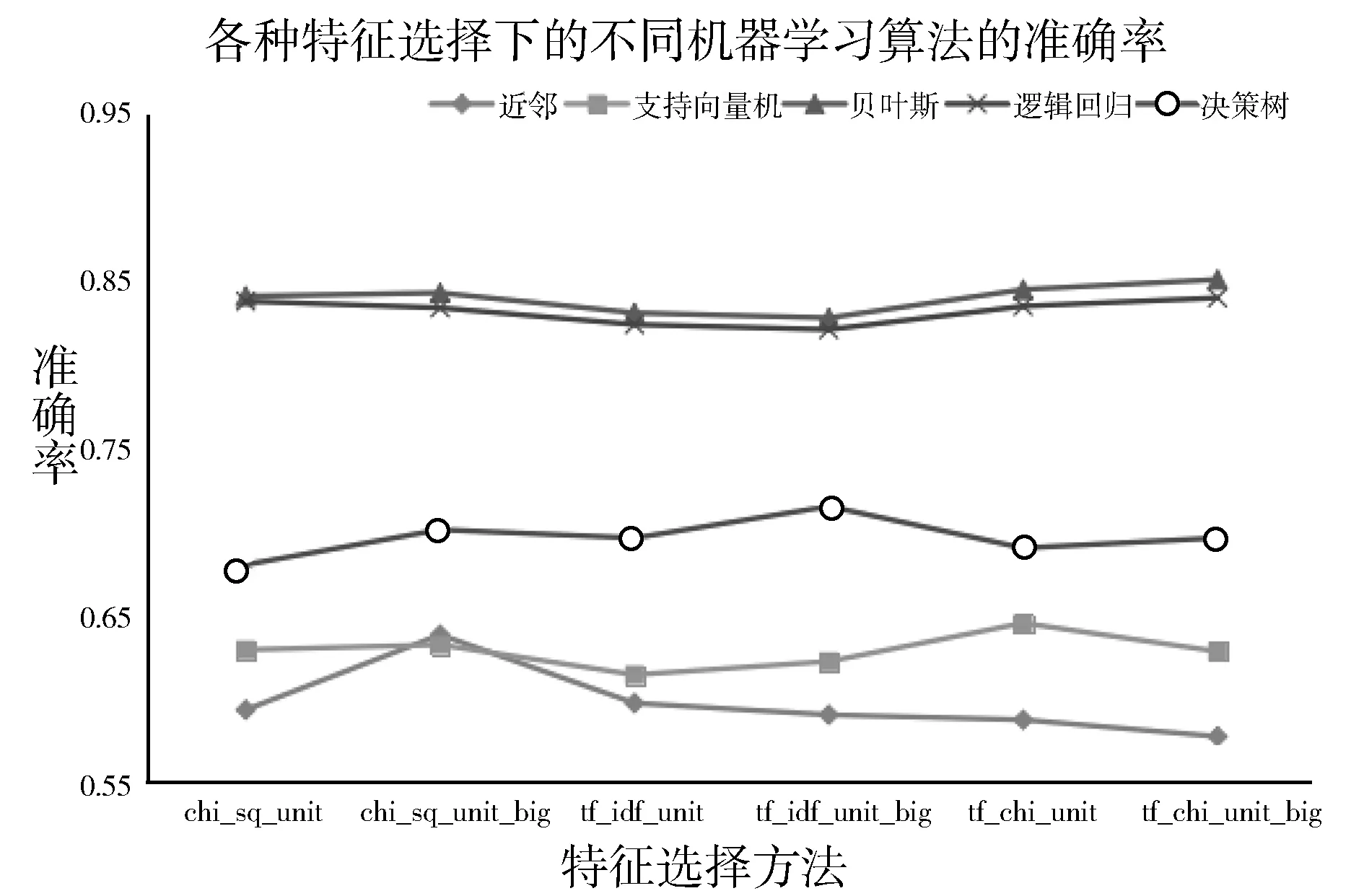
图4 各种特征选择下的不同机器学习算法的分类准确率
由图4可知:
1)多项式贝叶斯、逻辑回归、决策树在进行电影评论情感倾向性分析的时候具有更好的分类效果,这3种算法的分类性能明显好于其他2种算法,更加适用于电影评论情感倾向性分析。
2)相对于单词的特征选择,用单词以及双词组合的特征选择方法能提升分类器的性能,选择建立分类器时应选择单词及双词组合的特征选择。
3)在进行特征提取时,经过jieba的TF-IDF及卡方统计提取较为重要的词具有更好的分类效果,在卡方统计提取较为重要的词次之,只进行TF-IDF特征提取的效果最差。
结合上面的结论可得,在寻找最好的情感分类模型时,在算法上应该选择使用多项式贝叶斯、逻辑回归或者决策树,在特征提取的方面应该使用jieba的TF-IDF及卡方统计相结合的特征提取方法,在特征选择方面应该使用单词及双词结合的特征选择方法。
4.2 不同特征数的算法分类的准确率
在进一步研究时,选择使用jieba的TF-IDF及卡方统计相结合的特征提取方法,在特征选择方面使用单词及双词结合的特征选择方法,并通过调整特征提取的特征数,探究不同的特征数在不同分类器下,对情感分类器的分类效果的影响。
对于BP神经网络,使用了Python的Keras API及sklearn包,将Relu作为激活函数,训练集以及测试集batch-size设置为128、dropout值为0.5来防止过拟合,输出层采用了Sigmoid进行二分类处理,并且采用了梯度下降的优化方法,epoch设置为5,20%数据作为测试集,以上算法分类效果如表3所示。
表3 在不同特征数下各分类器的分类效果

分类器特征数100020003000400050006000贝叶斯0.8140.840.850.8580.8490.844逻辑回归0.8110.8250.8480.8430.8450.843BP神经网络0.8280.8440.8560.8620.8430.833决策树0.7010.7050.7020.6990.7150.709
表3中的1000、2000、3000、4000、5000、6000代表的是使用jieba的TF-IDF及卡方统计进行特征提取的特征数,通过调整特征数的数量,来调整分类器的性能。
由表3可知:
1)分类器的分类效果普遍随着特征数的增加而先变优然后再变差。
2)最好的分类效果出现在特征数为4000,且分类算法为BP神经网络上。
通过对上述的所有实验进行总结可得:
在进行电影评论情感倾向性分析时,以jieba的TF-IDF及卡方统计结合提取出来的较为重要的单词及双词,并且提取的特征数为4000时,在BP神经网络算法的分类准确率最高,而多项式贝叶斯次之,其他的分类模型则效果一般。
5 结束语
随着信息时代的发展,分享成为了时代的主流,人们在各种平台、通过不同的方式,去表达自己的情感,这便产生了各种各样代表着人们情感的文本。如何从大量的信息文本中,挖掘出有用的信息,是机器学习研究的一个大的方向。
本文通过对不同特征提取方法、特征选择方法的结合,以及用不同的机器学习方法对电影评论进行训练及测试,最终得出在经过jieba的TF-IDF及卡方统计提取信息量为前4000的单词及双词作为特征,并使用BP神经网络作为训练的算法使情感分类的效果最好,其准确率为86.2%。
猜你喜欢
有色金属(矿山部分)(2021年4期)2021-08-30
天津医科大学学报(2021年2期)2021-03-29
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
电子制作(2017年23期)2017-02-02
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
语言与翻译(2015年4期)2015-07-18
噪声与振动控制(2015年4期)2015-01-01
