
面向水利信息资源的智能问答系统构建与应用
2020-03-18 03:44张紫璇陆佳民
计算机与现代化 2020年3期
张紫璇,陆佳民,姜 笑,冯 钧
(河海大学计算机与信息学院,江苏 南京 211100)
0 引 言
大数据智能时代到来,各行各业开始向智能化转型。现有的系统中,通过关键字匹配进行检索水利工程对象的基本属性信息得到的结果往往过于宽泛,需要人工排查和筛选,甚至会得到与用户实际需要不相符的信息[1]。为了更好地在水利数据中精确地查找数据,本文设计并开发面向水利信息资源的智能问答系统,实现用户自然语言检索水利工程对象属性基本信息的功能。
在水利领域建立面向水利信息资源的智能问答系统,存在如下的问题和难点:
1)使用语义解析的方式完成智能问答时,用户使用自然语言问句进行查询,而查询知识库需要使用的是SPARQL结构化查询语言。这需要构建一个问答解析器,但这种方式依赖于手工定义的规则以及词汇表等外部支撑,回答范围具有局限性,而且需要多步操作,容易出错,对检索的准确度也有很大影响[2]。
2)水利行业领域问答语料稀少,获取途径不多,难以得到大规模领域语料。缺乏语料阻碍了水利智能化更上一层的脚步。
本文针对以上问题展开研究,在研究语义解析方法上,在现有的解析框架基础上构建问答解析器,将自然语言问句转化成结构化查询语言。针对问答准确率不高的问题,采用依存句法分析代替已有框架中的句法结构分析,完成语义查询图的构建,提高语义解析的准确率。针对水利领域缺乏语料的问题,本文使用语义解析的方法构建问答系统,获得一批问答对语料,在此基础上提出语料扩展方法,构建语料库。
1 相关研究
目前开放领域内智能问答主要有语义解析法和信息抽取法。语义解析法对自然语言进行语义上的分析,将问句转化成SPARQL查询语言[3]。然后通过对应的查询语句检索得到答案;信息抽取法重点是提取问句中的实体,在知识图谱中查询到以这个实体为中心的子图,这个子图当中的任意一个节点、边都是候选答案。依据特定的模板,按规则进行信息抽取,得到能够表示问句、候选答案特征的向量。建立分类器,依据输入的特征向量对所有候选答案进行筛选,得到最终答案。
1.1 语义解析
Zou等[4]提出了一种方法将自然语言查询语句直接转换成语义查询图,使用语义查询图对自然语言问题建模,然后利用子图匹配的方法进行问答,将语义消歧和回答问题这2个步骤结合在一起,利用部分子图匹配的结果进行联合消歧,效果显著。许坤等[5]设计了一套转换框架将自然语言问句转化为结构化查询语句,主要分析句法分析树,构造出查询语义图,对该图中的词语进行消歧,最后转换成SPARQL查询语言,得到答案。针对生物领域内实体的特殊性,为了提高检索的召回率,Zheng等[6]采用语义相似SPARQL查询的方法执行知识图谱的检索。为了降低问题理解的不确定性,Zheng等[7]又提出了一种集成用户交互的方法来实现高效问答。
1.2 信息抽取法
Yao等[8]利用信息抽取法构建问答系统,将知识图谱看作是相互关联的主题的集合。首先提取问题中的问题词,然后使用依存分析将问题转化为语法结构树,将那些对问题不重要的特征删除,确定出答案范围,学习依赖结果和正确答案在知识图谱上子图的匹配模式。
2 查询语言构建
本文借鉴文献[6]中的解析框架,构建符合水利领域需求的问答解析器完成基于语义解析的智能问答。为了提高问句到结构化查询语言的转化成功率,在语义解析框架基础之上给出了构建查询图的算法。针对水利领域,在关系消歧部分采用的是规则映射法与同义词词典法相结合的方法。
2.1 中文分词
中文分词是语义解析的第一步,作用是将问句分解成单独的、不同词性的词语,为后续处理打下基础[9]。本文对知识图谱中存在的所有节点的节点名称建立一个领域词典,包含水利领域的实体名称、属性名称。
2.2 依存句法分析
依存分析的任务是生成表示整个句子的句法关系的依存树[10]。本文采用HanLP基于神经网络实现的高性能依存句法分析器进行依存句法分析。例如查询问句“新安江水库的建成时间是?”,使用HanLP的依存句法分析函数之后,得到依存句法树示例如图1所示。
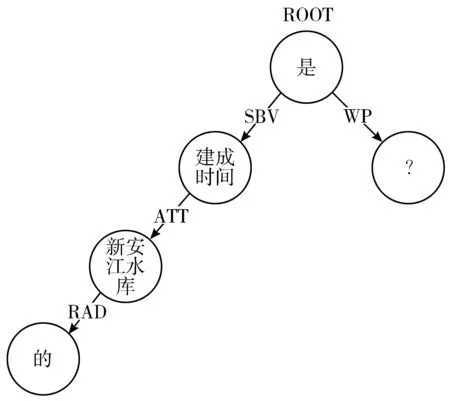
图1 依存句法树示例
2.3 查询语义图构建
语义查询图是通过依存分析得到的依存句法分析树构建的,将语义查询图中的2个相邻节点及连接2节点的边构造出一个三元组,转化成SPARQL结构化查询语句。语义查询图的构建算法描述如算法1。
算法1 语义查询图构建算法

输入:依存分析结果中的词性,依存关系对象C。输出:有向图(语义查询图)。1 for C do2 if(Ci是名词)3 //添加到语义图名词性节点集合4 if(Ci是动词){5 //找到动词的主语宾语6 //向有向图中添加边长和顶点7 }8 end for9 for C do10 if(Ci是名词){11 //找出有修饰关系的名词12 //构建成有向图13 }14 end for15 return有向图
算法1主要分析依存句法分析树中的名词性节点和动词性节点C。如果Ci是名词,则构建名词性节点,如果名词性节点之间存在修饰关系,则构建一条从修饰词到被修饰词的边,构建成有向图;如果Ci是动词,则以动词为核心,根据依存句法分析找到动词的主体和动词的客体,即它的主语和宾语,构成有向图,即语义查询图。例如问句“新安江水库的建成时间是?”,构建的语义查询图如图2所示。

图2 语义查询图
2.4 词语消歧
生成语义查询图后,初步大致清楚用户的查询意图。据此可以将语义查询图中的节点和关系映射到知识图谱中的标准表示名称,从本质上来讲这是消歧问题,通过消歧步骤可将用户输入的自然语言词语映射到知识图谱上的概念、实体或对象名称[11]。
1)概念与实体消歧。
本文对概念和实体进行消歧使用的是同义词词典映射法。通过水利信息资源知识图谱,在百度百科中找到对应的实体或概念,从百度百科中描述这些词语的infobox里使用这些词语的别名作为同义词。例如百度百科中“太湖”的页面,整个页面对“太湖”进行了详细的介绍。其中“太湖地处长江三角洲的南缘,古称具区、震泽,又名笠泽、五湖,是中国五大淡水湖之一”。“又名”后面的“五湖”“笠泽”可以抽取为“太湖”的同义词,在其他的页面中可能是“常简称”“又称”,后有实体的同义词。
抽取实体的文本信息,然后对概念和实体使用消歧模板抽取文本中的实体的同义词。本文使用Java正则表达式来表示模板,可抽取常简称、又称、又名、俗称、古称、原名、也叫这些词后面的词语,并且分割中间出现“、”和“或”的词语。例如上面“太湖”的例子中“古称具区、震泽,又名笠泽、五湖”,可抽取出“具区”“震泽”“笠泽”“五湖”4个词语。Infobox信息抽取概念或实体的“别名”属性,将其属性值抽取为实体的同义词。最后将这些同义词存放到同一个组里来表述这同一个词。表1所示为部分实体同义词词典。
表1 实体同义词词典

实体同义词太湖具区、震泽、笠泽、五湖三峡枢纽水库主坝三峡大坝、三峡工程洪湖水乡、汉江明珠新安江水库千岛湖
2)关系消歧。
本文对关系消歧采用的是规则映射法与同义词词典法相结合的方法。关系消歧时,首先将词语与规则映射表相匹配,如果在规则映射表中找到可匹配的规则,则将其替换完成消歧。如果在规则映射表中没有匹配到合适的规则,则与同义词词典对照,词典中记录该词,则将其替换完成消歧。
对于规则映射法,有些关系是由多个词共同表达的,如问句“新安江水库什么时候建成的”,“什么时候”后面接一个动词,可将其映射为动词+(时间|日期),这样就可以映射成“建成时间”或者“建成日期”,表2中列出了规则映射表。
表2 规则映射表

规则名称关系映射什么时候.*?/vV+时间|日期归|归属|属于.*?/n管理在|坐落于|处在.*?/n位于
问句中还有一些关系是以同义词的形式出现的,例如提问“青海湖在哪里?”这个问题时,人们想问的是“青海湖的所在位置”,这时候根据同义词词典将“在哪里”替换为“所在位置”。表3展示了部分关系同义词。
表3 关系同义词表
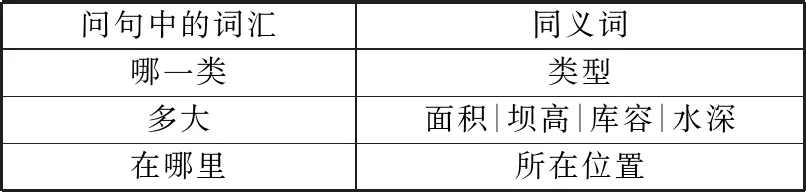
问句中的词汇同义词哪一类类型多大面积|坝高|库容|水深在哪里所在位置
2.5 结构化查询
到知识图谱中查询并返回答案是基于语义解析的问答的最后一步。这一过程分为2步:一是根据用户语义查询图生成SPARQL查询语句,即生成一系列的Triple Pattern;二是根据生成的Triple Pattern到知识图谱中查询并返回答案。
“新安江水库的建成时间是?”SPARQL的查询语句,如图3所示。

1 SELECT *2 FROM http://www.w3.org/WIBP_ZYML/CLASSMODLE#3 WHERE {4
图3 SPARQL查询语句样例
3 问答语料扩充
基于以上的研究,在限制语料的情况下,问答的性能不够完善,主要表现在问答范围有限,回答准确率不够高。
基于表示学习的方法不是基于逻辑符号的,也不需要借助词汇映射表等的外部支撑,灵活性高,性能表现比传统问答方式更好,但是基于表示学习的问答模型需要大量数据进行训练。水利领域缺乏一定规模的问答语料,水利领域专业性强,获取途径不多,语料匮乏,无法获得一定规模的专用语料。所以本文设计面向表示学习的问答语料扩充机制。
3.1 基本机制
图4是语料扩充机制的流程:
首先,使用语义解析方法完成问答。水利用户根据自己的需求提出问题,基于第1章所述的语义解析方法,系统返回答案。其次,将用户使用上述基于语义解析的问答系统提出的问题、系统返回的答案以及用户对该问题答案的反馈记录在日志中。这种方法主要是跟踪用户的行为,收集用户对该问题答案的修正,利用信息反馈机制,过滤无用信息进行二次检索。然后分析日志获得问答语料。虽然可以收集到一定数目的问答对,但还是不足以训练表示学习问答模型。所以本文在收集到的语料基础之上提出语料扩充方法,对语料进行扩充,最终构建成能够用于表示学习问答训练的水利领域语料库。

图4 语料扩充步骤
3.2 基本过程
1)基于语义解析的问答。
首先使用第1章基于语义解析的方式完成问答,将问答构建在水利信息资源管理系统上。图5描述了用户使用基于语义解析的问答系统进行提问、反馈等行为的流程图:

图5 用户问答行为流程图
用户输入自己想要查询的问题,点击语义解析QA,系统返回从知识图谱中查询到的答案。用户以自身的水利知识对给出的答案作出显式反馈,即直接给出“满意”或“不满意”。
2)日志记录。
日志是用户行为的重要载体[12],其中包含了用户进行问答时的搜索行为、反馈行为等。现在常用的日志框架有SLF4j、Log4j、Log4j2、Logback、jboss-loggin等。本文在系统中使用日志门面SLF4j与日志实现Logback配套的日志管理。日志中包含用户的个人信息、浏览资源名称、URL地址等,还包含了系统运行过程中产生的错误信息/运行状态等。对于用户的问答行为,本文在前台交互页面上使用js埋点技术获取。
3)分析日志获取语料。
与知识图谱推荐中关注单独用户行为不同,本文针对的是所有用户的所有问答数据,对日志进行过滤筛选,提取出用户的行为数据。日志中存储的信息数据,包含了丰富的用户对结果的满意度信息。本文使用公式(1)计算用户对问题答案的满意分数:
(1)
其中,Score表示分数,显示反馈对答案进行投票,分为“满意”和“不满意”。Qscore表示显示反馈中“正确(满意)”票数与“错误(不满意)”票数的差额,加1是为了避免现实情况下大部分用户不会参与到反馈中。Qclick是某一问题下某一答案的点击次数,Qclicks是某一问题下的点击总次数,α、β是所占的权重。
本系统经过2018年9月—2019年1月共计5个月的测试使用,从日志中得到的问答对共计370条。获得的部分问答对语料数据如表4所示。
表4 问答语料集
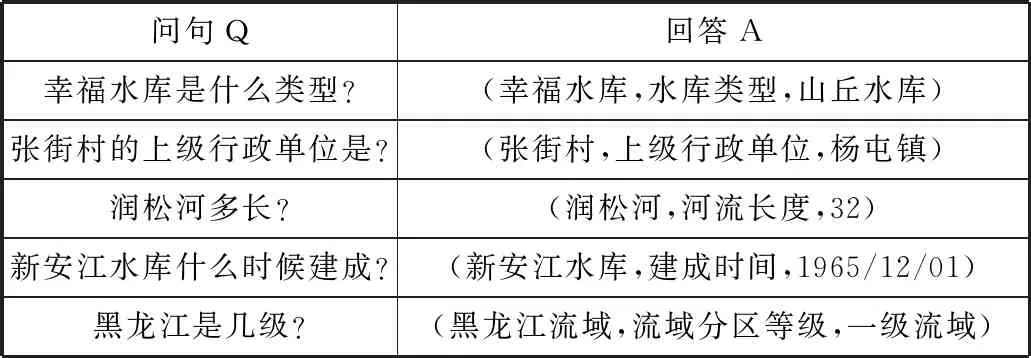
问句Q回答A幸福水库是什么类型?(幸福水库,水库类型,山丘水库)张街村的上级行政单位是?(张街村,上级行政单位,杨屯镇)润松河多长?(润松河,河流长度,32)新安江水库什么时候建成?(新安江水库,建成时间,1965/12/01)黑龙江是几级?(黑龙江流域,流域分区等级,一级流域)
4)语料扩充。
已收集到了一些问答对语料,但这些数据规模较小。本文要使用的文献[10]中的问答模型的实验数据集为人工构建,是标准地以(h,r,t)为基础,人为设定种子问题,将三元组映射成自然语言问题,然后进行训练。本文参考这种思路,在收集到的真实数据基础上给出扩充算法2来扩充语料集。
为了便于表述,本文使用O表示概念,Oe表示实体e所属的概念。问答对S={(qi,ai),i=1,2,…,|S|},是由(q,a),即(问题、答案)对组成,其中a为三元组(h,r,t)。
算法2的主要思想是:首先遍历所有已有语料集中的问答对。取出一对问答对,取出问答对中答案三元组(hi,ri,ti)所对应的头实体hi,找到实体hi所属于的概念Ohi,然后查询出该概念下的所有实体Oe,从Oe中取出10个实体ej,根据实体ej和关系ri查询出tj,用hj、tj取代原来问题,答案中的位置,形成新的问答对。
算法2 问答语料扩充算法

输入:问答对集S1。输出:扩充后的问答对集S2。1 for si si∈S1(si=(qi,ai),ai=(hi,ri,ti)) do2 在WaterKG中查询出hi所属的概念Ohi3 查询出概念Ohi下所有实体的集合Oe4 任取Oe下的10个实体ej(1≤j≤10),ej≠hi5 for j do6 在WaterKG中查出ej、rj对应的tj值7 将原问题、答案对中hi、ri、ti中的hi、ti换成ej、tj8 构成新的问答对9 end for10 end for
通过上述算法,最终得到扩充后的语料库,共计4000余条。问答语料库部分数据展示如表5所示。
表5 扩充后的问答语料库

问句Q回答A幸福水库是什么类型?(幸福水库,水库类型,山丘水库)树山水库是什么类型?(树山水库,水库类型,平原水库)曹家山水库是什么类型?(曹家山水库,水库类型,山丘水库)润松河多长?(润松河,河流长度,32)金水河多长?(金水河,河流长度,18)内城河多长?(内城河,河流长度,12)黑龙江是几级?(黑龙江流域,流域分区等级,一级流域)哈巴河是几级?(哈巴河,流域分区等级,三级流域)盘龙江是几级?(盘龙江,流域分区等级,三级流域)
4 基于表示学习的问答
本文使用Bordes[13]等提出的基于嵌入的问答模型,通过水利领域语料训练,构建了水利问答模型框架,通过训练该模型,完成基于表示学习的适用于水利行业的问答系统。
基于表示学习的问答模型[13]框架如图6所示。

图6 基于表示学习的问答模型框架图
首先,将知识图谱中的实体、关系与问句输入到模型算法训练代码中,学习知识图谱中三元组与问题中的词语的低维向量嵌入,使得问题和相应的答案的向量在低维空间是相似的[14]。输出知识图谱中的实体关系向量表示和问句中的词语的向量表示。对于问题的回答,将问句以及所得的向量表示输入到模型算法测试代码中,得到问题的答案。
1)S(·)函数。整个模型涉及一个函数S(q,a)的学习,该函数是对一个问题和一个三元组的相似性进行评分,得分函数如式(2):
S(q,a)=f(q)Tg(a)
(2)
2)f(q)函数。f(q)是将问题映射到低维向量空间的函数。采用词袋模型来表示,对于问题q,如(新安江水库,建成时间,什么时候?)中的每个词语分别嵌入到k维的向量空间,然后将这些词向量累加求和。问题的分布式表达f(q)为公式(3):
f(q)=VTφ(q)
(3)
其中,q代表问题,φ(q)代表nV维的问题向量,是q的稀疏二进制表示(∈{0,1}nV),表示词语是否存在。词向量矩阵V包含了所有词语的向量表示,大小为RnV×k,表示用矩阵V将nV维的问题向量映射到k维的低维空间。
3)g(a)函数。g(a)函数是将实体和关系映射到低维向量空间中的函数,采用与问题部分相同的词袋模型来表示。公式(4)为答案分布式表达:
g(a)=WTψ(a)
(4)
其中,ψ(a)表示ne维的答案输入向量,是知识图谱三元组的稀疏二进制表示(∈{0,1}ne),表示实体和关系是否存在。词向量矩阵W包含了所有的实体、关系的向量表示,大小为Rne×k,表示用矩阵W将ne维的答案向量映射到k维的低维空间。
对于知识图谱全集T,给定问题q,可以链接预测到它相应的答案a′,即分值S(·)最高的答案,如公式(5)所示:
(5)
5 系统实现
5.1 系统架构设计
面向水利信息资源智能问答系统主要包括:基于语义解析的问答、语料收集、基于表示学习的问答等核心功能。其总体架构图如图7所示。
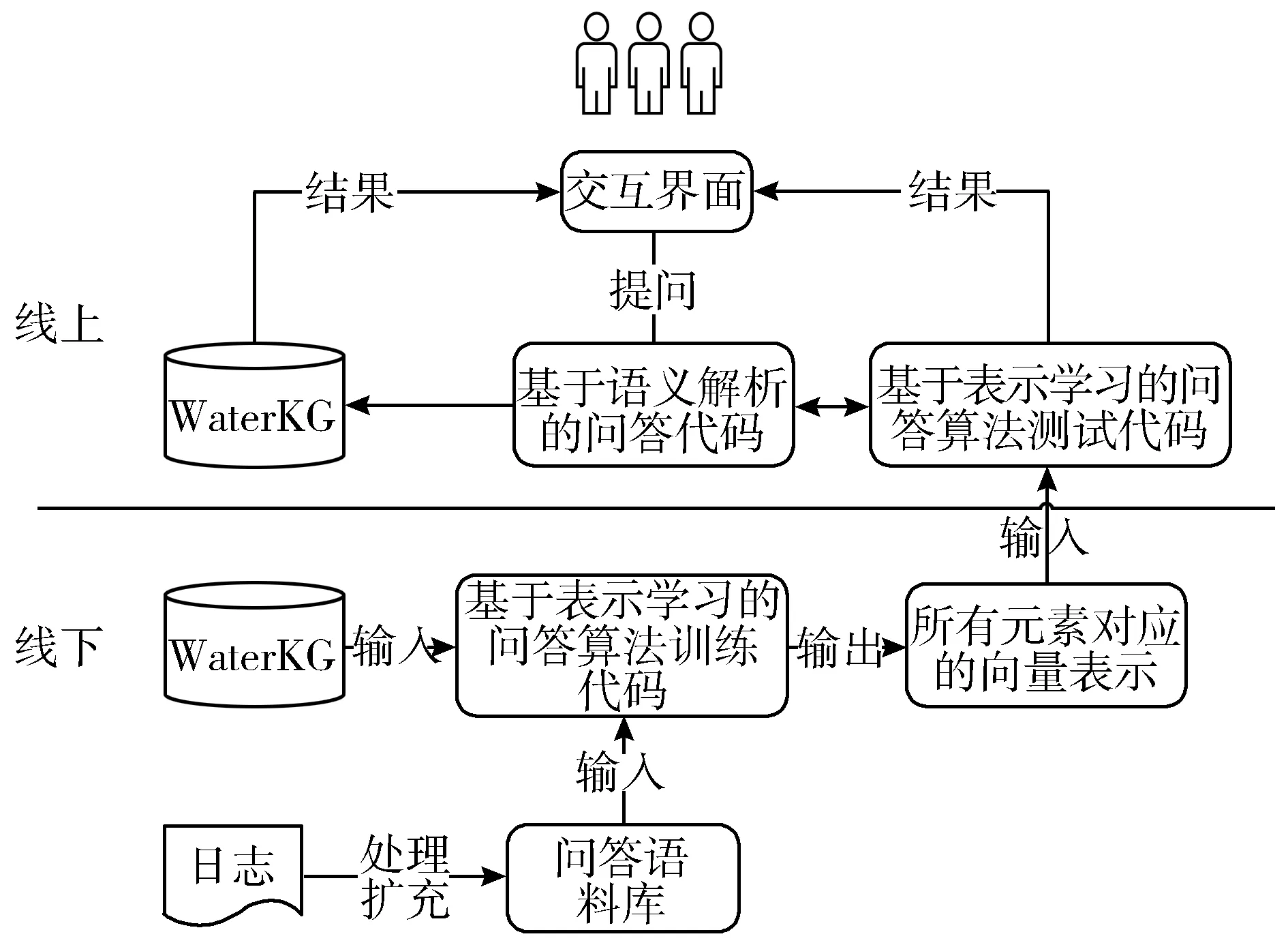
图7 整体架构图
该系统采用B/S架构,包括线上、线下2个部分。线上主要是用户输入问题,使用基于语义解析的问答方法或基于表示学习的问答方法,系统返回结果并展示,用户对该问题所返回的答案的反馈行为记录到日志中。线下主要是对语料的收集,处理日志,抽取问答对和用户行为反馈,扩充问答语料,构建成问答语料库。然后使用语料库训练基于表示学习的问答模型,该模型为线上基于表示学习的问答服务。
5.2 系统模块设计
面向水利信息资源的智能问答系统包括3个主要模块(如图8所示):基于语义解析的问答模块、语料收集模块、基于表示学习的问答模块。

图8 系统模块图
基于语义解析的问答模块得到用户所提问题的答案。语料收集模块包括用户查询问句,得到答案,用户的反馈,用户的点击行为记录在日志里,从日志中提取出问答数据,构成问答对,得到语料集,经过语料扩充后构建成语料库。基于表示学习的问答模块依赖于基于语义解析的问答模块与语料收集模块。根据语料收集模块中最终构建的语料库,训练基于表示学习的问答模型,训练完成后使用该模型提供智能问答功能。
5.3 系统实现展示
面向水利信息资源的智能问答系统实现了自动回答用户自然语句提问的问题。图9给出使用语义解析方法对问句“刘家峡水库有多高?”作出回答的界面。图10给出基于表示学习方法对该问句的回答。
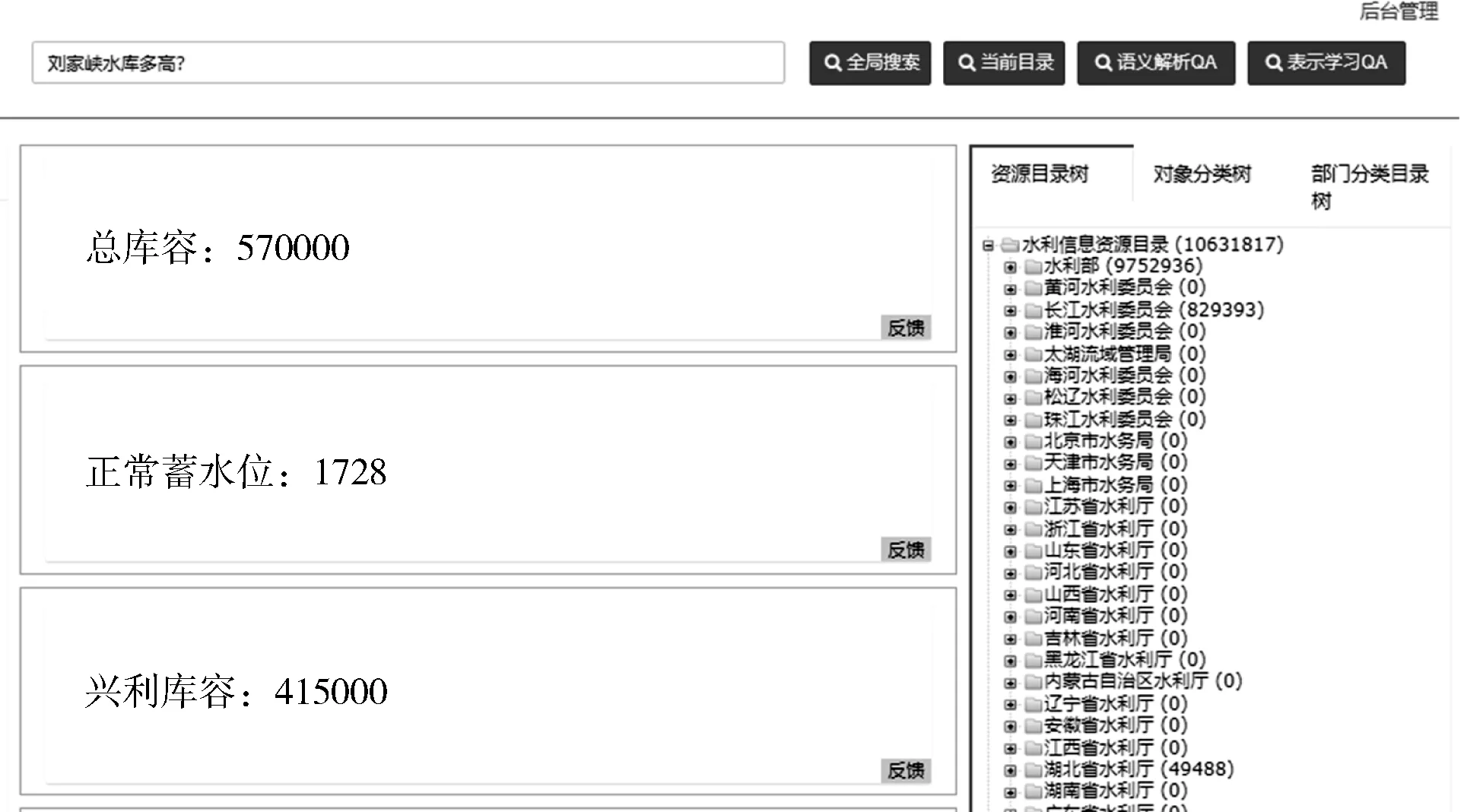
图9 基于语义解析的回答页面

图10 基于表示学习的回答页面
6 结束语
本文研究了面向水利信息资源,基于知识图谱、语义解析和表示学习的智能问答,虽然取得了一定的成果,能够很好地满足目前的需求,但是从长远的发展眼光来看,仍然有很多需要拓展和改进的地方,需要在以下几点继续深入研究:
首先,缺乏质量较高的问答对或结构化的水利行业数据集。本文中日志收集的过程能够收集到一定的问答语料对,这些问题来自水利行业从业者,质量有所保证,能够满足研究使用,但数据集的规模太小,问题种类也不够丰富。
其次,在语义解析的问答过程中,用户输入的问句中的词语很难和知识图谱中的词语形成映射,在分析没有回答出问题或者回答错误的案例时发现,大部分错误都是因为实体关系消歧。
最后,基于表示学习的问答模型并不十分理想,存在一定的局限性。未来可以在答案端将答案的路径的向量表示,与答案相关的知识图谱子图的实体和关系的向量表示,答案类型或者上下文相关度融合进来,以提升问答效果。
猜你喜欢
通信技术(2021年12期)2022-01-25
少先队活动(2020年12期)2021-01-14
开放教育研究(2020年2期)2020-03-31
中成药(2017年3期)2017-05-17
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
领导科学论坛(2016年9期)2016-06-05
长江学术(2016年4期)2016-03-11
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
