
基于机器视觉的轴承压印字符识别①
2020-03-18 07:55:42张桢铖周迪斌朱江萍
计算机系统应用 2020年3期
张桢铖,周迪斌,朱江萍
(杭州师范大学 杭州国际服务工程学院,杭州 311121)
传统工业上,轴承压印结束之后的分类、包装以及企业对于轴承信息的收录都是依靠人工检查与识别来完成.而机器视觉技术凭借其精度高,速度快,准确率高的优点已经在许多行业产生了良好的效益.但是轴承压印字符识别任然存在一些问题难点,首先是由于轴承是圆形结构,字符并不是横向分布,而是落在了环形带上,这就造成了后续分割与识别的困难;其次是一些字符识别耗时过多,导致检测效率降低.
文献[1]使用改进的圆检测算法定位字符区域,将坐标系转换极坐标进行字符分割与SVM 字符识别,该方法在极坐标下进行计算操作,使得计算更加方便,精度有所提高[1].文献[2]对采集到的图像首先利用Hough变换定位轴承圆心,对于轴承上的字符区域利用仿射变换进行矫正,随后进行轮廓提取并使用SVM 进行字符识别,采用仿射变换矫正方法不仅提高了算法整体的鲁棒性,而且极大程度的提高了字符识别准确率[2].文献[3]使用RBF 核的SVM 进行研究,通过使用双线性搜索与网格搜索方法的优点综合来进行参数选择,不仅搜索效率有所增加,识别率也有较大提高[3].文献[4]提出了一种机器视觉的轴承工件号识别系统,对采集到的黑白图像进行字符定位分割,并采用人工网络与支持向量机的算法对轴承工件号进行了有效识别,实时性、鲁棒性、准确性都满足了系统要求[4].
本文使用了最小二乘法对ROI 进行提取,具有定位准确与耗时少的优点,对字符区域使用1/8 圆展开,展开速度开,图像展开效果好,大大增强了算法鲁棒性,最后使用SVM 算法来对字符进行识别,并通过大量实验验证了该算法的可靠性[5].
1 字符区域提取
轴承压印字符是在模具作用下使轴承的部分表面厚度发生变化,从而在轴承表面形成字符的工艺,此字符具有永久性和防伪功能.通过压印形成的凹陷区域与背景区域具有一定的高度差,所以在平行光源的照射下就可以形成字符区域[6].
由于轴承压印字符具有一定的深度,通过环形光源对轴承表面的照射,根据表面反光程度的差异可以清晰的获得完整的字符轮廓[7].现场采集到的图像如图1 所示.
1.1 图像预处理
由于在拍摄过程中会有材料反射和微小噪音的影响,所以现场采集得到的原始图像都会包含有不同程度的噪声干扰,必须对原始图像进行一定的图像预处理,这样可以很大程度的改善图像中的信息[8].通过抑制这些噪声,有利于我们在对图像进行处理和分析的时候可以更便于得到有用信息.
首先对采集到的轴承图像运用高斯滤波进行降噪处理;然后使用直方图二值方法来对图像进行二值化处理,之后使用开运算再对二值化图像进行进一步的处理,消除图像中的微小噪声干扰,进而得到清晰的前景图像.

图1 轴承图像
1.2 圆心定位及半径查找
待识别字符所在区域位于轴承的一个环上,圆心位置的确定以及半径大小计算的准确程度,极大的影响了字符识别率.圆心定位最常用的两种方法就是Hough 变换与最小二乘法.
噪声点对于Hough 变换的影响略小,具有较强的鲁棒性,在对缺陷较大的圆进行定位时,需要提供图像中圆的半径长度等参数设置[9].圆心位置是通过投票来得到,但是大量的时间与内存的消耗也是在投票过程中消耗的,而且需要对圆的半径进行一定的约束,这样不仅可以提高精度,也会大大降低运算量.同时由于之前对原始图像进行了一系列的预处理,所以待查找圆并没有太多缺陷,因此使用最小二乘法拟合圆更适合本次实验.
这里使用最小二乘法首先假设圆的方程为x2+y2+ax+by+c=0 ,然后假设有一系列点(xi,yi)是近似的落在图像中的一个圆上,i∈(1,2,···,n).设该圆的圆心为(x0,y0),半径为r.d2=(xi-x0)2+(yi-y0)2这是圆上的点到圆心距离的平方和,这里将其与半径平方的差作为目标误差为了使目标误差的平方和最小,需要经过计算可得:


其中,

据此就可以将图像中的环形区域分离出来.本次实验上采用C++实现,在对外圆轮廓圆心进行求解时,Hough 变换一次求解计算所用时间约为140 ms,而最小二乘法所用时间则不到10 ms,很明显最小二乘法更适用.
1.3 ROI 提取
工业相机拍摄的轴承图像经过预处理后得到图像,包括字符区域与非字符区域.由于图像中包含大量无效信息,所以要筛选出要处理的对象,首先需要将字符区域分离与提取.
字符所在区域是由两个同心圆环所构成的环形区域,通过之前拟合圆的方法拟合出轴承的圆心及内、外圈的半径,拟合结果如图2 所示,由此便能分离出图像中的字符区域.
可以观察到,在图像的环形字符区域存在一些干扰因素,可以通过调整图像的亮度与对比度来消除这些因素的干扰.通过对图像像素进行点操作变换,可以使得图像的亮度与对比度有一定的变化.图像的亮度与对比度的调节主要基于下面的公式:

将原始图像设为f(i,j),经过调整之后的图像设为h(i,j).这个公式是对像素进行了一次线性变换,其中设置不同的α和β的值,就会对图像产生不同的变换效果.当图像f(i,j)×α的值比1 大的时候,图像f(i,j)中像素值之间的差异就会变大,因此就会导致对比度的增强,反之图像对比度将会减小.β值的变化会对图像亮度进行简单调整.
当局部光照亮度有区别时,假定光源与材料有一定的角度偏差,或其它各类因素导致材料亮度差异较大.可以考虑轴承轴向投影时,每个投影区域的亮度依据环境的亮度变化规律调节亮度.图像处理前后情况如图3 和图4 所示.

图2 ROI 区域

图3 图像处理前
2 字符图像提取
2.1 字符带展开
在后续的字符识别过程中,需要将单个字符进行提取与识别,一些传统的视觉算法对于环形轴承字符识别难以应用.因此为了使字符识别操作更顺利的进行,我们在这里将环形字符带转换为更容易进行识别操作的矩形字符带.如图5 所示.

图4 图像处理后
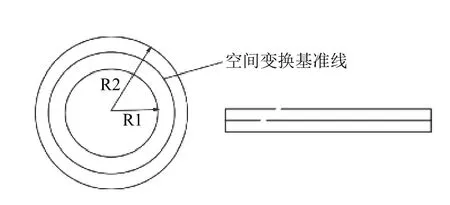
图5 圆展开示意图
我们使用的是1/8 圆扫描方法,将圆等分为8 份,之后圆上的其它区域由这1/8 个圆经过简单的反射变换之后就可以得到如图6 所示.

图6 圆的对称图
但是若扫描的起始点选取不恰当,位于字符段之间时,会导致同一字符段被分开.为了避免该情况发生,从垂直方向90°开始开始顺时针扫描,当发现一块空白区域,并且该空白区域所占角度大于设定阈值时,则将该空白区域的终点定为扫描起点.我们将这个角度的阈值设为20°.如图7,首先假设圆上一点为(x,y),那么其他7 个八分圆上其他各点坐标为(-x,y),(-x,-y),(x,-y),(-y,x),(y,-x),(-y,-x),(y,x),因此我们只需要对1 个八分圆的转换方式进行研究.假设从(0,r)开始,顺时针进行搜索至(r/2,r/2),当发现第一个最接近圆弧的点时,令其为P(xp,yp).然后对下一个像素进行寻找,选择P点正右边的P1(xp+1,yp+1)或者选择其右下方的P2(xp+1,yp+1),如图7 所示.

图7 当前像素与下一候选像素示意图
在这里构造了下面这个函数:
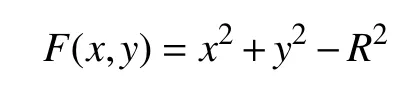
接下来对图像上的点进行讨论,这些点与圆有3 种相对位置:

通过这样的搜索方式,整个圆上的所有像素点都被快速搜索到.然后将半径为r的圆周长设置为展开矩形的长,将圆环的宽设置为矩形的宽.由于是将圆环展开为矩形,除了半径为r的圆,其他的圆必然需要对像素进行一定的插入或抽取,按照我们之前对圆搜索的方法,每当待展开圆半径每增加1 时,待检测圆上的像素有两种情景,不增加或者会增加8 个;半径减少时同理.由于知道了圆上像素个数的变化,这样就可以在对圆环展开时均匀的插入或抽出某些像素点.展开结果如图8 所示,字符带中的字符清晰可辩认,完全达到了算法识别要求.

图8 字符带展开图
2.2 单个字符切分与归一化处理
为了识别出轴承上的单个字符,因此需要将每个字符切分出来.对展开图像进行逐列扫描,根据黑色元素的连续性对字符位置进行分割,此次字符分割结束.然后再继续向后进行扫描,在图像最右端前按照上述方法一直扫描到底.通过上述扫描方法就可以精确的得到每个字符的宽度范围,这样就可以从轴承展开图像中分割出每个单个字符.
在对字符进行归一化操作后,字符识别的标准性与准确性都会得到很大的提高[10].具体实现方法如下:首先需要计算出轴承展开字符带中各个字符的高度,通过计算这个高度与设定高度数值之比,即为变换系数,由此就可求出操作后的宽度[11].这里我们假设原始图像大小为w×h,在对图像进行归一化操作之后图像大小为W×H,在原始图像坐标为(x,y)的像素点进行归一化之后所对应的坐标为(X,Y):
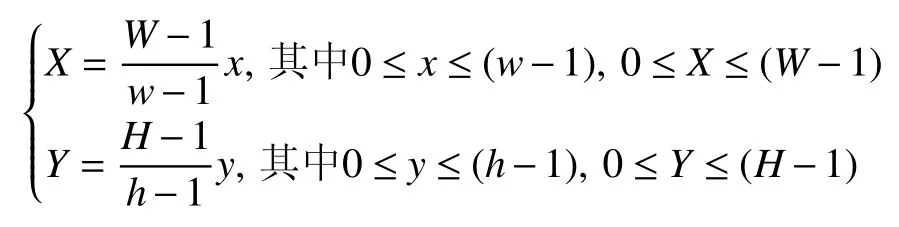
通过实验表明,将二值图像的单个字符大小归一化为宽度12、高度18[12].在通过实验得到这个宽度与高度之后,我们将新图像里面的点映射至原始图像中,结果如图9 所示.

图9 单个字符切分
3 字符识别
在对样本图像进行处理后,然后对字符进行识别操作,本文分别采用了模板匹配识别法、神经网络识别法与支持向量机识别方法来进行实验,通过对比选出更合适的识别方法.
使用模板匹配法来计算待识别目标与原型之间相似性的差异,我们将待识别目标图像记为T,其图像大小为X×Y,然后将已经准备好的图像模板记为S,其图像大小为M×N(M<X,N<Y).使图像模板S在待识别目标T上进行移动,相似度最大的即为识别结果[13].
使用BP 神经网络来对字符进行识别操作[14].我们选取26 个字母、10 个数字0~9 和“-”作为待识别目标,随机选取200 个图像进行训练,另外取100 个图像作为识别样本[15].本次实验采用的是三层神经网络结构,有25 个输入,隐含层取50 个神经元,输出为37 个,将最大输出端对应的字符作为识别结果.
使用SVM 算法进行字符识别,使用LIBSVM 来实现算法[16].之前的图像处理操作将字符大小归一化为12×18,在进行适当降维后,SVM 的输入为30 维,选用RBF 为高斯核函数,之后将图片素材特征化,将特征文件输入即可得到模型文件[17].在模型经过测试集测试后,将图像载入模型即可得到识别结果.得到的最优核函数参数为0.0526,惩罚因子为56.
4 实验与结果分析
本次实验共采集轴承图片300 张,对于神经网络与SVM 都是随机选取200 张作为训练样本,剩余100 张作为测试图片,模板匹配则随机选取100 张进行测试.在Inter(R)Core(TM)i7-4790 CPU,4 GB 内存的计算机上进行实验,在VC2015 上进行编程,算法实现上使用C++.
首先在圆心定位检测中,对Hough 变换与最小二乘法进行对比,统计两种算法的正确率与定位速度,测试结果如表1 所示.

表1 圆心定位检测结果
表1 结果显示,两种算法都具有较高的定位准确率,但是在消耗时间上,最小二乘法明显快于Hough变换.
然后对字符识别的准确率与消耗时间进行测试.对模板匹配,神经网络和SVM 3 种识别方法进行对比,结 果如表2 所示.

表2 字符识别检测结果
表2 结果表明:模板匹配虽然准确率满足实验要求,但是其耗时过长;神经网络在识别时间上能满足要求,但是由于样本有限导致识别率偏低;SVM 算法不仅识别速度快而且在有限的样本训练条件下,具有良好的识别准确率.
5 结束语
对于轴承压印字符的识别技术,使用高斯滤波可以有效消除图像噪声;采用最小二乘法对圆心的定位及半径的查找速度快,精度高;1/8 圆扫描法使环带展开后的字符清晰可辩认;最后利用SVM 对字符进行识别.实验表明:该算法对字符识别准确率达98%以上,识别速度也可满足工业需求,可实时的实现轴承表面压印字符的识别.在字符受到污染的情况下,识别准确率大大降低,接下来的研究工作就是设计鲁棒性更强的算法,可以最大程度的消除现场污染的影响.此外随着深度学习的不断发展,更加智能化的检测方法是值得不断去深入研究的.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
成都信息工程大学学报(2017年3期)2017-11-09 02:56:12
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:38
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
电源技术(2015年7期)2015-08-22 08:48:32
国外科技新书评介(2014年3期)2014-12-17 17:26:53
印刷技术·包装装潢(2014年5期)2014-08-27 16:56:19
