
基于DAPA的卷积神经网络Web异常流量检测方法*
2020-03-16 05:24:56高胜花李世明李秋月於家伟郑爱勤
网络安全与数据管理 2020年2期
高胜花,李世明, 2,李秋月,於家伟,郑爱勤
(1.哈尔滨师范大学 计算机科学与信息工程学院,黑龙江 哈尔滨 150025;2.上海市信息安全综合管理技术研究重点实验室,上海 200240)
0 引言
在网络空间信息安全领域,网络流量异常检测对于保障网络的正常运行和网络的安全起着至关重要的作用[1]。随着网络服务应用数据巨增,Web服务器遭受的攻击数量越来越多,攻击类型也越来越复杂,为保证向用户提供持续、安全和可靠的应用服务,需要实时检测出Web服务中的异常流量。现有的Web异常流量检测方法大多数为误用检测或是基于传统的机器学习算法检测[2];误用检测是根据已知攻击行为为主要特征,将入侵行为与正常行为根据已知特征加以区分来实现入侵行为的检测,该类方法效率高且误报率低,但只能发现已知的入侵类型,漏报率较高,特征的维护多采用人工方式完成。传统机器学习检测算法依靠手工提取流量中的特征,人为干预较严重。
1相关工作
网络异常流量的检测是保障网络安全至关重要的防御步骤。文献[3]提出了一个可以普遍适用的入侵检测框架,该框架能够检测真实世界的僵尸网络,具有非常低的假阳性率。文献[4]建立了一个流量检测系统MadTracer,自动生成检测规则,利用检测Web流量来判断服务是否包含不正当广告。实验结果表示MadTracer检测准确率达到了95%,但只能检测已有的攻击类型。文献[5]针对HTTP异常流量检测问题,在原始数据的基础上与经验特征工程相结合的思想提出一种深度混合结构神经网络,所提方法检测效果有较明显提升,准确率可达98.1%,但需要依赖人的经验特征,存在人为误差。文献[6]将深度学习应用到工控系统当中,将流量转换成灰度图,用构造好的灰度图去进行模型训练,对数据进行实时的异常检测,并做出相应的安全预防,实验结果显示精确度达到97.88%。文献[7]搭建基于SPP卷积神经网络模型去进行Web攻击检测,解决传统模型只能处理固定大小输入的问题,但不能根据特征图的不同,动态地调整池化过程。
针对上述文献在异常流量检测中存在的问题,本文在传统的卷积神经网络基础上,构建基于动态自适应池化(Dynamic Adaptive Pooling Algorithm,DAPA)的卷积神经网络Web异常流量检测模型,可以根据特征图的不同,动态地调整池化过程,并在全连接层后连接了一个Dropout层,解决模型在流量特征提取过程中存在的过拟合问题,提高了模型的泛化能力。
2 Web异常流量检测模型设计
目前,业界网络异常行为检测方法从原理上来说大约有如下几种分类,如表1所示。

表1 网络异常检测方法分类
本文采用基于分类方法中的二分类,搭建基于动态自适应池化的卷积神经网络模型,用该模型将数据流量划分为异常或正常。
2.1 Web攻击检测框架
Web攻击检测框架分为两个阶段,如图1所示。
第一阶段:数据预处理,进行流量捕获,获得数据集,对数据集中每一条请求流量进行剪裁、对齐、补足生成一系列50×150的矩阵数据,矩阵数据作为输入;
第二阶段:使用动态自适应池化卷积神经模型进行异常网络流量检测。
2.2 动态自适应池化CNN模型
动态自适应池化卷积神经网络模型如图2所示,异常流量检测过程中,流量数据转换成矩阵数据后,作为模型的输入。池化是对流量特征进行二次提取,需对池化域的流量特征进行归纳和计算,在全连接层后添加Dropout层。
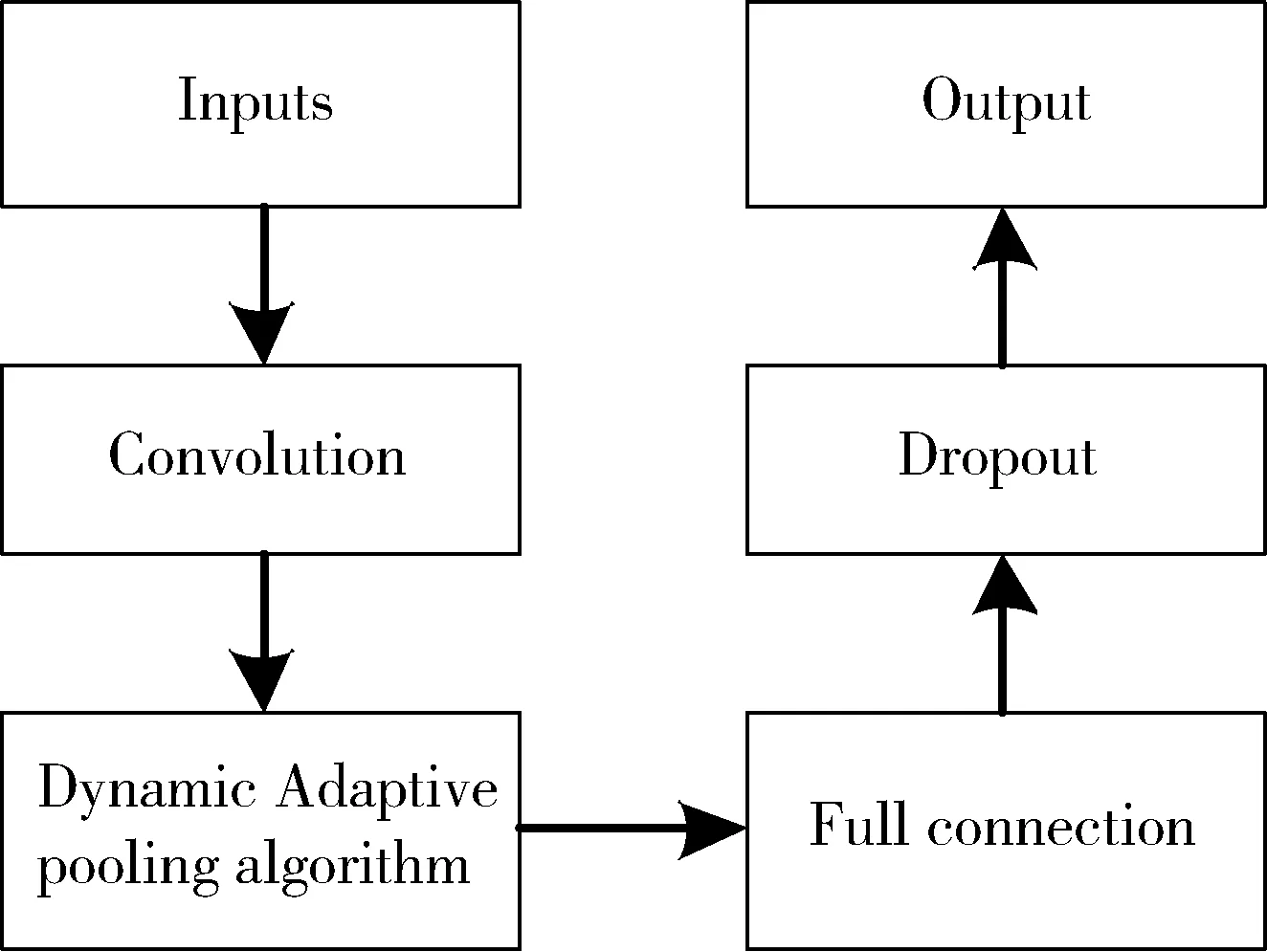
图2 CNN结构框架
2.2.1 动态自适应池化
池化是一种降采样的方法,池化层直接计算池化窗口内元素的特征值,设F为卷积层输入的流量矩阵,池化域为c×c的矩阵P,b2为偏置,S为得到的子采样特征矩阵,池化过程移动步长设成c,本文以最大二均值池化为基础,其表达式为:
(1)
式(1)是在最大池化的基础上改进的,当一些影响因素的值较大时,使用最大池化,会降低流量矩阵特征的提取,所以本文池化时会选取最大的两个元素求和,并取和的平均值作为子采样的特征值。
动态自适应池化模型以最大二均值池化为基础进行改进与优化,最大池化模型和平均值池化模型在对流量特征图进行二次提取的时候,都很难取得较好的效果,因此提出了动态自适应池化算法,其算法表达式为:
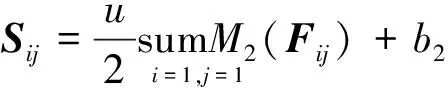
(2)
其中u为池化因子,如式(3)所示[8]:

(3)
其中a为流量特征图中除最大和第二大两个特征值外所有元素的平均值,vmax为流量特征图中最大和第二大的两个特征值的平均值,θ为校正误差项,p为特征系数。流量特征图的不同会导致池化因子的取值不同,池化因子会动态调整来达到最优。池化因子取值范围为μ∈(0,1),可以同时兼顾最大二均值池化和平均池化,在异常流量特征提取时既不会导致精度丢失过高,也降低了最大池化忽略其他较大因素时产生的影响。
2.2.2 CNN中的Dropout层设计
本模型在异常流量特征提取过程中存在过拟合问题,其表现为错误检测率在训练集上非常低而在测试集上却较高,目前解决该问题的方法主要有正则化、剪枝处理、提前终止迭代、Dropout等。
因Dropout具有较好的泛化能力和鲁棒性,故本模型采用Dropout[9]来解决过拟合问题。当每个神经元都去记录流量特征的时候就会让特征信息被过度地记录,导致仅仅记住了训练集上固定的特征。而Dropout层只有部分的神经元参与权值更新,弱化了神经元之间的相互影响,从而有效预防了固定特征被学习记录的问题。
3 实验结果与分析
3.1 实验数据集
实验数据采用公开自动生成的数据集HTTP CSIC2020[10],该数据集包含上万条Web请求数据,由西班牙研究委员会(CSIC)信息安全研究所制作。数据集包含正常请求约36 000个,异常请求约25 000个。
将数据集标记为Normal(training)、Normal(test)和Anomalous(test),并分离成独立的Web请求文件。数据集包括各种攻击,主要攻击类型如表2所示。

表2 攻击类型及其特点
该数据集主要包括GET、POST、PUT三种类型数据,一个Web请求记录至少包含上述一种类型数据,且以该类型数据为边界符,在请求数据提取后,还需要对数据进行字符串分割,分割依据HTTP请求报文的格式规范进行,主要涉及URL地址解码,参数项、键值对、特殊符号的分割,得到每一条流量数据过后,对每一条请求流量进行裁剪、对齐、补足等操作,生成50×150的矩阵数据A,所得矩阵数据A格式如图3所示,与数据处理前的数据流量作为输入相比,可以看出矩阵数据A更好地保留了流量数据原本的语序顺序和结构格式,使得数据流量的特征提取能够更加全面、更加精准。
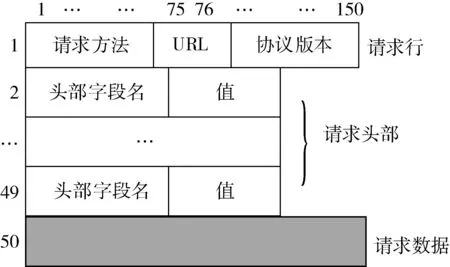
图3 矩阵数据格式
3.2 实验结果与分析
实验环境为Windows 10操作系统、Python3.7.3语言、TensorFLow框架,计算机CPU为Intel Core i5-4210u,内存8 GB,硬盘空间为2 TB,实验约61 000个矩阵数据,训练集与测试集比例为9∶1。
使用评价指标准确率和损失值对模型的检测结果进行评估,准确率计算如公式(4)所示,式中TP(True Positives)和TN(True Negatives)表示被正确划分为正常和异常的个数;FP(False Positives)和FN(False Negatives)表示被错误划分为正常和异常的个数。准确率越高,检测效果越好。
(4)
该实验选择交叉熵作为本文的损失函数,因为交叉熵描述的是2个概率分布之间的距离,交叉熵函数计算如公式(5)所示,q表示预测值概率分布,p表示正确的概率分布。
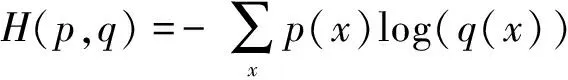
(5)
实验使用两种检测方法进行对比,分别为:使用不包含DAPA的传统卷积神经与本文提出的基于DAPA的卷积神经网络进行实验对比,实验对比结果如表3所列,由表3可看出,使用了DAPA的卷积神经网络精确度比未使用DAPA的神经网络精确度提高了1.2%,损失值降低了2.6%。

表3 实验结果
图4为加入Dropout技术前后及加入该技术时设置不同参数进行的对比实验图,模型中加入Dropout技术的目的是为了改善模型的过拟合问题。从图4中能够看出,当神经元占比数为100%时(即不加入Dropout技术)损失值最高,本模型会通过对训练数据的过度训练来降低损失值,从而出现过度拟合的现象;加入Dropout技术后,神经元占比数为40%时,损失值降低了4.2%,精确度提高了6%,所以本文选择设置参数为0.4,改善模型的过拟合性。

图4 神经元占比实验图
本文进行了不同迭代次数的实验对比,模型在不同的迭代次数过程中会生成不同的一个个小网络,对每个算法进行迭代训练,模型每增加一次迭代次数,都会使神经元之间的组合产生新的变化,使得神经元不会组成固定组合对模型学习过程产生影响,使得参数均匀分布,实验结果如图5所示。
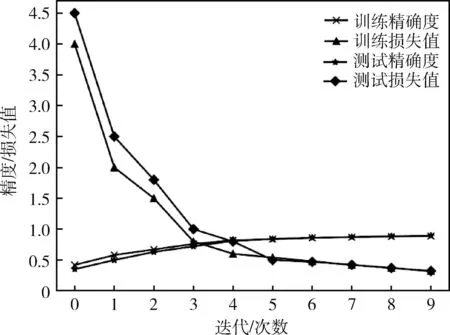
图5 实验精确度和损失值
4 结论
本文针对Web攻击流量检测问题,提出了一种基于动态自适应池化的卷积神经网络异常流量检测模型,将数据集转换成矩阵数据作为模型输入,模型根据输入特征图的不同,动态自适应地调整池化过程,用Dropout层来解决模型中存在的过拟合问题。实验结果表明,使用了动态自适应池化模型的效果更好,过拟合问题也得到了改善。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
