
北京松山自然保护区主要树种冠幅预测模型研究
2020-03-16 03:18:56王媛王秀兰冯仲科孙素芬张浪刘培斌
中国农业科技导报 2020年4期
王媛, 王秀兰*, 冯仲科, 孙素芬, 张浪, 刘培斌
(1.北京林业大学,精准林业北京市重点实验室,北京 100083;2.北京市农林科学院农业信息与经济研究所,北京 100097;3.上海市园林科学规划研究院, 上海 200232;4.上海城市困难立地绿化工程技术研究中心,上海 200232;5.北京市水利规划设计研究院, 北京 100048)
森林资源调查是对森林中各种资源的特征、数量进行测量或调查的过程,是森林经营与管理的基础。其中最重要的任务之一是立木测量,它在评价森林资源质量和林木生长状况方面具有重要的价值[1]。森林资源调查的因子包括胸径(diameter at breast height,DBH)、树高、冠幅、林地面积、蓄积量、年龄、优势树种等[2]。树高和胸径是反映立木质量和生长量的最基本因子[3],也是计算森林蓄积量、生物量、碳储量的基础。树冠是树木进行光合作用和蒸腾作用的重要场所,冠幅是树冠结构的重要特征因子之一,是预测树木生物量、树冠表面积、林分郁闭等的重要变量[4],因其相较于其他树冠结构因子直观且较易观测,也是在树冠中被研究最多的形态变量,在单木生长模型中常作为协变量预测树高和胸径生长量以及树木枯损等[5-6]。对树木冠幅的定量研究对林分密度调控、森林生态效益和生产能力的最优化管理具有重要意义。
在传统树木测量中,林业工作一般使用胸径尺测量胸径,以测高器测树高,并记录数据。而冠幅相对难以用传统工具测量且误差较大,因此,林业工作者基于树高、胸径与冠幅之间的关系建立回归模型,以容易测得的胸径推算树高和冠幅[7]。国内外学者就胸径、树高和冠幅之间存在的密切联系进行了大量的研究。例如,Sönmez[8]通过研究辽东冷杉的胸径和树高,建立了7个胸径树高模型,其研究结果表明精度最高的是三次方程。Calama等[9]对西班牙石松建立了树高-胸径模型,对5个双参数非线性方程进行了拟合和评价,建立了同一树种不同地区的模型。雷相东等[10]建立了长白落叶松等9个树种的树冠冠幅预测模型,结果证明树木的胸径对大多数树种的冠幅都有显著影响。符亚健等[11]对山西省庞泉沟自然保护区华北落叶松天然次生林单木冠幅预测模型展开研究,得出三参数的逻辑斯蒂形式的冠幅-胸径模型拟合精度较高,并且模型参数可解释。上述研究证明大多数树种胸径与树高、胸径与冠幅之间都存在较强的相关关系。近年来随着遥感技术的发展,运用高分辨率影像与LiDAR数据结合,传统手段难以获取的冠幅数据可以在遥感影像中获取,而利用胸径、树高与冠幅的相关关系,在大面积森林资源调查中可以利用冠幅数据推算胸径和树高数据,提高工作效率。
北京市延庆松山国家自然保护区地处北京市延庆县西北端,距离北京市区90 km。东部与延庆县后河村相邻,南部与佛峪口村和水峪村相邻,西边和河北省怀来县接壤,北边与河北省赤城县相邻,位于北京延庆县海坨山南麓,坐标为N40°29′9″~40°33′35″, E115°43′44″~115°50′22″,面积4 660 hm2。松山自然保护区地势北高南低,地形复杂,地势陡峭、地面起伏较大。本文基于松山自然保护区的实测数据,对松山主要的14个树种利用回归方程分别建立胸径-冠幅与树高-冠幅模型,通过比较分析选取最优模型,并进行精度检验。可为以后大面积开展森林资源调查以及冠幅、胸径、树高的高效预测提供参考。
1 材料和方法
1.1 数据来源
在松山国家自然保护区内的唐子沟、石湖沟和大柳树沟内建立了40 hm2(1 000 m×400 m)的森林大样地,划分为1 000个20×20 m2的小样地,使用全站仪[12](NTS 340,南方测绘仪器有限公司)对树木进行测量,可得到树木的三维坐标、树高、胸径、冠幅等基本数据。将全站仪架设于地形平坦处,激光点分别瞄准待测位置,通过三角函数和距离公式自动解算测量数据,得到相应树高、胸径、冠幅数据。为了建模更具代表性,本研究对每个小样地内胸径大于1 cm的所有乔木的树高、胸径、冠幅(东西和南北两个方向)进行测量和记录。
1.2 研究方法
1.2.1建模方法 本文将实测获取的各样地数据进行汇总后,选取松山地区数量较多的油松(PinustabulaeformisCarr.)、胡桃楸(JuglansmandshuricaMaxim.)、椴树(TiliatuanSzyszyl.)、榆树(UlmuspumilaLinn.)、五角枫(AceroliverianumPax)、蒙古栎(QuercusmongolicaFischerexLedebour)、白桦(BetulaplatyphyllaSuk.)、山槐(AlbiziakalkoraRoxb.Prain)、核桃(JuglansregiaLinn.)、柳树(Salix)、小叶朴(CeltisbungeanaBl.)、枣树(ZiziphusjujubaMill.)、椿树(AilanthusaltissimaMill.Swingle)、黑桦(BetuladahuricaPall.)14个树种的部分测量数据,利用SPSS 22.0建模。
建立模型时,树高、胸径数据直接使用测量值,因冠幅数据分别测量了东西、南北两个方向,在计算中,使用两个方向的测量值的平均值参与建模。将所有样地的数据按照树种汇总,去除异常数据后进行后续分析。
以往的研究表明,经验模型在单木生长预估中是一种常用方法,构建的模型直观明了[13]。由于各种函数回归模型的精度存在一定差异,本文选取了6个回归模型(表1)对松山地区树种进行拟合分析。

表1 候选模型Table 1 Candidate model
以冠幅数据D作为自变量,树高H和胸径d作为因变量,a、b、c、f分别为拟合模型的参数估计值。模型验证是建模的关键步骤,常用方法是数据分割(data splitting),即按照比例将数据分为建模数据和验证数据[14]。本文随机选取各树种80%左右的数据建立模型,剩余20%数据作为检验数据,在模型建立后对模型进行精度验证[15]。
1.2.2精度评价 本文选用决定系数R2、均方误差RMSE和F统计量三个指标对对模型精度进行评价。R2取值范围为[0,1],R2越接近1,表明模型对数据的拟合越好。均方误差RMSE是用拟合值与原始值之间的偏差来评价模型的回归效果,值越小越好。对回归方程进行F检验,回归方程的拟合度越高,F统计量值就越大。各指标估计值检验计算方法如下。
(1)
(2)
(3)
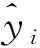
在计算上述指标后,对比每个模型的决定系数R2,均方误差RMSE和F统计量,按照R2、F最大以及RMSE最小的原则,选取出最优模型。
2 结果与分析
2.1 建模数据统计结果
2.1.1异常数据分析 将每种树木的所有数据绘制散点图,如图1(以山槐为例)所示,因树木本身或测量中较大问题存在个别异常数据,如记录过程中出现小数点标错位置以致明显过大或过小的数据,以及绘制散点图之后与趋势线和大多数数据距离过大的数据等,因此,需要去除后对剩余数据才能进行后续分析。
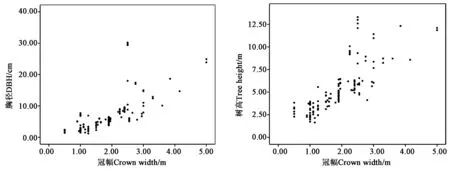
图1 山槐胸径、树高、冠幅数据散点图Fig.1 Scatter plot of DBH, tree height and crown width of Albizia kalkora Roxb. Prain
2.1.2建模数据统计分析 汇总所有数据,将枯死的树木数据,因测量、记录等过程出现错误的数据以及散点图中异常值剔除,最终选定样本量大于30的14个乔木树种进行研究,统计结果如表2所示。
从表2可以看出,选取的树种中,油松和蒙古栎的样本量较大,达到18 201和6 724株;椿树、核桃和柳树的样本量比较小,均为30余株。各树种的树高、胸径、冠幅数据的最大值与最小值差距较大,标准差值较大,说明使用的数据取值范围较广,具有代表性。
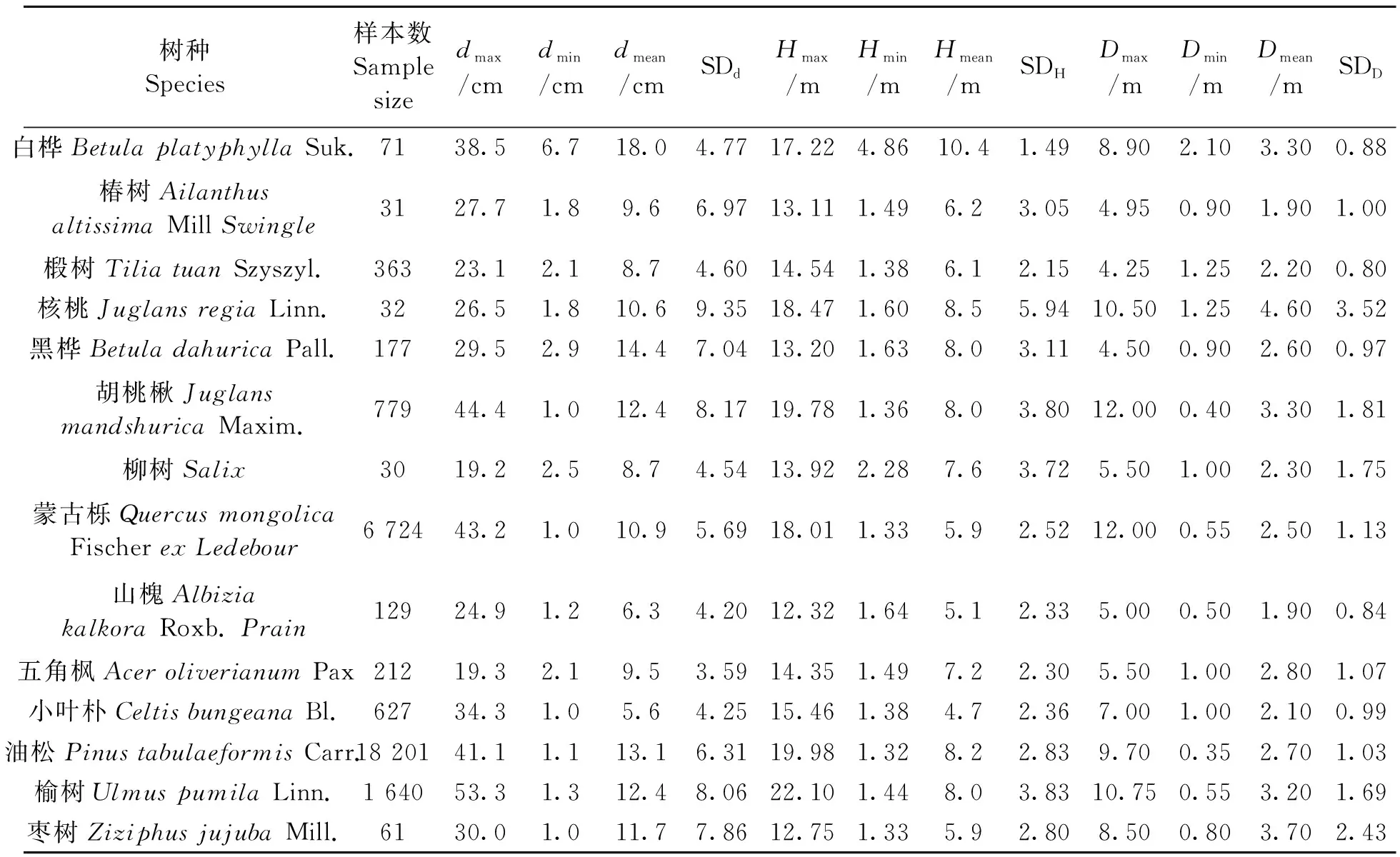
表2 建模数据统计Table 2 Statistics of model data
2.2 模型构建与分析
分别把各个树种的胸径、树高、冠幅的建模数据代入公式中,每个树种分别得到12个模型,包括6个胸径-冠幅模型和6个树高-冠幅模型,并求出其R2以及F值;使用检验数据计算RMSE的值。以山槐为例,按照候选模型分别计算出各模型的参数(表3和4),并绘制出各模型的曲线图(图2)。
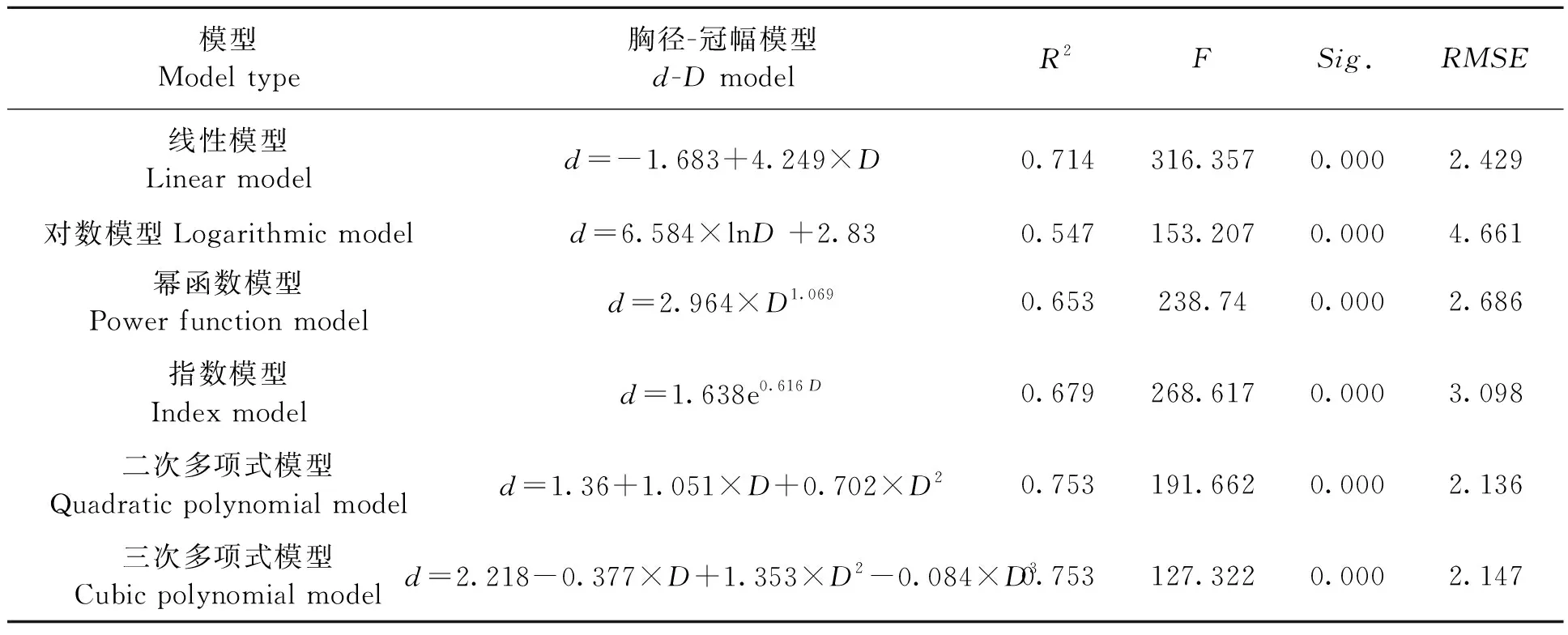
表3 山槐胸径-冠幅模型Table 3 Albizia kalkora Roxb. Prain d-D model
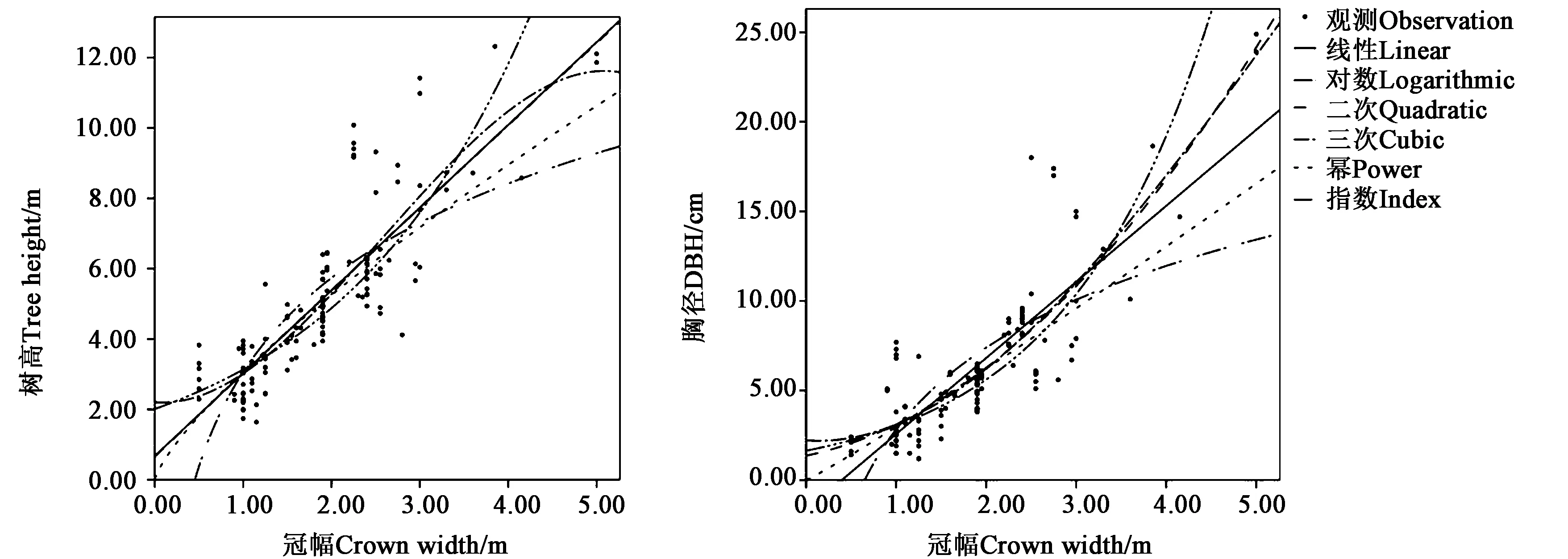
图2 山槐建模曲线Fig.2 Albizia kalkora Roxb. Prain modeling curve
从结果中可以看出所有模型的显著性水平Sig.<0.001,说明通过统计学检验。从决定系数R2、F统计值来看,各模型的拟合效果存在差异,其中线性模型、二次多项式和三次多项式模型的拟合效果较好,对数模型拟合效果最差。根据决定系数R2和F统计值最大的标准,选择山槐的最优胸径-冠幅模型为二次多项式模型,树高-冠幅模型为线性模型;计算得到对应的RMSE的值也是所有模型中最小的,说明选择的模型优于其他模型。
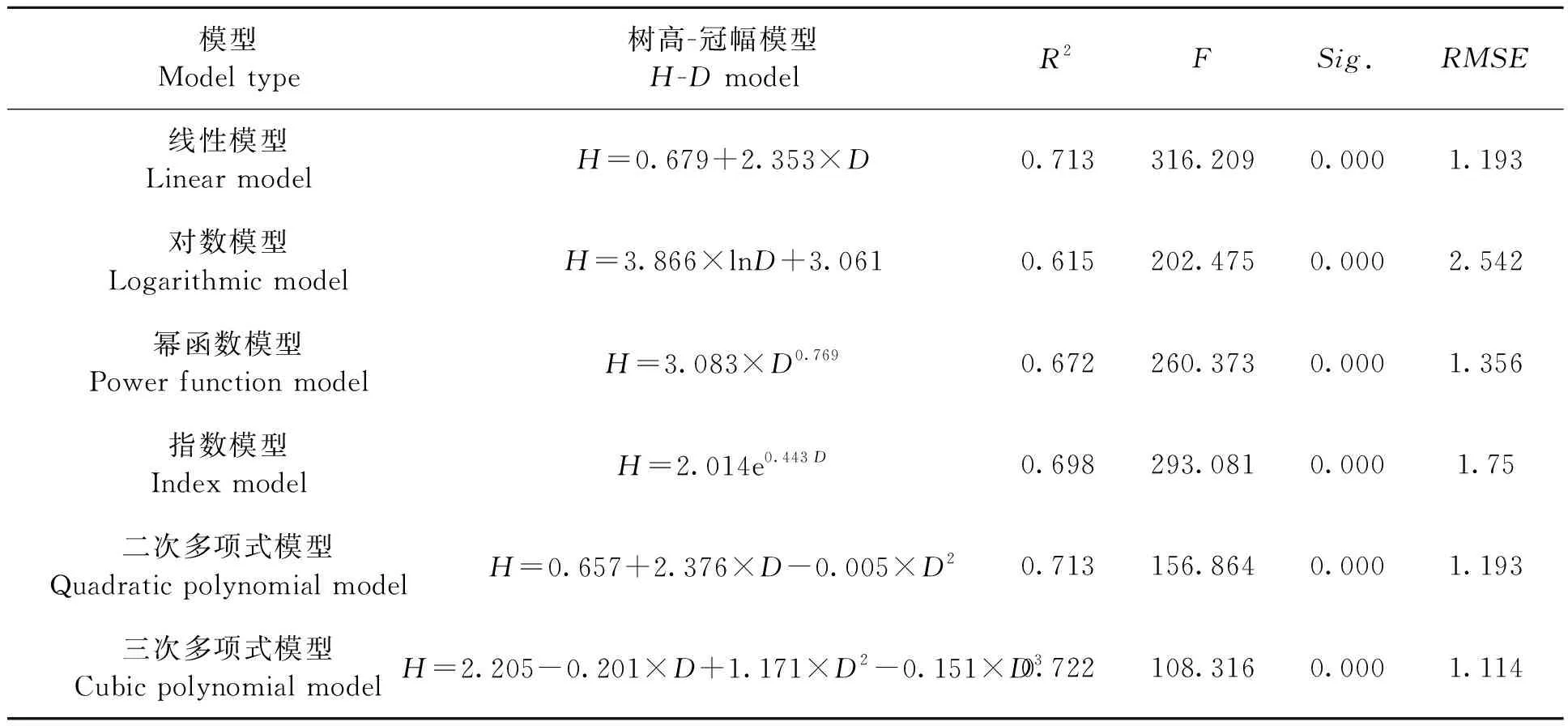
表4 山槐树高-冠幅模型Table 4 Albizia kalkora Roxb. Prain H-D model
2.3 确定最优模型
将所有树种的胸径、树高、冠幅数据分别代入回归方程,得到每个树种的12个模型。建模过程中,一些树种按指标最优的原则选取出的最优模型为二次多项式模型或者三次多项式模型,但是结合模型图像来看,二次多项式模型和三次多项式模型走势存在下降现象,可能出现过拟合的情况(图3),故应在排除这些模型之后选择最优模型。为了评估选取的最优模型的适用性和准确性,使用预留的验证数据参照RMSE值做评估。
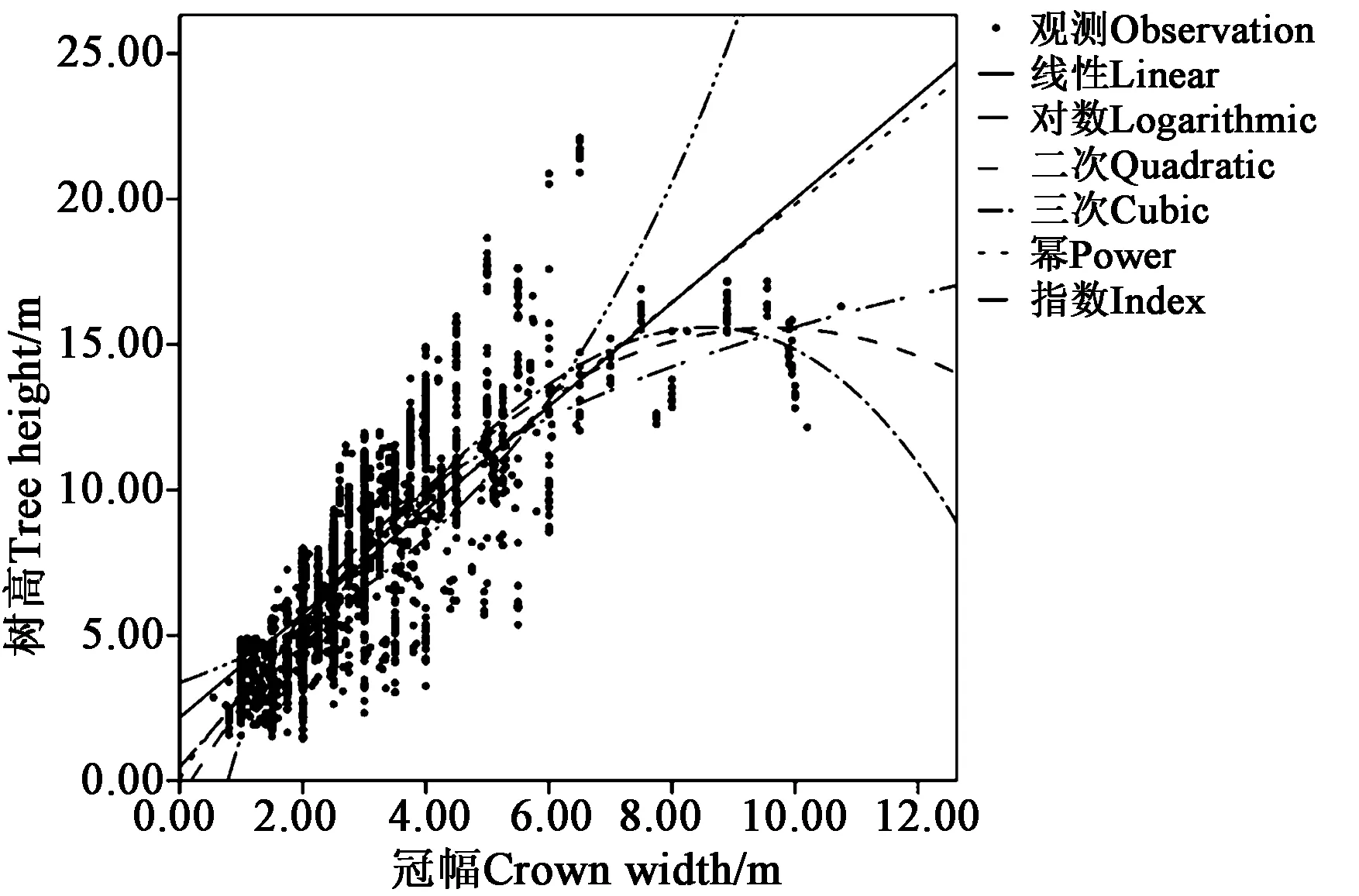
图3 榆树树高-冠幅模型曲线Fig.3 H-D model curve of Ulmus pumila Linn.
从建模结果可以看出,所有模型Sig.<0.01,说明极为显著。同样对每个树种的模型依据R2最大、F最大、RMSE最小的的原则,选取出最优模型,如表5、表6所示。在选取最优模型时,当 3 个指标相差不大时,选择系数较少、形式较简单的模型。在选取出的最优模型中,没有出现指数模型和三次多项式模型;三次多项式存在决定系数R2最大的情况,但同时存在过拟合,因此最优模型也均未选择三次多项式模型。线性模型和幂函数模型被较多树种选为最优模型。
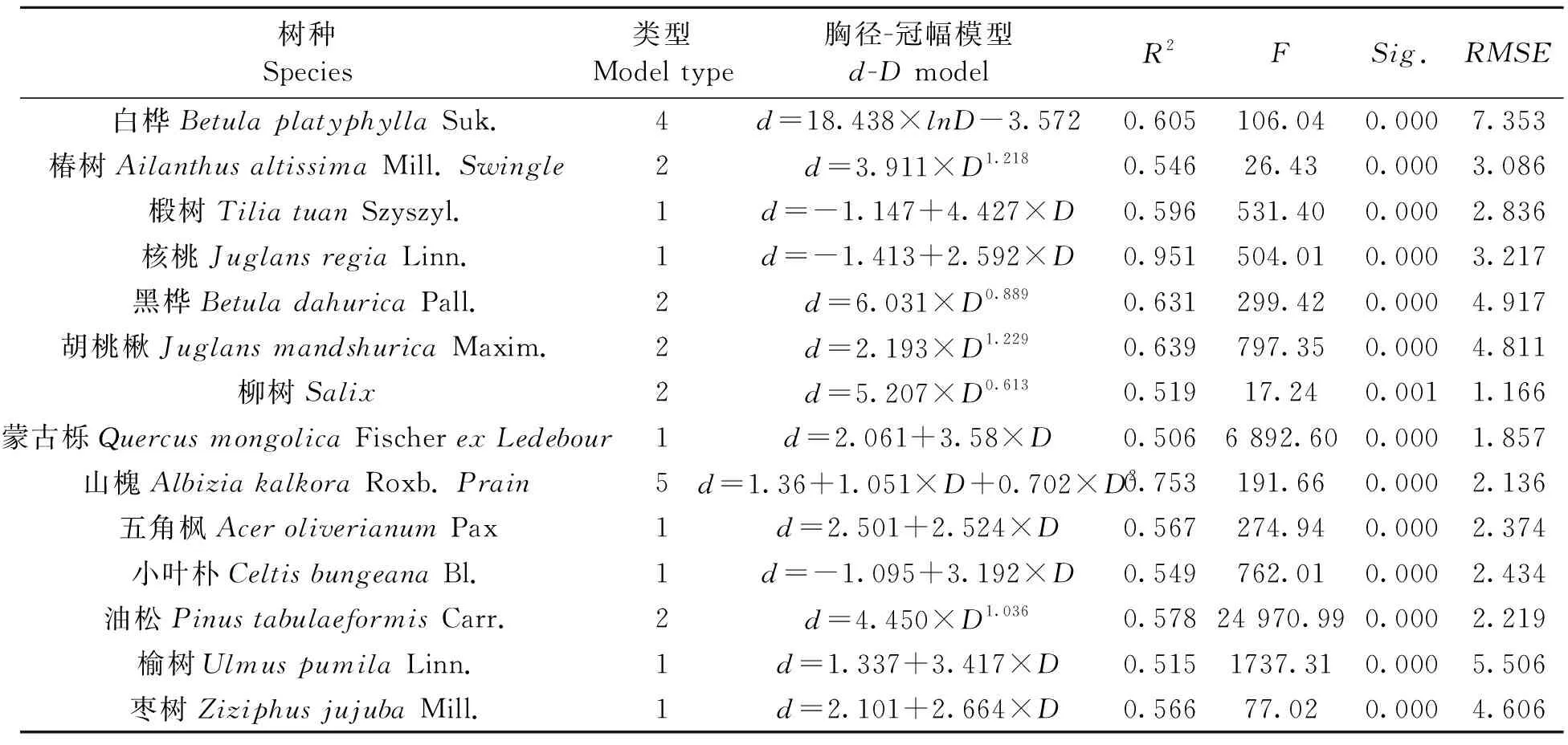
表5 各树种最优胸径-冠幅模型Table 5 Optimal d-D model
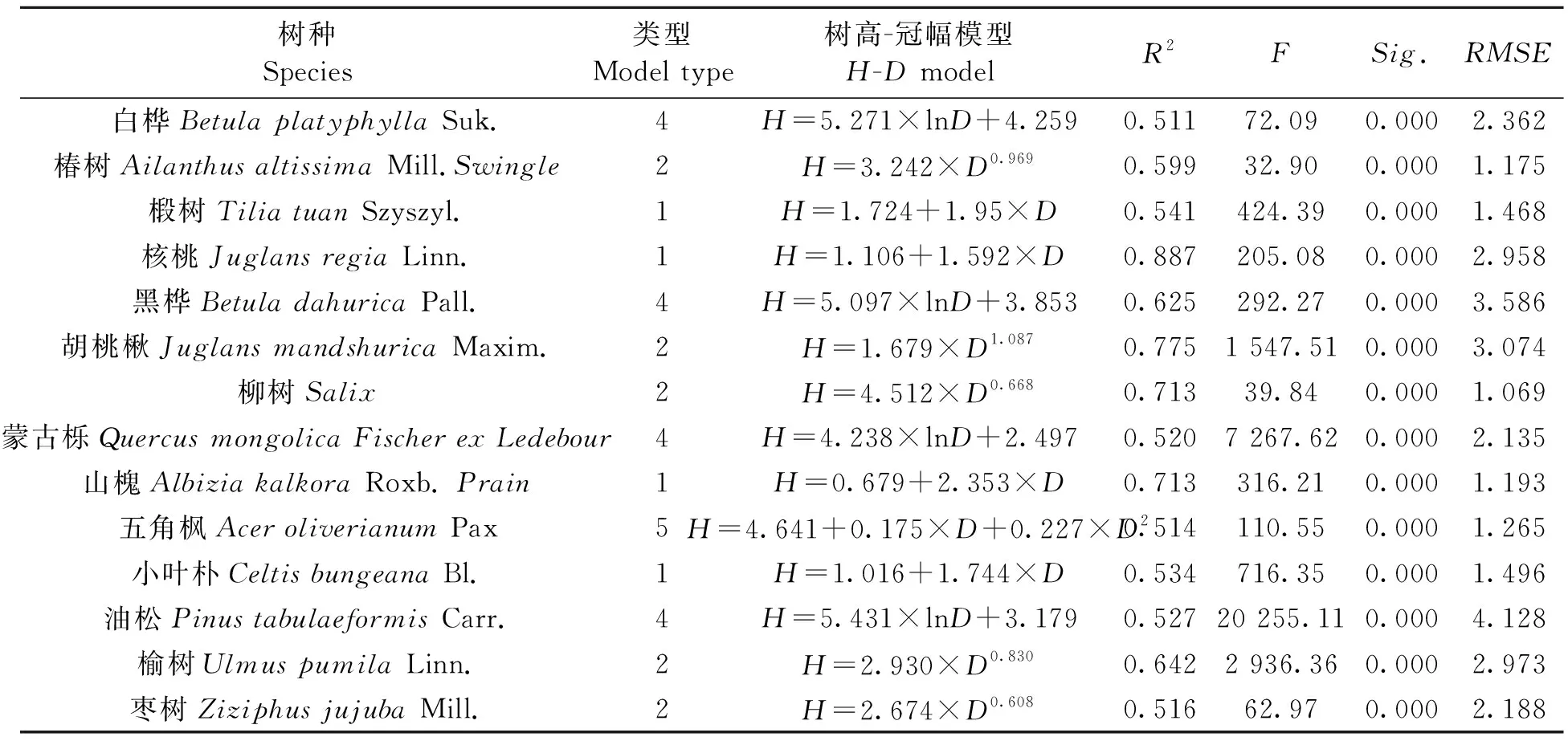
表6 各树种最优树高-冠幅模型Table 6 Optimal H-D model
选取出模型中,树高-冠幅模型的R2范围为0.511~0.887,最小的是白桦,最大的是核桃;RMSE的值最小的是柳树,值为1.069,最大的是油松的4.128。胸径-冠幅模型中,决定系数最大的是核桃,R2为0.951,榆树的最小,R2为0.515;RMSE的值来看,最小的是柳树,为1.166,最大的白桦为7.353,榆树为5.506,其余介于1.857~4.917之间。
3 讨论
从上述建模和验证结果可以看出,各树种的具体模型和参数都有不同,选取出的最优模型中幂函数模型和线性模型最多。并未出现指数模型,说明指数模型比起其他模型来说,较为不适合本研究所选树种。二次多项式模型和三次多项式模型在一些树种中出现了过拟合的情况,因此并未选择R2最高的二次多项式和三次多项式模型,说明经验模型不是越复杂越好。各树种的冠幅预测模型的决定系数R2都在0.5以上,其中决定系数最高的是核桃,胸径-冠幅模型R2高达0.951,树高-冠幅模型R2为0.887;决定系数最小的是蒙古栎,树高-冠幅模型R2为0.506,胸径-冠幅模型的R2为0.52,有一定的统计学意义。张树森等[16]利用哑变量构建了大兴安岭地区天然落叶松冠幅预测模型,模型的决定系数R2为0.717 4;韩艳刚等[17]用章古台地区的樟子松人工林数据构建了冠幅-胸径的基础模型、广义模型和基于混合效应的基础和广义模型,决定系数R2在0.5~0.7之间,在关于胸径和冠幅的研究中,决定系数很多在0.7左右,可以看出本研究精度较高。在大规模森林资源调查中,冠幅可通过遥感技术获得,但是林冠下的条件因子立地条件可能难以获取。这时直接使用冠幅数据估算树高和胸径值就有了实用价值。由此可以看出,对松山地区的数据进行模型拟合是有意义的,且模型简单易懂,在获取大量冠幅数据时可以作为以上树种用冠幅预测树高和胸径的参考,模型有一定的实用性,便于后续的应用。从精度验证来看,所有的模型显著性水平(Sig.)都小于0.01,都通过了显著性检验,且F较大,说明回归方程显著。但是从各模型的RMSE指标来看,还是存在不同程度的误差,存在这些误差可能有以下几点原因:一方面由于样本数量的限制,某些树种样本偏少,结论可能有误差;另一方面冠幅生长同样受到海拔、林分密度等的影响,下一步应在加大样本量的基础上加入一些容易获取的环境、林分和单木因子,研究这些因子与冠幅之间的关系。
近年来,随着遥感技术的迅速发展和无人机在林业中的应用,通过无人机摄影获取影像提取冠幅的方法,可高效地进行森林资源调查因子提取,提高了森林资源调查的效率,使森林资源管理实现信息化、精准化。利用树高、胸径、冠幅间的相关关系,可以通过冠幅预测胸径和树高。目前通过影像提取冠幅的方法主要有面向对象法、分水岭分割法、专家分类法等。王枚梅等[18]基于面向对象方法,提取四川贡嘎山某区域亚高山针叶林的树冠,精度较高,自动提取的东西冠幅和南北冠幅与真实冠幅的R2分别达0.765 1和 0.855 6,单元面积树木数和郁闭度的提取精度分别达0.99和0.92。孙华[19]采用标记分水岭和均值漂移分割算法对样地杉木冠幅信息进行提取。其中标记分水岭分割方法提取冠幅的最佳效果正确率为77.1%;多尺度分割漂移算法的正确率为86.6%。基于无人机和遥感影像的冠幅提取技术已经相对成熟,为建立胸径-冠幅和树高-冠幅模型提供了前提条件。本文建立的模型可对松山地区大面积森林调查中胸径、树高的预测提供参考。
猜你喜欢
吉林林业科技(2023年6期)2023-11-20 02:13:16
东北林业大学学报(2023年6期)2023-05-31 02:56:16
丽水学院学报(2022年2期)2022-04-19 01:22:10
内蒙古林业调查设计(2021年5期)2022-01-05 02:50:40
林业科技情报(2021年3期)2021-09-01 02:01:26
电脑与电信(2021年10期)2021-02-10 06:53:44
南方农业学报(2020年4期)2020-06-04 15:51:13
南方农业学报(2020年10期)2020-01-21 15:36:41
科学与财富(2018年12期)2018-06-11 01:49:24
中南林业调查规划(2017年1期)2017-12-19 00:58:07
