
集装箱船舶装卸客户满意度研究
2020-03-16 02:31李田田
电子技术与软件工程 2020年24期
李田田
(南京信息工程大学 江苏省南京市 210044)
1 引言
集装箱船舶装卸涉及船方、码头、一关三检、理货、货主等多家单位;作业过程中需要岸桥、场桥、拖车、叉车等多种设备;司机、理货员、关手、调度员、业务员等多工种的配合,装卸工艺流程较为复杂,客户满意度受到诸多因素影响,故有必要对集装箱船舶装卸客户满意度展开研究,能够有效改善影响客户满意度的关键因素,从而改变消费者行为,建立和提高客户忠诚度,提升企业的竞争力和盈利能力[1]。
2 数据与方法介绍
2.1 数据说明
通过分析简化,我们选取靠泊时长、等待作业时长、离泊时间、作业时间、在泊时长、船舱板作业、装载箱量和困难作业箱量作为我们所要研究的影响因素变量[2]。其中靠泊时长=实际靠泊时间-计划靠泊时间;离泊时间=实际离泊时间-计划离泊时间。本文分析使用的数据共有381 个样本量。
2.2 主成分分析
主成分分析是一种设法将原变量重新组合成一组新的互相无关的综合变量,同时从这些综合变量中选取较少的几个综合变量,尽可能多地反映原变量的信息的统计方法[3]。主要目的是希望能够提取出较少的几项综合性指标,它们互不相关,并且能最大限度地反映出原来较多指标所反映的信息,进而用这较少的几项综合性指标来刻画个体。
其中每个主成分的贡献率是指每个主成分所提取的信息量在全部信息量中所占的比例。前m 个主成分的贡献率之和称为前m 个主成分的累计贡献率,在实际应用中,只要累计贡献率大于85%,就可以认为前m 个主成分已综合了原变量中的大部分信息。
2.3 聚类分析
聚类分析是研究一组多维样本的分类问题。在分类之前,对类的个数和类的属性并不清楚,只是希望通过模糊概念(例如样本间的相似或相互关系的密切程度)对它们加以适当的归类。聚类是将数据分到不同的类或者簇,要满足同一个簇中的对象有很大的相似性,而不用的簇间的对象有很大的相异性。
其中K-Means 聚类是一种应用范围非常广的聚类方法,其思想是在给定聚类数k 时,通过最小化组内误差平方和来获得每个样本点的分类。首先,随即确定k 个初始点作为质心,然后将数据集中的每个点分配到一个簇中,具体来讲,找到最接近每个点的质心,并将其分配给该质心所对应的簇。之后,每个簇的质心更新为该簇所有点的平均值[4]。

图1:作业时间箱线图
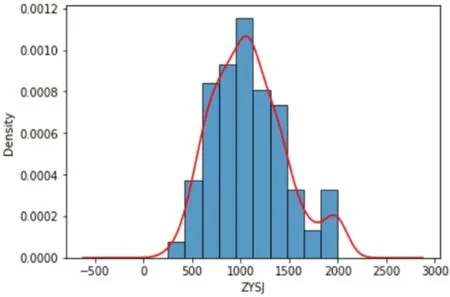
图2:作业时间核密度图

图3:在泊时长箱线图

图4:在泊时长核密度图
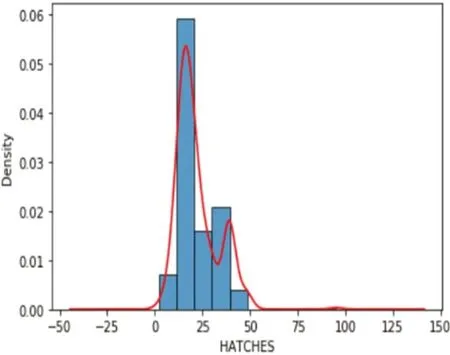
图5:舱盖板作业量核密度图

图6:装卸箱量核密度图

图7:等待作业时长核密度图
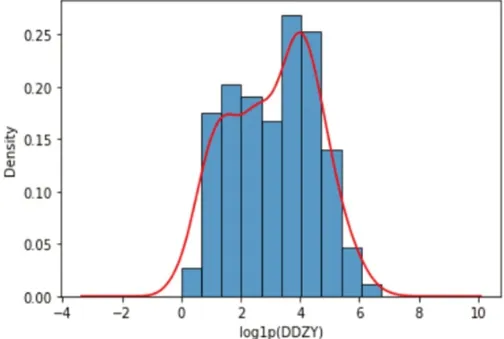
图8:困难作业箱量核密度图
2.4 决策树
分类是一种根据输入数据集建立分类模型的数据挖掘算法,通过一种学习算法来确定分类模型,该模型可以很好地拟合输入数据中类标号和属性集之间的联系。学习算法得到的模型不仅要很好拟合输入数据,还要能够正确地预测未知样本的类标号。决策树是以树结构形式来表达的一种重要的预测分析模型。

表1:在泊时长分箱结果

表2:靠泊时长分箱结果

表3:混淆矩阵
决策树的构造过程不依赖领域知识,它使用属性选择度量来选择将元组最好地划分成不同的类的属性。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性来选择输出分支,从而确定各个特征属性之间的结构[5]。构造决策树的关键步骤是在某个节点处按照某一特征属性的不同划分构造不同的分支,尽可能让一个分裂子集中待分类项属于同一类别。决策树算法主要围绕两大核心问题展开:
(1)决策树的生长问题,即利用训练样本集,进行决策树的建立。
(2)决策树的剪枝问题,在保证决策精度的前提下,在树的大小和正确率之间寻找平衡点,使树的叶子节点最少,叶子节点的深度最小。
3 主要结果
3.1 数据预处理
3.1.1 靠泊时长(DDKB)
靠泊时长的数据分布大都集中在[0,25]区间以内,整体呈现非正态分布,根据数据的特点,对数据进行分箱处理,尽量保证每个箱子分到的数据均匀。采用了左闭右开的方式进行分箱,由于值为0 的数据个数偏多,所以将0 单独作为一个箱子,分箱的结果如表1 所示。

图9:聚类结果

图10:散点图1
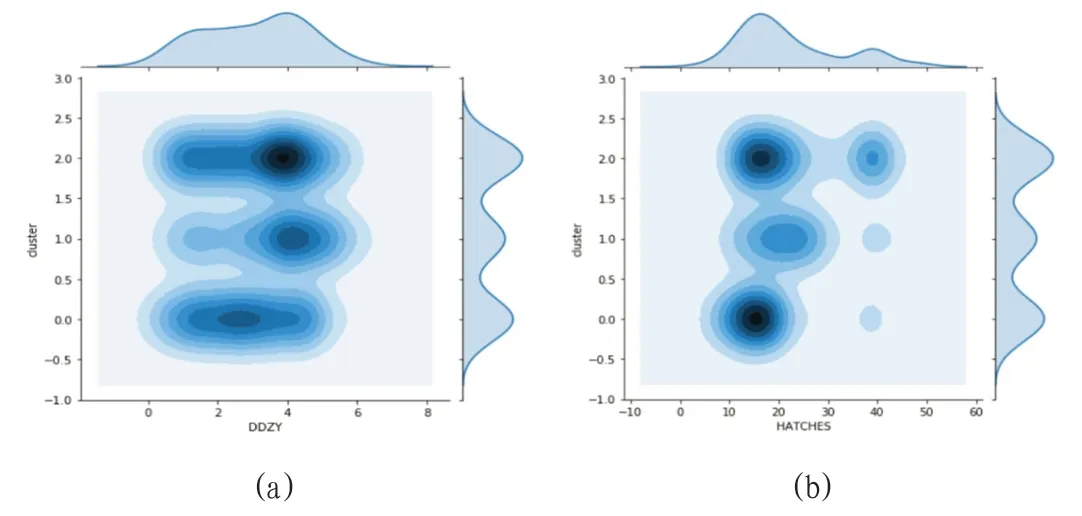
图11:双变量核密度图1

图12:双变量核密度图2
经过分箱以后,将每个区间进行命名,一共分成5 个箱子,可以看成5 个类别,也就是说将在泊时长进行变量转化,从数值型数据转化为分类变量,在后续处理中,分别将其记为0,1,2,3,4,方便建模。
3.1.2 作业时间(ZYSJ)
作业时间呈现右偏分布,因为数据有缺失,所以采用中位数的方法对缺失值进行填充。对数据进行填充后,并通过箱线图(图1)检测异常值。
对异常值采取盖帽法进行处理,由箱线图可知,大于2000 的值都是异常值,对将大于2000 的值都设为2000。将处理后的数据画核密度图(图2),可以看出呈现正态分布。

图13:散点图2

图14:决策树

图15:变量重要性排序
3.1.3 离泊时长(DDLB)
离泊时长全部数据大部分集中于[0,400]区间内。因为离泊时长有缺失值,而且离泊时长服从严重的偏态分布,所以不宜使用全部数据的均值或中位数进行填充,故截取数据范围在[0,400]的范围,观察其分布情况,呈现右偏分布,则使用该区间的中位数进行缺失值填充。根据离泊时长数据特点和变量特征,将采用盖帽法,令大于1700 的数值等于563,再采用分箱的方式,分箱结果如表2 所示。
3.1.4 在泊时长(ZBSC)
作出在泊时长的箱线图(图3),发现值大于2200 以上的都是异常点,故采用盖帽法,将大于2200 的值等于2000,并作出处理过后的在泊时长核密度图(图4),发现数据已呈现正态分布。
3.1.5 舱盖板作业量(HATCHES)和装卸箱量(XL)
经绘制箱线图检验舱盖板作业量和装卸箱量的异常值,发现舱盖板作业量只有一个异常点,值为95,采用盖帽法改为48。处理后的数据呈正态分布如图5 所示。装卸箱量小于10 和大于900 的数据是异常点,将盖帽处理后,呈现正态分布如图6 所示。
3.1.6 等待作业时长(DDZY)、困难作业箱量(DIFF)
等待作业时长呈右偏分布,故对数据进行取对数处理,经处理后的直方图如图7,可见呈对称分布。
从图8 看出困难作业箱量的分布近似为正态分布。
3.2 实证分析
3.2.1 聚类分析
主成分分析是一种常用于减少大数据集维数的降维方法,通过将高维变量缩减到低维变量,并能通过低维变量代表原数据的大部分信息。减少数据集的变量数量,自然是以牺牲精度为代价的,降维的好处是以略低的精度换取简便。因为较小的数据集更易于探索和可视化,并且使机器学习算法更容易和更快地分析数据,而不需处理无关变量。针对本文胡数据,通过提取两个主成分,方差贡献率达到95%,说明提取出的两个主成分能够反映原来变量的大部分信息。
将提取出的两个主成分用于聚类分析的变量,以第一主成分作为横坐标,以第二主成分作为纵坐标,得出分类结果如图9。其中第一个类别有126 个样本,第二个类别有106 个样本,第三个类别有149 个样本。并从聚类的结果来看,分成3 类效果较好,类与类之间界限清晰,存在较大差异。
3.2.2 探索性分析
通过聚类分析得到各个样本的类别,将样本类别作为研究的目标变量,分别查看各个影响因素与类别之间的关系。
(1)不同类别下对比。
由图10 可以看出在不同类别里面,样本点的分布不同,在类别0 情况下,作业时长基本都是低于1100,在类别1 情况下,作业时长大部分高于1100,而在类别2 里作业时长处在1000 和1500之间。靠泊时长处在区间[10,50)的样本被分到类别2 的数目较少,处在区间[1,10)的样本被分到类别0 的数目较少。
(2)单个因素与类别。
双变量核密度表示如果颜色越深,则频数多大,故由图11 和图12可以看出类别0的情况下,等待作业时长主要集中在[2,3]之内,船舱板作业主要集中在[15,20]之内,装载箱量主要集中在[300,400]之内,困难作业箱量主要集中在[0,10]和[30,40]之内。同理也可以看出类别1 和类别2 的分布情况。
(3)在泊时长、作业时间和类别。
由散点图图13 可以看出在泊时长在[750,1000]区间和作业时间在750 附近的值被分在了类别0,值越大则越容易被分为类别1,处在中间范围的被分为了类别2。
综上所述,根据集装箱船舶装卸背景及数据特点,将类别按照客户满意度进行划分,一般来说客户比较倾向于希望在泊时长短,作业时间少,所以类别0 表示客户的满意度是不满意,类别1 表示客户的满意度是满意,则类别2 表示客户的满意度是一般。
3.2.3 决策树
通过按照样本的60%的比例划分出训练集,剩下的40%作为测试集,并根据训练集训练出的模型对测试集进行预测,从而判断模型的建立是否合理。得到混淆矩阵如表3 所示。从混淆矩阵结果看出,模型的建立是合理的,其中只有少数样本预测的类别与实际类别不符合。
绘制决策树如图14 所示。在划分数据集之间之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。从决策树可以看出在泊时长这个因素最为重要,以在泊时长为1338.5 为分界线进行划分,如果在泊时长小于1338.5,再根据作业时间进行划分,可见作业时间是继在泊时长的第二个重要影响因素。如果在泊时长小于1338.5 且作业时间大于940.5,则考虑装载箱量因素。以此类推,可根据细分具体情况,从而判断在何种情况下,判断客户的满意度是满意的。对于客户不满意情况,可针对具体情况,进行改进,对于满意度一般的情况,也可以进行某些方面的提高,从而更充分的让客户感受到满意。
由对特征的重要性进行排序,得到的结果如图15 所示,可见在泊时长、作业时间和装载箱量因素为主要影响因素。靠泊时长、离泊时长、船舱版作业、等待作业时长和困难作业箱量等因素对客户满意度的影响不大。
4 结论
通过对集装箱船舶装卸相关指标进行变量转换、缺失值填充,异常值检测等措施以后,将其做主成分分析,通过提取了两个主成分,累计贡献率达到95%,能够充分代表原始数据的大部分信息。利用提取出的主成分将整个样本进行聚类分析分成三类,其中包括客户满意,客户满意度一般和客户不满意三种。将客户满意度作为目标变量、影响因素作为自变量,从而构建决策树。使用训练集得出的决策树用于预测测试集,预测效果良好,并且得出在泊时长、作业时间和装载箱量因素为主要影响因素。靠泊时长、离泊时长、船舱版作业、等待作业时长和困难作业箱量等因素没有参与到决策树建模中,故对客户满意度的影响不大。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中国水运(2018年7期)2018-09-21
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
新校长(2016年8期)2016-01-10
郑州大学学报(医学版)(2015年1期)2015-02-27
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
食品科学(2013年8期)2013-03-11
