
基于卷积神经网络的计算机网络流量异常检测
2020-03-15 02:44:32黄昱鸿
电子技术与软件工程 2020年23期
黄昱鸿
(福建龙溪轴承集团股份有限公司 福建省漳州市 363000)
1 引言
随着互联网的普及,网络用户数量不断增加,网络数据量也在急剧增加,这些都对网络安全研究提出了重大挑战,各种网络安全威胁日益明显。在计算机网络中,各种攻击、故障等安全问题往往会导致网络流量的变化,由此,对异常网络流量实施检测对于确保网络安全有着十分重要的意义。笔者所从事工作即为计算机管理与网络维护,由此,提出了一种有效的网络流量异常检测技术,旨在为相关工作人员提供一定的借鉴与参考。
2 计算机网络流量异常检测算法设计
本文针对以往计算机网络流量异常检测应用神经网络时存在的问题,构建了一种基于动态自适应池化的卷积神经网络流量异常检测模型,通过进行池化层的分析与调整,根据各种函数映射动态调整池化过程,提高模型的通用性。
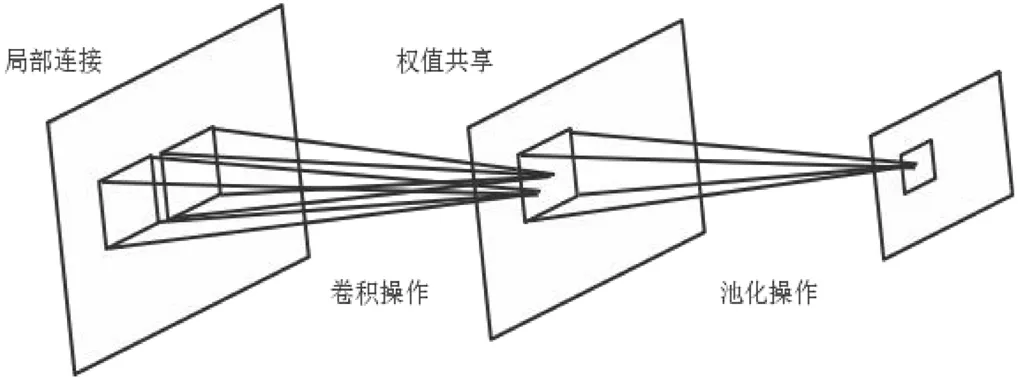
图1:卷积神经网络特点
2.1 卷积神经网络原理
传统的感知神经网络通常采用全连接结构,也就是说,每个神经元与前后相邻层中的每个神经元相互连接。这种全连接结构训练网络上的权值和偏差等参数的数量随着网络层数的增加而迅速增加,使其容易出现局部优化和梯度衰落等问题。卷积神经网络是一种典型的深度学习方法,它具有特殊的网络结构,包括局部连接、权值分布、向下采样等结构设计思想,能直接从数据中学习更高效的函数,如图1。从隐写的角度来看,卷积神经网络的卷积结构有助于捕获相邻像素之间的相关性,提高特征提取的效果。与此同时,权值分布、池化等结构也显著减少了训练参数,使网络模型能够处理更大尺寸和容量的采样数据[1]。
2.2 网络流量异常检测模型
2.2.1 网络流量异常检测结构
本文构建的网络流量异常检测模型主要涉及到两个方面,分别为数据处理和流量数据检测,如图2。
第一阶段:数据预处理,获取流量和所需的数据集。使用时间序列函数方法处理数据,拟合、对齐、缩放数据集中的每个流量请求,生成50*150 的矩阵数据,并使用矩阵数据作为输入。
第二阶段:构建模型,进行池化层和Dropout 层的设计。基于动态自适应池化进行卷积神经模型的构建,以此实现网络流量异常的检测。对于检测得到的结果,将其划分为两类:正常和异常[2]。
2.2.2 动态自适应池化卷积神经网络模型
动态自适应池化卷积神经网络模型如图3。当检测到网络流量异常时,对流量数据进行转换,使之转变为矩阵数据,并设置为输入。池化属于流量特征的第二次提取,在此过程中,需要计算池化域的流量特征,并在全连接层后进行Dropout 层的添加。
为避免异常流量特征提取过程出现模型过拟合现象,在模型上增加了一个Dropout 层来解决过拟合问题。在此之后,训练集的错误率非常低,而测试集的错误率却增加了很多。在训练过程中,神经网络的各个模块处于相互连接的状态。在每个神经元记录流量特征的过程中,特征信息被覆盖,所以训练集仅仅具备单一的一些特点,使得问题随之出现。而有效应用Dropout 则可以避免以上情况的发生,通常情况下,Dropout 层只会让其中一层神经元给出反应,通过此神经元来进行权重的更新。这使得神经元之间处于相互独立的状态,不会相互影响,避免固定功能发生变化[3]。
在模型训练中,将全连接层中的神经元动态设置为0,概率为40%。设置为0 的神经元可以认为不参与权值的更新,每次不固定的将神经元设置为0。每个训练集随机选取神经元,测试数据集也按照40%的比例选取。
2.3 网络流量异常检测算法
池化通常包含有平均值池化模型和最大池化模型这两种方法。本文以最大二均值池化来实施计算,见式(1):

该公式在最大池化的基础上进行了改进,将两个最大的项相加,通过得到的值来计算平均值,以此得到子样本的特征值。在最大二均值池化的基础上对动态自适应池化模型进行了改进和优化。对于流量特征图的二次提取,这两种模型得到的结果都不理想[4]。为此,本文结合以上两种模型存在的缺陷给出动态自适应池化算法,算法的计算公式见式(2):
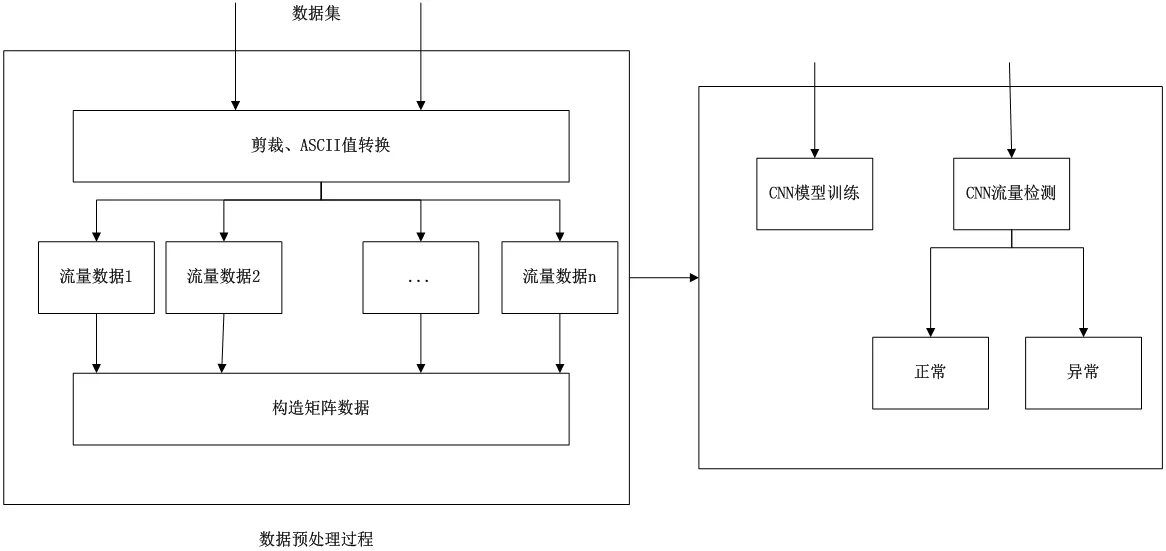
图2:网络流量异常检测框架
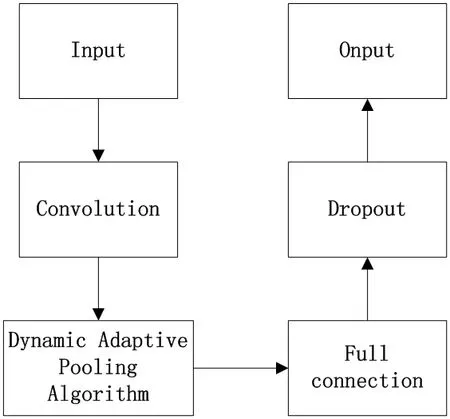
图3:动态自适应池化卷积神经网络模型
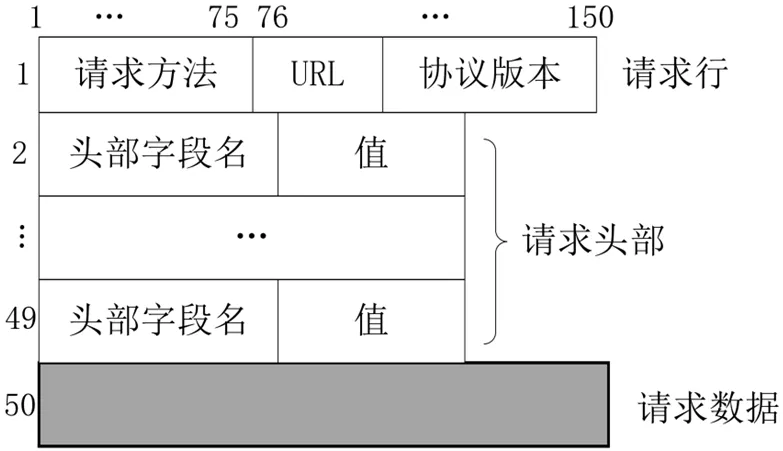
图4:矩阵数据格式

其中公式(2)中的u 为池化因子,如公式(3)所示:

池化的过程和卷积差不多,因此,本文基于卷积来进行池化。针对这两种类型的池化,在最大双均值的基础上对动态自适应池化进行了改进和优化。在不同的迭代时间处理池化的不同区域时,模型提取性能更准确[5]。
3 计算机网络流量异常检测实验分析
3.1 实验数据集
实验数据采用的是HTTP CSIC 2020 数据集。其涉及到36000个常规请求以及25000 个非常规请求。为便于后文分析,本文将数据集分别设置为Normal(training)、Normal(test)以及Anomalous(test)三种类别,并将其拆分为单独的数据查询文件。

表1:实验结果
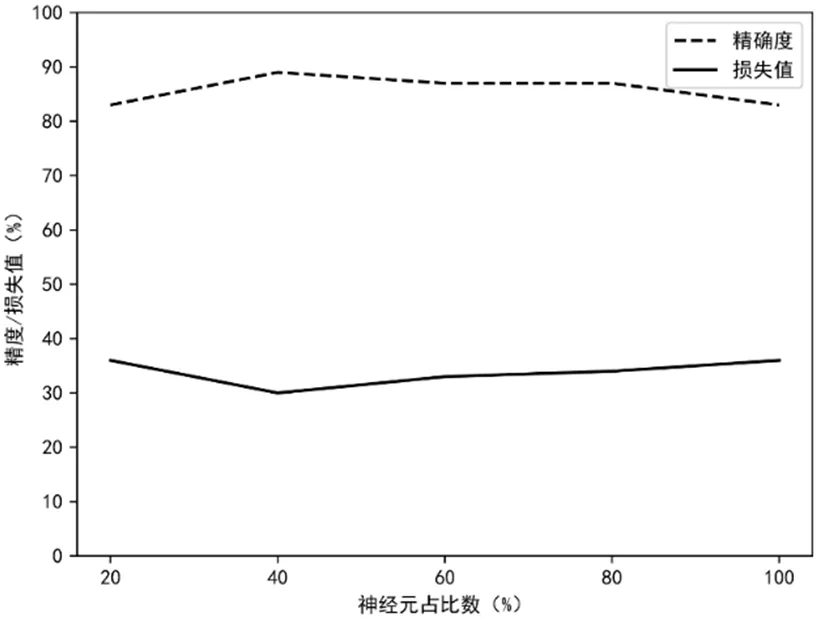
图5:神经元占比实验图
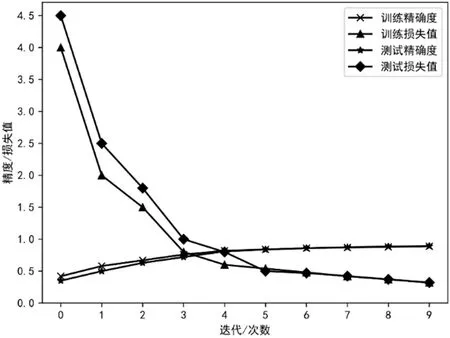
图6:实验精确度和损失值
该数据集涉及到GET、POST 以及PUT 这三种类型的数据。Web 请求记录至少包含上述一种数据类型,数据集根据请求头进行分段,分段基于为每个流量接收的HTTP 请求消息的格式。进行数据的处理之后,针对各流量请求实施切割、对齐以及填充,得到50×150A 的矩阵数据。图4 为矩阵数据格式。相比之下,矩阵数据流可以将数据流的原始词序完好的保存下来,同时可以展现出结构化数据格式,数据流的采集更为精准。
3.2 实验结果分析
实验环境设置为windows 10 操作系统,以Python3.7.3 作为分析语言,矩阵数据采用的数据大概包含有61000 个,训练集与测试集比选择的是9:1。利用估计值的精度和损失值来评价模型检测的结果,精度按式(4)计算。精度越高,检测效果越好。
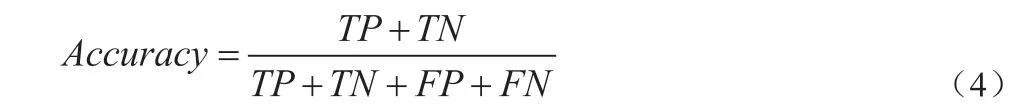
在进行实验分析的过程中,以交叉熵代表损失函数,此处表达的意思为两个概率之间的距离。公式与(5)一致,在此之中,q表示的是预测的概率分布,p 表示的是正确的概率分布。

本实验主要将本文提出的基于DAPA 的卷积神经网络方法与规则匹配方法、传统的最大二均值池化算法(MTPA)进行对比,结果见表1。可以看出,本文提出的方法是精准率最高的,损耗值最低。
图5 表示的是对Dropout 技术进行添加后,以不同的参数进行实验,对添加前后的效果进行比较,之所以加入Dropout 技术主要是对模型的过拟合问题进行优化。
基于图5 能够得知,在没有Dropout 技术的情况下,损失最大。当训练一个模型时,模型对训练数据集进行过训练以减少损失值,导致过拟合。对Dropout 技术进行添加之后,神经元比例设置成40%的情况下,损失值实现了4.2%的降低,准确率则实现了6%的提升。所以,为了提高模型的适用性,本文将该参数设为0.4。
本文对不同迭代次数的实验进行了对比,实验结果如图6。
基于图6 能够得知,模型针对各个算法都进行了迭代训练。每进行一次训练,神经元的组合都会发生变化。这可以让神经元的组合一直保持更新,不会处于固定的状态下,从而确保参数的分布是均匀的。
4 结论
通过详细研究计算机网络流量的异常检测,引入卷积神经网络,构建了基于动态自适应池化的卷积神经网络异常流量检测模型,通过进行池化层的改进,基于数据集HTTPCSIC2020 进行实验,得知提出的基于DAPA 的卷积神经网络算法是三种网络流量异常检测算法中精确度最高,损失值最低的,验证了提出方法的可行性。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22 09:52:26
软件导刊(2022年3期)2022-03-25 04:45:04
自然杂志(2021年6期)2021-12-23 08:24:46
微型电脑应用(2021年3期)2021-03-31 08:56:46
计算机技术与发展(2019年1期)2019-01-21 00:56:38
现代装饰(2018年5期)2018-05-26 09:09:01
北京航空航天大学学报(2017年7期)2017-11-24 05:27:28
电源技术(2015年5期)2015-08-22 11:18:38
