
基于视觉的动态手势识别概述
2020-03-13 10:26李为斌
计算机应用与软件 2020年3期
李为斌 刘 佳
(南京信息工程大学自动化学院 江苏 南京 210044)
0 引 言
随着计算视觉技术的迅速发展,传统的人机交互技术(如键盘、鼠标等)逐渐无法满足人们日常活动中的应用。许多研究工作致力于开发新的人机交互技术,包括手势识别、人脸识别、人体姿态识别[1]等。其中,手势识别是人机交互中一种十分重要的交互方式,它主要由计算机通过视频输入设备(摄像头等)对用户手势进行检测、跟踪与识别,从而理解人的意图。鲁棒的人手识别系统对手语识别、机器人控制、人机交互等多方面应用的发展起到积极影响[2]。
在手势识别技术发展初期,一些研究[3]使用数据手套等传感器设备来直接检测、获取人手及其各个关节的空间信息,以便于精确地提取并识别出特定的手势。一些学者将光学标识引入识别系统中以提高识别准确性,也取得了较好的效果[4]。数据手套和光学标识等外部设备虽然提高了识别的稳定性和准确性,但在一定程度上掩盖了手势自然的表达方式。为了追求用户更舒适的体验,自然手势识别技术逐渐成为当前研究的重心。然而,由于人手结构的复杂性、手势动作的多义性以及图像获取过程的模糊性,使得手势识别成为了一个极具挑战性的研究课题。
手势一般可划分为静态手势和动态手势两类,本文主要对近年来基于视觉的动态手势识别研究进行综述,着重于从手势分割、手势跟踪、特征提取和识别算法四个方面进行梳理和归纳。基于视觉的手势识别系统基本流程如图1所示。
1 手势检测和分割
手势分割旨在将图像中手势区域和背景区域分离。手势分割的结果在一定程度上会影响到手势跟踪、特征提取以及手势识别的准确性。目前手势分割技术主要受限于复杂的背景条件,如手势距离视频采集设备不一、光照条件变化频繁等。另外手势运动幅度较大也会影响到手势分割的结果。常用的手势分割方法可分为基于表现特征、基于运动信息、基于深度阈值和混合分割四类。
1.1 基于表现特征的分割方法
对于动态手势识别,主要考虑的是手势的运动而不是手势的姿态,计算复杂度应尽可能低。因此,低层次的特征(如肤色、手形)往往是首选。肤色检测是最常用的分割方法,它利用人手肤色和背景间的差异性以实现分割。肤色检测的关键因素在于颜色空间的选择。RGB颜色空间[5]在早期手势分割研究中得到了广泛的应用,但其对光照条件敏感,且计算成本相对较高,学者们提出了几种能更好地分离开色度和亮度分量的正交颜色空间,如HSV[6]、YCrCb[7]、Lab[8]等。在HSV中,颜色信息多由色调(Hue)分量和饱和度(Saturation)分量表示,通常不随亮度(Value)分量变化而变化。在YCrCb内,Y表示图像的亮度分量,Cr和Cb表示色度分量。肤色分割方法计算成本低,且对手势的旋转、部分遮挡和尺度变化具有一定的鲁棒性,但它不能有效处理背景中类肤色的区域(如人脸、手臂)。
利用手形特征分割手势是另一种简单有效的方法。手势轮廓能有效表示手的形状,它可以通过边缘检测算子(如Canny、Sobel、Prewitt、Laplace等)获得。与肤色检测相比,轮廓特征不受光照变化和类肤色背景的干扰,但其有效性可能受到部分遮挡和视点变化的影响。综上所述,肤色和手形特征在手势分割应用中各具优势,一些研究通过将它们结合起来以提高准确性[9-10]。
1.2 基于运动信息的分割方法
在某些特定的交互场景中,人手是唯一移动的对象,利用运动信息来检测和分割手势的方法是可行的。这一领域主要有背景差分法和光流法[11]两类。背景差分法是指将图像序列中的当前帧与预设的背景图像进行比较来检测运动的手势。该方法检测运动目标速度快,易于实现,其关键在于背景图像的选取。
光流法是一种基于像素的目标运动估计方法,它利用图像序列中的像素强度数据的时域变化和相关性来确定各自像素位置的运动。与背景差分法相比,基于光流的分割算法无需预先保存背景图像,它能在复杂环境下清晰地描述手势的运动,具有较好的鲁棒性,但在手势有遮挡时分割效果不佳,且实时性较差。
1.3 基于深度阈值的分割方法
随着深度传感技术迅速兴起,基于深度相机的手势识别的研究得到了更多的关注。与基于单目视觉的方法相比,其主要优势是,能够有效地捕获具有时空信息的深度图像。深度图像中每个像素点代表了在三维场景内目标对象与摄像头间的真实距离,这也为基于深度阈值的分割方法提供了可靠的理论依据。文献[12]假设人手是距离视频设备最近的对象,根据经验设置了一个深度值在0.8米至1米的阈值区间,通过将人手置于此区间内以实现检测和分割的目的。文献[13]提出了一种动态阈值分割算法,首先利用NITE工具包来检测手掌质心并跟踪,然后根据质心的深度值设置一个动态阈值区间,依据此区间分割出动态手势。上述两种方法虽然简单可行,但其缺陷在于无法精确地切除手臂区域。
针对手臂区域的分割问题,Ren等[14]建议在手腕处系一条黑色的丝带,这是最简单、稳定的优化方案,也在很多识别系统中得以应用。Chen等[15]将手掌矩心记作圆心来绘制手掌的最大内圆,在内圆的像素点集合内,相距最远的两个连续像素点被记作手腕的两个端点,最后根据手腕线完成手臂和手势区域的分离。该方法具有较强的适用性和准确性,但计算复杂度略高,有待进一步优化。
1.4 混合分割方法
基于深度阈值的分割方法往往假设人手是最接近相机的对象,显然此方案仅适用于非常有限的场景。Tao等[16]通过结合动态阈值和YCrCb颜色空间的方法进行手势识别和分割,取得了较好的效果。Wen等[8]设计了一种基于深度信息的双手识别系统,它首先基于Lab颜色空间完成手势的粗分割,然后使用K-means聚类算法进行手部聚类以进一步分割手势区域。该方法能有效解决因双手互相重叠而导致分割失败的问题。综上所述,通过利用彩色图像和深度图像的彼此优势,设计一种具有更高精度的分割算法是值得探究的。
2 手势跟踪
手势跟踪在动态手势的识别中起着关键的作用,其主要目的是确定视频序列中人手的运动轨迹。目前手势跟踪算法主要分为三类:基于生成模型、基于判别模型和基于混合模型的跟踪方法。
2.1 基于生成模型的跟踪方法
生成模型方法通过在线学习方式建立目标模型,然后使用模型搜索重建误差最小的图像区域,完成目标定位。使用生成模型跟踪手势时,首先需要对当前帧中的手势区域进行建模,然后在下一帧中寻找与该模型最相似的区域就是预测位置。生成模型以统计学和贝叶斯为理论基础,一般涉及的算法有连续自适应均值漂移(Camshift)算法、卡尔曼滤波(Kalman Filter)、粒子滤波(Particle Filter)等。
2.1.1Camshift算法
Camshift算法是一种以颜色概率分布图为基础的目标跟踪算法。文献[17]使用Camshift算法和HSV颜色空间来跟踪手势,其具体跟踪过程是:首先初始化一个搜索窗口,并计算色度分量概率分布;然后使用meanshift算法调整搜索窗口的中心位置和大小;随后再将当前帧迭代得到的搜索窗口用作下一帧搜索窗口的初始值,如此反复直至收敛。该方法具有低复杂性和较高的实用性,但在更复杂的场景中它的鲁棒性不稳定。例如包含手臂区域的图像,由于手臂具有和手势相似的颜色概率分布,会导致搜索窗口漂移。为了解决这一问题,Yang等[18]寻找并计算了一个手部深度优化概率,然后将其与Camshift算法进行结合,通过实时更新直方图以确保手部跟踪的准确性。
2.1.2卡尔曼滤波
卡尔曼滤波是一种能够对目标位置进行有效预测的算法。当目标的运动满足高斯模型时,对其运动状态进行预测,并与观察模型进行对比,根据误差来更新运动目标的状态。Park等[19]将状态方程设为三个维度,在各个维度上使用三维向量作为在轴上的速度,并应用卡尔曼滤波算法逐帧预测手掌质心及其周围参考点。该方法能适应人手运动速度的连续变化,跟踪效果较好。Yeo等[20]利用卡尔曼滤波以消除不稳定的噪声来估计和细化最优位置。该方法能够使手部的位置或轨迹变得更加平滑且跳动更小,更适合控制应用程序。
基于卡尔曼滤波的跟踪算法具有实时性好、无偏和最优的特点,能有效地解决手势部分遮挡和跟踪丢失的问题,但缺点是仅适合于线性系统,适用范围小。为了解决这一问题,学者们提出了粒子滤波算法。
2.1.3粒子滤波
粒子滤波算法源于蒙特卡洛方法,其核心思想是利用随机搜索以获得目标的后验分布的估计。粒子滤波往往将跟踪问题视为状态估计问题。目前粒子滤波算法大多被用于跟踪手掌质心或手指的空间坐标,在跟踪过程中,通过使用一组随机采样粒子对目标的位置进行建模。文献[21]设计的跟踪算法可分为基于图像的二维位置跟踪和一维深度跟踪两部分。通过将尽可能多的处理放在二维空间中以实现更快的跟踪,指尖点三维坐标则通过合并可用的深度信息来获得。相较于文献[22]中三维跟踪方法,该算法的跟踪精度和稳定性更优异。
在嘈杂环境中,粒子滤波的鲁棒性优于卡尔曼滤波,但其也存在粒子退化现象。许多研究者尝试将粒子滤波与其他算法结合起来,解决样本退化问题[23]。
2.2 基于判别模型的跟踪方法
判别模型方法通常将手势跟踪视作二分类问题,它同时提取手势和背景信息用来训练分类器,将手势从图像序列背景中分离出来,从而得到当前帧的手势位置。目前判别模型在手势跟踪中应用较多。
Keskin等[24]提出了一种利用多层随机决策树预测手部关节位置的方法,其主要思想是通过聚类将手势数据集划分为更简单的子集,然后为每个子集训练单独的手势估计器。
文献[25]提出了一种用于无标记复杂关节实时连续手势恢复的跟踪算法,主要包括以下阶段:用于图像分割的随机决策树分类器、用于标记数据集生成的鲁棒方法、用于特征提取的卷积神经网络以及用于稳定实时手势恢复的逆运动学算法。
文献[26]提出了一种基于多视图卷积神经网络的三维回归方法,它首先将深度图像点云投影到三个正交平面上,然后为每个投影图像生成一组手关节的热图,最后将三组热图与预先学习的手势先验相融合以得到三维关节位置。
2.3 基于混合模型的跟踪方法
判别模型方法一般具有较好的稳健性,但其缺乏模型拟合中固有的准确性。生成模型方法在初始化时可能会依赖于前一帧,这使得从错误中恢复变得更具挑战性。混合模型通过结合判别模型方法和生成模型方法来提高相邻帧的模型拟合的鲁棒性。
文献[27]提出使用一种混合方法跟踪人手的关节三维运动,其中,判别模型方法采用基于部分的姿势检索算法,通过检测深度图像中的指尖来估计完整或部分手势;生成模型方法则使用颜色信息和特定手势模型来预测最佳的手势位置。
文献[28]设计了一种判别估计器用以预测手势的分布,并从该分布中提取不同的手势假设;然后通过结合粒子群优化算法和遗传算法来检测三维手势模型和观察图像之间的重建误差;最后将误差最小的结果输出。该方法具有较好的鲁棒性,且在目标跟踪丢失后能确保快速恢复跟踪。
Mueller等[29]使用两个卷积神经网络实时定位和估计人手的3D关节位置。该方法在SynthHands数据集和EgoDexter基准数据集上测试,结果表明它在目标遮挡、背景变化等环境中能实现低误差。
表1列举了近几年主流的动态手势的跟踪算法。
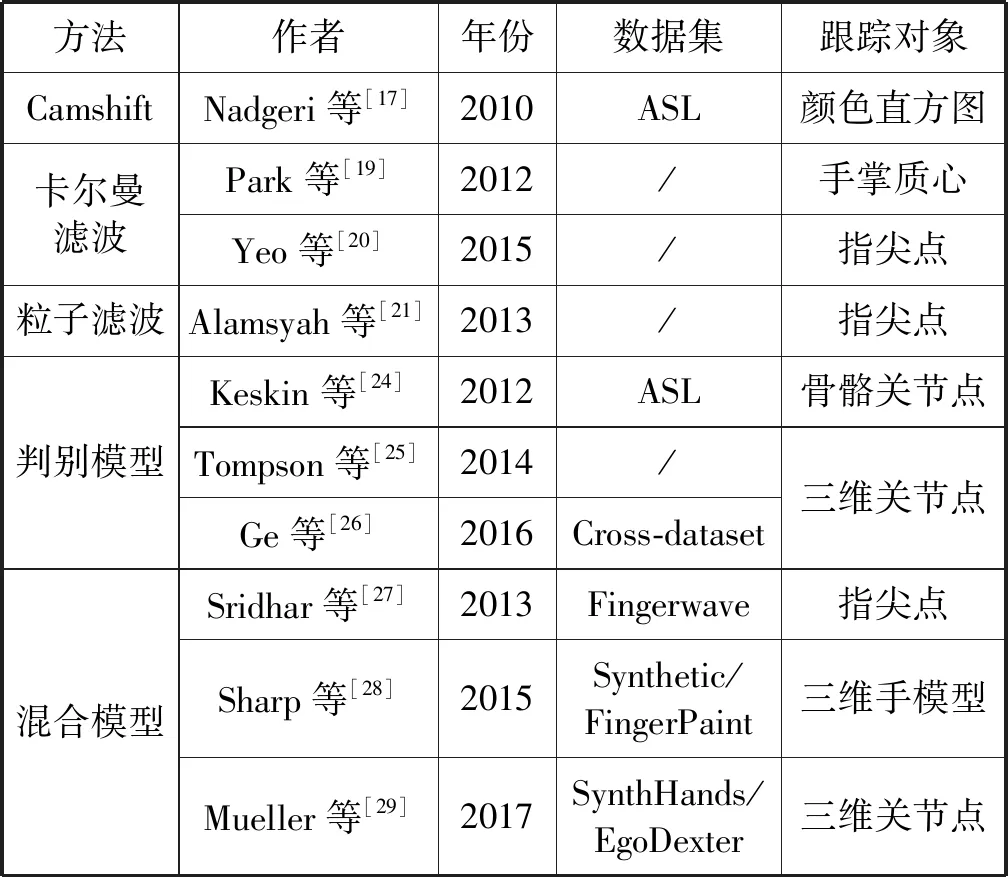
表1 动态手势跟踪算法及跟踪对象
3 特征提取
特征提取是将输入样本中感兴趣区域转换为特征向量的集合。在手势识别中,提取的特征应包含待测手势的相关信息,并以紧凑的形式表示,作为该手势的标识,将其与其他手势区分开来。结合现有的多数文献来看,动态手势特征主要包括全局特征、局部特征和融合特征。
3.1 全局特征
全局特征通常用于表示图像序列的整体属性,可以通过运动历史图、运动能量图、时空形状等加以描述。Ren等[30]在陆地移动距离算法(Earth Mover’s Distance,EMD)基础上设计了一种手指陆地移动距离(FEMD)算法。相比于其他距离度量方法,该算法仅考虑手指的外轮廓而不包括手掌区域,它通过一组记录着每个轮廓顶点到手掌中心点之间相对距离的时间序列曲线来表示手部轮廓,其中每个手指对应于曲线的某一段。文献[31]提出超像素陆地移动距离(SPEMD)算法来度量不同手势间的差异性,其中手形和纹理信息以超像素的形式进行描述。该方法对手势的旋转、平移和缩放都有一定的鲁棒性。文献[32]通过组合指尖到手掌质心的距离、手形边缘曲率特征以提高识别准确率,但也导致其特征维数较高,实时性受到影响。
3.2 局部特征
这类特征通过提取图像序列中能有效地表征动态手势的局部特征点,再对这些特征点的各种属性进行统计建模,实现对动态手势的描述。文献[33]提出了HON4G(Histogram of Oriented 4D Normals)描述符来描述深度序列,该描述符使用了时间、深度和空间坐标的4D空间中的表面法线方向直方图来捕获运动和几何数据。在MSR Gesture 3D数据集上测试,实验结果验证了该描述子的优越性。
文献[34]提出了一种改进的三维局部稀疏运动尺度不变特征变换(3D SMoSIFT)特征描述子。首先为每个灰度帧和深度帧构建金字塔作为尺度空间,然后使用角点检测算法和稀疏光流法快速检测和跟踪尺度空间中动态手势周围的鲁棒关键点,再基于这些关键点构建三维梯度和运动空间,最后分别在两个空间上计算SIFT描述符。在Chalearn手势数据集的评估结果表明,该特征能明显提高识别精度。
文献[35]提出了三维面片直方图(Histogram of 3D facets,H3DF)特征描述符来有效捕获和编码三维形状信息。首先将三维云点及其周围点定义为三维面,其中每个面均由小平面建模,然后使用空间中心池策略来组织小平面的集合以描述感兴趣区域,形成最终的H3DF描述符。
3.3 融合特征
对于某些特定手势,单一特征通常能给出优异的识别结果,但其适用范围小,且稳定性一般。为了提高稳定性和适用性,学者们考虑了将多个特征相融合的方案。Monnier等[36]首先从每个视频帧中提取归一化骨架关节位置和HOG特征,以产生相应的多维描述符序列,然后对这些特征描述符进行插值以确定其固定宽度,最后合并该序列中的特征形成最终描述符。Liang等[37]提出了一种融合全局特征运动能量图和局部特征梯度直方图来识别手势的方法。首先将归一化的运动能量矢量分割为一组分段,并利用相应的帧索引将深度视频分割成一组网格;然后使用HOG特征从深度序列中提取手势的局部纹理信息和运动信息。
4 手势识别
识别算法是手势识别研究中最后但最重要的一步,当前主流的识别算法包括基于模板匹配的方法、基于数据分类的方法和基于深度学习的方法。动态时间规整算法(Dynamic Time Warping,DTW)是最常用的模板匹配方法;数据分类方法中应用较为广泛的有支持向量机(Support Vector Machine,SVM)、人工神经网络(Artificial Neural Network,ANN)、隐马尔可夫模型(Hidden Markov Model,HMM)等;深度学习方法有卷积神经网络(Convolutional Neural Network,CNN)。
4.1 动态时间规整
DTW算法是一种基于动态规划思想的非线性规整方法,它利用规整函数描述待测模板和参考模板的时间对应关系,以求解出两个时间序列的相似度。使用DTW算法识别手势时,需预先记录一系列参考模板,然后匹配并计算待测手势和参考模板间的相似度,将其中相似度最高的模板手势记作识别结果。DTW算法具有训练样本需求少、精度高等特点。Plouffe等[38]利用DTW算法识别动态手势,识别精度达到96.25%。
然而,DTW算法受限于计算复杂度高、稳定性差等问题,尤其是在复杂手势、训练样本数量较多等情况下。因此,涌现了很多优化原始DTW算法的研究,如Ruan等[39]针对搜索路径和匹配过程两个方面进行改进,通过全局约束算法将搜索路径斜率约束至[1/2,2]区间内,再利用失真阈值算法实时地控制待测手势与参考手势匹配的过程。经测试,该方法能显著地减少计算复杂度,提高识别效率。
4.2 支持向量机
支持向量机是一种基于统计学习理论的有监督的学习模型,其基本原理是利用在样本空间或特征空间求出最优超平面,使小同类样本集与超平面之间的距离最大。Huang等[40]提出了一种基于Gabor滤波器和SVM分类器的手势识别方法。该方法通过使用自适应肤色模型以克服光照变化对手部检测的干扰,并采用基于Gabor滤波器的手势角度估计和校正方法实现对手势变化的鲁棒。Dardas等[41]利用SIFT描述符提取图像中的关键点,并使用K-means聚类算法和矢量量化算法将这些关键点映射为直方图向量,将该直方图作为多类SVM的输入向量以构建手势分类器。在可变尺度、方向和光照条件以及复杂背景等情况,该方法都能达到令人满意的实时性能,分类精度达到96.23%。
4.3 人工神经网络
人工神经网络是受生物神经网络启发的一类信息处理模型,它由许多相互连接的并行神经元组成。人工神经网络的模型种类繁多,对于不同的需求可衍生出不同的结构,目前误差反向传播神经网络(BPNN)应用较为广泛。Hasan等[42]提取了手部轮廓和复数矩来表征手势,并使用BPNN对两类特征进行训练,识别正确率分别达到70.83%和86.38%。文献[43]使用量子粒子群算法对BPNN进行优化,很大程度上解决了其收敛速度慢、局部极小化导致网络训练失败等问题,提高了识别效率和稳定性。
Tusor等[44]利用模糊神经网络(Fuzzy Neural Network,FNN)建立了模糊手势模型,并设置了14个取值介于“大”、“中”和“小”的模糊特征值用于描述和区分不同的手势。文献[45]提出一种自成长和自组织神经气(Self-Growing and Self-Organized Neural Gas,SGONG)网络,该网络通过拟合人手形状提取出有效的特征。该特征对手势的尺度和旋转变化不敏感。此外,该网络的收敛速度也比其他网络更快。
4.4 隐马尔可夫模型
隐马尔可夫模型是一种典型的概率统计模型,通常用于描述具有隐藏状态的马尔可夫过程。HMM能有效地捕获时序中的相关性。由于手势动作是一个时间序列,因此HMM在手势识别领域中得到了广泛的应用。使用HMM识别动态手势时,需预先为每个手势训练一个单独HMM模型,然后求解每个HMM模型产生待测手势的概率,概率最大的HMM模型对应的手势就是识别结果。
文献[46]选用字母轨迹的运动角度作为手势的特征向量,并利用左右拓扑结构的HMM对23个预设字母轨迹进行识别,识别准确率达到91.6%。一些研究将HMM与其他分类器相结合,如文献[47]利用AdaBoost分类器检测用户的手部,再使用粒子滤波进行跟踪,最后基于HMM完成手势识别。该方法在识别精度方面有着显著提升,但计算复杂度极大,无法满足实时性的要求。
4.5 深度学习
深度学习是近年来最受学者们关注的研究领域之一,如今已成为大数据和人工智能相结合最成功的典型。深度学习是一种非监督学习,它不仅能自动提取图像中的特征,还能够自动学习更高层次的特征,这克服了人工提取特征的主观性和局限性。根据时间维度处理方式不同,可将基于深度学习的手势识别方法分为卷积神经网络、三维卷积神经网络(3DCNN)和序列模型。
4.5.1CNN
CNN又称为二维卷积神经网络(2DCNN),是深度学习中最基础的网络结构之一,通常由卷积层、池化层和全连接层组成。目前CNN已经在人脸识别、目标检测等领域取得了极大的成功,在手势识别领域也迅速兴起。Neverova等[48]开发了一种手部姿势估计的深度学习模型,该模型关键之处是通过将人手分割成不同的部分来将结构信息编码至训练目标中。Oyedotun和Khashman[49]使用CNN和堆叠去噪自动编码器来识别24种美国手语手势,在公共数据集上取得91.33%的识别率。2DCNN主要提取图像序列中的空间特征,很少涉及到时间维度信息,因此多用于静态手势的分类应用中。
4.5.23DCNN
与2DCNN相比,3DCNN可以保持时间结构的同时,还能有效地捕获时空维度上的判别特征。目前一些3DCNN已经被提出并应用于手势识别中,其中值得关注的是,Molchanov等[50]提出了一种基于深度和强度数据的驾驶员手势识别的3DCNN,该方法为归一化的深度和强度数据分别训练了两个独立的子网络,通过将两个网络输出结果进行融合以实现最终预测。此外,为了避免训练样本集相似度较高而导致的过拟合问题,还采用了时空数据增强技术来改变手势的输入体积。在VIVA数据集测试下,该系统的分类率达到了77.5%。文献[51]设计了一种以多种数据类型为输入的3DCNN,该结构通过对相邻视频帧进行卷积和子采样,以实现颜色信息、深度信息以及人体骨骼信息的融合。
4.5.3序列模型
近几年,一些学者采用将CNN(或3DCNN)与序列模型相结合的方式来识别动态手势,其基本原理是利用序列模型的结构特性来处理时间维度信息。循环神经网络(Recurrent Neural Network,RNN)是最常用的序列模型之一,它能利用隐藏层中的循环结构来处理时间数据。Molchanov等[52]利用循环机制对文献[50]中的3DCNN进行了扩展,提出了一种循环三维卷积神经网络(R3DCNN)。该网络首先利用3DCNN提取视频序列中局部时空特征,然后将这些特征输入到RNN中,最后在Softmax层中预测待测手势概率。
长短期记忆网络(Long Short-Term Memory,LSTM)是一类特殊的RNN,它能解决RNN内存不足的问题,多被用作RNN的隐藏层。为了利用手部骨骼关键点的三维数据序列来解决手势识别问题,文献[53]介绍了一种结合3DCNN和LSTM循环网络的动态手势识别方法。其中,3DCNN主要用于检测与骨骼关节位置相关的空间特征,LSTM循环网络则考虑序列的时间演化。该方法在六种基准数据集上进行了实验,结果表明其在小数据集的性能最佳。
综上所述,目前常用的手势识别方法都有其自身的优缺点,为了便于选择和应用,有必要对其优缺点进行比较和总结。表2对不同的手势识别方法进行了详细的对比。
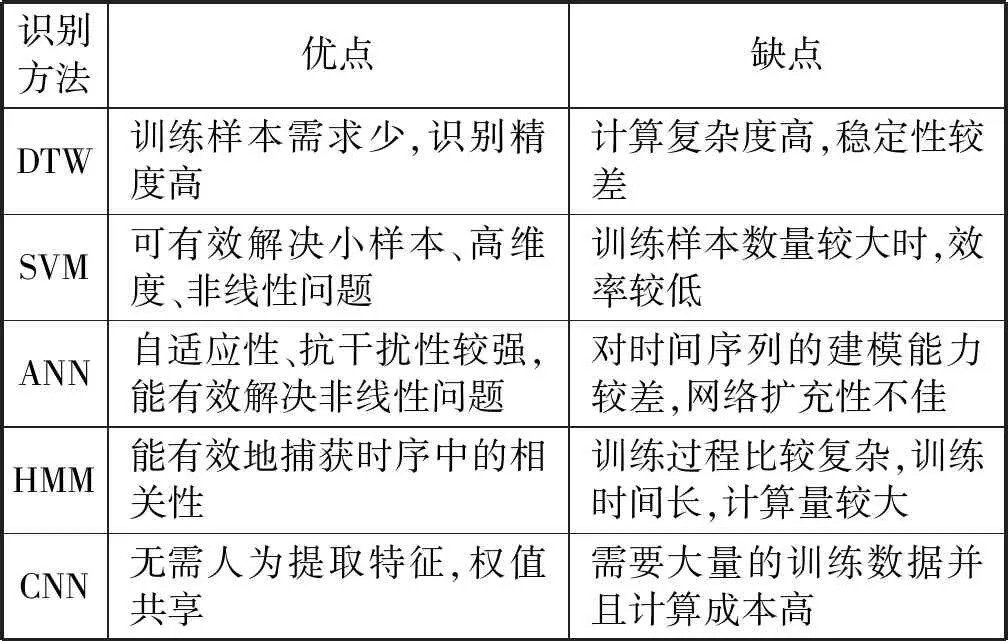
表2 常用的手势识别算法比较
5 结 语
视觉手势识别技术的发展给人机交互带来了一种全新的方式,用户与计算机之间只需徒手便能完成交互功能,这让用户成功摆脱了数据手套和光学标识等外部设备的束缚,从而提高了人机交互的灵活性和自然性。从最初的手语识别应用,到后来体感游戏的创新,手势识别技术正日趋成熟,时至今日手势识别与其他领域也有着密切的结合,主要包括医疗辅助、智能汽车和机器人。
1) 医疗系统。在传统外科手术中,医生使用键盘或触摸屏等设备操控计算机以查阅病例资料,该方式不能保证环境无菌,而手势识别系统则可以帮助医生直接使用手势控制计算机,极大提高了手术安全性和效率。伦敦圣托马斯医院和多伦多森尼布鲁克医院[54-55]是该领域的先驱者,他们已成功将手势识别技术应用于医疗实践中。
2) 车载系统。自2013年谷歌宣布研发利用手势控制汽车的技术至今,手势识别融合车载系统的方案得到了越来越多厂商的关注。2015年,宝马推出了首款搭载着手势控制功能的智能车,它支持通过手势实现接听电话、控制音量和缩放导航地图等功能。此外,奥迪、福特、谷歌等车企也接连展示过同类型的概念车。
3) 机器人控制。对于新兴的社交机器人而言,能够通过理解用户手势来实现人机互动是极其重要的。Fischinger等[56]发布了一款护理机器人Hobbit,为了便于老年人与机器人的日常交互,他新增了一个3D手势界面。深圳优必选科技公司推出的多款智能机器人都支持客户利用自然手势完成资料查阅、音乐播放和日程提醒等功能。
尽管已经取得了这么多令人欣喜的进展,但手势识别研究仍然是一个较为新兴的领域,今后其发展将呈现以下趋势:
1) 智能学习算法的研究。目前,大多数手势识别系统仍需经历模型训练的阶段,这一过程通常需要大量的训练样本,同时耗费大量的时间。智能学习算法旨在让计算机通过“在线学习”的方式对用户执行的手势动作示范进行学习和记忆,而无需额外的训练操作,从而显著地提高识别效率。
2) 多个深度摄像头的融合。不同于普通摄像头,Kinect和Leap motion等新型的深度摄像头能直接获取丰富的手势信息,从而用于精确的手势识别。此前大多数研究者通过单独使用Kinect或Leap motion进行研究,并取得了较好的结果。通过将多个深度摄像头进行融合以设计出具有更高精度与稳定性的识别系统,是该领域中一个值得研究的潜在方向。
3) 现有的大多数手势识别系统无法同时识别多个用户执行的手势。与识别单一用户手势不同,这类问题需要考虑到不同手势特征的提取以及手势模型的构建。此外,由于个人习惯、熟练度和时间的不同,不同用户执行特定的手势也是不同的。因此,开发一种考虑这些个体差异的多用户手势识别技术,是该领域的另一个未来研究方向。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
红领巾·萌芽(2019年9期)2019-10-09
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
福建基础教育研究(2019年6期)2019-05-28
小学阅读指南·低年级版(2017年6期)2017-06-12
数学大世界·小学低年级辅导版(2010年9期)2010-09-08
阅读(中年级)(2009年11期)2009-04-14
