
移动微云任务迁移与调度
2020-03-13 10:55徐红霞孔志周
计算机应用与软件 2020年3期
徐红霞 孔志周
1(济源职业技术学院 河南 济源 459000 )2(湖南大学 湖南 长沙 410082)
0 引 言
目前,移动云计算领域有两种体系结构,一种是远程云[1],即由功能强大的服务器和计算机软硬件集群构成,通过WAN向移动设备提供服务。此时,移动设备通过蜂窝网络或访问点访问云端资源。然而,远程云因为过高的通信延时使得执行实时应用并不会带来较高的响应。另一种是移动微云(Cloudlet,也称朵云)结构[2],由邻近的移动设备以无线方式构成,可以支持实时应用的执行。这种体系结构中,移动设备可以移动Ad hoc网络的形式访问节点的计算资源。
移动微云中,任务迁移[3]即是将移动节点上的任务迁移至目标处理节点上,从而实现任务调度问题的收益最优。任务迁移决策由多个参数影响:信道带宽、计算能力、功率系数以及所有参与节点的排队延时。任务调度的优化目标之一是满足移动系统对于响应时间的需求,尤其对于实时应用,如对象识别[4]、灾难预警[5]、实时视频编码[6]、语音识别[7]等。任务迁移与调度的另一目标是改善移动设备的能效。尽管电池技术发展迅猛,但计算密集型移动应用的执行仍然令移动设备的电量消耗太快,因此,此时移动云中的任务迁移与调度可以通过将计算型任务卸载至能效更高的设备上执行来提高能效。
已提出过多种类型的调度用于任务迁移决策以降低任务的完成时间,并满足服务质量需求,或节省电池能量[8-12]。通常,任务算法可分为集中式和分布式调度方法。集中式调度方法中,调度决策基于所有参与节点的已有信息,在中心控制器中制定,这种方法容易遭受单点失效和移动节点不合理部署的影响。分布式调度算法中,每个节点自主作出调度决策,可以使得移动微云具有更好的可扩展性和灵活性。
此外,多数先前的工作仅仅局限于单个移动设备下的任务处理场景,而在移动云系统中,可能存在有多个源设备和多个处理节点的场景。文献[13]提出了一种移动系统中的分布式动态调度算法,算法将包括迁移需求的任务信息发送至邻居节点,邻居节点对其消息进行响应并执行任务。而在多个不同源节点生成多个请求时,算法仅仅依据最短的任务响应时间选择任务的处理节点,导致部分节点负载过重。然而,文献在如何获取实时的资源信息上并未给出具体方案。在移动云场景中,邻近资源信息的发现方式有两种:主动式和被动式。文献[14]以一种被动式方式请求其他节点资源信息,虽然资源发现开销较短,但其响应时间过长,无法满足实时任务的需求。主动式资源发现周期性收集不同节点的资源状态,基于当前资源信息更快的作出调度决策,对于时间约束型任务更加有利,便相对的资源开销较大。文献[15]设计一种主动式邻近异构资源的资源发现路由策略,该策略添加了CPU类型、占用率、内存以及能量等级等参数至控制信息中,以周期性的广播使得所有节点能够获取相互的资源信息。但是,控制信息的收发频率在文中并没有得到研究,使得任务调度与迁移的决策过程中没有考虑资源发现的过大开销,而这对于最终的任务调度结果是至关重要的。
总结目前的主要研究内容,当前在移动云中已有的分布式调度决策方法依然具有一些限制:1)多数调度问题受限于单源移动设备下的任务调度;2)在处理节点上的任务队列长度和功率系数等参数下作出了过多不合理的假设,使得节点的资源信息一直可知。
为了解决以上问题,本文提出一种分布式自适应概率调度算法,可将来自于多源节点上的任务调度至微云中的邻近处理节点,在满足任务时间期限的同时,维持较低的能量消耗。算法首先估算任务在每个参与处理节点上的完成时间和能耗;然后,调度当前任务至以概率计算方式得到的能效最高的节点上执行;同时,在不可预测的网络条件下自适应调整时间余量参数,尽可能实现更高的任务完成率。
1 系统模型
1.1 网络模型
令V表示移动微云中所有无线节点集合,E表示移动微云中所有无线链路集合,G(V,E)表示由于节点集V和边集E组成的无向拓扑图,P表示移动微云中所有处理节点集,P为V的子集,S表示移动微云中所有源节点集,也为V的子集,J表示到达V的任务集。
定义1一个微云由若干无线节点以无向通信图G(V,E)的形式构成。给定节点u∈V和v∈V,当且仅当dis(u,v)≤rt(dis(u,v)为节点u与v间的欧氏距离)时,则有edge(u,v)∈E。即:若两个节点间建立一条直接通信链路,则两个节点间的距离需在其广播通信范围rt内。
处理节点u的计算能力表示为mipsu(每秒百万指令数),本文假设CPU执行单个指令的能耗eu与其速率的平方成正比,即:
(1)
对于每个节点u,tq,u表示排队延时,即任务置入队列尾部直到任务被处理的等待时间。节点按其计算能力划分为两类:第一类为仅能处理自身任务的弱功能源节点,另一类为可处理其他节点任务的强功能处理节点。
假设J中的任务为计算密集型,且相互独立,可执行于任一微云中的节点。一旦任务到达,即可调度至处理节点上执行。任务完成后,其结果集中返回至任务发送源节点。从源节点传输至目标节点的数据量Dj(字节)与从目标节点返回的数据量是相同的。同时,假设所有节点的传输功率et、接收功率er和传输范围rt是相同的,最大传输带宽Bmax在邻接节点间共享。微云中的节点随机分布,任意两个节点间或直接相连,或以Ad hoc方式连接。
1.2 任务模型
对于节点j∈J(源节点的任务队列中的任务),具有以下属性:
1)Dj:在源节点与处理节点间传输的数据量;
2)Cj:处理的计算量;
3)Tj:任务j的时间约束。
任务j的所有属性在任务j到达队列时对于源节点是可知的。与相关文献中模型不同的是,本文在任务调度与迁移上加入了截止时间的约束,对于不满足截止时间约束的调度方案均视为不可行方案。因此,在调度算法设计过程中,必须将资源发现开销考虑进来,对于响应时间过长和开销过大的资源发现方式,势必会导致最终的任务调度时间超过截止时间约束,进而导致任务失效。
1.3 问题描述
在网络和任务模型下,可以计算任务执行的能耗和完成时间。执行任务的能耗包括两个部分:
1) 计算能耗:表示处理节点u执行任务带来的能耗,定义为:
ComputationEneryj=eu×Cj
(2)
2) 通信能耗:表示任务从源节点迁移至目标节点处理时的能耗。通信能耗正比于数据传输量,令H(j)表示源节点至处理节点间的跳数,则:
CommunicationEneryj=H(j)×(et+er)×Dj
(3)
则任务j的执行总能耗为:
TaskEnergyj=ComputationEneryj+CommunicationEneryj
(4)
所有n个任务总能耗为:
(5)
任务的完成时间由三个部分组成:
1)tq,u:处理节点u的排队时间,即任务执行前的等待时间;
2)texecution:任务在处理节点上的执行时间:
(6)
3)ttransmition:源节点与处理节点间的数据传输时间:
(7)
当任务被迁移至节点u时任务j的完成时间即为三个部分之和:
TaskCompletionTimej=tq,u+texecution+ttransmition
(8)
若任务在其时间期限内完成,即满足式(9),也即认为任务成功调度;否则,任务调度失败。
TaskCompletionTimej≤Tj
(9)
令n为任务总量,定义两个指标评估任务调度结果,一个是任务完成率,一个是成功调度任务的平均能耗,分别定义为:
(10)
(11)
本文的最优化问题可定义为:给定由源节点集S和待调度任务集J构成的微云系统G(V,E),将任务从一个或多个源节点上调度至处理节点上,并实现能效的最优化,即:
minAverageEnergyPerSucessfulTask
约束条件为:
Bu,v≤Bmax∀e=(u,v)∈E
(12)
(13)
P⊆V,S⊆V,P∩S=∅,P∪S=V
(14)
式(12)确保节点间的通信不能超过最大带宽;式(13)确保仅能被调度一次;式(14)表明微云中的节点或为源节点,或为处理节点。
2 自适应概率调度算法设计
为了求解以上的任务调度问题,本文设计一种分布式的自适应概率调度算法,算法由两个阶段组成:资源发现阶段和自适应概率调度阶段。资源发现阶段中,源节点周期性地收集邻居处理节点的资源信息;自适应概率调度阶段中,在每个源节点上,一旦任务j到达,调度器即选择一个处理节点执行任务j,并满足时间约束以及能耗最优的需求。
2.1 资源发现阶段
阶段一基于QoS OLSR[16]设计资源发现策略,利用两类控制信息以获得资源信息:
1) 修改的Hello Message:该消息在局部(即广播至一跳邻居节点)发送以使得节点发现其局部邻居(类似于OLSR协议中的HELLO消息);
2) 修改的拓扑控制Topology Control(TC)消息:通过多跳中继节点(Multipoint Relay,MPR)发送至整个网络,以使得拓扑分布和资源信息可以给所有节点间共享。
两种消息类型周期性发送。消息发送间隔是一个变量,与网络状态变化快慢相关。网络状态变化越快,消息发送间隔相应越短。相关研究表明,初始的Hello消息和TC消息发送间隔为2 s和5 s。
本文通过在控制消息中向每个邻居ID添加以下参数(扩充4个字节)对路由表进行了扩展:
1) 设备参数:包括节点u的处理速度mipsu和功率系数eu;
2) 队列长度:节点u当前的排队时间tq,u。
从MPR节点发送的修改TC消息将携带其邻居节点ID和其资源信息。一旦接收到修改的控制消息,每个源节点将更新其邻居列表,该列表记录了所有参与处理节点的资源信息。分布式资源发现过程如算法1所示。
算法1Resource Discovery Algorithm
输入:Initial neighbor table of nodeu
输出:Neighbor table of nodeu
功能:操作控制信息并更新节点u的邻居列表
1. listen control message
//节点监听网络中的控制信息
2. if(nodeureceives a control message from nodev) then
3. if(Message Type==HELLO_MESSAGE) then
4. updatau’s neighbor table by adding/updating nodevand its parameters
//更新邻居列表
5. if(nodeuis an MPR node) then
6. construct/update TC message
//构造/更新TC消息
7. else if(Message Type==TC_MESSAGE) then
8. updateu’s neighbor table by adding/updating the nodes and their parameters in the TC message
//更新TC消息中节点的邻居列表
9. if(nodeuis an MPR node) then
10.forward the TC message to all of its neighbors
//将TC消息中继发送至其所有邻居节点
11. returnu’s neighbor table
//返回邻居列表
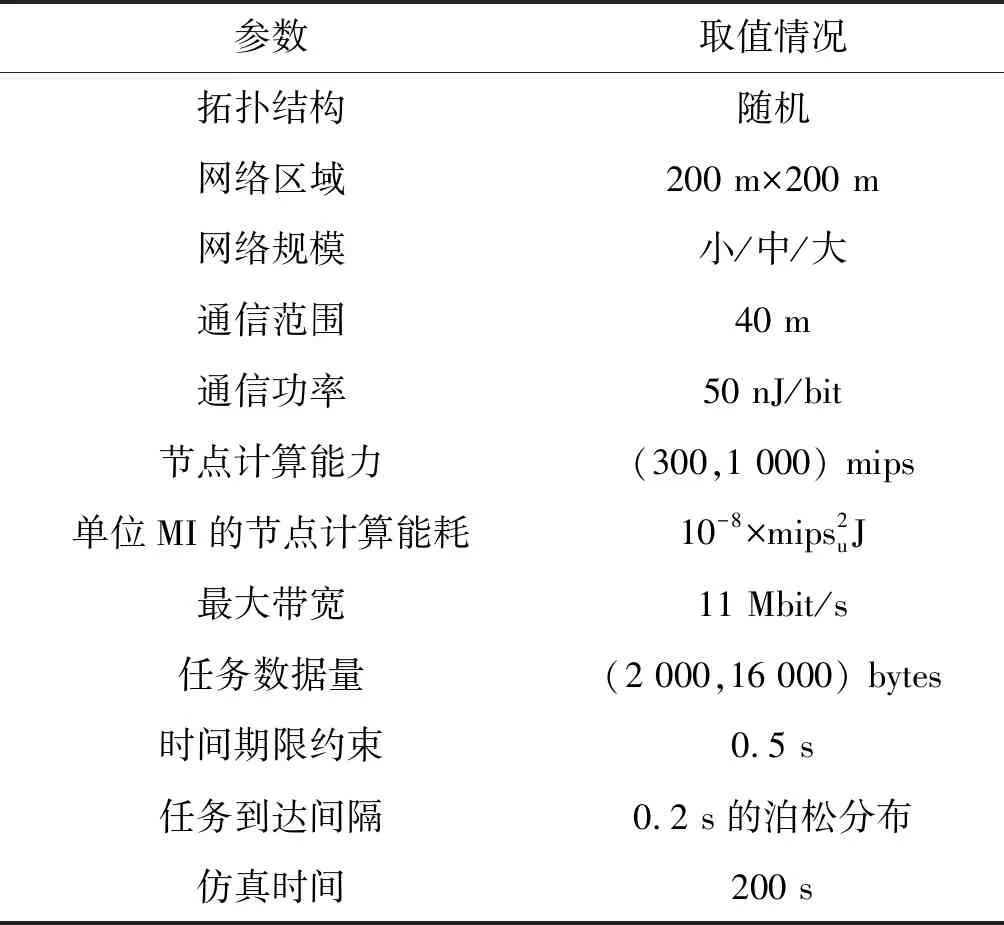
考虑到应用任务较紧的时间期限,修改的Hello消息和修改的TC消息需进一步缩短。QoS OLSR协议的控制信息在本文算法实现过程中添加了额外比特。原始QoS OLSR中,默认的Hello消息间隔为2 s,TC消息间隔为5 s。修改的QoS OSLR中,Hello消息间隔为TC消息间隔的一半,这可以确保MPR节点将带有邻居信息的TC消息发送至整个网络。后面的实验中也将研究消息发送间隔对算法调度性能的影响。
2.2 自适应概率调度阶段
一个源节点u每次接收一个局部用户任务j时,会估算任务在每个潜在处理节点v∈P上的能耗TaskEnergyj,v和完成时间TaskCompletionTimej,v。这两个变量分别通过式(4)和式(8)求得。
调度器维持一个满足式(15)的处理节点集合P′,并从该集合中随机选择一个处理节点。节点v∈P′被选择为处理节点的概率为ρv。
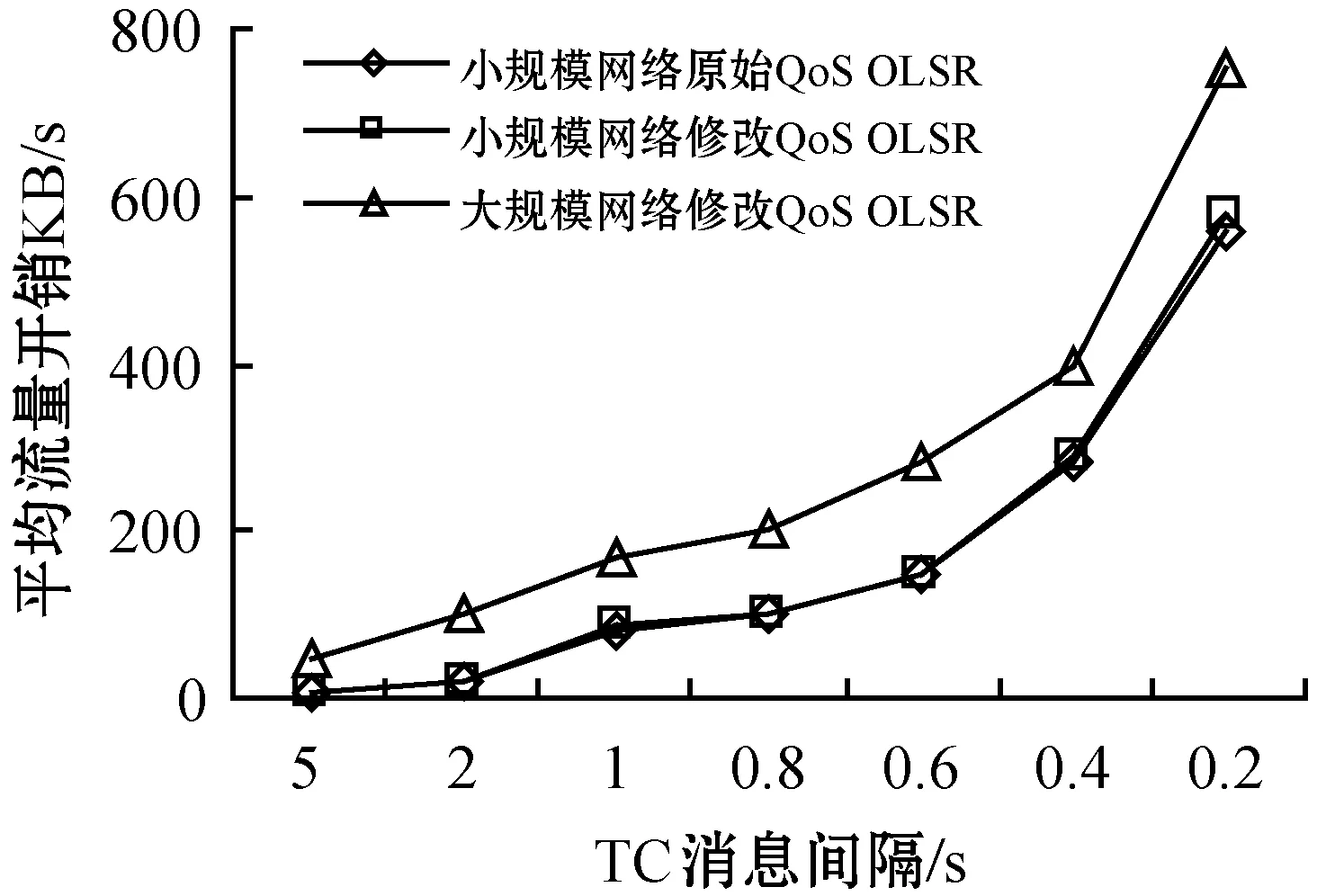
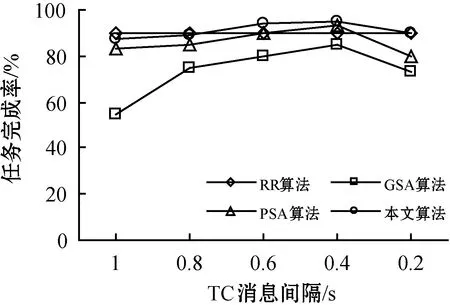
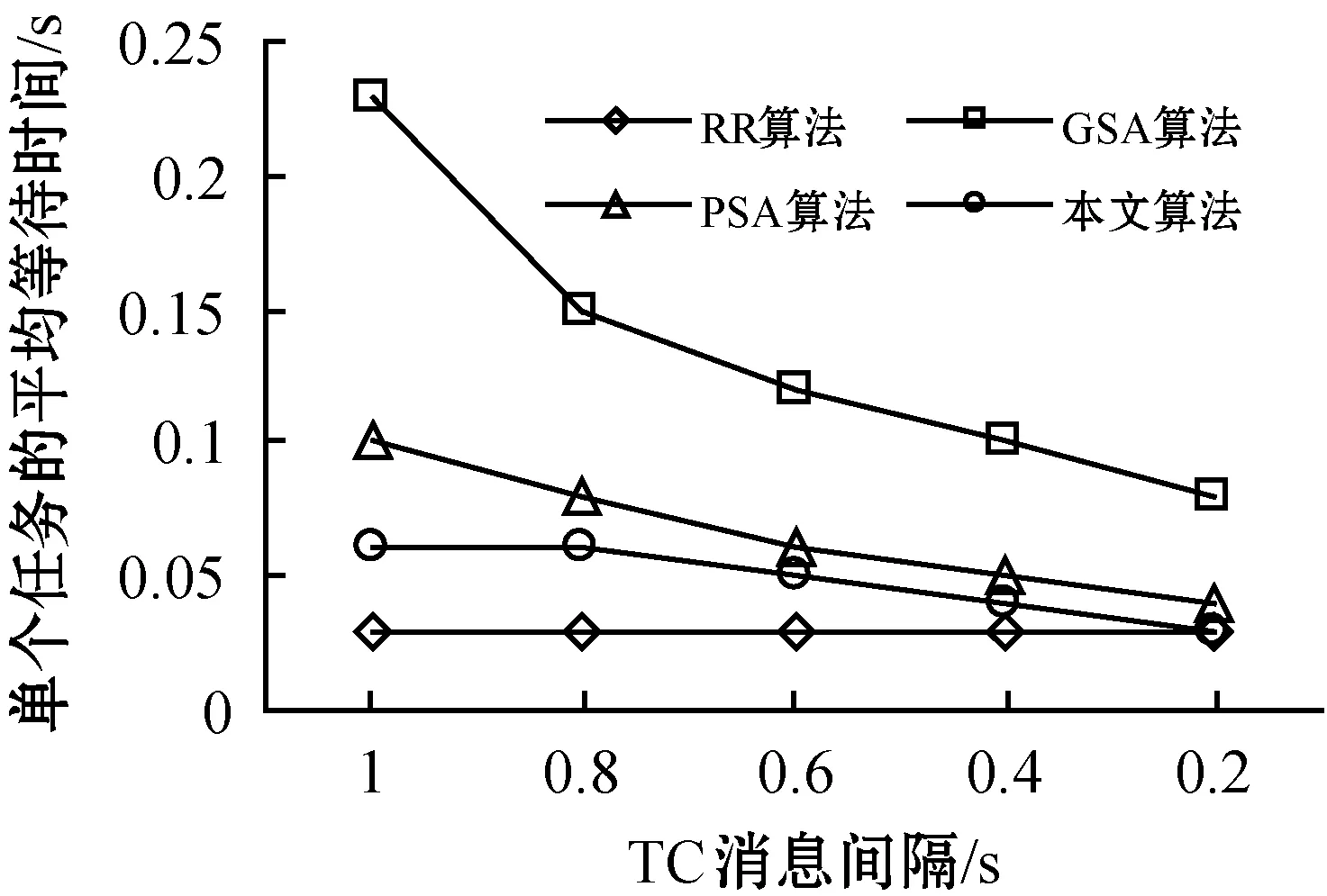
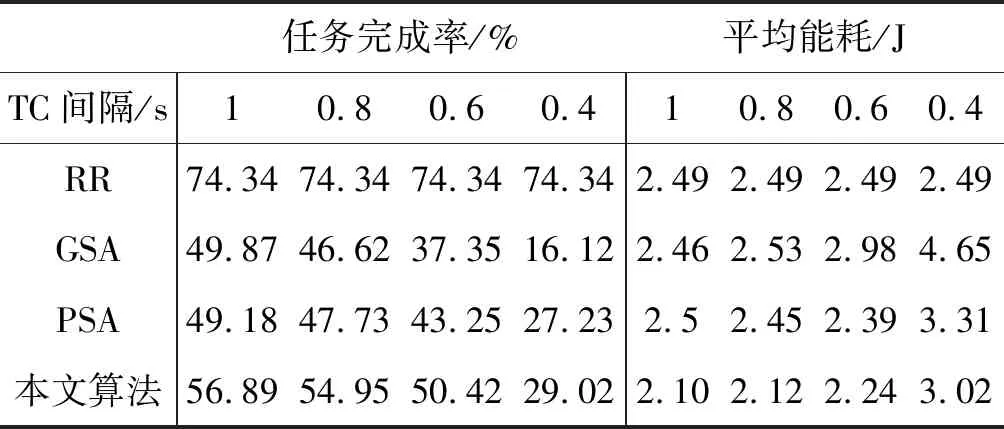
TaskCompletionTimej,v (15) (16) 在动态的无线网络环境中,无法确保任务能够在时间期限内完成。理由在于:1) 可能多个源节点同时将任务调度至同一个处理节点。由于在处理节点上的排队延时,实际的执行时间将大于估计的完成时间,导致无法满足时间期限约束;2) 通信带宽在多个数据传输间共享,使得无法给出精确的传输时间。 若无法满足时间期限,调度器将增加tmargin值以避免连续的任务调度失效。若连续a1个任务调度失效,时间余量增加△t1。在接收a2个连续成功调度的任务后,调度器将减少时间余量△t2。仿真实验中将a1和a2初始化为2,这表明若出现2个连续失效任务,调度器将以能耗增加为代价选择计算能力更强的处理节点,从而实现成功的任务调度(满足时间期限约束),反之亦然。仿真实验中△t1和△t2初始为0.05 s,且与任务的时间期限相关。对于越长的时间期限,△t1和△t2也相应越长。以上所有四个参数可以反映出自适应度概率调度算法在出现任务失效时的适应性,并作出相应优化。例如:若调度器以确保任务完成率为目标,算法将选择较小的a1和较大的△t1。算法2是自适应概率调度过程,并假设每个到达的任务将被置入开始时间t_start的队列J。 算法2Adative Probability Scheduling Algorithm 输入:neighbor table of node u from algorithm 1 and task queueJ 输出:tasks scheduling results 功能:微云中任务与处理节点间的映射关系 1. set the number of consecutive successful tasksns=0 //设置连续成功调度任务的数量 2. set the number of consecutive failed tasksnf=0 //设置连续失效任务的数量 3.tmargin=0 //初始化时间余量 4. while (J≠∅) do //队列不为空则从队列中提取一个任务 5. extract taskjfromJ 6.P′← ∅ //将处理节点集初始化为空 7.Pis initialized as all the processing nodes in the neighbor table //将P初始化为邻居列表中所有处理节点 //步骤1:寻找合格的处理节点 8. for eachv∈P 9. estimatedtaskcompletiontimej,v=tq,v+texecution+ttransmition 10. TaskEnergyj,v=ComputationEnergyj,v+CommunicationEnergyj,v 11. if (Estimatedtaskcompletiontimej,v 12.P′=P′∪v //满足式(15)则更新处理节点集 //步骤2:计算合格的处理节点选择为处理节点的概率 13.for eachv∈P′ 14. computingρvusing Equ.(16) //计算处理节点选择概率 15.randomly select processing nodew∈P′ based on probabiligyρw //基于概率选择处理节点 //步骤3:将任务j调度至处理节点w,并更新节点w的估 //算队列时间 16. send taskjtow //将任务j发送至处理节点w 17.tq,w=tq,w+Cj/mipsw //更新邻居列表中的tq,w //步骤4:接收处理节点w中任务j的结果,并记录当前时 //间t_completej 18. if (receive taskj’s result) then 19.taskcompletiontimej=t_complete-t_startj 20. if (taskcompletiontimej≤Tj) then 21.ns++ 22.nf=0 23. else 24.nf++ 25.ns=0 //步骤5:自适应调整时间余量tmargin 26. if (nf>a1) then 27.tmargin=tmargin+△t1 28.nf=0 29. if (ns>a2) then 30.tmargin=tmargin-△t2 31.ns=0 32. else goto line 4 自适应概率调度方法基于节点作为处理节点概率的方式选择处理节点,并且以为节点带来的能耗来计算概率,进而以自适应的方式调整其时间余量参数,在不可预知的网络条件下改善任务调度性能。这种自适应的概率计算方式所选的处理节点不仅可以维持较高的任务调度成功率,还可以降低任务的平均执行能耗。 选择三种算法与本文算法进行了比较,包括轮转调度算法RR、贪婪调度算法GSA以及概率调度算法PSA。RR算法以轮循环方式进行任务调度,第一个任务到达后,调度至P的第一个节点,第二任务到达即调度至P的第二个节点,依此类推。GSA算法总是将任务调度至所估计的完成时间在时间期限内的能效最高的节点上。PSA算法维持一个满足TaskCompletionTimej,v 利用图3所示的节点结构组成的微云说明不同调度算法的结果,表2是相关参数配置。算例由一个语音识别应用生成。图中有两个源节点s0和s1,四个处理节点n0、n1、n2和n3。一个任务的数据量为4 000字节,信道带宽为11 Mbit/s。 图1 移动微云结构 表1 参数配置说明 参数取值情况任务到达间隔0.5 s任务数据量4 000 bytes任务计算量200 MI任务时间期限1 seno/en1/en2/en30.25/0.16/0.09/0.04 J/MImipsno/mipsn1/mipsn2/mipsn3500/400/300/200 MI/s 开始时间t=0 s,两个源节点s0和s1开始接收任务。每0.5 s每个源节点接收一个任务。对于本文提出的自适应概率调度算法,tmargin初始化为0。若一个任务未被成功调度,则tmargin增加0.5 s;否则,tmargin减小0.5 s。由于通信能耗比计算能耗相对较小,算例分析通信能耗。根据式(5),在处理节点n0、n1、n2和n3上执行任务的能耗分别为50 J、32 J、18 J和8 J。 图2是四种调度算法得到的调度结果。粗线代表s0的任务,细线代表s1的任务。实线代表执行时间,虚线代表在处理节点上的等待时间。每条线的长度即为任务的完成时间。若线的长度大于1 s,则任务执行失效。算例统计了算法得到每个任务的完成时间和能耗。利用轮转算法RR和贪婪算法GSA,两个源节点总是将任务调度到相同处理节点上。RR算法将任务调度至计算能力更强的节点(n0,n1)上,导致了很高的任务完成率和能耗。GSA算法总是将任务调度至能效最高的节点以满足时间约束。因此,可能出现长时间的队列等待,这也导致了GSA算法总是拥有最低的任务完成率。利用概率调度算法PSA,基于式(16)可将两个源节点的任务调度至不同的处理节点上,比较GSA算法,在分配给每个处理节点的任务数量上,PSA算法仅有一个任务调度至n1,而不在n3上。然而,使用概率调度方法的确改进了很大的性能。本文的自适应概率调度算法当出现第一个失效任务时在t=1.5 s时将增加tmargin。对于s1,n2不再满足式(15)的时间约束。因此,在t=1.5 s时,s1将任务调度至n1。这样使得自适应概率调度算法成功地避免了一次任务失效,且其每个成功调度任务的平均能耗也得到了改进。 具体地,对于RR算法,任务完成率为75%,能耗为36 J/task;对于GSA算法,任务完成率为37.5%,能耗为34.6 J/task;对于PSA算法,任务完成率为62.5%,能耗为25.6 J/task;对于本文算法,任务完成率为75%,能耗为23.6 J/task。 (a) RR算法调度结果 (b) GSA算法调度结果 (c) PSA算法调度结果 为了评估算法性能,在OMNET++[17]仿真平台下搭建一个移动微云任务调度系统,由若干节点构成,其拓扑结构随机生成,每个节点的传输信号范围为40米,且具有11 Mbit/s 802.11g的无线信道传播能力。部署三种具有不同节点密度的网络场景进行仿真。场景1为小规模网络,随机在200 m×200 m的区域中部署10个节点,其中2个为源节点,8个处理节点。场景2为中规模网络,随机在200 m×200 m的区域中部署20个节点,其中4个为源节点,16个处理节点。场景3为大规模网络,随机在200 m×200 m的区域中部署40个节点,其中8个为源节点,32个处理节点。任务到达时间服从泊松分布。任务总的数据量处于[2 000,16 000] bytes之间,其他实验参数如表2所示。 表2 仿真实验参数配置说明 在构建移动微云任务调度系统时,关于节点的移动模型,OMNET++支持两种形式的节点移动。第一种是固定网络形式,其所有节点是固定的。第二种是移动网络形态,其每个移动节点根据以下模式在指定区域内可以移动。其移动周期为一个随机数,服从均值为5 s和标准差为0.1 s的均匀分布。当节点移动出现转弯时,其移动的新方向同样服从与之前移动相同的均匀分布。移动节点的运行速率服从[1 m/s,3 m/s]间的均匀分布。所有节点可按照随机方向在区域内以均匀分布的速率进行移动。同时,所有节点拥有相同的初始能量等级,仅当节点在处理任务或节点处于发送/接收消息状态时才开始消耗能量,计算能耗可用式(2)-式(4)进行计算。对于移动微云系统,显然需要采用第二种移动网络形态。此外,由于OMNET++中已有对于最优状态链路路由协议OLSR协议的扩展,本文仅需要对现有的OLSR内核进行扩展,进而实现资源发现路由过程即可。具体实现过程中,为了减少移动节点间的信息转发数量,资源发现协议中的链路状态状态都由MRP节点产生,以便控制移动网络中的洪泛信息传播。 选取以下性能指标评估算性能: 1) 任务完成率:即式(10); 2) 任务平均等待时间:即任务在处理节点上的等待与开始执行的平均间隔时间; 3) 单个成功任务的平均能耗:即式(11)。 如前所述,QoS OLSR协议的控制信息在本文算法实现过程中添加了额外比特。原始QoS OLSR中,默认的Hello消息间隔为2 s,TC消息间隔为5 s。修改的QoS OSLR中,Hello消息间隔为TC消息间隔的一半,这可以确保MPR节点将带有邻居信息的TC消息发送至整个网络。为了测量此时的开销,实验测量了小、大规模网络中控制消息的比特数,包括HELLO消息和TC消息。平均流量开销定义为在整个网络中每秒传输控制消息的比特数,该指标可以显示整个网络带宽被控制消息消耗的程度,图3是实验结果。可以看到,平均流量开销几乎随着TC消息发送的频率呈指数级增加。当TC消息间隔为0.2 s时,流量开销在小、大规模网络中约为600 KB/s和750 KB/s。在小规模网络中,修改的QoS OLSR的流量只有轻微的增加,比原始QoS OLSR约增加2%。这是由于仅有4比特数据添加至每个Hello消息中,尤其在小规模网络场景中,TC消息的邻居列表的增加也是相当有限的。 图3 控制信息的平均流量开销 进一步观察不同算法在不同TC消息间隔下的性能。如前所述,RR算法的TC间隔为2 s。图4显示,除了RR算法,其他三种算法的任务完成率首先会随着TC消息间隔变短而增加,而在TC消息间隔达到0.2 s前则出现下降。这是由于在较长的TC消息间隔下,没有足够的控制消息携带资源信息,算法将无法获取邻居节点信息。当控制消息发送变频繁时,在源节点上的资源信息将被更加频繁地更新,进而使得任务完成率增加。然而,当流量开销占据大部分网络带宽时(0.2 s的TC间隔),算法将无法预测准确的传输时间。 图4 任务完成率 RR算法并不依赖于实时的资源信息,该算法依次将任务发送至邻居节点,因此其任务完成率是相同的。本文算法在所有情况下均具有最高的任务完成率,分别高于GSA算法和PSA算法16.6%和3.6%。因为增加tmargin,可使算法在出现任务失效时发送任务至计算能力更强的节点上,将更加可能在时间约束内完成任务。 进一步的结果如图5所示,该图给出了任务在处理节点上的平均等待时间。GSA算法是最高的,因为此时两个源节点总是将任务迁移到能效最高的节点上执行。PSA算法和本文算法通过选择处理节点降低了多个任务在同一处理节点上的等待情况。若发生任务等待,本文算法也将选择平均等待时间更低的节点执行任务,此时约比GSA算法节省了2~4倍的时间。RR算法拥有最短的等待时间,因为它仅将任务均匀地发送至邻近节点执行。同时,图5还表明了TC消息间隔对性能的影响。对于越短的TC消息间隔,将越能准确地获取资源信息,因此所选择的执行节点越能得到更短的等待时间。 图5 任务的平均等待时间 图6显示的是单个成功任务的平均能耗。除了RR算法,其他三种算法的平均能耗均是先随着TC消息间隔的增加而增加,在TC消息间隔达到0.2 s前下降。可以看到,本文算法的平均能耗是最少的。当TC消息间隔为0.4 s时,本文算法拥有最高的任务完成率:95.14%,以及最少的能耗:1.6 J。 图6 平均能耗 表3是大规模网络场景下的仿真结果。可以看到,所有算法此时得到的任务完成率小于小规模网络场景。理由在于:此时需要花更多时间在源节点与处理节点间进行数据传输,即:1) 多跳延时,每个中继节点需要接收全部消息并重传至下一跳节点;2) 信道访问延时,更多的节点在同一时间发送数据从而导致拥塞。在较短的TC消息间隔下,流量开销更大,这也进一步影响传输时间。因此,任务完成率将随着TC消息间隔变短而降低。 表3 大规模网络场景下的实验结果 基于移动微云环境,本文提出了一种基于自适应概率的任务调度算法。算法通过资源发现和自适应概率调度两个阶段寻找能效最高的任务调度解,资源发现阶段通过修改原始的QoS OLSR协议中的控制信息,以发现和更新近邻资源信息;自适应调度阶段则通过概率计算方式将当前任务调度至合适的处理节点上。算法可以通过调整时间余量参数在未知的网络条件下改进任务调度性能。仿真实验结果表明,自适应概率调度算法在维持更高的任务完成率的情况下,可以降低单个任务成功执行时的平均能耗。2.3 算例说明
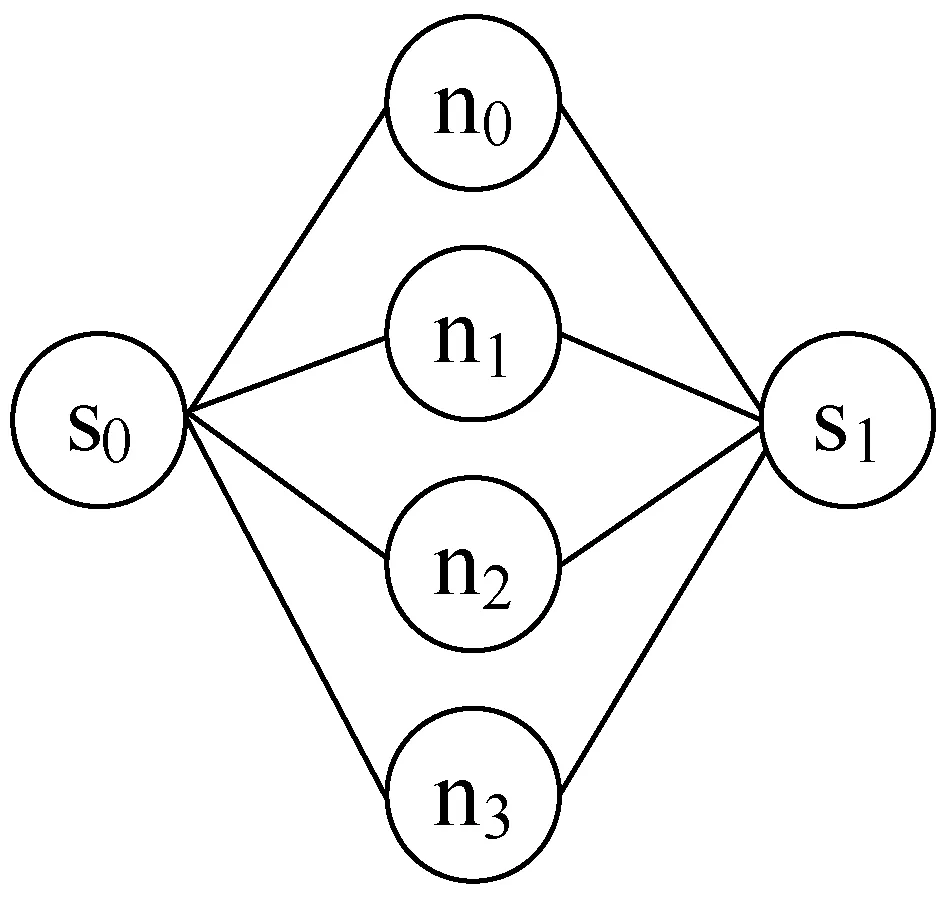

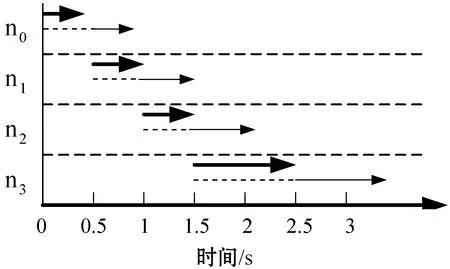
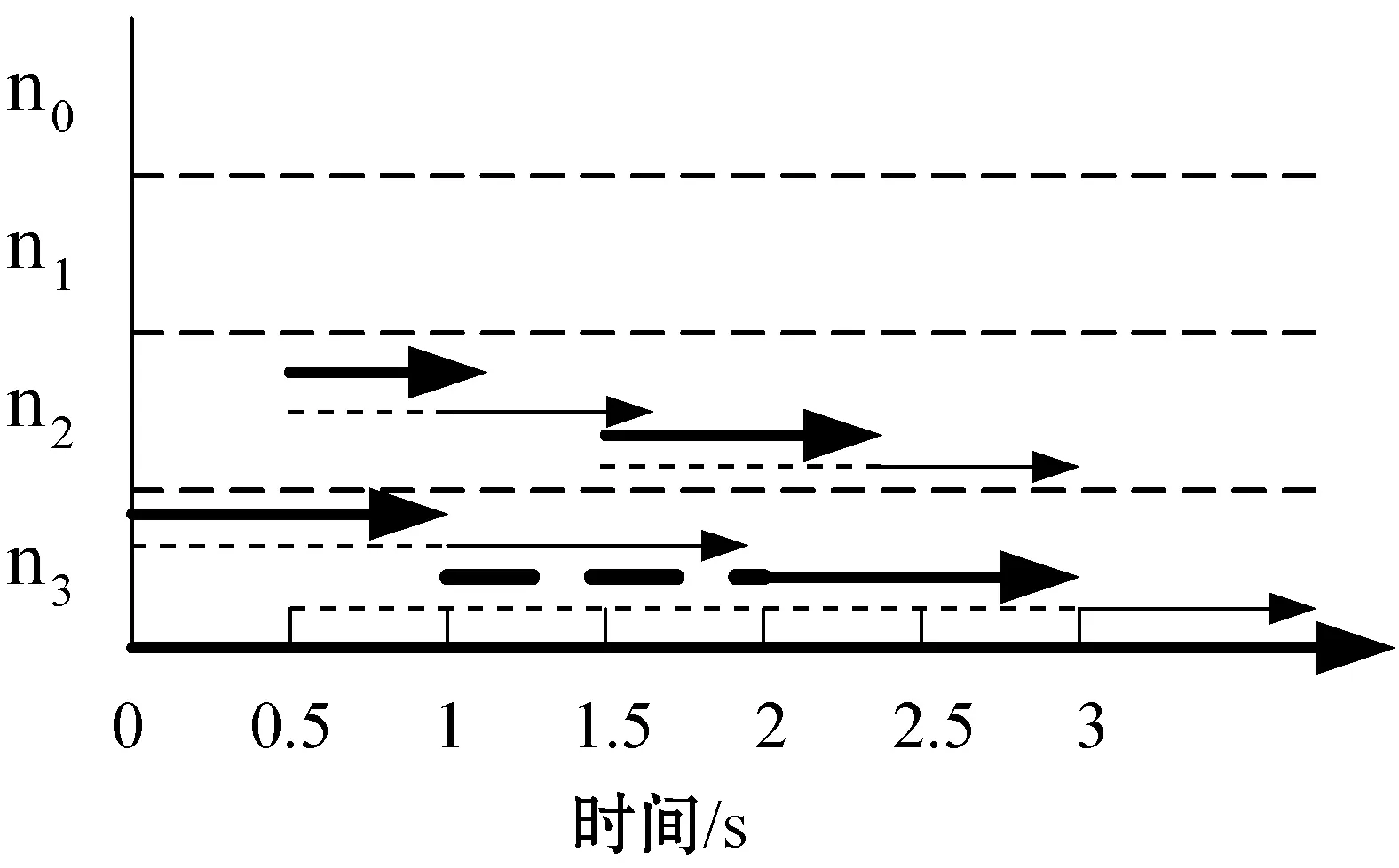
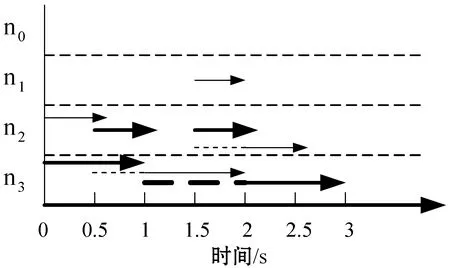
3 仿真实验
3.1 环境搭建
3.2 仿真结果

4 结 语
猜你喜欢
吉林大学学报(信息科学版)(2022年2期)2022-08-15昆钢科技(2022年2期)2022-07-08计算机测量与控制(2022年2期)2022-03-30建材发展导向(2021年23期)2021-03-08智能计算机与应用(2020年2期)2020-04-29电脑爱好者(2019年7期)2019-10-30知识就是力量(2019年7期)2019-07-01华人时刊(2018年15期)2018-11-10电脑爱好者(2017年10期)2017-06-01电脑爱好者(2015年8期)2015-04-24
