
基于条件植被温度指数的夏玉米生长季干旱预测研究
2020-03-11 04:00:20许连香王鹏新
农业机械学报 2020年1期
李 俐 许连香 王鹏新 齐 璇 王 蕾
(1.中国农业大学土地科学与技术学院, 北京 100083; 2.农业农村部农业灾害遥感重点实验室, 北京 100083;3.中国农业大学信息与电气工程学院, 北京 100083)
0 引言
干旱是对农业生产影响较大的自然灾害,其波及范围广、持续时间长、危害性大[1]。及时准确地进行干旱预测对提前采取防灾措施以减小因旱灾造成的经济损失、保证粮食安全具有重要意义[2]。
干旱指数是衡量干旱程度的重要指标,研究人员提出了许多干旱指数来监测和预测干旱程度[3-4]。传统干旱指数如帕尔默干旱严重程度指数(Palmer drought severity index, PDSI)、标准化降水指数(Standardized precipitation index,SPI)等[5],通常利用气象站或水文站等观测数据,虽然数据较为准确,但其精度受限于区域内站点的位置和分布密度,大范围的旱情监测评估应用中,其代表性有待提高[6]。遥感技术的快速发展使得实时、动态的区域性旱情监测成为可能。常用的遥感干旱监测指数包括植被指数(Vegetation index,VI)、地表温度(Land surface temperature,LST),以及在此基础上开发的条件植被指数(Vegetation condition index,VCI)和条件温度指数(Temperature condition index,TCI)等[7-8]。有研究表明,植被指数对降水或土壤水分亏缺具有延迟响应[9],而地表温度虽然对初始水分胁迫具有更大的敏感性[10],但时空变化受大气、环境状况影响较大,仅利用植被指数或者地表温度进行干旱监测并不理想。故许多学者尝试将植被指数和地表温度结合,利用两者互补特性提供的作物水分亏缺信息来监测旱情[11]。王鹏新等[12]在归一化植被指数和地表温度的散点图呈三角形分布的条件下,提出了条件植被温度指数(Vegetation temperature condition index,VTCI)的干旱监测指数,弥补了单一遥感指数的不足,并且成功实现了陕西省关中地区冬小麦生长季的干旱监测和预测[13]。
常用的预测方法有灰色预测模型、神经网络模型[14]、加权马尔可夫模型和求和自回归移动平均(Autoregressive integrated moving average,ARIMA)模型等。其中,ARIMA模型作为时间序列分析的主流方法,在很多领域中得到广泛应用[15]。艾欣等[16]利用ARIMA模型对电价时间序列进行分析,表明ARIMA模型可提高实时市场的电价预测准确性;窦慧丽等[17]应用ARIMA模型,以较高精度实现了小波消噪后交通流的实时动态预测。在农业干旱预测方面,田苗等[18]基于VTCI干旱监测结果,利用季节性求和自回归移动平均(Seasonal autoregressive integrated moving average,SARIMA)模型,实现了冬小麦生长季的短期干旱预测。有研究表明,农业旱情的发生和发展除受降水、温度等影响外,还与农作物自身生理机能有关[19]。在不同区域、不同作物生育期内,作物对水分胁迫的抵抗力不同,其反映的干旱特征也存在差异[20]。本文以河北中部平原为研究区域,基于遥感反演获取的VTCI时间序列数据,利用ARIMA模型及季节性ARIMA模型,分别逐像素对该地区的VTCI时间序列进行分析建模预测,分析对比两种模型的预测精度,以获得适合河北中部平原旱情预测的模型;同时,在灌溉类型种植区,验证基于条件植被温度指数(VTCI)的夏玉米生长季对农业旱情预测的有效性。
1 材料与方法
1.1 研究区概况
选取位于河北中部平原保定市、石家庄市、廊坊市的部分地区以及沧州市和衡水市为研究区(图1),其覆盖范围介于114°32′~117°36′E,36°57′~39°50′N之间,面积约为5.3×104km2。该地区属暖温带大陆性季风气候,年平均气温10℃以上,主要耕作制度为冬小麦-夏玉米轮作,是我国重要的玉米生产基地[21]。然而,夏玉米生育期内气温高且蒸散量大,降水时空分布不均以及水资源的总体不足使得该地区夏玉米生育期内干旱时有发生[22]。灌浆成熟期是夏玉米产量形成的主要阶段,需要充足的水分作为溶媒把茎叶中的营养物质运输到籽粒中,此时土壤水分状况较生育前期更具有重要的生理意义[23]。本文重点研究预测该期间(9月)的干旱时空分布情况,以期为当地农业的防灾减灾提供科学指导和依据。

图1 研究区域位置及气象站点分布图Fig.1 Location map of study area and weather stations
1.2 数据获取与处理
条件植被温度指数(VTCI)计算式[24-25]为
(1)
其中
Lmax(Ni)=a+bNi
(2)
(3)
式中Ni——第i个像素的归一化植被指数
L(Ni)——在研究区域内,某一像素的NDVI值为Ni时的地表温度
Lmax(Ni)、Lmin(Ni)——当NDVI值为某一特定值Ni时研究区内所有像素的地表温度的最大值和最小值,称作热边界和冷边界
a、b、a′、b′——待定系数,由研究区域的NDVI和LST的散点图近似得到
选取河北省中部平原2010—2018年夏玉米生长季的Aqua-MODIS数据,主要包括时间分辨率均为1 d、空间分辨率均为1 km的地表温度产品MYD11A1与地表反射率产品MYD09GA。在进行镶嵌、重采样、投影转换以及裁剪等预处理的基础上,将这两类MODIS数据产品批量处理反演得到研究区域日LST产品和日NDVI产品,进一步利用最大值合成技术,生成以旬为单位的NDVI和LST最大值合成产品。将多年某一旬的NDVI和LST最大值合成产品再一次应用最大值合成技术,生成多年旬尺度NDVI和LST最大值合成产品;同时,基于最小值合成技术将多年某一旬的LST最大值合成产品逐像素取最小值,得到多年旬尺度LST最大-最小值合成产品。
利用上述NDVI和LST合成产品,根据VTCI计算方法生成2010—2018年每年夏玉米生长季(7—9月)以旬为单位的VTCI时间序列数据,共81旬。另外,VTCI的取值范围为[0,1],VTCI值越小,表明作物受水分胁迫程度越重;VTCI值越大,表明作物受水分胁迫程度较轻或不受水分胁迫。考虑到云雨因素可能造成的某些时段或者某些像素数据的缺失,采用反距离加权插值法[26]对缺失数据进行插补,以保证VTCI数据的完整性。
1.3 研究方法
1.3.1ARIMA预测模型
ARIMA(p,d,q)模型是由BOX和JENKINS提出的时间序列预测方法,通过对非平稳时间序列进行差分处理获得平稳序列,进而利用自回归移动平均模型ARMA(p,q)实现对差分后平稳时间序列未来变化的预测。p为自回归阶数,q为移动平均阶数,d为差分阶数。利用ARIMA模型进行预测的基本步骤为[27]:
(1)平稳性检验及平稳化处理:首先检验VTCI时间序列{Xt;t=1,2,…}的平稳性,若为含有趋势性的非平稳时间序列,对其进行d阶差分处理将其转换为平稳序列{xt},即
(4)

由于xt取值不仅与VTCI时间序列自身值有关,而且还与进入系统的随机扰动值有关,故对平稳时间序列{xt}拟合ARMA(p,q)模型为
(5)
φ(B)xt=θ(B)εt
(6)

(7)
式中θi、φi——模型参数εt——白噪声序列
(2)模型定阶:对于平稳化处理后的时间序列,需要对自回归阶数p和移动平均阶数q进行确定,即实现模型定阶。首先,通过自相关函数(Autocorrelation function,ACF)和偏自相关函数(Partial autocorrelation function,PACF)的拖尾或截尾特征建立对应的模型,其结构判定的基本准则如表1所示,确定p和q的取值范围。然后,根据AIC准则(Akaike information criterion,AIC)对p和q进行优选以保障模型的预测精度,AIC函数达到最小的模型即为最优模型。AIC函数定义为
AIC=-2lnL()+2ω
(8)
式中L()——极大似然函数值
ω——模型参数个数

表1 ARMA模型定阶基本原则Tab.1 ARMA model fixed basic principle
(3)参数估计:模型定阶后,使用极大似然估计法对选定模型中的参数θi、φi进行估计。
(4)模型检验:根据残差序列是否为白噪声序列检验模型是否充分提取序列值的信息。采用正态分布检验法,若残差的自相关函数和偏自相关函数值均落在95%的置信区间内,则残差序列为白噪声序列,表明拟合模型有效提取了序列信息。否则,需要重新拟合模型。
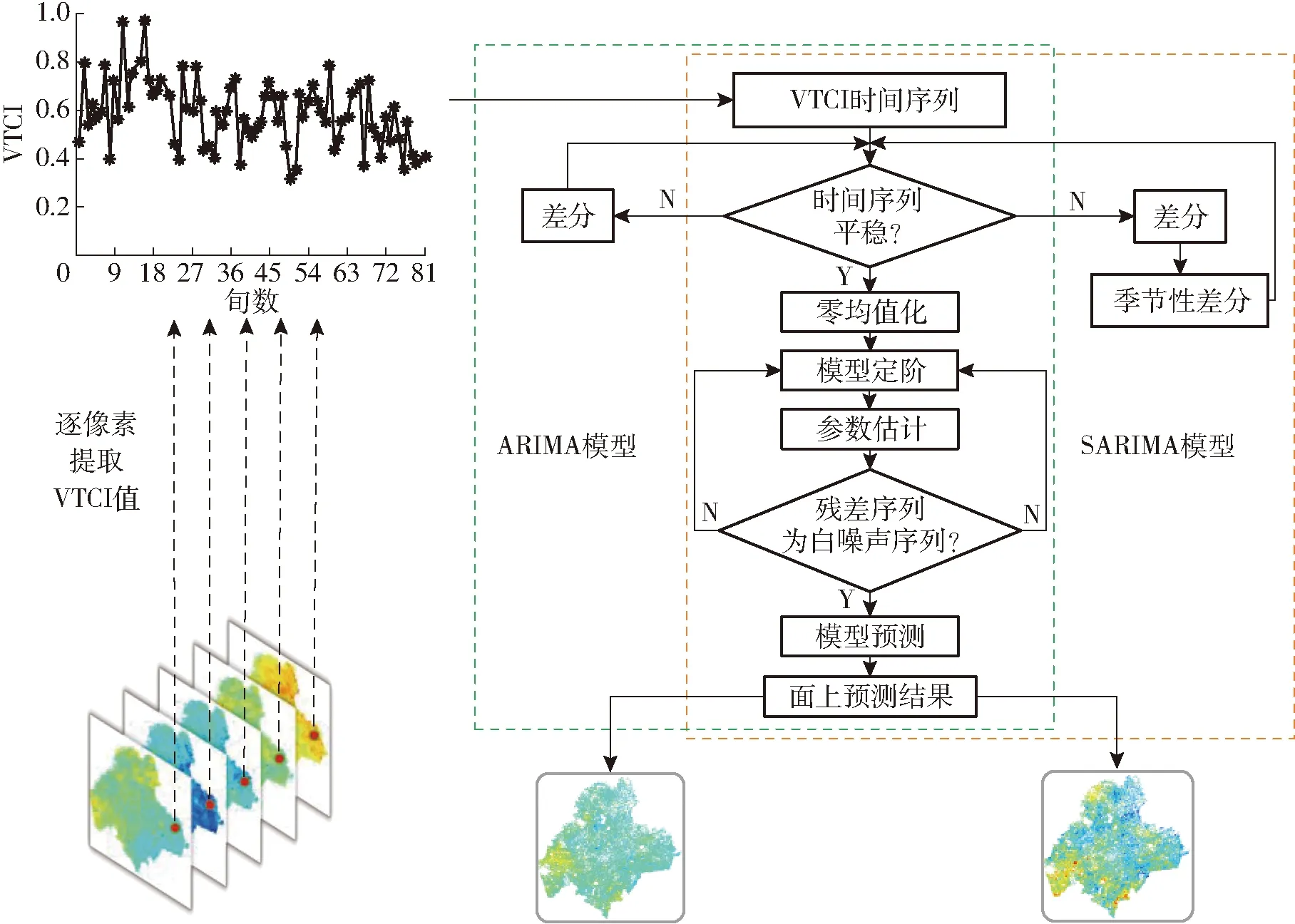
图2 逐像素建模预测流程图Fig.2 Pixel-by-pixel forecasting flow chart
(5)模型预测:经过步骤(1)~(4),即可确定最优预测模型,利用VTCI时间序列运行此最优模型实现VTCI预测。
为了有效减少金矿开采导致的水资源污染,应采用水层隔离方式来减少水污染现象的发生,矿井排水也可以充分利用,用来灌溉农田。通过应用阻水技术和截流技术封闭进水通道,避免矿井水资源泄露,保障矿金周边能够正常供水。针对已污染水源需要及时进行净化处理和水污染治理。采用物理或化学方式进行污水治理,分段治理污水,逐步改善水环境,净化污水。
1.3.2SARIMA预测模型
若非平稳性时间序列不仅含有趋势性变化,还含有季节性变化,对其进行平稳化处理过程中,需要在进行d阶差分的基础上,再进行D阶季节性差分以消除季节性变化影响得到平稳序列[28],模型表示为ARIMA(p,d,q)(P,D,Q)S,具体公式为
(9)
其中
(10)
式中P——季节性自回归阶数
Q——季节性移动平均阶数
Φi、Θi——模型参数
将2010年7月上旬—2018年8月下旬的VTCI数据作为分析建模数据,2016—2018年每年9月上旬—9月下旬的VTCI数据作为检验数据。逐像素提取多旬VTCI建模数据组成一维时间序列,分别作为两个模型的输入数据,预测流程如图2所示,从2016—2018年每年8月下旬分别向前1步、2步和3步得到2016—2018年每年9月上旬1步预测结果、9月中旬2步预测结果和9月下旬3步预测结果。
1.4 预测精度评价
将VTCI遥感监测结果作为真值,应用绝对误差(Absolute error,AE)、平均绝对误差(Mean absolute error,MAE)与均方根误差(Root mean square error,RMSE)评价河北中部平原夏玉米生长季VTCI预测结果的精度,计算式为
AE=i-Xi
(11)
(12)
(13)
Xi——第i个像素的VTCI监测值
N——研究区域内所有像素点数(或气象站点总数)
2 结果与分析
2.1 时间序列长度的确定
有研究表明,时间序列长度是影响模型预测准确性的重要因素[29]。为探究时间序列长度对基于ARIMA模型的VTCI预测精度的影响,选取均匀分布在河北中部平原地区,包括饶阳、任丘、河间、献县、涿州、雄县、高碑店、固安、永清、霸州、晋州、辛集、藁城、深州、故城等49个气象站点(图1),利用49个气象站点所在像素的VTCI时间序列,分别使用9n(n=2,3,…,8)旬不同长度的VTCI数据进行建模预测,并分析基于ARIMA模型的VTCI预测精度随时间序列长度增加的变化特点。
由表2可得,同一时间序列长度时,平均绝对误差随预测步长的增加而增大,表明基于ARIMA模型的VTCI预测精度随预测步长增加而降低。不同时间序列长度时,模型预测精度随时间序列长度增加上下波动,当序列长度大于36旬时,平均绝对误差波动幅度逐渐减小,模型预测精度趋于稳定。综上,考虑到模型预测精度的稳定性,本文分别选取2010年7月上旬至2016年8月下旬、2010年7月上旬至2017年8月下旬、2010年7月上旬至2018年8月下旬的VTCI时间序列数据进行建模,以得到2016—2018年每年9月的VTCI预测结果。
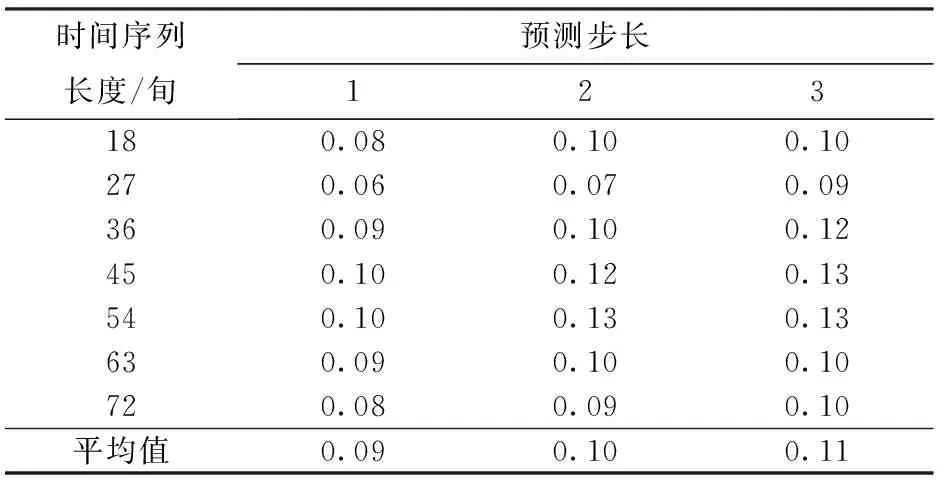
表2 ARIMA模型平均绝对误差随时间序列长度变化的统计结果Tab.2 Statistical results of ARIMA model mean absolute error varied with time series length
2.2 ARIMA模型及SARIMA模型定阶结果分析
根据ARIMA模型建模方法,首先分析49个气象站点所在像素的VTCI时间序列适合的模型结构,再由点及面,逐像素对研究区所有像素的VTCI时间序列进行模型定阶。以饶阳为例,其平稳化处理后VTCI时间序列的自相关系数及偏自相关系数(图3)未随延迟时期增加迅速衰减至零值附近作小值波动,均表现拖尾特征,表明序列适用ARMA(p,q)模型。自相关阶次p和移动平均阶次q可由低阶向高阶逐步试探,p、q的取值范围分别取1~3和0~2。依据AIC准则进一步进行模型优选,AIC值最小的模型即为该序列的最优模型。
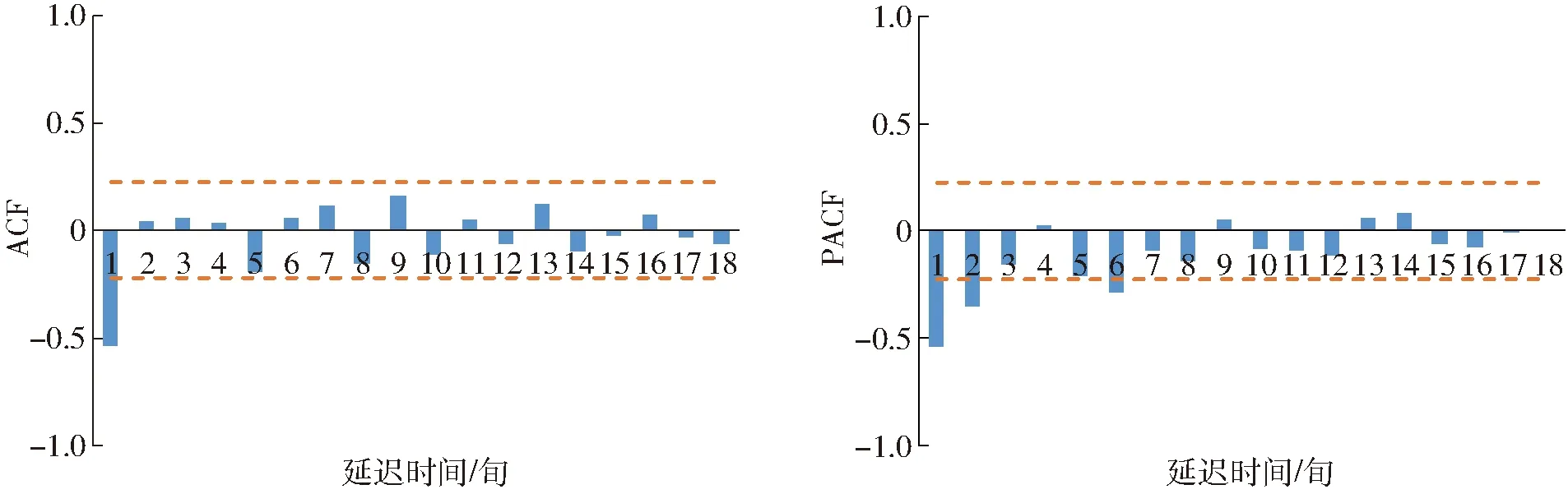
图3 饶阳气象站差分序列的自相关函数和偏自相关函数Fig.3 Autocorrelation and partial autocorrelation function graphs of differenced time series of VTCI in Raoyang weather station

图4 模型定阶结果Fig.4 Model identification results
逐像素对研究区所有像素进行模型优选,得到ARIMA模型和SARIMA模型面上定阶结果(图4)。可以看出,ARIMA模型的定阶结果分布具有区域性,未出现“椒盐式”分布现象,表明相邻像素点干旱变化情况具有良好的相关性。廊坊市、沧州市、衡水市及石家庄东部等区域适合ARIMA(1,1,1)模型,模型形式较为一致。然而,保定市的模型形式存在ARIMA(1,1,1)、ARIMA(1,1,2)及ARIMA(2,1,1)等多种情况,表明受客观环境及人为因素的影响,同一地区不同像素VTCI时间序列反映的旱情特性也存在差异性,适用的模型形式可能不同。综上,逐像素确定ARIMA模型形式的方法较为合理。SARIMA模型的定阶结果分布虽呈现了类似的区域性特征,但适用的模型形式更为多样,大部分地区适用的模型为ARIMA(1,1,1)(0,1,0)9以及ARIMA(3,1,2)(0,1,0)9。整体来看,ARIMA模型定阶结果较SARIMA模型区域分布特征更为明确,相邻像素点间干旱变化状况相关性更强。
2.3 干旱预测结果分析
2.3.1两种模型VTCI预测结果比较

图5 2017年9月干旱监测结果与预测结果Fig.5 Drought monitoring results and forecasting results in September 2017
根据2.2节中两种模型定阶结果,逐像素进行参数估计和预测,分别得到2017年9月上旬1步预测结果、9月中旬2步预测结果、9月下旬3步预测结果(图5)。对于ARIMA模型预测结果,从时间上看,各旬VTCI均存在较大差异,9月上旬和下旬预测结果VTCI值偏高,特别是中部地区,处于不旱或较为湿润的状态;而9月中旬预测结果VTCI值较上旬和下旬预测结果整体偏低,大部分地区均有旱情发生,虽然与监测结果相比,预测旱情偏轻,但准确反映了河北中部平原地区9月上旬到9月中旬旱情加重,9月中旬到9月下旬旱情有所缓解的变化趋势。从空间分布来看,河北中部平原西北部VTCI值较东南部偏低,特别是保定市和石家庄市东部地区较其他地区干旱严重,与实际监测结果一致。总体来说,三旬的预测结果基本反映了监测结果的特征。
比较来说,SARIMA模型预测结果与ARIMA模型预测结果表征的旱情发展趋势较为相似,9月中旬大部分地区均有旱情发生,与实际情况吻合。然而,石家庄及衡水市部分地区的3步预测结果显示干旱程度加深,受旱面积也呈扩大趋势,与监测结果相差较大,表明SARIMA模型3步预测结果的不确定较大,不适合更长期的预测。整体来看,SARIAM模型向前1~2步预测较为准确,但向前3步预测结果精度稍差。
综上所述,ARIMA模型较SARIMA模型对河北中部平原夏玉米生长季干旱的预测能力更为突出,向前1~3旬预测结果均较为准确反映旱情的发展变化趋势。
2.3.2两种模型干旱预测结果的精度评价
为定量评价两个模型的预测精度,以2017年9月研究区VTCI干旱监测结果为真值,以基于两模型分别向前预测1步、2步和3步得到的2017年9月上旬、中旬和下旬VTCI预测结果为预测值,计算得到两模型预测结果与监测结果的绝对误差和绝对误差频数分布图(图6)。频数大于500时,ARIMA模型1步预测结果绝对误差主要分布在[-0.05,0.14],而SARIMA模型1步预测结果主要分布在[-0.18,0.27],较ARIMA模型误差分布更为分散。两者峰值虽较为接近,分别为0.04和0.07,但前者峰值频数为6 022,而后者仅为4 122。2步和3步预测绝对误差分布规律与1步预测相似,ARIMA模型预测误差分布较SARIMA模型更为集中,最大频数对应的绝对误差更接近零值。另外,逐像素计算并统计两模型预测结果与监测结果的平均绝对误差以及均方根误差(表3),结果表明,基于ARIMA模型1步、2步、3步VTCI预测结果的平均绝对误差和均方根误差均低于基于SARIMA模型的误差,平均绝对误差分别降低0.05、0.05、0.08,均方根误差分别降低0.06、0.07、0.09。综上,ARIMA模型预测结果整体上精度更高,预测结果反映的旱情与实际情况更为吻合,可用于研究区夏玉米生长季干旱预测。

图6 2017年9月预测结果绝对误差频数分布Fig.6 Frequency distributions of absolute errors of forecasting results in September 2017

表3 ARIMA模型和SARIMA模型预测误差的统计分析Tab.3 Statistical results of forecasting errors of ARIMA model and SARIMA model
2.3.3ARIMA模型干旱预测结果分析
在比较ARIMA模型和SARIMA模型预测精度的基础上,利用精度较高的ARIMA模型逐像素建模预测,得到研究区域2016—2018年每年9月的VTCI干旱预测结果,计算统计所有像素绝对误差绝对值及误差在不同区间的分布情况(表4),分析不同年份夏玉米生长季VTCI的预测精度。结果表明2016—2018年各旬VTCI预测结果中,2017年9月上旬1步预测结果精度最高,仅有约0.61%的像素绝对误差绝对值超过0.20;2016年9月下旬3步预测结果精度最低,有大约17.26%的像素绝对误差绝对值超过0.20。其中,2016—2018年向前1步的VTCI预测结果中仅有5.84%的像素绝对误差绝对值大于0.20,并且有62.16%的像素绝对误差绝对值小于0.10,表明向前1步的VTCI预测精度较高。随着预测步长的增加预测精度略微下降,2步、3步预测结果中像素绝对误差绝对值大于0.20的百分比分别为6.38%、8.72%。整体来说,不同年份夏玉米生长季ARIMA模型1步、2步、3步的VTCI预测精度均较理想。
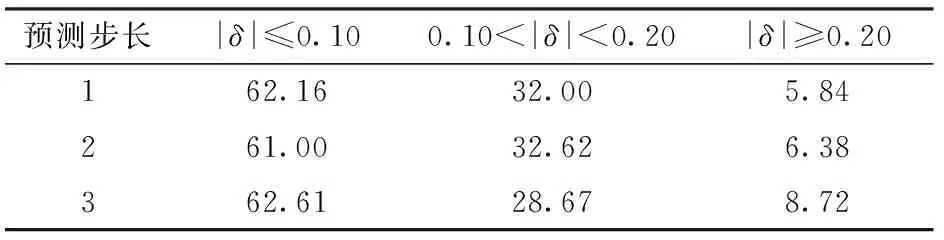
表4 2016—2018年VTCI预测的绝对误差区间的分布Tab.4 Distribution of absolute error interval of VTCI forecasting from 2016 to 2018 %
注:|δ|表示VTCI预测的绝对误差绝对值。
3 讨论
基于遥感反演的VTCI干旱监测结果进行夏玉米生长季干旱预测,虽然VTCI时间序列在物理意义上具有周期为9的季节性,但SARIMA模型预测精度整体较ARIMA模型低,主要因为河北中部平原夏玉米种植区VTCI时间序列未表现明显的季节特性,若对平稳化处理后的序列再进行季节差分,会因为差分过程中信息的损失出现过度差分(简称过差分)的现象,从而影响模型预测精度。
另外,前人研究已表明干旱预测是属于带有强非线性特征的系统问题[30],ARIMA模型作为一种线性预测方法,会忽略VTCI时间序列数据中的非线性部分,在准确预测旱情发展趋势方面具有一定劣势。所以在后期的研究中,可利用在非线性系统预测方面具有较强优势的神经网络等方法对ARIMA建模过程中的未拟合的非线性误差进行修正,以提高干旱预测的精度。
4 结论
(1)基于49个气象站点所在像素的VTCI时间序列,使用不同时间序列长度的VTCI数据进行建模预测,结果表明,基于ARIMA模型的VTCI预测精度与时间序列长度未呈现明显的相关关系,但模型预测精度随序列长度的增加而逐渐趋于稳定。
(2)将ARIMA模型和SARIMA模型分别用于河北中部平原2017年夏玉米生长季VTCI预测,结果表明,ARIMA模型较SARIMA模型VTCI预测精度更高,更适合河北中部平原夏玉米生长季的干旱预测,其1步、2步、3步VTCI预测的均方根误差分别为0.07、0.14、0.10。
(3)应用ARIMA模型逐像素对2016—2018年夏玉米生长季VTCI进行预测,结果表明,不同年份夏玉米生长季VTCI的预测精度稳定性较好,其2016—2018年1步、2步和3步VTCI预测结果绝对误差绝对值大于0.20的像素平均占比分别为5.84%、6.38%、8.72%。
猜你喜欢
少儿画王(3-6岁)(2024年4期)2024-05-19 06:11:03
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
中国农业信息(2021年4期)2021-12-21 07:23:40
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
今日农业(2019年11期)2019-08-13 00:49:00
现代园艺(2017年19期)2018-01-19 02:50:04
CHIP新电脑(2016年3期)2016-03-10 14:22:03
水利信息化(2015年5期)2015-12-21 12:54:40
天津农林科技(2011年3期)2011-05-14 00:49:46
