
基于BP神经网络的企业复工复产预测研究
2020-03-09 00:40:52李国华李晨光姜辰龙郭骐翔
吉林电力 2020年6期
周 莽,李国华,李晨光,姜辰龙,郭骐翔
(国网长春供电公司,长春 130021)
2020年初爆发的“新型冠状病毒肺炎”(简称:“新冠肺炎”)成为举国关心的焦点。文献[1]中由于其存在人传人的特性,加上春节期间返潮高峰,在短期内来看,“新冠肺炎”疫情对我国社会经济发展产生了较大的影响。由于电力作为国民经济发展的“预警器”和“晴雨表”,通过客观、真实地反映当前生产生活的电能消耗情况,能够准确地反映社会经济发展状况,因此,在“新冠肺炎”疫情期间,基于电力数据开展企业复工复产监控及预测,对稳经济、保民生至关重要。在此背景下,构建企业复工复产状态识别方法具有重要实践意义。
当前,学术界关于“新冠肺炎”疫情对企业复工复产影响的研究相对较少,主要集中在:文献[1]中疫情对就业、文献[2]中疫情对供应链等方面的影响。另外,文献[3]中对疫情后复工的影响,研究了缓疫策略执行力和依从性。总体来看,“新冠肺炎”疫情对企业复工复产产生了重要的影响,如何从电网角度助力企业复工复产成为重要的研究课题。以往企业复工复产运行状态监测主要依赖于人为主观判断,缺乏科学依据,并且监测效率及预测准确度较低,企业复工复产预测方法缺少推广性,导致疫情防控决策缺少准确的方法支持。近年来,利用电力大数据进行预测的研究一直受到国内外学者的重视,并展开了大量的研究。学者们主要采用线性和非线性两种方式进行预测,其中线性预测模型主要包括文献[4]中自回归滑动平均(ARMA)模型和文献[5]中差分整合移动平均自回归(ARIMA)模型;文献[6]中非线性预测模型包括灰色模型(GM)、文献[7]中支持向量机(SVM)和文献[8]中神经网络(NN)等预测模型。根据以往电力领域预测的研究表明,在大数据背景下,文献[9]中提出神经网络因其结构简单等特点,使其被广泛应用。基于吉林省某市的企业用户电力数据,借鉴较成熟的人工神经网络预测理论和方法,对企业是否复工复产情况进行预测。首先,确定企业复工复产的基本特征,提炼相应的指标体系;其次,通过电话访谈及网络调研等方式,获得企业复工复产的实测数据;最后,基于BP神经网络算法,构建企业复工复产状态识别模型,通过训练参数,得到接近于实际结果的识别模型,因此,利用BP神经网络算法,准确、高效识别企业复工复产状态,提高模型预测准确度,为政府决策、电网公司稳定运行、企业生产经营提供数据支撑。
1 算法分析
人工神经网络区别于生物学上的神经网络,拥有如BP神经网络、遗传算法等分支,文献[10]中BP神经网络算法是当前电力领域应用较多的一种机器学习算法。因此,构建基于BP神经网络的企业复工复产预测模型,解决企业用电特征的非线性映射问题。
1.1 BP神经元原理
BP神经元是神经网络的最小数据处理单位,其中存在大量数据存储节点,其模仿生物神经元的特征:加权、求和与转移。设x1、x2、x3…xn为神经元的输入项;wj1、wj2、wj3…wjn为权系数;bj为判断阈值;Sj为净输入值;f(·)为激励函数;yj为第j个神经元的输出项。那么,BP神经网络在第j个神经元的净输入值为:
(1)
式中:X=[x1,x2,…,xi,…,xn]T,W=[wj1,wj2,…,wji,…,wjn]。
净输入通过激励函数测算得到第j个神经元的输出值为:
(2)
f(·)反映了BP神经网络中的非线性映射能力。另外,f(·)分为单极性激励函数(log-sigmoid函数)和双极性激励函数(tan-sigmoid函数)。由于tan-sigmoid激励函数延迟了饱和期,因此,选择tan-sigmoid激励函数进行学习。tan-sigmoid激励函数公式为:
(3)
式中f(x)的范围为(-1,1)。
1.2 BP神经网络算法流程
采用BP神经网络方法对企业复工复产进行预测,训练并调优模型参数。神经网络算法流程见图1。

图1 BP神经网络流程
2 实例分析
2.1 数据来源
以吉林省某市的企业用户为例,除去居民用户外,所有电压等级为380 V及以上,日均平均电量不小于10 kW·h的用户。样本数据主要来源于电力营销系统,按照农林渔牧业、矿业、制造业、物流仓储业、批发和零售业、住宿和餐饮业、金融业七个行业,每个行业随机抽取400户,共获得2 800个样本作为模型数据,其中样本变量主要包括行业分类、运行容量、电量等。由于训练数据不能再用于模型测试,因此将样本数的80%用于训练模型,调整模型结构,提高模型拟合度,其余20%样本数据测试训练后的模型,验证模型拟合结果的正确性。通过电话访谈及网络调研的方式,明确企业复工复产情况,将企业实际的复工复产状态作为模型训练样本的输入数据。
2.2 神经网络模型构建
2.2.1 指标选定
为了提高模型预测效果,降低模型估计误差,需要获取更多输入指标的特征,界定输入指标的概念。主要包括2019年全年平均日电量(q1)、过年期间(除夕、初一、初二)的平均电量(q2)、当前日电量(q3)及用户运行容量(D)。考虑到企业用电量一般规律,针对当前日用电量小于5 kW·h的企业直接视为未复工复产企业。另外,D用于控制同行业内不同企业用电规模的差异对计算结果偏差的影响。上述4项作为网络学习样本中的输入项,输出项为企业复工复产的实测值。为了降低样本数据的随机误差,对学习样本数据先进行归一化,降低模型训练的随机误差。
2.2.2 训练过程
BP神经网络模型由输入层、隐藏层及输出层组成,其中只有输入层和隐藏层才有偏置调节。鉴于企业复工复产状态属于客观事实,训练模型时需要提前判断其真实状态,因此,选择有导师信号的神经网络。其结构见图2。

图2 复工复产BP神经网络训练过程
图中输入节点[x1,x2,x3,x4]分别表示用户运行用量、全年平均日电量、过年期间平均日电量和当年日电量,隐含层表示权重判断[wj1,wj2,…,wjn],输出层表示输出节点。最终输出值是通过一系列非线性函数运算之后得出,即:
(4)
式中:xi为第i个维度的输入;n取4;m为对应的输出端的节点个数。
根据BP神经网络正向传播得到模型输出值,如果期望值与测算值存在较大偏差,则将误差结果进行反向传播测算,即实现误差值最小化。均方误差(EMS)为:
(5)
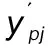
测算全局的误差主要目的是为了改变BP神经网络的连接权系数,在最大程度上减小全局误差,调整全局连接权系数的公式为:
(6)
式中:η表示学习速率,主要影响连接权系数在循环过程中产生变化量的大小,考虑到η过小会影响运行速度和系统稳定性,文献[10]中η一般取值在0.01~0.8之间。
2.3 模型训练结果分析
通过训练样本数据,当模型的均方误差处于稳定状态后,即不再修改模型的权值和阈值,只需改变输入节点数和输出节点数,即可直接用于测试样本的训练,对计算结果进行反复修正,从而使网络输出的最后结果具有误差最小、精度最高。首先,在训练过程中将训练样本数据输入模型,并根据训练样本数据的误差调整模型结构;其次,用验证数据测量模型的优化程度,当模型优化程度稳定时即停止训练;最后,测试训练后的模型预测效果,判断模型优劣。神经元的内部函数采用S型函数进行计算。根据神经网络算法及用于判别的六大指标,构建人工神经网络模型。D、q1、q2、q3作为输入变量,企业复工与否为期望输出信号。将指标数据输入神经网络模型,通过增加迭代次数与神经元,不断调整其权值和阈值,使预测准确率达到最大,此时的神经网络模型结果为最优。
将企业复工复产相关数据输入模型进行训练,得到训练曲线见图3。由图中可知,在对样本进行了246次训练后,均方误差处于较低水平,且基本没有变化,表明BP神经网络模型拟合度较好。另外,当隐藏层神经元个数达到48个时,均方误差基本处于稳定状态,表明BP神经网络具有较快的收敛速度及较高的预测精度。
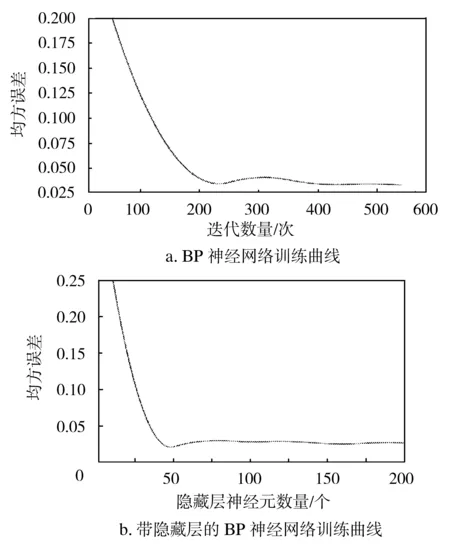
图3 复工复产BP神经网络训练曲线
基于最优的BP神经网络模型,将20%的样本进行测试,采用S型函数进行计算,其中将各行业实际复工企业数与其中预测正确复工企业数进行比较,得出预测准确率。表1为BP神经网络模型测试样本得到的不同行业的企业复工复产预测正确率。总体来看,BP神经网络预测企业复工复产的准确率较高,总体准确率达到了92.3%,其中金融业企业复工复产预测准确率达到了97.5%,表明BP神经网络预测值与实测值的偏差较小,模型预测效果较好。
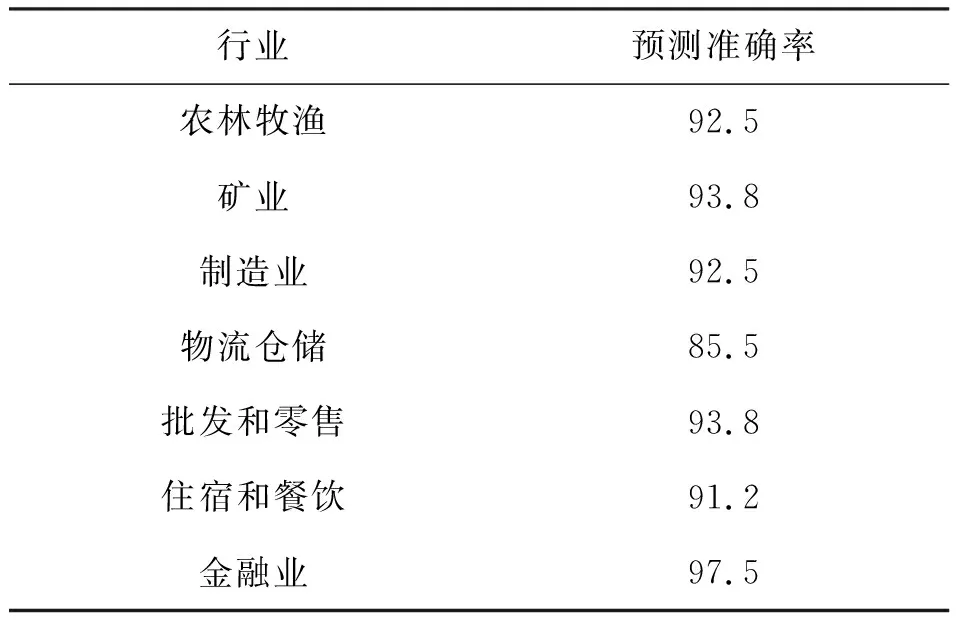
表1 各行业企业复工复产预测准确率情况 %
3 结论
通过综合考虑企业生产经营用电特征、能耗使用情况、节日期间用电特性和冬季用电特性等因素对企业复工复产的影响,构建了BP神经网络企业复工复产预测模型。研究结果表明:企业复工复产预测模型训练迭代次数及隐藏层神经元个数均达到了模型均方误差的稳定状态,模型预测效果较佳;同时企业复工复产预测准确率达到了92.3%,模型预测准确度较高。构建的BP神经网络企业复工复产预测模型具有较高的实际推广应用价值,但从模型预测准确率来看,在预测精确上仍存在7.7%的提升空间,因此,下一步将在改进模型结构、完善指标体系等角度入手,进一步提高企业复工复产预测的准确性。
猜你喜欢
江苏安全生产(2022年2期)2022-04-19 13:03:24
自然杂志(2021年6期)2021-12-23 08:24:46
建材发展导向(2020年16期)2020-09-25 07:54:52
安全(2020年3期)2020-04-25 06:54:20
中国化肥信息(2020年3期)2020-01-20 01:28:17
电子制作(2019年19期)2019-11-23 08:42:00
现代装饰(2018年5期)2018-05-26 09:09:01
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
电源技术(2015年5期)2015-08-22 11:18:38
