
结合LBP特征和深度学习的人脸表情识别
2020-03-09 13:12
计算机测量与控制 2020年2期
(1.聊城大学 物理科学与信息工程学院,山东 聊城 252059;2.聊城大学 机械与汽车工程学院,山东 聊城 252059)
0 引言
人脸表情在人与人交流过程中扮演着重要的角色,是进行情感信息交流的主要方式。随着大数据与人工智能时代的来临,如何在人机交互中实现计算机对人脸表情的识别,成为了当下的一个热门研究领域。
现如今人脸表情识别大多分为两个方向,先提取人脸表情特征再使用分类算法进行识别的传统方法和深度学习下的人脸表情识别方法。在提取特征方面,众多学者提出了LBP特征[1]、尺度不变特征变换(scale-invariant feature transform,SIFT)[2]、灰度共生矩阵(gray-level co-occurrence matrix,GLCM)[3]和Gabor小波变换[4]等特征提取方式,在分类算法上则有支持向量机(support vector machine,SVM)[5]、K最近邻分类[6](k-NearestNeighbor,KNN)、随机森林[7](random forest,RF)等分类方式。但这些方法所提取特征受人为干扰因素过大,会造成人脸表情信息的丢失,导致最终分类准确率不高,除此以外,这些方法对其他数据的泛化能力也较低。在2012年,Krizhevsky使用卷积神经网络(convolutional neural networks, CNN)模型在ImageNet竞赛中取得冠军,其Top-5错误率为17%,远超过传统方法下的图像分类正确率,这一现象引发了研究人员的广泛关注,从此深度学习被广泛应用于图像分类问题中。例如Tang[8]将CNN与SVM相结合,在FER2013数据集上达到了71.2%的识别率。Jeon[9]等结合方向梯度直方图(histogram of oriented gradient, HOG)和CNN来进行人脸表情识别,取得了较好的识别效果。本文也将使用CNN的方式来识别人脸表情,首先提取数据库图片LBP特征,将其尺寸归一化之后输入到改进的LeNet-5神经网络中进行识别,实验结果表明,所提方法在CK+和JAFFE数据库中可获得非常好的识别效果。
1 系统流程
文中系统流程如图1所示,主要过程包括:1)图像预处理。采用基于Haar-like特征的AdaBoost算法来提取人脸区域,然后提取人脸区域LBP特征并将其尺寸归一化,以作为神经网络的输入;2)改进神经网络。原始的LeNet-5网络是用来识别手写体数字图片,该种图片背景单一且较为简单,因此原始网络不适合直接对复杂的人脸表情进行识别,需要对网络的各种参数和结构进行调整;3)实验与评估。使用调整好的神经网络对输入图片进行训练和识别,统计准确率来判断文中方法性能。

图1 系统流程图
2 图像预处理
CK+与JAFFE数据集中的原始图像包含了人脸区域和背景,需要经过预处理去除冗余信息,才适合作为神经网络的输入图像,本文中的预处理为:人脸检测、LBP特征提取和尺寸归一化。
2.1 人脸检测
本文采用基于Haar-like特征的Adaboost算法检测人脸区域,该算法运算速度和正确率都很高,可满足实时检测的要求。该方法基本思想是使用Adaboost算法将基于图像特征的弱分类器训练为强分类器,再将强分类器组合成级联强分类器来检测人脸区域,所检测出的人脸图像如图2所示。

图2 人脸检测示意图
2.2 LBP特征提取
LBP是一种描述纹理的算法,具有旋转和灰度不变性[10]等特点,被广泛地应用于纹理分析、图像匹配等领域。常用的LBP有两种:基本LBP算法和圆形LBP算法。基本LBP算法是将中心点像素值和中心点8邻域像素值作比较,如果8邻域像素值小于中心像素值,则标记为0,否则标记为1,然后从左上角开始顺时针将二值化后的8邻域像素值组合成一串8位二进制数字,然后将其转换为10进制数字,由该数字来代替中心像素值。圆形LBP算法则是将基本LBP算法的3×3邻域扩展到任意圆形邻域,该邻域可由参数(P,R)表示,P为邻域像素个数,R为该邻域半径,该算法改善了基本LBP算法无法识别大尺寸纹理特征的缺点。本文中所提取到的人脸表情LBP特征图如图3所示。

图3 LBP算法示意图
图3中可以看出处理后的图像可明显突出表情特征。
2.3 尺寸归一化
通过双线性插值算法将已经检测出来的人脸LBP特征图尺寸进行调整,使得所有的神经网络输入图片尺寸相同,避免了输入到神经网络后出现的尺寸不匹配问题。尺寸归一化算法为双线性插值算法,其基本思想是将待求像素点周围4个点的像素值进行加权平均,最后计算出待求点的像素值。该方法可一定程度上避免失真,保持图像的清晰度。尺寸归一化之后的图像如图4所示。

图4 尺寸归一化示意图
3 神经网络模型
3.1 卷积神经网络
卷积神经网络是前馈式的神经网络,可从输入数据中自动提取特征,具有很强的学习和表达能力,非常适合图像分类问题。该网络通常包含以下部分:卷积层、池化层、全连接层[11]。
一般来说,卷积层和输入图像直接相连,通过使用不同的卷积核将输入图像转变为抽象程度更高的图像特征并传给下一层,卷积层的计算过程如式(1)所示:
(1)
通常在卷积层之后会再加入池化层,池化层不但可以对特征降维,而且可以较好地保持特征的尺度不变性,同时也能降低神经网络的运算量。池化层计算公式如式(2)所示:
(2)


表1 改进后的LeNet-5网络结构
全连接层的作用是将图像的二维特征组合为一维特征,通常放在卷积层和池化层之后。该层输出公式如式(3)所示。
Il=f(wlIl-1+bl)
(3)
其中:Il和Il-1分别为输出和输入,wl为全连接层的权重值,bl为全连接层的相应的偏置项。
3.2 改进的LeNet-5网络模型
LeNet-5模型最初是用来识别手写体数字,其准确率达到98%以上,是一种经典的神经网络模型,具体结构如图5所示。
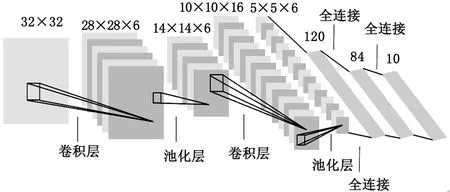
图5 Lenet-5网络结构图
使用LeNet-5模型对人脸表情进行识别,发现损失值收敛速度过慢,准确率较低。经分析之后对网络结构进行改进,具体如下:
1)原始LeNet-5是用来进行手写体数字识别,其图片相对简单,尺寸也较低,为32×32;而本文所进行的人脸表情识别图像复杂,且不同表情之间差异较小,使用低尺寸图片会使得图像损失特征信息,所以本文将输入图像尺寸调整为128×128。
2)调整卷积核的个数。卷积核的个数影响到之后输出的特征图个数,考虑到人脸表情过于复杂,本文将增加卷积核的个数以提高网络分辨表情的能力,将前6层的卷积核个数分别设置为16、16、32、32、64和64,同时将后3层全连接层的输出节点个数分别设置为128,64和7。
3)调整卷积核的尺寸大小。卷积核的尺寸与提取到的特征质量有关,原始的LeNet-5采用5×5的卷积核,用来提取人脸图像特征效果不好,本文将调整卷积核大小,具体为表1所示。
4)将sigmoid激活函数替换为Leaky ReLU激活函数。原有sigmoid函数计算量过大,并且在输入过大或者过小时,输出会接近+1和-1,斜率很低,在使用梯度下降法时梯度下降过慢,会严重降低训练速度,不适合当前网络结构。所采用的Leaky ReLU函数与当前卷积神经网络常用的ReLU激活函数相比,其优点在于可以避免当输入为负值时导致权重无法更新的问题。
5)在原有的前4层网络之后,新加入第5层卷积层和第6层池化层。本文网络结构输入图像尺寸为128×128,经过前4层网络之后特征图尺寸为11×11,需要继续降低尺寸,减少计算的复杂度。
6)在第一层全连接层之后加入Dropout函数,Dropout可用来解决网络模型中数据过拟合的问题,也可以增强网络模型的泛化能力。
7)使用学习率指数衰减法对网络结构进行优化。使用该方法可提高神经网络训练速度,使训练过程中损失曲线更加稳定的下降,减少曲线的震荡次数。
改进之后的网络模型结构如表1所示。表1结构包含卷积层、池化层和全连接层,输入层和softmax层未列于此表中。
4 实验结果与分析
4.1 实验数据与环境
本文将分别在CK+与JAFFE公开数据集上进行测试,由于JAFFE数据集不包含轻蔑类型的表情,因此本文将去除CK+数据集中的轻蔑类型,最终将表情分类为生气、厌恶、恐惧、悲伤、快乐、惊讶、中性7种人脸表情。由于CK+和JAFFE数据集原始表情数量较少,本文将原始人脸表情图像以仿射变换方式对样本数量进行扩充。扩充后的CK+数据集图像为6476张,JAFFE数据集图像为4689张。人脸表情图像样例如图6所示。

图6 CK+与JAFFE数据集人脸表情样例
本文方法使用硬件信息如下:GPU为NVIDAGeForceGTX1660 6G,CPU为InterCorei3 8100 3.6 GHz,内存为8 G;软件信息如下:操作系统为Window 10,安装Python3.6.5和TensorFlow深度学习框架。神经网络中所设置超参数如下:初始化学习率为0.0005,学习率衰减指数为0.96,动量为0.9,正则化系数为0.001,dropout设置为0.5,Epoch为20。
4.2 输入图像和网络结构之间的交叉对比
为证明本文方法的有效性,并探索何种方式才能得出最高的正确率,本文将使用10次10折交叉验证方法,对不同的输入图像输入到不同的网络中得到的准确率做出了统计,具体如表2所示。

表2 CK+与JAFFE数据集实验准确率
表2中第1列为不同的输入图像类型,第2列和第3列为使用原始LeNet-5网络和改进之后的LeNet-5网络对CK+数据集上的输入图像进行识别的准确率,第4列和第5列为使用原始LeNet-5网络和改进之后的LeNet-5网络对JAFFE数据集上的输入图像进行识别的准确率。
从表2可以看出,使用原始LeNet-5网络来进行人脸表情识别准确率较低,即使输入图像为LBP特征图像,也只提升了2%~3%左右的准确率,其原因在于原始的网络结构并不适合人脸表情识别,需要做出针对性的调整才能使准确率得到提高。由实验数据可知将数据集图像所提取的圆形LBP(8,5)特征图输入到改进的LeNet-5网络中,其识别率可达到最高,在CK+和JAFFE数据集可以分别达到98.19%和96.35%的准确率。
为进一步查看本文中方法性能,使用上述方法统计不同表情的准确率,如表3所示。

表3 不同表情识别准确率
由表3可知,本文方法对CK+数据集不同表情识别率均达到了95%以上,其中高兴和惊讶的识别率为100%;在JAFFE数据集准确率稍低,但也有5种表情识别率在95%以上,足以证明本文方法的有效性。
为了更加直观地观察神经网络的性能,本文绘制了JAFFE和CK+数据集的损失值和准确率曲线,如图7所示。

图7 不同数据集损失和准确率曲线图
从图7中可以看出,随着迭代次数的增加,JAFFE和CK+数据集的损失值和准确率均趋于平缓,且损失值可以迅速下降,说明本文所设计的网络模型较为合理。
4.3 与其他方法的对比
表4和表5展示了使用其他方法在JAFFE和CK+表情数据集的识别率对比。

表4 JAFFE数据集实验准确率

表5 CK+数据集实验准确率
由表4可知,使用深度学习对人脸表情进行识别要比传统方法的准确率高。这是因为传统方法所提取特征难以完全描述人脸表情特点,进而在分类算法中准确率难以得到提高。
由表5可知,虽然同样采用了深度学习的方法来进行人脸识别,但本文方法的准确率是最高的。文献[15]和文献[16]所使用卷积神经网络结构较为基础,没有针对人脸表情识别问题对网络结构做出针对性的调整,且训练样本较少,最终准确率较低;文献[17]虽然对网络结构做出了改进,但其特征提取能力不如本文方法,使得准确率不高。文献[18]使用HOG提取特征,再使用主成分分析法降维,最终将特征向量送入深度稀疏编码网络中进行识别。其总体准确率尚可,但单一表情识别率如恐惧和悲伤不如本文方法准确率高。
5 结语
本文结合LBP特征提取与改进后的Lenet-5网络对人脸表情进行识别,其结果要优于主流方法。为更好地提取到图像特征,将原始图像的LBP特征输入到网络模型中去,并对比了输入哪一种LBP特征图准确率更高;将Lenet-5网络进行以适用于人脸表情识别,包括输入图像尺寸的调整、卷积核的调整、层数的调整和加入神经网络优化算法等。
文章下一步计划是将本方法应用于不同的数据集中以查看方法性能,此外还需要加强神经网络泛化能力。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
计算机系统应用(2021年9期)2021-10-11
奥秘(2021年5期)2021-06-15
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
